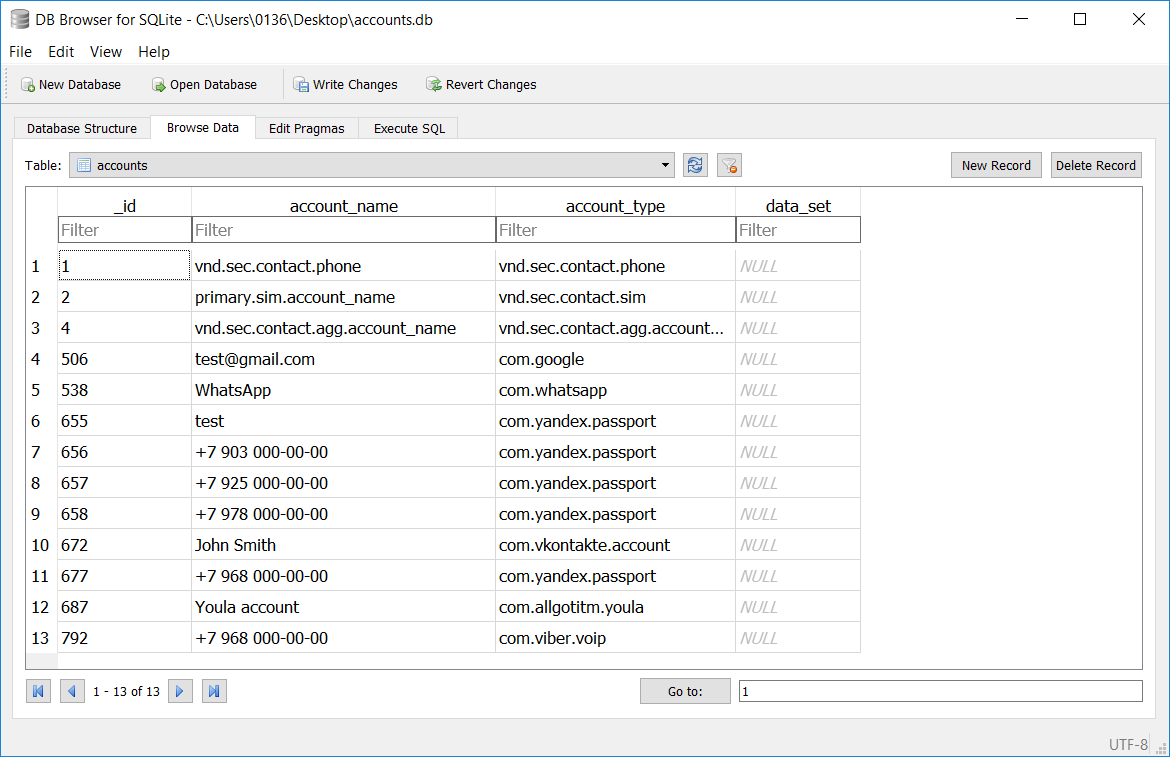
Over recent weeks, Alex Caithness, Principal Analyst at CCL Solutions, has been exploring the LevelDB database format. As ubiquitous as SQLite has become owing to the popularity of iOS and Android, he argues, “The trio of HTML5, CSS and JavaScript (and latterly, increasingly WebAssembly, aka WASM), plus the optional extra of offloading processing to the cloud, enable coders to make webpages which fulfil the role of a traditional application – a ‘Web App’.”
In turn, increasingly, browsers act as operating systems and pages as apps. This article abridges Caithness’ research, summarizing his team’s findings about LevelDB. For greater detail, including relevant links and illustrations, visit CCL Solutions’ blog:
- Part 1 provides an overview of LevelDB and the IndexedDB on which it’s built.
- Part 2 takes a deep dive into the way that Chrome-esque applications manage their IndexedDB stored data — and also links to a GitHub repository containing all of the Python Scripts generated during this research.
Hang on! That’s not SQLite! Chrome, Electron and LevelDB
Webpages can do very complex things. Web-based office suites, image editing apps, and video editors are just some examples. Although web browsers provide APIs (Application Programming Interface) for opening and saving data to a user’s local file system, making use of them is often clunky. On one side, making use of the user’s host system requires an understanding of the operating system currently in use, and on the other the browser tries to “sandbox” Web Apps, separating them from each other, and restricting their access to the host system for security reasons. Because of this, data persistence is often achieved by some combination of storing data in the cloud and making use of a variety of browser managed storage mechanisms.
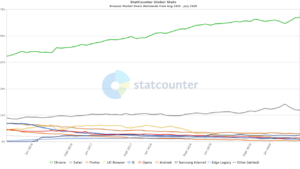
Chrome and its derivatives make up the majority of the browser market, so it is most important that we understand how Chrome manages its on-disk storage for Web Apps.
Safari and Chrome actually have a shared lineage in their rendering Engine – Safari using WebKit and Chrome using Blink, which is based on WebKit. Opera, Android Browser and Samsung Internet are all based on the Chromium codebase (Chromium being the open source version of Chrome) and the new version of Edge that now ships with Windows 10 is also based on Chromium.
As these browsers are all sharing aspects of a single codebase many of the artefacts associated with these browsers will also be shared. Because of this convergence I’ve started referring to these browsers that borrow heavily from Chrome (or Chromium) as being “Chrome-esque”.
In many cases it can be desirable to create a Web App because you can deploy that anywhere that can run a browser, but what if you want your app to look and act like a “real app”?
That’s where Electron (formally Atom Shell) comes in. Electron is an open source framework maintained by GitHub for building cross-platform applications based on web technologies. Electron allows a developer to bundle a back-end webserver that runs locally on a user’s machine, with the front-end of a website or web app built with HTML5, CSS and JavaScript, and rendered using Chromium. An Electron application window looks like a native application – but it’s really a browser with all the web navigation stuff stripped out.
So how common are these applications? Well if you’re running an up-to-date version of Windows, you almost certainly have at least one Electron based application already installed: Skype. Yep: Skype is based on Electron which means that it’s Chromesque and at the time of writing much of the chat information is persisted through IndexedDB. Other apps built on top of Electron include Discord, Slack, Microsoft Teams and Yammer, and the desktop versions of Signal and WhatsApp.
As Web Apps become more and more common, the need to persist data between sessions is often necessary to properly provide the functionality on offer. A word processor running the browser is all well and good, but if you can’t save your work as you go, it becomes a risky business. Of course, storing data in the cloud has become standard practice – being able to access your data from any location and on any device is an expectation of most users.
That being said, web apps should also operate offline in situations where that functionality makes sense – as would be the case for a word processor for example. For this, data needs to be stored locally, if only ephemerally. Local data storage can also be used for speed, where resources need to be accessed multiple times, for tracking, to provide functionality for browser extensions, and so on.
The IndexedDB API
One API that provides storage to websites is IndexedDB, a key-value store that provides web developers a means to store JavaScript objects — as keys and values — across multiple datastores on a per-domain basis. The data types allowable in the store comprise all the primitive types such as numbers, Booleans, strings, binary blobs and more, as well as the collection types that allow the arrangement of that data into a hierarchical structure if needed. The data can also be addressed via multiple indexes based upon properties of the object.

Compared to other storage APIs, IndexedDB shines in terms of its flexibility – good old Cookies provide only a very small storage space per record and need to be text based; Web Storage (Local Storage and Session Storage) is again text-based only; Web SQL and Application Cache (aka AppCache) are both deprecated legacy technologies (and never formally standardised in the case of Web SQL).
Finally there is the “FileSystem API” which is certainly interesting as it allows a Web App to make use of a file-system-like structure to store data locally; it is currently still officially an experimental API, although it is well supported by mainstream browsers. The FileSystem API on Chrome also makes use of the same technology as IndexedDB as it happens, albeit storing data in a different structure – but that’s for another blog.
LevelDB
The format the Chrome-esque browsers and applications use to actually store the IndexedDB data is LevelDB, an on-disk key-value store where the keys and values are both arbitrary blobs of data.
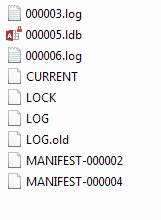
LevelDB is an on-disk key-value store where the keys and values are both arbitrary blobs of data. Each LevelDB database occupies a folder on the file system. The folder will contain some combination of files named “CURRENT”, “LOCK”, “LOG”, “LOG.old” and files named “MANIFEST-######”, “######.log” and “######.ldb” where ###### is a hexadecimal number showing the sequence of file creation (higher values are more recent). The “.log” and “.ldb” files contain the actual record data; the other files contain metadata to assist in reading the data in an efficient manner.
When data is initially written to a LevelDB database it will be added to a ”.log” file. “Writing data” to LevelDB could be adding a key to the database, changing the value associated with a key or, indeed, deleting a key from the database. Each of these actions will be written to the log as a new entry, so it is quite possible to have multiple entries in the log (and, indeed, “.ldb” files) relating to the same key. Each entry written to LevelDB is given a sequence number, which means that it is possible to track the order of changes to a key and recover keys that have been deleted (indeed, it is actually more effort to exclude old and deleted entries when reading the database!).
LevelDB Log File Format
The LevelDB “.log” files are broken up into blocks of a fixed size (32 kB). The blocks contain a 7-byte-long block header followed by data related to log entries. From a data recovery perspective, the log file format offers some great benefits: keys and values are stored in full, without any compression applied, therefore string searches and carving will be successful in a lot of cases. It is worth considering that as batched data can flow across block boundaries it will be interrupted by the 7 byte block header if it spans multiple blocks. If searching and carving is the primary concern then, it is worth pre-processing the log by removing 7 bytes every 32 kB to optimise the chances to recover data.
LevelDB ldb File Format
The ldb file format is a little more involved than its log file counterpart. The ldb files are made up of Blocks (slightly confusingly this term is reused in the Log, but the structure and contents are different). Unlike the blocks in the log files, blocks in ldb files do not have a fixed length. The final 8 bytes of the file contain the file signature: 0x 57 FB 80 8B 24 75 47 DB.
Data in ldb files can be compressed using the Snappy compression algorithm designed by Google. With Snappy, speed is always preferred over high compression ratios. Because of the way that it operates, it is normal to see data appearing to be more or less uncompressed and legible towards the start of a block but becomes more and more “broken” looking as repeated patterns are back-referenced.
It is important to understand that this compression is in use in the long-term storage for LevelDB records: naïve searching and carving is unlikely to be successful when applied to this data, without first decompressing the contents of the blocks.
IndexedDB on Chromium
In Chrome-esque applications, IndexedDB is built on top of a LevelDB store.The LevelDB store for a particular domain will be found in the IndexedDB folder with a name in the form: “[host with concurrent separators replaced an underscore]_[dbid].indexeddb.leveldb”, e.g. for “https://archive.org” the folder would be named: “https_archive.org_0.indexeddb.leveldb”.
The Database Structure
In order to read through the objects in the IndexedDB in a meaningful way we need to understand the structure of the IndexedDB: how many object stores there are; how to identify them; and so on. We can achieve this by identifying records in the LevelDB backing store with specially constructed metadata keys.
Key Prefix Structure
The keys of the records relating to IndexedDB data and metadata all have a common prefix format which indicates what aspect of IndexedDB each record refers to. The key prefix contains 3 integer values: the database ID, the object store ID, and the index ID.
StringWithLength
Most text fields in the database metadata will be stored as “StringWithLength” structures. This structure comprises a varint value giving the length of the string in characters, followed by the string encoded using UTF-16.
Global Metadata
Global metadata does not pertain to any particular database, object store or index, so in the key prefix those values will all be zero, therefore a global metadata record can be identified by the key prefix: 0x 00 00 00 00. The next byte will define the type of metadata being defined, the structure of the remainder of the key (if any) and the structure of the record’s value.
Database Metadata
For database metadata records, the key prefix will contain the database ID for the database in question, then zero for both the object store ID and the index ID. The key prefix for these records will therefore be: 0x 00 yy 00 00, where yy is the database ID. The next byte will define the type of metadata being defined.
Object Store Metadata
The key prefix format for object store metadata is a little surprising – as with the database metadata only the database ID field is set, with the object store and index ID both still set to zero (this is because when the object ID is set to a value, the records contain record data or metadata referring to records rather than the object store itself). Instead the standard key prefix structure will be followed by the value 50 (0x32), e.g. for database ID 1: 0x 00 01 00 00 32.
This prefix will then be followed by the object store ID encoded as a varint; for object store ID 1 this would be: 0x 00 01 00 00 32 01. The key is then completed by a byte which determines the type of metadata to follow.
Reading Records
Once we understand the “shape” of the IndexedDB database, we can start to consider how to identify and read the actual records in the object stores.
The LevelDB records relating to data held in an IndexedDB object store can be identified by key prefixes where the database ID, object store ID and index ID are all populated. Index IDs 1 through 3 are all reserved and have a special meaning:
- A record in the object store identified by its primary key
- An “exists” marker with the version of the record as its value
- An external object table record which details file or blob data related to the record that isn’t stored with the record itself
If we are only interested in reading stored objects from IndexedDB, then the only index ID that we really need is 1 (the record identified by its primary key); ID 3 will also be of interest in most cases.
The value for records following this key structure will contain the serialised form of the object stored in IndexedDB. Other items of interest include the backing store version, Blink version tag, and V8 version tag.
Object Encoding
After the 3 values that form a header of sorts, the rest of the data is made up of the serialised JavaScript object. The serialisation uses a tagged format: a tag byte followed by the serialised data.
The method by which the JavaScript objects are stored is governed by two different areas of the Chromium application code: primarily the V8 JavaScript engine (https://v8.dev/), with additional work done by the Blink rendering engine (https://www.chromium.org/blink). A full description of the data format used to serialise the objects is found in the full version of the blog.
External Data
It is possible for web apps to store files or blobs inside IndexedDB. If embedded files are present then alongside the “indexeddb.leveldb” folder for each domain there will be a matching “indexeddb.blob” folder, e.g. for “https_docs.google.com_0.indexeddb.leveldb” there will be a corresponding “https_docs.google.com_0.indexeddb.blob” folder. The mechanism for linking these files to records in the database is described in the full version of the blog.
The more you know
To help other researchers in this field we’re excited to announce that we are open-sourcing the Python code that we generated during the research for this blog. In the set of scripts, located on GitHub, you’ll find pure Python implementations of: Snappy decompression, LevelDB, IndexedDB, V8 Deserialisation and Blink Deserialisation.
The APIs still need some tidying up or wrapping to improve the coding experience, but they will do the job to get started digging into these files. Improvements will be on the way in the coming months and in the meantime if you find any bugs or missing features please feel free to submit a bug report or pull request!

Alex Caithness is a compulsive hex fiddler, regex wrangler, Python evangelist and Principal Analyst working within the R&D team at CCL Forensics. Over the past few years he has spent his time trying to devise ways of getting hold of more and more interesting data whilst making the data he already has more useful, especially with regards to mobile devices. As well as developing the internal capabilities at CCL, he has also written a number of commercially available forensic tools including Epilog and RabbitHole as well as open source scripts and modules.
He is a regular speaker at industry events and conferences and provided training including digital fundamentals, data formats, the Python scripting language and the tools he has written.