
I have done some research on recovering severely damaged zip archives (ooXML documents) lately, and will share some findings and a toolset I made along the way. It was initially meant for newer Word docx, but applies equally well to xlsx, pptx and zip archives generally. I believe I've found some interesting things, but that's up to you to evaluate for yourself. However, I believe certain commercial applications have shortcomings in content detection that my tool will outperform. Link to package with documentation, theory, facts, findings and commercial software comparison;
Updated 24.06.11;
http//
Summary of ooXML (zip) Carver Tools
Description of tools
- ooxml_carver.exe = The main application. Searching, decompressing and generate log of findings.
- inflate_raw.exe = Decompress single files that are in raw format deflate.
- inflate_raw_loop.exe = Brute force decompressor. Dead slow but identifies all valid and healthy deflated chunks.
- deflate_raw.exe = Compress single files or by batch, using raw method (method inflate, windowBits -15).
- deflate_raw_batch.cmd = Sample batch to show how deflate_raw.exe can be used.
- metadata_extracter.exe = A metadata extractor and docx consistency analyzer.
- [Content_Types].xml.deflate.raw = Healthy raw deflated file to test on.
- fragment.docx.bin = Severely damaged zip file structure fragment with 1 healthy (raw) part and 1 partly damaged part. Test it too..
A specialized toolset that carves and analyzes compressed parts from the ooXML format. The format is basically zipped xml files. As a matter in fact toolset/document is almost as much about zip in general as it is about ooXML.
The fact that it is zipped means we may be able to recover complete parts of the document even though only a fraction of the original document is recovered. That is because the zip format is just like a filesystem with individual files on. They don't depend on each other, so we can recover them separately. Technically, the ooXML files are compressed by deflate method. When they are assembled together into a zip file (but with extension docx, xlsx or pptx), the deflated xml files are organized according to the zip format. That means there will usually be 3 different sections in the final zip file;
1. ZIP local file header. Start signature = 0x504b0304
2. ZIP data descriptor. Start signature = 0x504b0708
3. ZIP central directory file header. Start signature = 0x504b0102
4. ZIP end of central directory record. Start signature = 0x504b0506
In number 1 the individual compressed data parts are found with a standard header prepended to it with information like size, timestamp, name, crc32 etc. Number 2 I don't think is ever used by ooXML. Number 3 is the central index with information about where everything is located inside the zip file. Number 4 is just a tiny a marker that this is the end of the zip file.
Since we know the organization of the zip format we can easily detect the individual parts of an ooXML document. The local file headers always have the same starting signature 504b0304, followed by the cleartext form of the internal filename starting 31 bytes after the start of the signature. The compressed data is then attached right after the filename, unless the "Extra field" is used (denoted at byte 29). Because of this known information it is easy to spot and isolate the compressed part. Number 2, 3 and 4 is not at all important. All we need to do is create a dummy zip structure around the compressed part, and the standard zip handling software can uncompress it. However, if the compressed part is corrupted, the standard zip handling software cannot decompress it. Now specialised zip repair software can be used on the generated zip file. This application will extract/decompress the found parts. It is using a method called raw inflate, which means decompression is performed without the requirement of knowledge about size, crc32 etc (in the header).
OK so what? We already have zip repair software that does this! That's right, but most of it costs money, and they have varying success at doing the job. I have tested 10 different zip repair related software on how they detect the content. When content is detected, they can attempt a repair/recovery. Ie, the algorithms for how they repair corrupt parts have not been tested. It is the search algorithm that has been tested, on how well they identify actual content in a zip archive. All of the 10 need a perfectly intact local header to identify the compressed data. 5 of them performed particularly bad, while the 5 others performed equally good. This is where my tool really distinguishes itself from the others, as it may work even with damaged local file headers. But if the compressed data is corrupted then, my tool will currently not try to repair the data. So if that's the case you may need third party repair software to try repair on the zip file that this tool generates. Especially the repair software from SysTools (both zip and docx) seems to perform a crappy job. If I feed it with a specialized fragment, it either freeze or crash!!. The same happens with Object Fix Zip. StellarPhoenix Zip Recovery and Zip Repair Pro also did not identify the content even with good headers. I wonder why it's even called zip repair software, when almost all the zip structure must be good for the software to identify the piece as a zip archive with content inside..
Results
Equally good
ZipRepair Pro (GetData) v4.2.0.1281
Advanced Zip Repair v1.8
Nucleus Kernel Zip v4.02
SysInfoTools Zip Repair v1.0
WinRar
Bad
SysTools Zip Repair v1.0
SysTools Docx Repair v3.1.2.0
Object Fix Zip v1.7.0.27
Zip Repair Tool v3.2
Stellar Phoenix Zip Recovery v2.0
Last resort attempt
If you know or suspect that compressed data is there but no tools can identify it, you may want try the loop decompressor, inflate_raw_loop.exe. It is dead slow and must not be run on large files, unless you have lots of time. It will start decompression attempt at offset 0x0. If nothing is there, it will move on the offset 0x01, and attempt next decompression, and so on. You will get some false positives, therefore you can configure the minimum number of characters in the match (an inputbox is presented). As a test you can try this tool on a sample docx fragment included; fragment.docx.bin. Inside this file is a broken theme1.xml which is easy to spot. However, there is also a document.xml there, with erased header. Try it out. A good hint and indication is the presence of any of the names of the source files, as listed at the bottom of this document. Since all documents start with [Content_Types].xml, you know that if you see the name of any of those listed after it, there is very likely compressed data found before that string. To give you an idea about expected time use, it took me 24 seconds to finish a 14 kB docx file by brute force method (looping and writing both decompressed data as well as to the logfile). The main application, ooxml_carver.exe, does have this functionality, but will not do so past offset 0x3a98 (15.000 bytes forward). Maybe I change this in future. I may as well put the configuration of the minimum size for a match, to a local configuration file.
Extra
During the research, I could not find any tool to decompress in raw mode. Therefore I also include a basic "raw decompressor". Run the program and a file open dialog is launched. Then choose the raw compressed file. Included is one such sample file; [Content_Types].xml.deflate.raw
Last word
This was never meant to be distributed. But along the way on researching I at some point realized that some people actually may find this interesting or helpful. It is completely free to use and can be distributed as you like. It is written in AutoIt and compiled and tested on 32-bit XP. Whenever the sourcecode is cleaned up, I can provide it. Many thanks to the people at the AutoIt forums, and especially the user Ward that has published nice and advanced UDF's on CRC32 and inflate/deflate functionality (machinecode of zlib to memorymapped).
Last word 2
I've also come a long way of writing a metadata/source code collector. That tool will apart from the obvious, detect tampered with documents. For instance a valid timestamp in the zip structure means that the documents has been edited with in a rather unusual way. According to the ooXML specification these timestamps shall never be used, and therefore always will be 0x00002100 if software complying to that specification (like MS Office, OpenOffice etc) has been used. The in-work tool will also log values for rsidRoot and rsids (and more). Just need to find a sensible way of logging the information..
Common source files of ooXML documents
Word
[Content_Types].xml
_rels/.rels
word/_rels/document.xml.rels
word/document.xml
word/theme/theme1.xml
word/settings.xml
word/fontTable.xml
word/webSettings.xml
docProps/app.xml
docProps/core.xml
word/styles.xml
Excel
[Content_Types].xml
_rels/.rels
xl/_rels/workbook.xml.rels
xl/workbook.xml
xl/theme/theme1.xml
xl/worksheets/sheet2.xml
xl/worksheets/sheet3.xml
xl/sharedStrings.xml
xl/styles.xml
xl/worksheets/sheet1.xml
docProps/core.xml
docProps/app.xml
Powerpoint
[Content_Types].xml
_rels/.rels
ppt/slides/_rels/slide1.xml.rels
ppt/_rels/presentation.xml.rels
ppt/presentation.xml
ppt/slides/slide1.xml
ppt/slideLayouts/_rels/slideLayout7.xml.rels
ppt/slideLayouts/_rels/slideLayout8.xml.rels
ppt/slideLayouts/_rels/slideLayout10.xml.rels
ppt/slideLayouts/_rels/slideLayout11.xml.rels
ppt/slideLayouts/_rels/slideLayout9.xml.rels
ppt/slideLayouts/_rels/slideLayout1.xml.rels
ppt/slideLayouts/_rels/slideLayout2.xml.rels
ppt/slideLayouts/_rels/slideLayout3.xml.rels
ppt/slideLayouts/_rels/slideLayout4.xml.rels
ppt/slideLayouts/_rels/slideLayout5.xml.rels
ppt/slideMasters/_rels/slideMaster1.xml.rels
ppt/slideLayouts/slideLayout11.xml
ppt/slideLayouts/slideLayout10.xml
ppt/slideLayouts/slideLayout3.xml
ppt/slideLayouts/slideLayout2.xml
ppt/slideLayouts/slideLayout1.xml
ppt/slideMasters/slideMaster1.xml
ppt/slideLayouts/slideLayout4.xml
ppt/slideLayouts/slideLayout5.xml
ppt/slideLayouts/slideLayout6.xml
ppt/slideLayouts/slideLayout7.xml
ppt/slideLayouts/slideLayout8.xml
ppt/slideLayouts/slideLayout9.xml
ppt/slideLayouts/_rels/slideLayout6.xml.rels
ppt/theme/theme1.xml
docProps/thumbnail.jpeg
ppt/presProps.xml
ppt/tableStyles.xml
ppt/viewProps.xml
docProps/core.xml
docProps/app.xml
Sample logfile;

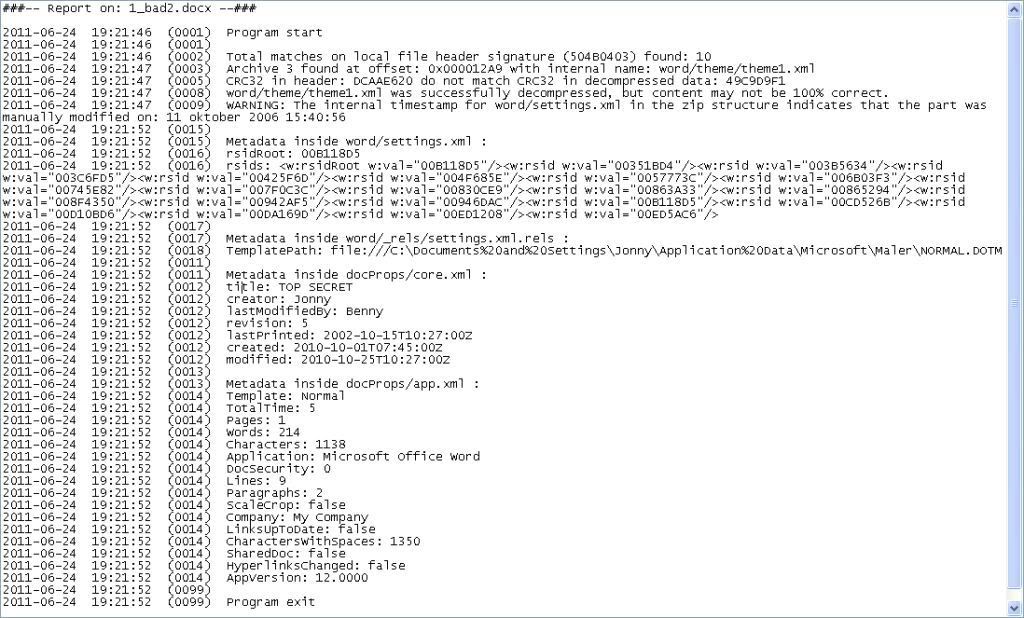
Sample log from metadata extracter;
Feel free to try and give feedback no matter if good or bad. Beware though, It is the first alpha release. It can likely be improved with lots of stuff..
A combined metadata analyser is also in-work.
Joakim Schicht

Good work! )
Maybe redundant, or not useful, but maybe not, OFFZIP
http//
jaclaz
It is indeed related, as he is using parts of zlib too. D His brute force implementation is faster than mine, so I need to study the source. The signature evaluation of decompressed data is also a nice idea to give a correct extension. However it seems to be flawed in that it cannot detect certain stuff. I tried injecting a raw deflated (an xml tweaked as a txt in the header signature) file into a dll and his tool did not find it, whereas mine did. Another downside is the output files do not have their original names, because it does not evaluate zip structures. It would aslo be nice to have a descriptive logfile and a summary. His error messages about windowBits -15 is wrong and confusing (not that it matters on the output though).
But anyways, thanks for the link. D I think I will adopt the signature to extension functionality.
Joakim
Yes, the idea of OFFZIP is "right", the implementation may be bettered, IMHO.
Still risking to go OT, but maybe giving you some ideas, DYNAMITE may be of some use, reference in this seemingly unrelated thread
http//
Also maybe some useful snippet may be found in the Linux zip source (which has the -F and -FF switches to try fixing corrupted zip files).
About signature, possibly you can somehow integrate TriD (or it's library)
http//
jaclaz
Package is updated and bruteforce is improved as well as basic signature/extension functionality for the most common filetypes. And most importantly, the duplicate *.raw and *.zip files are no longer written as duplicates (just confusing). The summary file is also much more readable. Se added image in first post. Next will lots of other functionality (already in another separate app) be ported into this one, with more analysing/logging capabilities for metadata and more..
Joakim
Uploaded an update. Added functionality so that if document.xml is found, all actual document text is dumped into document.xml.txt. Also added a small app that can batch compress files in raw mode (windowsBits=-15).
Yet another version uploaded now with a metadata extractor and ooxml consistency analyzer; http//
Sample log from metadata extractor shown in first post. Don't know where it's going but still working on something..
Joakim