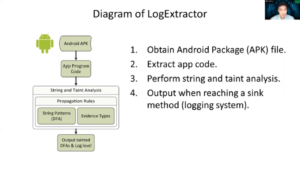
Forensic Analysis of ReFS Journaling
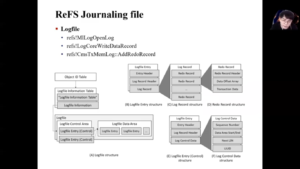
Hello, I am Seonho Lee from the Affiliated Institute of ETRI. Today, I talk about the forensic analysis of ReFS Journaling.
Before everything, let me just briefly explain the two key topics of the presentation. I’m going to explain what