Discover how tailored, culturally aware mental health support can help digital forensic investigators cope with the hidden trauma of their work....
Discover how tailored, culturally aware mental health support can help digital forensic investigators cope with the hidden trauma of their work....

20th August 2025
Read the latest digital forensics news – SANS releases DFIR Summit playlist, UAC launches v3.2.0, Neal Ysart discusses the Coalition of Cyber Investigators, and more....read more

20th August 2025
Explore S21 Transcriber: a fully offline, court-ready tool with free 30-day access and training....read more

19th August 2025
Retailers face rising cyber threats—join Exterro's Sept 4 webinar to learn fast, modern forensic response strategies and protect your brand....read more

Forensic video analysts face a new level of complexity with the increasing use of H265/HEVC in modern surveillance systems. If you’re working with H265/HEVC video, you may already know how challenging its compression can be.
To help you address this challenge, Amped Software has introduced the Coding Tree Units (CTU) filter in Amped FIVE. A tool designed to decode and visualize the structure of H265 video at the block level. Essential for understanding image reliability and integrity.
In this article, you’ll learn why Coding Tree Units matter, what they reveal about your footage, and how to use this filter in your forensic investigations.
Coding Tree Units are the foundational building blocks of video encoded with H265/HEVC. Unlike older standards like H264, which used smaller “macroblocks” (typically 8×8 or 16×16 pixels), CTUs can be as large as 64×64 pixels. These blocks are subdivided into smaller Coding Units (CUs) and Prediction Units (PUs) based on image complexity and motion.
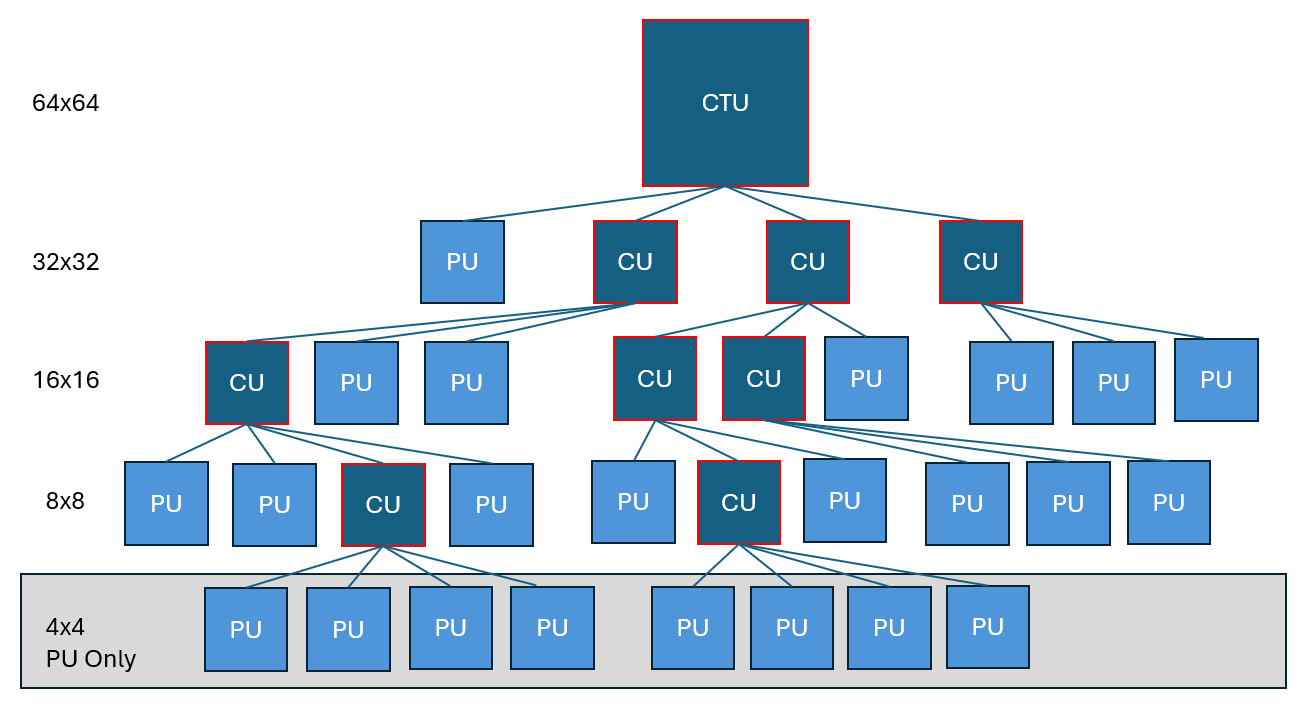
Why does this matter? Because how a frame is divided and compressed affects how reliable and detailed the image truly is. Understanding CTUs lets you see whether a part of the image was truly captured or merely copied from a previous frame.
The structure enables highly adaptive compression but introduces variability in how image regions are encoded. From a forensic perspective, this variability can obscure critical image features or create encoding artifacts that impact interpretation.
If you’re analyzing video evidence during an investigation and to be presented in a courtroom, it’s not enough to “see” an object in a frame. You need to verify its authenticity and reliability. Here’s why understanding CTUs is important:
By analyzing CTUs, you get a behind-the-scenes look at how the image was formed. This allows you to make informed judgments about its forensic value.
1) Access the filter
Navigate to the Verify filter category. Locate “Coding Tree Units” or use the quick search bar. The filter interface includes two tabs: Settings and Legend.
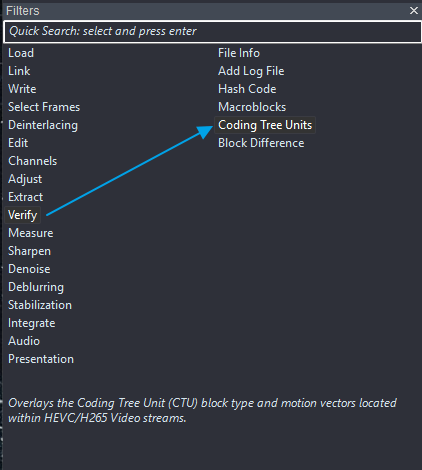
2) Consult the Legend first
Before activating overlays, review the Legend tab. Color codes indicate:
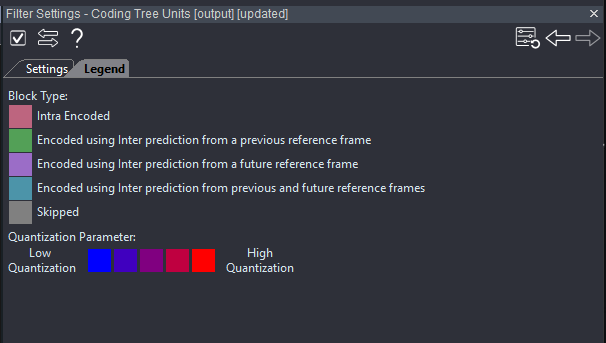
This legend parallels Amped FIVE’s Macroblocks filter but is adapted for HEVC.
3) Enable CTU Subdivision Visualization
In the Settings tab, check the option for CTU Subdivisions. This overlay maps how each 64×64 unit is broken into smaller coding units. Irregular subdivisions typically indicate regions of interest or image complexity.

4) Analyze Prediction Units
Enable Prediction Units to see how the encoder handled motion:

Use this to understand why a specific area lacks detail or appears distorted.
5) Inspect Motion Vectors
For video with B or P frames, activate Motion Vectors. Arrows will illustrate the spatial relationship between the encoded block and its reference source. This is particularly valuable when tracking objects or validating object persistence across frames.

6) Evaluate Spatial Compression via Quantization
Overlay the Quantization Parameter to determine the level of spatial compression applied per unit. A QP closer to 51 suggests aggressive compression, often resulting in loss of detail critical to forensic tasks.

One of the main takeaways from using this filter is that more pixels don’t always mean more usable information. For example, a 4K video might appear sharp overall but lose crucial detail in motion or low-light areas due to compression.
A license plate might be visible in one frame, then completely unreadable in another. That’s simply because the encoder skipped or heavily compressed that region. CTU analysis can explain why this happens, helping you decide whether restoration is even possible.

Amped Software developed the tool because you need more than just visual clarity, you need data integrity. The CTU filter allows you to:
The CTU filter empowers you to assess whether an image is trustworthy, explains why detail may be missing, and supports your analysis with visual proof.
In forensic video analysis, knowing how data was captured is as important as the data itself. Use the CTU filter in Amped FIVE to reveal the invisible structure behind every frame.
This article only scratches the surface, to get deeper into the theory behind CTU analysis, read the full blog post.

The latest version of Oxygen Analytic Center has been released!
Oxygen Analytic Center brings together cutting-edge tools for streamlined digital investigation. Effortlessly review vast data sets with real-time collaboration, automate key workflows, and unlock deeper insights through advanced analytics. From customizable dashboards to secure, cloud-based access, Oxygen Analytic Center equips your team with everything needed to work smarter and faster.
The release of Oxygen Analytic Center v.1.5 includes:
Oxygen Analytic Center v.1.5 introduces the Device Dashboard, a centralized display where users can easily access detailed device information through clickable links, enabling fast navigation to key artifacts.
This dashboard’s pre-configured filters streamline the review process, reduce manual effort, and surface critical information quickly. The use of clickable elements enhances navigation and significantly improves the user experience.
Access to the software can now be secured using Two-Factor Authentication (2FA). Administrators can enable this option by selecting specific users or departments to which it is applied.
This feature adds an extra layer of security, helping protect access to sensitive data and enhancing overall system integrity.
We’ve made numerous UX improvements to the left sidebar and enhanced the overall usability of the software.
These improvements will make navigation more intuitive and efficient, especially within the left sidebar. Users will experience smoother interactions and a more consistent overall experience across the software.
If you use Oxygen Analytic Center, check out our Release Notes for a full list of updates.
If you are not yet a customer and are interested in seeing these enhancements in Oxygen Analytic Center v.1.5, contact us to make arrangements.
Oxygen Forensics is a global leader in digital forensics software, enabling law enforcement, government agencies, enterprises, law firms, and service providers to gain critical insights into their data faster than ever before. Specializing in remote and onsite access to digital data from cloud services, mobile and IoT devices, drones, device backups, UICC, and media cards, Oxygen Forensics provides the most advanced digital forensics data extraction capabilities, innovative analytics tools, and seamless collaborative analysis for criminal and corporate investigations to bring insight and truth to data.
# # #
Want to share an investigation with us?
We’d love to hear how our software supported you in solving your investigation. Please contact us at marketing@oxygenforensics.com

UK police forces are implementing Project Odyssey, a new digital forensics approach that extracts only relevant data from victims’ phones in three hours instead of keeping devices for months. The technology uses time-slicing techniques and involves victims in real-time approval of data extraction, addressing concerns about “digital strip-searches” that previously deterred survivors from seeking justice.
Read more (emergencyservicestimes.com)
Forensic experts demonstrate new capabilities in Amped Authenticate for identifying synthetic media and manipulated images. The webinar showcases advanced detection methods including metadata analysis, reflection consistency checks, shadow analysis, and compression pattern examination to combat increasingly sophisticated deepfakes and AI-generated content.
Dutch researchers at the Netherlands Forensic Institute have developed a new technique to identify deepfake videos by analyzing subtle facial color changes caused by heartbeat-induced blood flow. The method detects minute shifts in skin tone around the eyes, forehead, and jaw that occur with each heartbeat—biological signals absent in AI-generated deepfake content. While still undergoing scientific validation, the breakthrough adds to existing forensic tools for combating increasingly sophisticated manipulated media.
Cross-platform file transfers via SMB shares between macOS Sequoia and Windows 11 cause significant timestamp alterations that vary by file type, operation method, and host operating system. The research reveals that some forensic tools may show null timestamps due to Windows storing file attributes across multiple MFT entries, requiring investigators to examine base file records for complete timestamp data.
Read more (forensicatorjourney.gitbook.io)
Apple introduces significant updates to the iOS Unified Logs command in macOS 15.5, including a new ‘log repack’ option that creates filtered log archives from existing ones. The log collect command now supports predicate filtering, while log stats gains the ability to use date ranges with the –end option, enabling faster and more accurate forensic analysis of iOS device logs.
Read more (ios-unifiedlogs.com)
Forensics Europe Expo returns to Olympia London on June 18-19, 2025, for its 12th year with a focus on digital forensics, AI-driven investigations, and emerging technologies. The event co-locates with The Blue Light Show for the first time, creating an expanded platform for collaboration between law enforcement, government agencies, and emergency services. Sessions will cover topics including autonomous digital investigation technology, 3D crime scene reconstruction, voice data analysis, and AI forensics implications.
Apple’s newest operating system updates across iOS, macOS, watchOS, iPadOS, and visionOS introduce several potential forensic artifacts that could aid criminal investigations. Key features include AI-enhanced location tracking, improved metadata indexing, enhanced health data from wearables, visual search capabilities that embed geolocation data, and live translation services that may store spoken conversations.
Security experts identify three major Android malware threats emerging in 2025: embedded firmware-level malware in budget smartphones, evolved banking trojans with full surveillance capabilities, and NFC-relay fraud targeting contactless payments. These threats exploit Android’s open architecture and widespread adoption, with malware-as-a-service models making sophisticated attacks accessible to novice cybercriminals.

The latest version of Oxygen Remote Explorer has been released!
Oxygen Remote Explorer revolutionizes the way businesses collect critical digital evidence. Whether investigating incidents remotely or onsite, our tool provides powerful, targeted data collection and analytic capabilities designed for efficiency and accuracy. With features like automated task scheduling and comprehensive data access, you can ensure no detail is overlooked – no matter where the evidence resides.
The release of Oxygen Remote Explorer v.1.8.1 includes:
Users can now perform remote Chrome data collection using the Android Agent that works over any mobile network or Wi-Fi regardless of location. Chrome is a widely used browser, so remotely collecting its data can provide investigators with comprehensive evidence while eliminating travel costs.
It is now possible to remotely collect Discord data from Android devices via mobile network or Wi-Fi regardless of location. Discord data collection is crucial in corporate investigations as it can reveal unauthorized communications, data leaks, or insider threats occurring outside official channels. By collecting the data remotely, organizations can avoid travel expenses and gather data much faster.
We have added the ability to show Remote Explorer Agent progress and collection steps on Windows and macOS endpoints. This feature is valuable when conducting collections as it introduces a layer of transparency that is not available in traditional, covert extraction flows. This update allows for better time management and early detection of issues such as collection failures or endpoint-side disruptions.
Now users can also delete any of the previously added endpoints along with the data associated with them. This feature helps free up storage and server resources, reduces clutter by keeping only active endpoints visible, and permanently removes sensitive client information after a collection or investigation is complete – supporting data privacy and client trust.
If you use Oxygen Remote Explorer, refer to the “What’s New” file in the “Options” menu or check out our Release Notes for a full list of updates.
If you are not yet a customer and are interested in seeing these enhancements in Oxygen Remote Explorer v.1.8.1, contact us to make arrangements.
Oxygen Forensics is a global leader in digital forensics software, enabling law enforcement, government agencies, enterprises, law firms, and service providers to gain critical insights into their data faster than ever before. Specializing in remote and onsite access to digital data from cloud services, mobile and IoT devices, drones, device backups, UICC, and media cards, Oxygen Forensics provides the most advanced digital forensics data extraction capabilities, innovative analytics tools, and seamless collaborative analysis for criminal and corporate investigations to bring insight and truth to data.
# # #
Want to share an investigation with us?
We’d love to hear how our software supported you in solving your investigation. Please contact us at marketing@oxygenforensics.com

The following transcript was generated by AI and may contain inaccuracies.
Massimo Iuliani: Welcome everybody. Just a few words about me before starting. I’m not an engineer, but I studied mathematics and have a different theoretical background. I’ve worked extensively in image and video authentication topics. I worked with the University of Florence for several years on projects funded by the European Commission and DARPA, all related to authentication and reverse engineering of multimedia content.
Being in the university, I worked extensively in research and I’m co-author of several papers in peer-reviewed journals related to multimedia forensics in general. I also have experience as an expert witness in multimedia forensics in Italy. I think this was really useful for me because I was able to look at different points of view since this topic brings together scientific research and very technical issues, along with the need for people to understand and use these tools and explain them in an easy way.
Before starting, I’d like to explain why we’re making this webinar. The main issue is related to the spreading of these new technologies that allow people to create good manipulations, even if you’re not an expert. You can use text-to-image tools, ask for anything, create good manipulations, and edit specific pieces of images to create very realistic manipulations. On the other side, we really rely on our eyes and our senses to determine what is real and what is not.
Based on our experience and some tests we’ve been conducting, we’ve noticed that people are not very good at determining what is real and what is fake. Just to give you an example, here we have a couple of images. If you want to guess which is real and which is fake, you can try answering in the chat to share your thoughts. We can now create highly realistic images, but sometimes we can make confusion between what seems synthetic and what simply has high resolution or high detail.
Take 10 seconds to try to guess, and then we’ll see another example to build the case for why we need several tools available to determine what is real and what is fake. I see there are some answers in chat. One is real, one is fake, and don’t worry if you made a mistake because we don’t expect people to be able to guess correctly.
Let me give another example to have fun and understand how our brain works when trying to determine what is fake and what is real. We are Italian, so we like to eat good food and drink good coffee. We also need to take lots of pictures to invite you to drink and eat in our restaurants. Again, you can try to determine if they’re real or fake. I understand they look good.
We don’t really need to understand now if we are good at this or not, because these are just samples. But I think it’s good to understand how our brain works when we try to say, “Is this coffee real or is it fake?” How do we decide? Do we decide based on quality, details, resolution, contrast, or something else? As you can see, we can have very different opinions and we take time to decide. In this case, unfortunately, they are both fake. I’m sorry because they look very good.
These examples are just to show you that it’s very hard. We conducted a big test on this with 20 images, asking people—we don’t care if they are naive or extremely expert in multimedia forensics—to choose whether the image is real or not, just based on visual analysis. Here’s the result we achieved so far. As you can see, we have results from zero to 20 correct guesses, and the distribution shows that on average people get 10 out of 20, meaning half the results are correct. So it’s like flipping a coin.
This means that unfortunately, we are not very good at determining what is real and what is fake. If you think you can do something better, we would really appreciate if you can try the test and see if you can achieve better results. You can scan this QR code, or maybe Michelle can share the link in the chat. You can take the test—it’s completely anonymous and will only store the score. Of course, we’ll provide you with your score.
It’s good to understand how good we are, and the truth is that we are not good at this task. That’s why this is our starting point: we are not good at determining what is real and what is fake. This webinar will show some new techniques that can be used to authenticate images. Since this topic is very complex, we also need some background information, so we need to show at least the basics and principles of how we work in image authentication for different cases. Then we’ll open Amped Authenticate and see examples in practice.
Of course, we will not go into all the details. I will try to find the balance between explaining the basics and principles, but we cannot go too much into detail because there’s a full week-long course on these topics. We’ll try to find the balance. Furthermore, we will see how to combine different tools to provide lots of information related to the image lifecycle, and we’ll also see how to describe and properly interpret some results that we can achieve from our forensic analysis.
Please feel free—as Michelle was saying—if something is not clear, if you’re curious, or if you want to share your experience on some topics like this, you can use the chat. Don’t worry, I will try to answer at the end.
Massimo Iuliani: What is the main forensic principle when we take a look at an image? If we are naive, we just look at the image content—the visual content of the image. But if we are forensic experts, we need to remember that behind the image there is a huge amount of information. The image, first of all, is a file—a digital file that has a container. It’s a package of data, and this package contains data in a structured way depending on the type of file.
Furthermore, within this package that we can imagine like a box containing things, we need a list of information related to the data, and these are the metadata. It’s like textual information related to the image content. For instance, if we acquire with a specific camera, we expect to find in this textual information the brand, the model, the acquisition date, maybe GPS coordinates, technical specifications of the lens, the firmware—lots of information that can be used to analyze the image and check the consistency between this metadata and the image content.
Then we have some more advanced information called coding information, which is what our computer needs to decode the image and read it. Image pixels are generally not stored as raw data, but we encode them in a specific way. When we double-click with our mouse, the data are decoded based on the coding information to show the image. This coding information can be customized based on the brand, model, or specific software used, so they can leave huge and relevant traces to understand the image lifecycle.
Finally, last but not least, we have the pixels—not the decoded pixels, but the encoded pixels. So it’s a data stream that is encoded based on the coding information. We have lots of information available to analyze the image. So how can we use them when we have a malevolent user that tries to edit or synthetically create a digital image?
What happens is that all this data can be modified, can be partially created, or can be partially deleted. For instance, if you modify an image with software, some metadata will be changed. If you create an image with an AI-based system, some metadata can be created based on the system you’re using. If you manipulate an image with standard software or AI-based software, afterward you need to save the image again, so you are altering the coding properties and compression parameters of the image.
Furthermore, if you modify some specific portion of the image—for instance, if you want to remove a part or an object, or you want to modify a face—you are altering the pixel statistics. When you acquire an image, the process of acquisition introduces several correlations among pixels. When you modify a portion of the image, you are altering, removing, or adding some specific artifacts or patterns. You can add correlations, remove correlations, remove sensor patterns, and so on.
Furthermore, even if we exclude digitalization and focus on the digital domain, we have to remember that an image is a 2D representation of a 3D scene. When we acquire a 3D scene onto an image, we apply some projective transformations that are subject to geometrical rules. We expect that some shapes must satisfy some rules. Shadows must be consistent according to specific rules that link the light source with the cast shadows, reflections must be consistent, perspectives must be consistent. Similarly to the previous examples we made, we are not very good at determining if the perspective is correct or if the lighting is consistent.
So we have a big world of things that we can analyze. Rather than taking a look at all these things, we’ll start from some quick cases. We will touch on some advanced tools that we released in Amped Authenticate, together with other available tools that can be combined with them to provide much more reliable information and findings on the image.
Massimo Iuliani: Let’s start. Let’s suppose that this image is provided, and this image is supposed to show a famous person at a specific moment in time. We want to use this image as evidence that this specific person was there at that specific moment. Let’s try to analyze it and determine which tools we need to use in this case.
We’d like to understand if the image is native and reliable in content—meaning it hasn’t been modified. We want to check if the metadata are reliable, so we can verify, for instance, if the image is expected to be captured from a specific camera and we see in the metadata that we will find that specific camera. Then we expect that if the image is native, we expect a specific resolution, some specific metadata, creation date, modified date, compression schemes that must be consistent with the specific brand and model, and a specific file structure from that brand and manufacturer.
How can we analyze this? Of course, we cannot have the experience of knowing all these details for all models. In Amped Authenticate, we can exploit two tools. One is to use an internal database—we have more than 14,000 images belonging to different models and reference cameras that can be compared with the questioned images. We can also use external services to download images and filter those images based on some parameters of our questioned image, to find images that should have the same structure as the questioned image, and then we can make decisions.
Let’s try. We’ll open Amped Authenticate and load our first image. Let’s go and check immediately the metadata. I go to the metadata and I can see clear traces of expected original metadata. For instance, I can find specifications of the lens, which means this belongs to an iPhone 13, and we see that this image is full of metadata.
We can also check, for instance, if the modified date and the created date are the same. As you can see here, the modify date is the same as the create date. The image is supposed to belong to an iPhone 13, so metadata seems to be consistent with a native image. But let’s go deeper.
For instance, let’s take a look at the thumbnail. We know that when you save an image, within the image itself we save other small images that can be useful when, for instance, on our computer we need to see the preview of the image. So you don’t need to decode the whole image—you have these smaller images that can be decoded for the thumbnail preview. Let’s check the thumbnail of this image. If I check this thumbnail, I can see that the content of the thumbnail that is supposed to be the same as the image content is very different.
I think this is a huge problem for the integrity of this image. Maybe the only check I would do is to verify if this could be a bug of the software. Something I can do is download through—for instance, in Amped Authenticate we can download similar images from Flickr and Camera Forensics belonging to the same model to see if this may happen. I already did this and found a few of these images, so I can load them as reference.
I can see, for instance, that in this case I have a thumbnail, and the thumbnail of course has the same content. Then I can compare the metadata again, but I don’t find something really strange. There are a few differences that should be explained, but the problem is not clear. I can do something else. If I check the EXIF data, I also notice that we have GPS coordinates, so I can try to see where this image has been taken.
It’s easy with Amped Authenticate because I can go to tools and show image location on Google Maps. I can see that this image has been captured here—we are at Budapest, so we can go here with Street View. Now this suggests something to me because if I look at the thumbnail, it seems that the content is very similar.
Let’s open again, let’s open the thumbnail, and maybe I can remove this image and I can see that here I have a river, maybe here I have a bridge, and here some stone—I don’t know what, maybe a statue. If I check again, I can see that I have the river, the bridge, and possibly the statue. In this case, I verify that the GPS coordinates and the metadata are strongly consistent with the thumbnail, so this hidden content that is very different from the original content.
This result, in my opinion, at least based on my expertise, strongly supports the hypothesis that the image is not reliable at all. One explanation could be that we took an image, then we copied the metadata of another original image onto the questioned image, but by mistake we also copied the thumbnail. This would justify the fact that the GPS coordinates of the metadata are strongly consistent with the thumbnail rather than with the image content.
This is just an example of how we can combine several tools, even available tools, to determine if an image has been modified or not. In this case, we noticed that the model was compatible with some metadata that we found, we saw that the thumbnail content is different from the image content, and we verified that the GPS location was consistent with the thumbnail rather than with the image content. So we can say that the image is unreliable.
Massimo Iuliani: Let’s move to another case in which we try to combine available Amped Authenticate technologies with new interesting tools. Let’s say that now the question is very clear and very trendy: Is this image synthetic or is it authentic? How can we work? The dream of everybody is to have a tool where you can drag and drop the image and the tool will say, “Don’t worry, it’s synthetically generated. Period.” And you’re done. Unfortunately, it can’t work like that for several reasons.
But we can certainly use a deepfake detector to determine if there are some compatibilities in the low-level traces of the image. We can determine if we can find the footprint of some synthetic generation models. This is one key point, but there is also another point. We have reflections. Reflections are a very peculiar thing to find in an image, and based on what we were saying, this reflection must satisfy some geometric rules.
I’ll try to explain in one slide which is the principle. This is an image—an original image with an original reflection. What happens? Let’s take a look at this drawing here. We have an object that is reflected through a mirror. When you look at something through a mirror, it seems that the object is on the other side of the mirror at the same distance from the mirror. If you connect any point of the object with its mirror part, you will have lines that are all parallel because they are all orthogonal to the mirror.
When you acquire these parallel lines through your camera sensor, you have that the parallel lines will converge in the image. For those of you who are familiar with vanishing points, this is very trivial. For those who are not familiar, please think about when you drive on the street—the lines on the street are parallel in the 3D world, but if you look at them with your eyes or in your image, you will see that these lines will converge. It’s exactly the same principle.
So you have parallel lines in the 3D world, but you have a vanishing point—converging lines in the image. You expect that in this image, for instance, if you connect the ear of the girl with the reflected ear, the line connecting these two points will intersect the reflection vanishing point. This means that if I connect several points with their reflections, all these lines will intersect at the vanishing point.
This is in theory in the analog world, but since here we are in the digital world, we have that we can select a point up or down, and maybe different experts choose slightly different points. How can we solve this issue in the forensic world to guarantee repeatability? We say, “Let’s consider this hair, the edge of the hair here. Then we’d like to connect this point with the corresponding reflection point of the hair, but which one?” We select a wedge—an interval—and this determines a wedge in which we should find the reflection vanishing point.
If we do this with several points with their reflections and we intersect all the wedges, in the end we expect that the intersection of all the wedges will contain the reflection vanishing point. Yes, this image is real—sorry, I’m reading the question. It’s real, it’s just to show how it works. Indeed, in this real image, the reflection vanishing point is contained in this yellow region.
If we find a wedge that is incompatible with the intersection of all the other wedges, this means that the image is unreliable because it does not satisfy the projective requirements. A long explanation to try it on this image. Here we have a couple of tools: one very advanced tool for diffusion model detection, the second model-based for detecting the consistency of reflections in an image, and then we can combine these results.
Let’s open the second image. First, let’s open the diffusion model deepfake detector. This tool is designed to detect images that are compatible with any of the most famous diffusion models, which is the most important technology to create deepfakes. We use it, and as you can see, the system is trained on some of the most famous diffusion model-based tools for generating images like Stable Diffusion, DALL-E, Midjourney, and Flux.
Here you have a result of compatibility with any of these models, plus of course “not compatible with a diffusion model.” Since these tools are data-driven, we must remember that if a new tool comes on the market and the detector is not still trained on it, maybe it is not able to detect that specific model. In this case, we expect that the image falls in the “not compatible with diffusion model” category, meaning that the image can be AI-based with some unknown models or can be real.
But in this case, fortunately, we see a very strong compatibility with Midjourney—it’s 0.97. We shouldn’t read this like a probability—it doesn’t mean 100%. But we can say that the tool is strongly confident that we have a huge compatibility between the questioned image and Midjourney. This is a huge clue. We’ll try to combine this with the reflection analysis, so we can open the reflection analysis.
I already started it, but we can do it together. We can restart the project. How does it work? Let’s say that we have some points that we can connect. I would say the lips, maybe the corner here of the lip. Let’s say from here, we can connect this—I don’t know—here, or maybe here. Let’s create a wedge like this.
Now we know that the vanishing reflection point should be somewhere in this wedge. Let’s do the same with other points. Maybe we can go with the eyes and start from the corner here of the eye. We can link—I don’t know—here or here. There is a question: “Is there a certain numerical range that we can trust?” Not exactly. This technology allows you to decide which is the range. If you’re unsure, you can do like this and say, “With this, I’m sure.”
Maybe we can delete this. That’s why we have wedges. So now I would say something here. I can show how to make this line because now we can choose another point. Let’s use this connection point here. I’m looking in the middle of the mouth, let’s say here. This point is the reflection of this point, but which exact point? To avoid misinterpretation, it is good to decide a wider wedge to be sure that the corresponding point is contained within it.
Now, as you can see, the system became unfeasible. Furthermore, I can keep adding points. For instance, if I select this point here, this should be connected to some point here, at some point on the external side of the ear. So maybe between here and here, but the system is already unfeasible.
Until we have a couple of points like this, we can see the feasible region, meaning that we expect the reflection vanishing point to be somewhere here. When we put too many constraints, if the image is real, we expect to have the intersection; otherwise we don’t. In this case, we can see that the reflection is technically speaking inconsistent.
This is a huge clue because although we have the deepfake detector that is sure, or almost sure, that this image is synthetically generated, if I have to go to court, on one side we have the tool that is very effective because it gives you the answer. But the inconsistency of the reflection is extremely powerful because it is model-based, it is easily explainable, and on this side is a stronger weapon to say that the image is inconsistent because it’s not data-driven, but it’s model-based.
Very useful to see how we could combine these new tools—one that is focused on AI detection, the other one that is more general, analyzes the physical inconsistency, but is also model-based and has a strong background. This specific tool—we made lots of tests, a formal description of the reflection inconsistency analysis, and these results are published also in a paper that you can find in the slides where we also discovered that different synthetic generation models have different capabilities in generating consistent shadows and reflections. So the answer is that yes, it’s fake.
Just to summarize what we understood on this example: AI-based tools, like physical-based tools, cannot really provide a probability. It’s up to our expertise to combine the results and decide which is the weight in deciding the answer. Furthermore, especially for the data-driven tools, we have to remember that if you’re taking an image from the wild, from anywhere, we should consider that the AI-based tool—the data-driven tool in general—can lack some information.
We should take care in using these results in general, while the physical-based tool is extremely effective, independent of compression, independent of the image lifecycle. If you find any inconsistency, it’s a physical inconsistency—it’s model-based, so boom, you are done. Even if it’s more generic—you cannot say it is generated with Midjourney—different tools provide different information that can be combined for an overall result.
This is just a note that we’d like to share because it’s important to be informed when we use any data-driven tools. Remember that when you have numbers that describe a confidence or a compatibility that is the output of a tool, they cannot be generally linked to probability. If we have a tool that provides 0.99, it doesn’t mean that we have a probability almost one of something. The short answer is that we can never link this output to probability.
If you’re curious, we had a long webinar on this, so you can scan this QR code and take a look at it. It is generally recommended when we use any tools to use compatibility-related words rather than probability terms to avoid misleading results and sometimes also big mistakes. The tools work well—we have to work well also in the interpretation.
Massimo Iuliani: Let’s make another example. In this case, I would like to start from the ground truth, so we see how the manipulation is built, and then we see how to detect it. I think this is really interesting because it is good to see also how images can be created to create a really realistic manipulation.
Let’s use a text-to-image tool, which means that you have a prompt, you put a prompt and say “please imagine this,” and the tool provides you the image. I want to imagine a group of refugees facing the sun, and here’s the result. But now let’s say I want to modify the information within this image, so I’m not satisfied, and I add the prompt: “Please add a tent in the upper left corner of the image.” And the tool adds the tent.
I’m not satisfied yet, maybe with the identity of the person in the center, so I ask, “Please add a woman in the middle with a different dress.” And boom. Now this is the fake image. We don’t care exactly what we’d like to explain with this image. How can we analyze this? Of course, by using a deepfake detector, but also in this case I can notice that we have shadows. Here you can see these people with cast shadows, and also the woman has a cast shadow here.
Can we again combine deepfake detectors with shadow analysis? Let’s go and check this out. Again, I will try in one slide to explain how this works. The main principle is that if we have a light source and then we have objects, the cast shadows are built in a specific way. If you connect the light source with any point, the connecting line will also intersect the corresponding point of the cast shadow.
Why is this very useful? Because if you link a point with its corresponding point of the cast shadow, the line will also intersect the light source. If you do this with several points and their corresponding cast shadows, in the end you expect that their intersection in a real image will intersect at the light source.
This is a very trivial case in which we connect cast shadows with the corresponding points, and as you can see, we almost get the light source. This is useful similarly to reflection because it is explainable, it is model-based, and it’s also immune to compression because even if you have a very low resolution image or strongly compressed image, this is a geometrical property. This means that it still stands after the compression.
Let’s make an example of how it can be used to detect the fakes. For instance, if you have a real image, again, similarly to reflection, we’re not using lines, but we are using wedges to avoid misinterpretation or disagreement among experts. Here you can see that the region contains the light source.
Let’s take this Midjourney image. If we consider the people and their corresponding cast shadows, if you intersect the wedges, you can find an intersection. So in some way, Midjourney is creating a sort of consistency in this image between shadows. Fortunately, Midjourney still doesn’t know that the light source should be in this intersection, so in this case we can conclude that the image is not reliable.
In this case, I’m not opening Amped Authenticate to save a bit of time, but if you analyze the cast shadows—you create the wedges here and here—you will find that there is no region. Again, in this case we have two different tools: the physical-based tool that is saying the image is not reliable, plus the deepfake detection tool that is saying that the image is a deepfake.
Maybe we can check what Amped Authenticate says about this image. As you can see, the image is strongly compressed here. I think this is not the original image, but it’s a recompressed version. Let’s see if we are lucky, meaning that Amped Authenticate still finds traces of synthetically generated images. As you can see, it finds high compatibility with Flux.
So on one side we have a strong hint that the image is synthetically generated or manipulated, together with a model-based tool that is strongly effective in giving reliability to your results. I see a long question—maybe I will read it later. Is that okay for you? A lot of questions. Please give me some minutes so I will close and then we’ll try to answer them.
Since this webinar is more designed to understand how we can use tools and advanced tools, if you want, you can check on the blog for other tricks to spot deepfakes. You can scan this QR code because there are several bugs that can allow us to detect if an image is generated by a specific architecture because they have some specific defects.
Massimo Iuliani: Let’s make one last example that is related to checking integrity of an image. We have this image and we are asked to determine if the image is camera native or it has been processed in some way. Is the content reliable or not? Again, here I would like to show you another advanced but very generic tool.
We need another piece of theory that we’ll try to summarize in one slide. When you acquire an image—when you click on your smartphone—several things happen in your camera. The 3D world passes through the lenses, the optical filter, a color selection pattern. Then the image is digitalized, so we have sampling, we have interpolation of the colors, we have in-camera software processing, we have a specific compression pattern, we add specific metadata and so on. In the end we have our image.
Why is this important? Because all these pieces leave specific clues in the digital image that can be used to verify if the image is native or not. If the image is native and it has never been touched, we expect to find exactly those traces. If you modify the image in any way, you will apply some additional processing. For instance, you remove something, so you’re changing the statistics there, or you are resampling the image, or you are adding things, or you’re cloning things in the image, or you’re changing a face.
So you’re processing a part of the image, changing the statistics of the pixels, changing maybe the perspective if you’re changing the position of some objects. Then you need to save the image again, meaning that you’re applying further compression to the image. This means that you are partially deleting the traces of the original image and you are adding some specific clues that are related to your processing and to the manipulation itself.
During this process, we delete original traces and we add some other traces. This is extremely useful to check the image integrity, especially because if you manipulate an image and you compress it again, you have an image that has been subjected to compression because you acquired it, then manipulation, then compression. When you have a manipulation between two compressions, we don’t care if you use the most reliable and effective AI-based tools—there are some technologies that allow you to spot it independent of the technology.
Let’s check how it works. Let’s open Amped Authenticate and let’s load this last example. Of course we can try to visually analyze this image. I see here something strange, but I don’t rely on my eyes. First of all, we go to the metadata. First, the file format and Amped Authenticate quickly give me some hints on where to start.
The first thing to be noticed is that the create date is different from the modified date. This is immediately a hint that the image is not native, but we know metadata can be unreliable. But let’s start from here. Then we see that the image is expected to belong to a Google Pixel 7A. We have an unexpected compression scheme.
Let’s open the compression schemes. Here, Amped Authenticate provides, based on the database that we have available, which compression schemes are compatible with the one of the questioned image. We have thousands of images belonging to several models, and we find compatibility in the compression scheme between the questioned image and these models here.
As you can see, we can also find here a Google Pixel—a Google Pixel 4 XL. We don’t have in the database Google Pixel 7A yet, but it seems that the compression scheme is compatible with the Google Pixel. So the compression is compatible with the Google Pixel, but the image has been processed after the acquisition. What could be the reason?
Let’s take a look at the metadata. Of course, the analysis could be longer if you don’t know where to look. Let’s take a look at the metadata and—oh, here I see “Edited with Google AI.” So this is a hint that either within the camera or after the modification, the image has been processed in some way. We don’t know exactly what happened, but we have now two hints that the image has been processed.
Maybe it has been processed with Google AI, we don’t know, but if it has been processed after the acquisition, it means that the image has been compressed twice. If it has been compressed twice, we expect to find some anomalies. Of course, we would need the full course to understand which anomalies we should find, but I will show you and quickly explain.
When we look at an image in the frequency domain, we can see this kind of plot. When the image is compressed twice, we expect that this plot exposes peaks and valleys like here. As you can see, we have peaks, valleys, peaks, valleys. So it’s exactly what I expect when I see an image that has been compressed twice. This is another strong hint that the image has been compressed twice.
So we are building the story: the image has been acquired, then since the modified date is after the create date, it means that something happened, maybe with Google AI because we’re reading the metadata, and then the image has been compressed again. So we have two compressions, and this is confirmed by the analysis of this DCT plot.
If it has been manipulated in the middle, we can use a tool that localizes manipulation when an image has been compressed twice. Remember, I don’t care if you used AI or not, because this tool analyzes the inconsistency between the two compressions. It is robust to any AI technology in this sense. Let’s try to use it—it’s the ADQ JPEG tool.
Boom. Very clear. We can find a piece of the image with a compression scheme that is completely inconsistent with the rest of the image. If we swap—now, maybe now that I have the hint of the software, maybe I can go and visually see if I see something strange. I have to say that visually speaking, I cannot see—yeah, maybe here I can see some traces of compression, some edge, some strange edge. But I couldn’t say that this is manipulated from these edges.
But fortunately, this tool that is very effective, especially when the compression quality is high, exposed that the image has been likely processed in this part. Again, here we combine things to reach an explanation of the lifecycle of the image.
Just to summarize, we analyzed metadata and saw that Google AI was used and that the image was modified because we have a modified date after creation date. The frequency analysis revealed traces of double compression, and then the manipulation was detected through the ADQ JPEG tool. We also found the original image, and as you can see, we have this thing here.
This case is very interesting because we were able to determine even a small manipulation. This is not always the case—of course, it depends on several factors. In this case, the manipulation was made after the acquisition through some internal software within the smartphone. We didn’t go outside of the smartphone, but please remember that we’re starting to see that AI processing sometimes happens inside the camera.
Within your click, you also have some AI-based processing. That’s why we shouldn’t rely only on tools, but we also have to use our knowledge to understand the background information and see what to expect.
I’ll just give you a couple of examples. One is this Samsung phone that uses super resolution and scene optimizer where you get an image like this that you see here, but then the optimizer provides a very detailed image. Are these details real? Who knows? It’s not the topic of this webinar, but it’s something that we should consider with attention.
Another clear example is again Samsung Galaxy S21 S23 with this remastering feature. We got this picture and then the tongue was changed into teeth. Of course this is a change of the meaning of the content, but the image technically speaking is camera native. What is the boundary between integrity and authenticity? It’s something we should consider because this boundary is getting thinner and thinner.
Massimo Iuliani: Just to summarize what we did, we analyzed a number of cases, and we saw that each case required some specific weapons. Fortunately, Amped Authenticate is well equipped and we keep updating it with the most advanced tools. We saw cases in which, for instance, we found inconsistencies between the metadata and the image content because we had hidden content with GPS coordinates that were consistent with the hidden content but not related to the image content.
We saw cases in which deepfake detectors can be used and combined with physical-based detectors to spot that the image is completely unreliable because they were synthetically generated and manipulated. We also saw that format analysis in the last case could reveal AI traces and we could also spot the manipulation. I think it’s important to note that the last case was very useful because we used a tool that is not explicitly designed for AI to detect AI, but can detect any manipulation—AI-based or not—when the manipulation is done within compression.
So it can be used in several cases. If you are thinking, “Do I really need all this technology?” If you didn’t make it yet, do the deepfake detection test, try to visually detect deepfakes, and then if you get 20 out of 20, yes, you are our expert. Thank you very much.

A round-up of this week’s digital forensics news and views:
Magnet Forensics introduces Magnet One Process, a cloud-based processing engine for digital investigations, alongside Mobile Case Stream that delivers real-time mobile evidence to investigative teams. The platform combines case management, secure storage, and review capabilities, reducing time-to-evidence from weeks to minutes. The new features are currently in beta and will be widely available later in 2025.
The Scientific Working Group on Digital Evidence (SWGDE) has published a comprehensive guide on digital image compression and file formats. The resource helps forensic professionals understand compression techniques, navigate various file types, and maintain evidence integrity through solid technical knowledge of digital images.
Scotland’s victim identification officers work tirelessly examining disturbing images to identify child abuse victims. Detective Constable David Murray and his team now identify nearly 400 victims annually, 90% from Scotland, compared to 25-30 victims four years ago. Despite the emotional toll, officers find purpose in safeguarding children from further harm through their work identifying victims from seized devices.
The Tackling Organised Exploitation Programme announces the launch of TOEX DART, a new Data Analysis & Review Tool designed to help investigators process large volumes of digital phone data. The application enables quick upload of phone extractions and provides high-level summaries to identify patterns and connections, becoming the seventh tool in the TOEX Capabilities Environment.
Read more (toexprogramme.co.uk)
Cyberly is an innovative fictional city created by Sherfox Labs to teach digital forensics in a safe, engaging environment. Complete with its own infrastructure, characters, and smart technology, this imaginary world allows students to practice investigative skills without the ethical concerns of using real cases. The city features organizations like the B.Y.T.E. Detective Agency and Villainous Ventures Inc., creating a rich context for students to develop practical skills while maintaining an element of humor.
Read more (blog.sarahmorris.prof)
Forensic video analyst Brandon Epstein argues that algorithmic deepfake detection tools for online media consistently fail in real-world conditions. According to the TRIED benchmark report, these detection methods are unreliable due to re-encoding issues, poor media quality, and frequent ‘undetermined’ results. Epstein advocates shifting from deepfake detection to media authentication, where content creators provide original media and provenance claims for expert verification.
LogTap offers a comprehensive browser-based solution for security log analysis without requiring server uploads or software installation. The tool features on-the-fly data shaping, a powerful scanning engine that uses SuperSQL queries and regular expressions, timeline visualization for event frequency analysis, and graphical mapping of lateral movement. Running entirely client-side through WebAssembly, LogTap enables security analysts to efficiently process sensitive log data, particularly in restrictive SOC environments.
Investigators at CCL examine how AI companion chatbots like PolyBuzz store data on Android devices. The analysis reveals that these apps use WebView and Volley technologies to cache conversations, character images, and API responses. These cached artifacts provide valuable forensic evidence about user interactions, including prompts used to generate AI characters and conversation fragments.
Read more (cclsolutionsgroup.com)
Fuji, an open-source forensic tool by Andrea Lazzarotto, enables logical data acquisition from Macs using three native macOS utilities. The tool provides ASR (Apple System Restore) for volume collection, Rsync for directory collection, and Sysdiagnose for system data and Unified Logs that are converted to an SQLite database. Fuji’s user-friendly interface helps examiners avoid common mistakes during data collection while preserving metadata and Apple Extended Attributes.

Magnet Forensics unveils pioneering cloud-powered processing for Magnet One, along with instant time-to-evidence for investigators at Techno Security East 2025.
Magnet Forensics today announced transformative new updates to the Magnet One platform: Magnet One Process, a next-generation cloud processing engine, and Magnet One Mobile Case Stream that, for the first time ever, puts critical mobile evidence at the fingertips of investigative teams in real-time.
Magnet One, the groundbreaking digital investigations platform that fuses the unstoppable power of the cloud with cutting edge AI, empowers investigative teams to analyze and collaborate in real-time so they can close cases faster and keep their communities safer. And now, with the addition of Magnet One Process, Magnet One has taken a pioneering leap forward by delivering the industry’s first complete digital investigations platform that marries advanced case management, secure storage, and enhanced case review with the power of a cloud-based processing engine, providing all members of the investigative team – examiners, investigators, prosecutors and agency leadership – with an investigative edge.
Leveraging Magnet Forensics’ proven leadership in digital evidence processing, Magnet One Process enables agencies to process evidence with unprecedented speed, scale, and precision – supercharging investigations with seamless forensics workflows while freeing up valuable time and resources in the lab.
The addition of Magnet One Process to Magnet One unlocks a new set of user experiences – Case Streams – that amplify the critical work of digital forensics teams with transformative workflows that will help shape a smarter future for digital investigations across the agency.
And today, Magnet Forensics is unveiling Magnet One Mobile Case Stream, the groundbreaking mobile forensics experience that turns mobile devices into instant sources of truth by uncovering critical mobile evidence in real-time. Mobile Case Stream combines the power of the Magnet One platform with Magnet One Process, the unmatched mobile access capabilities of Magnet Graykey, and the seamless case collaboration of Magnet Review, to create a force multiplier built to accelerate every step of the mobile investigation.
With Mobile Case Stream, time to evidence is slashed from days—or even weeks—to minutes. Digital forensics labs can now get critical mobile evidence into the hands of investigative teams in real-time, unlocking key insights and actionable leads when they matter most—right at the start of a case.
“At Magnet Forensics, we’re passionate about delivering pioneering advancements to our digital investigations solutions that help ensure public safety agencies can seek justice and protect the innocent,” said Braden Thomas, Chief Product & Research Officer at Magnet Forensics. “When every second matters in an investigation, Magnet One, with the introduction of Magnet One Process and Mobile Case Stream, will provide game-changing capabilities that empower investigative teams to solve cases at the speed of crime”.
Magnet One Process and Mobile Case Stream are available now in a limited customer beta program and will be widely available later in 2025.
To get started with Magnet One for free today, please visit our website.
Founded in 2010, Magnet Forensics is a developer of digital investigation solutions that acquire, analyze, report on, and manage evidence from digital sources, including mobile devices, computers, IoT devices and cloud services. Magnet Forensics products are used by more than 5,000 public and private sector customers in over 90 countries and help investigators fight crime, protect assets, and guard national security.
For further information:
Rick Andrade

With over 2 billion monthly active users worldwide, Instagram has evolved far beyond a simple photo-sharing platform. It has become a primary communication channel—and unfortunately, a hunting ground for sophisticated cybercriminals. From elaborate romance scams targeting vulnerable seniors in the UK to organized cyberstalking networks terrorizing college campuses across the United States, criminals are increasingly exploiting Instagram’s Direct Message feature to execute complex, long-term schemes.
Instagram’s current architecture presents a significant limitation for forensic investigators. The platform implements a rolling storage mechanism that retains only the most recent 20 Direct Messages per conversation thread in standard device analysis scenarios.
Instagram’s “Download your information” feature provides a comprehensive alternative data acquisition method. This functionality generates complete archives containing:
At GMDSOFT, we’ve developed specialized capabilities within our MD-RED to analyze Instagram export data from both Android and iOS devices. Our solution bridges the gap between Instagram’s data export functionality and the practical needs of forensic investigators.
The difference between standard analysis and comprehensive Instagram data examination can be case-changing. Investigations that previously hit dead ends due to limited message visibility now have access to complete criminal communication records.
As social media platforms continue to evolve their data retention policies and technical architectures, forensic investigators must adapt their methodological approaches accordingly. The combination of Instagram’s data export functionality with specialized analysis tools like MD-RED provides a robust solution for overcoming current platform limitations. This approach not only addresses immediate investigative needs but also establishes a framework for comprehensive social media forensics that can adapt to future platform changes and emerging criminal methodologies.
Tech Letter Vol.11 provides detailed, step-by-step guidance on implementing Instagram DM analysis in your forensic workflow, including best practices for data export and analysis techniques. If you want to learn more about Instagram DM analysis, request the full tech letter on our website!

The latest update to our flagship solution is here, Oxygen Forensic® Detective v.17.3.
Users can now restrict access to privileged data by protecting it with a password. This feature is especially useful when certain evidence must remain hidden from investigators due to legal or procedural constraints. Allowing users to set a password helps ensure compliance while still enabling investigators to work effectively.
It is now possible to extract Line iCloud backup that stores contacts, private and group chats, private and group calls, and notifications. Moreover, we have improved support for Line Google backups. Adding this additional source of Line data can significantly enhance investigative capabilities.
Support for additional columns in AT&T Call Data Records (CDR) has been implemented, including fields such as Beamwidth, Sector, ECGI, ENB-ID, LAC, and CID. Moreover, the display of cell towers, as well as beam and sector widths, has been implemented in the Maps module. Predefined templates have been added to simplify the processing of CDR data. CDR analysis plays a crucial role in many investigations. This support expands investigators’ ability to analyze data.
Users can now enrich existing files in the software with supplementary data. A new Import Supplementary Data button has been added to the Files section, allowing users to upload CSV or TXT files. Each hash from the uploaded file is matched against the hashes in the extracted files. When a match is found, the related data is added to the corresponding file in the extraction. The result is more efficient and seamless investigations.
Selectively export data to OFBR backups choosing specific sections, applications, and time ranges in the Custom export settings. This update allows users to include only the necessary information, enhancing both flexibility and efficiency in your workflow.
If you use Oxygen Forensic® Detective, refer to the “What’s New” file in the “Options” menu for a full list of updates.
If you are not a customer and are interested in trying out Oxygen Forensic® Detective v.17.3, request a free trial.
Oxygen Forensics is a global leader in digital forensics software, enabling law enforcement, government agencies, enterprises, law firms, and service providers to gain critical insights into their data faster than ever before. Specializing in remote and onsite access to digital data from cloud services, mobile and IoT devices, drones, device backups, UICC, and media cards, Oxygen Forensics provides the most advanced digital forensics data extraction capabilities, innovative analytics tools, and seamless collaborative analysis for criminal and corporate investigations to bring insight and truth to data.
# # #
Want to share an investigation with us?
We’d love to hear from you and how our software supported you in solving your investigation. Please contact us at marketing@oxygenforensics.com.

A round-up of this week’s digital forensics news and views:
Forensics Europe Expo 2025 takes place on June 18-19 at Olympia London, co-located for the first time with The Blue Light Show. The event highlights cutting-edge developments in digital forensics, featuring sessions on AI-driven investigations, laser scanning, voice data analysis, and multimedia evidence integrity. World-class speakers from academia, law enforcement, and industry will present across multiple specialized tracks, with over 100 companies exhibiting the latest forensic technologies.
The Scientific Working Group on Digital Evidence (SWGDE) has released guidelines for the seizure and analysis of Internet of Things devices. The document covers identification of diverse IoT devices, preservation of volatile data, and effective analysis strategies to extract meaningful insights from complex IoT data formats.
A digital forensics and incident response management model (DFIRMM) has been developed to protect Internet of Things (IoT) systems used in agriculture. The model addresses unique security challenges in smart farming through four phases: pre-incident preparation, incident detection, post-incident response, and forensic investigation. Researchers demonstrated its effectiveness through a case study of MQTT-enabled agricultural networks under DoS/DDoS attacks.
A new free forensic tool called Arsenic is now available for investigators requiring quick results from iOS devices. The software combines extraction and analysis capabilities, working on both Windows and Apple Silicon systems to efficiently extract data from unlocked phones through iTunes backups and unified logs collection. Arsenic offers targeted analysis of specific files and innovative features like retrieving photos based on AI-classified content categories.
Read more (northloopconsulting.com)
A new forensic tool has been released for parsing iOS unified logs. The tool allows investigators to convert iOS logarchive files into searchable databases, drastically reducing investigation time. It includes features like date range filtering, custom parsing rules, and automatic categorization of logs into labeled activities such as battery usage, screen brightness changes, and device lock/unlock events. The tool runs on macOS and generates a comprehensive forensic report to verify data integrity.
Read more (ios-unifiedlogs.com)
Apple’s Unified Logs contain detailed artifacts about flashlight usage on iPhones, including brightness levels and how the flashlight was accessed. The logs indicate five different brightness levels ranging from 0 (off) to 1 (highest), and record when users toggle the flashlight via Control Center. These artifacts can provide valuable context for digital forensic investigations by confirming device usage during specific timeframes.
Read more (charpy4n6.blogspot.com)
Interpol’s Singapore innovation center serves as a hub where law enforcement officers develop techniques to counter sophisticated criminal strategies. The facility houses advanced technology including underwater drones, digital forensics tools, and robotic K9s to help police stay ahead in the technological arms race against organized crime. In recent years, AI has transformed criminal activities, with the lab now focusing on combating deepfake romance scams, sextortion, and advanced cyber threats.
Apple Unified Logs provide detailed pattern-of-life information on iOS devices, capturing data on device orientation, screen locks, app usage, and more. These logs can be extracted by connecting the device to a Mac and using terminal commands, employing third-party tools, or pulling files from a full system extraction. For analysis, logs should be converted to JSON format on a Mac before using iLEAPP to create a SQLite database that can be queried with DB Browser for SQLite.
Read more (abrignoni.blogspot.com)
Velociraptor allows investigators to perform forensic analysis on acquired disk images by emulating a live client. The tool supports various disk formats including EWF, VMDK, VHDX, and raw formats. After creating a remapping configuration file and launching Velociraptor with this config, investigators can interact with the disk image as if it were a live system, running hunts and examining the file system through the familiar interface.

Welcome to our brand-new webinar series — your go-to source for practical solutions to the most common and complex challenges in digital forensics — all in less than 20 minutes.
Each episode delivers expert insights, real-world use cases, and quick, practical tips to help you work smarter, faster, and more effectively. Don’t miss out — tune in and level up your digital forensics game.
Check out our most recent on-demand episodes:
In Episode 1, Keith Lockhart and Amanda Mahan walk you through how to filter data for relevance and create a powerful, portable platform for viewing, tagging, and reporting on key evidence.
Watch the full webinar to discover the flexibility you need to work cases anytime, anywhere.
In Episode 2, Keith Lockhart and Amanda Mahan deep dive into some lesser-known but incredibly powerful analytic features of Oxygen Forensic® Detective including extracting and even translating words from photos and videos.
Watch the full webinar to learn how much power lies in your photos and videos.
In Episode 3, Lina Phuong and Keith Lockhart explore the best approach to a disagreement between you and your software. Lina guides us in this one-of-a-kind conversation geared toward the continued commitment to forward progress for our users … one log at a time!
Watch the full webinar for exclusive insights from this unique conversation.
In Episode 4, Dan Dollarhide and Keith Lockhart delve into “Shortcuts to Nirvana” … a curated selection of tips and tricks that highlight the essential role of Oxygen Forensics technology, including:
Watch the full webinar for the complete discussion.
You can find these and more informative Oxygen Tech Bytes on-demand webinars here.

As the pace of technological change accelerates and threats evolve, the world of forensic science is undergoing a seismic transformation.
From AI-driven investigations to real-time data recovery and smarter emergency response coordination, Forensics Europe Expo (FEE) 2025 is set to bring the global forensics community together at Olympia London on 18-19 June.
Now in its 12th year, FEE 2025 promises to be a landmark event, co-located for the first time with The Blue Light Show, the UK’s only exhibition dedicated to emergency services interoperability.
This co-location creates a powerful platform for law enforcement, government agencies, academia and the private sector to collaborate, innovate, and shape the future of public safety and forensic investigation.
Thousands of delegates are preparing to attend this unmissable event, free to attend for those who register in advance.
Cybercrime, digital evidence and emerging technologies are now central to forensic investigation. Reflecting this shift, FEE 2025 will feature a strong emphasis on digital forensics, with a series of sessions designed to help professionals stay ahead of rapidly evolving threats.
Attendees can expect deep dives into topics such as:
These sessions provide real-world insight into the tools, techniques and technologies that will define the next generation of forensic investigation.
The FEE 2025 conference programme brings together a line-up of experts across academia, law enforcement and industry. Among this year’s high-profile speakers:
From traditional techniques to emerging science, these sessions offer a vital opportunity to learn, question and connect with the field’s most respected thinkers.
For the first time, Forensics Europe Expo will be co-located with The Blue Light Show, creating an expanded ecosystem of knowledge sharing and collaboration across emergency services.
This co-location reflects the growing emphasis on interoperability between frontline responders and forensic teams. FEE 2025 attendees will have full access to six theatres and five content streams at The Blue Light Show, including:
From police to fire, ambulance to rescue services, the show brings together the entire emergency response chain. It’s a chance to better understand how evidence and insights from forensics are being used in live, high-pressure scenarios and how closer collaboration can lead to faster decisions, smarter strategies and ultimately – saved lives.
Beyond the conference sessions, FEE and The Blue Light Show will feature over 100 exhibiting companies showcasing the latest innovations in:
Attendees will have the chance to evaluate new products, meet directly with suppliers and discover tools that can improve accuracy, efficiency and courtroom outcomes.
Join us 18-19 June 2025 at Olympia London for Forensics Europe Expo 2025.

Semantics 21, the UK-based pioneer of AI-driven digital forensics and safeguarding technology, proudly announces that Founder and CEO Dr Liam Owens has been awarded the Most Significant Contribution to the Global Response to Online Child Sexual Abuse accolade at the IPPPRI 2025 Excellence in Online Protection Awards, presented by Brandon Epstein from Magnet Forensics, Sam Lundrigan and Simon Bailey from IPPPRI, and Caroline Barnett from SAS.
In an industry where every second counts and the stakes are human lives, Dr Owens has become a recognised global leader in the protection of children from online and digital harm. His innovative vision and compassionate leadership have redefined what’s possible in digital investigations.

Dr Owens established Semantics 21 with a mission to empower frontline investigators to locate, identify, and rescue victims of child sexual abuse faster and with greater accuracy. His flagship platform, S21 LASERi-X , is acknowledged as one of the most advanced AI-powered forensic tools globally, used by thousands of government and law enforcement agencies. It has dramatically reduced case times and significantly increased the number of actionable leads—directly saving lives.
Additionally, under Dr Owens’ leadership, Semantics 21 created the Global Alliance Database, the world’s largest law enforcement child protection intelligence system, containing over 3 billion indexed records. The platform enables real-time international cooperation, secure intelligence sharing, and the automatic detection and removal of harmful content. Incredibly, it is provided entirely free to vetted law enforcement teams, demonstrating Semantics 21’s unwavering commitment to global child safeguarding.
A ground-breaking advocate for investigator mental health, Dr Owens made Semantics 21 the first company to integrate live wellbeing monitoring into digital forensic software. This innovation provides real-time alerts on emotional strain and workload fatigue, enabling managers to protect the wellbeing of investigators dealing with harrowing material.
Semantics 21 is the only company to have received both The Queen’s Award for Innovation and The King’s Award for Enterprise in Innovation. Beyond technical achievement, Dr Owens’ leadership has been defined by moral conviction: offering over £700,000 worth of licences free to underfunded child protection units and prioritising public safety and accessibility over profit.
The nomination praised Dr Owens as:
“A visionary, a leader, and a force for good… His work continues to set the benchmark for what is possible when cutting-edge technology meets uncompromising purpose.”
“This award belongs to my team and the global community of investigators and partners we serve,” said Dr Liam Owens. “At Semantics 21, we pride ourselves in being streamlined, but we are still mighty. Every child rescued makes every challenge worthwhile. Our message remains clear: Every Victim Matters.”
The team at Semantics 21 are becoming renowned for industry world-first and global leadership. Here are just a few of their achievements in the industry of digital forensics:
1. First Digital Forensics Company to Deploy AI for CSAM Detection
Pioneered the use of artificial intelligence to automatically detect child sexual abuse material in forensic workflows.
2. First AI Platform Built Specifically for CSAM Victim Identification
Designed from the ground up with law enforcement to prioritise victim-first workflows, not a generic AI repurposed for forensics.
3. First to Offer Integrated Object, Scene, Action, and Location Detection Offline
Includes over 70,000+ object types from weapons and vehicles to nudity, violence, and age estimation – all analysed within one offline tool.
4. First Multi-Modal AI Engine for Media Review
Combines image, video, audio, and text analysis into one seamless workflow for investigators.
5. First to Introduce AI Confidence Scoring for Investigative Triage
Empowers investigators to prioritise media review using system-generated confidence levels on key indicators.

6. First Scalable AI-Powered CCTV Review Tool Used in Riot Response
Adopted by UK forces to compress multi-year CCTV reviews into weeks.
7. First Automated School Badge Lookup System (UK, Ireland, Canada, Now USA)
Allows investigators to identify school affiliations from a uniform’s logo, even in complex media.
8. First AI-Based Location Prediction Tool for Victim and Suspect Location Identification
Uses scene cues to help determine likely geolocation without GPS data.

9. First and Only System to Track Investigator CSAM Exposure Levels
Provides real-time exposure data and a dedicated management portal for monitoring and safeguarding investigator wellbeing.
10. First to Introduce Wellbeing Feature to the Frontline Users
Enables users to reduce their exposure levels, set thresholds and decompress from reviewing harmful materials.
11. First AI Forensics Vendor to Offer WhatsApp-Style Investigator Support
Real-time bug reporting, feature requests, and help straight from frontline users.

12. First Offline AI Transcription & Translation Tool for Police Interviews
Used by national agencies to securely process sensitive recordings without internet access.
13. First Modular AI Engine Built Specifically for Law Enforcement and Military Use
Fully deployable offline, on-prem, or in secure hybrid environments, never reliant on public cloud APIs.
13. First and Only Secure Global Intelligence Database for CSAM and Terrorism Hash Sets
Secure, cross-border sharing of case intelligence, unmatched in scale and reach with over 3 billion LE records.
14. First Digital Forensics Company to Win Both the Queen’s Award and King’s Award for Innovation
Recognised for transformational impact in safeguarding, policing, and forensic innovation.

For more information on Semantics 21 and its life-changing technologies, visit:
Atola Technology introduces iSCSI support for imaging remote drives in its flagship TaskForce and TaskForce 2 forensic hardware imagers.
Firmware update 2025.4 also features numerous improvements for reassembling and imaging RAIDs and a built-in Hex viewer for byte-level analysis.
“We’re proud to release one of the biggest updates in Atola’s history,” says Vitaliy Mokosiy, CTO at Atola Technology. “The firmware will add muscle to your TaskForce in many ways. We’ve enabled remote drive imaging via iSCSI, doubled NVMe-to-NVMe imaging speed, introduced an interactive Hex viewer for all drives, image files, and logical files, and added support for imaging of Synology NAS RAID with one missing device.”
TaskForce now supports imaging remote drives connected via iSCSI. This is especially useful when a drive is soldered to the motherboard or cannot be physically removed from a computer due to legal, logistical, or technical constraints.
With iSCSI, the remote system exposes its drive as a network-attached block device, which TaskForce detects and can image like any locally connected storage.
To help users quickly set up remote drives on Linux as iSCSI targets, Atola Technology provides a free, ready-to-use script at GitHub.
A new built-in Hex viewer is now available for all drives, image files, and logical files. It lets users dive deeper into the data at the byte level to identify unusual data patterns or analyze file structure in depth.
[img-2]
The Hex viewer features seamless scrolling and an option to jump to a specific sector of a drive or an image file.
During logical acquisition or browsing files, Hex Viewer provides the ability to see all the bytes of a file or examine its specific portion using the ‘Go to offset’ command.
New features of the RAID module are designed to ensure faster, more accurate detection and offer more flexibility, especially in complex cases.
[img-3]
With the new firmware update, Atola TaskForce and TaskForce 2 have received a variety of other improvements. Here are some of them:
All enhancements and fixes included in the firmware update 2025.4 are listed in the product changelog.
The firmware update 2025.4 is already available for download at atola.com.
Atola TaskForce is a high-performance forensic hardware imager with 18 ports, capable of running 12+ parallel imaging, hashing, or wiping sessions at 15 TB/hour cumulative speed. Atola TaskForce supports automated RAID reassembly and imaging with a missing device, has Express mode for time-saving self-launching imaging, and provides Web API for automating forensic data acquisition workflow.
Atola TaskForce 2 is a new version of the TaskForce forensic imager, designed primarily for in-lab usage. The new device has 26 ports, including four M.2 NVMe ports, and can image 25+ drives simultaneously, even the damaged ones, reaching 25 TB/hour cumulative speed. TaskForce 2 has all the features of TaskForce, including RAID and damaged drives support, Express mode, and Web API for workflow automation.
Atola Technology is an innovative company based in the Vancouver area, Canada, specializing in creating forensic imaging hardware tools for the global forensic market.
Atola’s engineers – including its founder and CEO Dmitry Postrigan – have strong expertise in storage media and data recovery, and focus on creating highly efficient and user-friendly forensic imagers.
To learn more, visit us at atola.com and find us on LinkedIn.

