Hi, thanks for showing me. This is Christian Chao, a PhD from Iowa State University. Today, I’m going to present LogExtractor. This is joint work with Chen Shi and my advisor is professor Neil Zhenqiang Gong and professor Yong Guan. The project is cooperative with NIST researchers, Barbara Guttman and James Lyle and sponsored by NIST and csafe, Centre of Statistics and Application of Forensic Evidence. We propose LogExtractor as an automated approach for identifying and extracting digital evidence for Android Log Text Corpus.
Searching evidence in the Text Corpus is one of the most popular ways when forensic practitioners look into their mobile devices. According to R-Droid an Android app data flow analyzed a study in 2016, by analyzing around 23,000 real world apps. If [inaudible] logging system is the primary place where apps save evidentiary data, such as GPS location, and network information. That is to say when a forensic analyst investigates the mobile device Log Message has the highest chance to contend the useful digital evidence. Here let’s work through this [inaudible] of evidence identification from logs.
First, the first investigator dumps the log from the suspect device by using tools such as Android Debug Bridge. Next, wastage tracks the Log messages, then investigate [inaudible] software to search by keyword or regular expression to locate and retrieve the evidence. Following the information introduced [inaudible], let’s take a look at this piece of Real World Log Message.

If you were for instance an analyst working on this, how and how fast would you find your evidence from the log message? Well, probably you can come up with techniques such as keyword searching or regular expression mappings. But let’s look at this closely again. Given that you’ll find these are GPS coordinates, by which patterns would you use to parse this information? And imagine if there are no keywords like location that show up. It will be more difficult to catch this part when dealing with the Real-World size Log Corpus, which is also more than 10,000 messages.
Let me use this example to rephrase and motivate our research problems. Given that a forensic investigator wants to find the evidence from Log Message A and B. Our first research problem, evidence identification problem, is to find which message contains the evidence, and if the answer is yes, what types of evidence they are. In this case, given that we find our message A contains that GPS latitude, what’s the actual value it’s supposed to be? Here the evidence extraction problem comes, which targets at answering this kind of question. Using the affirmation example from message A, let’s quickly go through the example to see how an ideal automation tool like LogExtractor should work for extracting the actual evidence on the Log Message body part, which is highlighted in orange. Later, we will repeat this example with more technical details. Given LogExtractor has to analyze this result as the State diagram in the center and Input String at the bottom left, we work on that state diagram based on the input corrector one by one, then I’ll put the result at the bottom right. So here we place an automation to see the result.
So as you can see, with such a state diagram, we can [inaudible] extract the latitude value which is 30.03 from the Input String. Our research purpose is to use LogExtractor to answer both evidence identification and extraction problems. We find that existing studies are limited at solving their specific domain problems, but cannot help us to solve evidence identification and extraction problems in Android Logging System. For example, the Android App can analyse studies such as FlowDroid and DroidSafe. As the right hand side figure demonstrated, we can only tell which type of data can be [inaudible] at which category of sync like the Files System. Unfortunately, they do not support the output as detailed as the Log Message String patterns. On the other hand, String analysis studies like JSA and Violist do support String pattern analysis, but do not answer which piece inside the String patterns carry which type of evidence.
Log parsers, unlike [inaudible] approaches, implement the analysis based on the data mining, which builds their analyst logic on historical data. However, while it does use techniques like Regular Expression to cash Frequent Use evidence, it still lacks the ability to answer evidence extraction problems without key workings or manual operations. Therefore, we propose LogExtractor for solving our research problems.
Before diving deep into the research details about how we build the automated extraction tool, I would like to give a quick review on Android Log Message. As the example shows, a Log Message is composed by Timestamp, the Process ID, the Test ID, Log Level, Log Tag and Body Message. Well, Timestamp, Process ID and the Task ID are determined by the run time and Android app can decide the Log Level, Tag, and Body by selecting the corresponding APIs and variables.
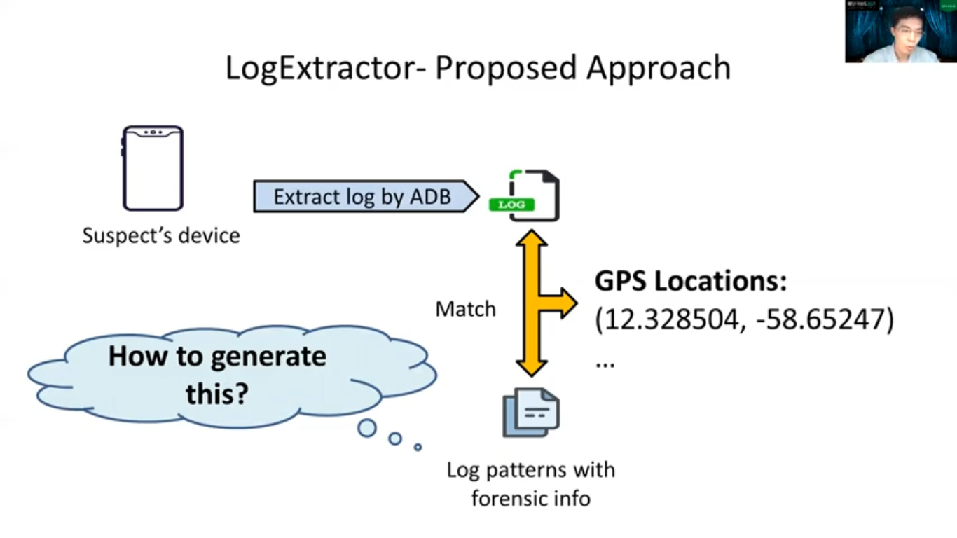
Here is our proposed [inaudible] with the help from LogExtractor. After the forensic investigator obtains the Log message from the suspect device, LogExtractor automatically identifies the evidentiary Log messages and extracts the evidence like a GPS location as shown in the example. So now the problem is, how to generate these kinds of patterns? So next we will present how we generate a pattern here for matching and extracting the evidence.
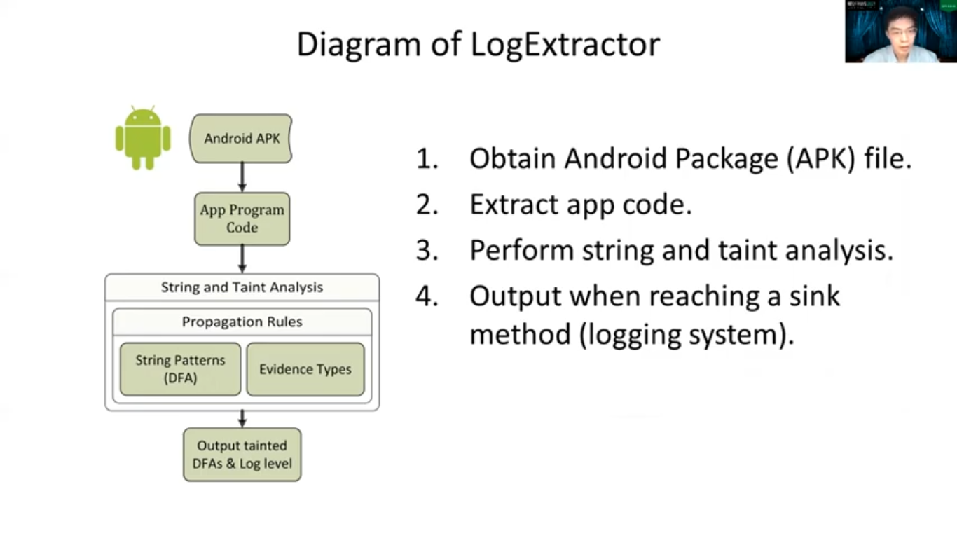
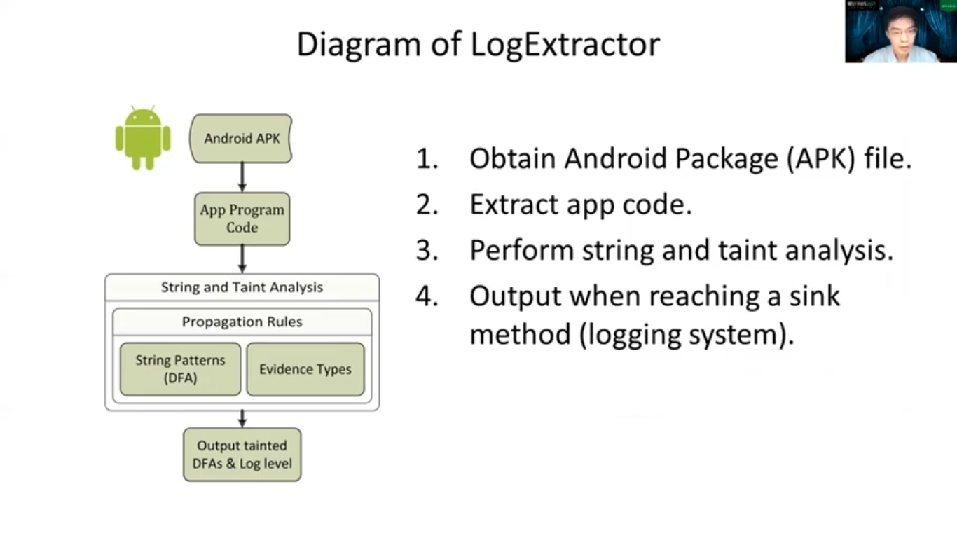
We propose to build App Log Evidence Database in the offline phase, by analyzing Real World Apps. Each entry in a database represents a Log Message pattern, including Log Level, the String patterns of Log Tag and Log Body. That may be retained [inaudible] during the wrong time. The log stream pattern is summarized as tainted DFA, which will be covered later. The workflow at the bottom demonstrates how we use this database to identify and match the evidence from Log messages.
To build App Log Evidence Database, a part of the LogExtractor, we propose to apply a composition of String and Taint Analysis over Android App Program Code. That is, we analyze Android APK files collected from the Real World market, such as Google Play store. Then for each login and API that writes the log message, we output a log of message patterns. So here let’s use a program called [inaudible] sample to demonstrate this.
So first we initialize. So, as you can see another line too, we initialize a String constant, and we [inaudible]. So here we have the variable tracking the stream variable, ‘’Lat-’’. Then we propagated it into the stream buffer. So here is another variable with floating numbers, String pattern and carrying the latitude type. That’s your latitude with angle brackets [inaudible]. Then we combine them together and propagate the result to the output buffer. So that’s the overview. And now, before moving to the Tainted DFA let’s first look at the DFA.
So the DFA, Deterministic Finite-State Automaton, is functionally equivalent to the record expressions like these two examples. When we match an input stream with the DFA, by working from a state to another state, one corrector is consumed from the input stream. At the end, if one can reach the end state denoted by the double circle such as S4 state and the input stream becomes empty, then we can conclude that they are a match.
This is the tainted DFA representing our previous example. So as you can see, the left hand side is the part for the constant stream, ‘’Lat-’’, and the right-hand side is the floating number string with evidence type, Latitude.
So beside the [inaudible], we add a Taint Table for each state within the DFA to check evidence-type provocation in the app program. In this example, any corrector being matched by the right hand side will be a part of the Latitude String Output.
So by using that Tainted DFA, we summarize that there are three scenarios when using the Tainted DFA to extract the evidence stream from the input. So no doubt that the evidence type is unnecessary to be a single type like the latitude that we previously demonstrated. This work can also support the case when the input string carries multiple evidence types, like a text input or the unique identifier. So to quit extracting the stream, we keep tracking two pointers, one point to the current state after consuming an input corrector while the other one points to the previous state. In this scenario, since we just move from a state without evidence to the one that has a certain evidence type, we initialize this output buffer.
And following the previous one, if both pointers point to states with the same evidence type, we should append the input corrector to the output. This arrow suggests that, as you can see here, the first one is the tainted one, and the next one is done when we saw the taint which means the first one has the evidence-type state, but then the following one doesn’t. So in this case, such as that the input corrector T3 shall not be counted as the evidence stream, and we should stop the buffering and output of the result. So, let’s wrap up the scenario that was introduced earlier and work through this example again. So this is the example that we, by analyzing the program code [inaudible] get this tented DFA.
So if you remember it, the left hand side is the Constant String and the right-hand side is the Floating String with the Evidence Type Latitude. And suppose we have an Input Stream like the bottom shows. So here, we start from the initial pointer. So next, from the S26 to S27, there is an uppercase L so that we consume, correct our L and move to the next date. And since these two states are just states without the evidence type, then this corrector should not be counted as any kind of evidence here.
And next is the A and T and hyphen. So we moved to the hyphen then, okay. This is the first scenario that we earlier proposed. So we moved from the state. We sell the evidence types to a state with the Latitude evidence type. So after consuming the hyphen corrector we’re supposed to initialize the output buffer, and you can see the edit button, right? Like this. Then we conjoin the number three and since it is not real that two states have the same evidence-type latitude, so number three should be counted as part of the Latitude [inaudible]. So we keep appending the output from the Input String until we reach the end state of this tainted DFA. And since you can see the infrastructure here is empty, which means we finish extraction and we can output this value as a result.

So we evaluated LogExtractor on both Benchmark Apps and Real World Apps. For Benchmark Apps, we used DroidBench. We count only the apps that write log-in messages. At the end we found there are 65 apps. As you can see the Identification Extraction Performance are quite well. There are some technical limitations that deteriorate the performance like ICC flow, it’s inter-component and communication between the different Android components. And we inherited this limitation by the tool we use for R-Droid to construct a co-graph. And also there are other limitations like the Implicit Flows that are well-known challenges in [inaudible]. And also since we linked precise stream models of Strava String Libraries, like the Formatter and Matchersome patterns around the wrongly constructed.
And the Real World App variations conducted over 12,000 apps. We manually verified 91 apps and got a similar performance report like the Benchmark apps. There are two additional limitations found in the Real World apps verification. One is the String Model Precision on two dimensional data structures, such as Map. And the other one is the Any String DFA, which for, by Any String, it means it’s a regular expression. You can imagine this as a regular expression that can step [inaudible] the String. So in this case if there are the API [inaudible] that we failed to buy a proper String model, then it will deteriorate the performance because then we keep the system consistent and treat it as an Any String model. And you can imagine that in this case, we will merge all evidence types together and offer the results. So in this case it will cause false reports.
And before concluding this study, I wish to use some Real World Log messages that were found in our manual verification to highlight LogExtractor contribution to our research problems. These are the Real World Log messages that carry a GPS location data. As you may find, the first one looks straightforward and can be easily followed, given the searching keywords are correctly used.
Next, we find a case where GPS coordinates appear as we solve the keyword. However, due to the separator and their appearance sequence, that latitude goes first, then longitude. We believe this may cause for an investigator [inaudible] but it is not impossible to find. So the most interesting one comes up here, the next one.

We also find a case where there’s no keyboard location like GPS, like latitude. There’s nothing there, but just a comma. And these are just comma-separated String. And coordinates order do not appear as the other generally used patterns like you always go with the latitude and then longitude. So in this case the LogExtractor reports that actually the first one is the longitude, then it goes with latitude. So we believe it is very challenging for a human investigator, as well as other existing forensic analysis tools to determine the correct GPS coordinates from the Log message. So, and here, this is how we introduced the LogExtractor to play the important role when being used to automatically extract the evidence from the text stream.
So to sum up our proposed framework, LogExtractor combines String and Taint analysis to build the App Log Evidence Database. With that database, we present how to match and extract the digital evidence from the Log Message, dumped from the suspect device. At the evaluation part, we demonstrate how LogExtractor can help with retrieving the Real World GPS Location Evidence, which humans and [inaudible] are limited to catch. In the future, we aim to keep improving the time and space efficiency when applying LogExtractor on analyzing Real World Apps. Also, we will work on extending our existing industry analysis model by the one with higher precision. So thank you for joining this presentation, again.





