Hi everyone. My name is Gabriel Souza, and now I will present a paper to the Digital Forensic Workshop USA, and the article is entitled “Using Micro-Services and Artificial Intelligence to Analyze Images in Criminal Evidences.” So, this work has the support of my institute Universitade Federal do Rio Grande do Norte [inaudible]
So let’s start. In the following slides I will describe the problem that was solved and the challenges faced and the situation’s objectives. So, before I introduce the development section, we need to understand how does a criminal investigation proceed.
First of all the investigative institution receives any report about criminal schemes. That is, it always starts with a complaint. At this the institution begins an initial investigation to look for some concrete evidence of the crime, when there is a strong evidence that confirm the complaint the institution prompts the police to realise an operation to confiscate from the accused media such as smartphones, laptops, tablets and all the relevant things to the investigation.
So from this device the institution starts a process of evidence analysis. Using a forensic tool that extracted all the coded data extracted from all these device, generic and compressed files with images. These files they analyzed to investigate all the data to found an image, text messages, emails all the data that that can prove [the initial complaint].
So, after getting together and also the [institute] the accused, equipment, the analysts reporting as all investigate events, and this report is forwarded to the judgment for the initiation of judicial proceedings.
It is important to be clear that, his proposed session aims to improve the evidence analysis process and we aim to improve and speed up the process of extracting view and announcing final investigate criminal evidence data.
So, from this image we can see how do we get the evidence analysis process? First police go to the house of the accused and for court ordered and collected devices and documents that may contain relevant information from the evaluation, as you can see in the second image.
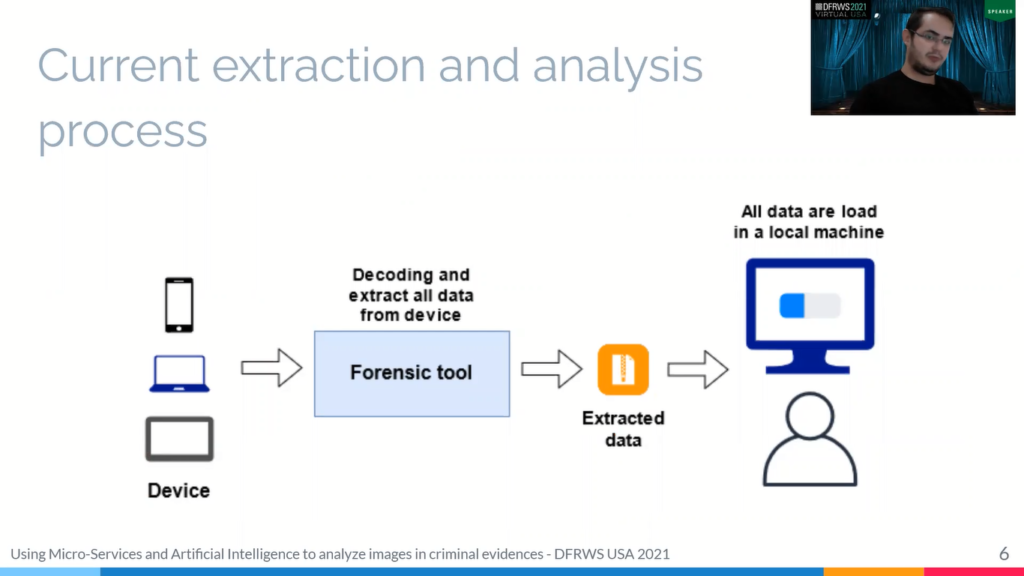
So, the police will collect any document or device that can possible, that can possible search for clues that incriminate the suspect, that is any component of an image, or specific information, or where is data as well. So in the current extraction and analysis process across the entire process of extracting and viewing devices there is big enough for us to do.
So this tool invades the device and decoding and extracting all the data, in generically compressed files, the analyst takes the files to your local machine and drove the forks [?]. He can access the extracted data and start the investigation process.
The big problem of this process is that the software to view this 500 files, many are sourced from the machine. So the files loading memory, and so more data the evidence contains more resource file, basically on the advancement of the device storage capacity, especially going unfeasible.
Another important point is that if five analysts are involved in the evidence analysis, each one should come up with the same fact and local machine. Each of these machines must have enough resource to the FST stretch.
So, to create more efficiency for the evidence analysis, we need to keep in mind that the device contains a large amount of the investigation may have many devices for a person and many people related to an investigation.
So we can conclude that this province is that the problem. Another observation that the analysts usually has access to the evidence just a few days before the judgment. So it is clear that is necessary to develop solution that can provide this important step.
Therefore, to resolve the problem in the evidence analysis step, we propose a big data platform, named INSIDE platform. With this platform we process our data in a file provided by the forensic institute and offers artificial intelligence solution to speed up the data analysis.
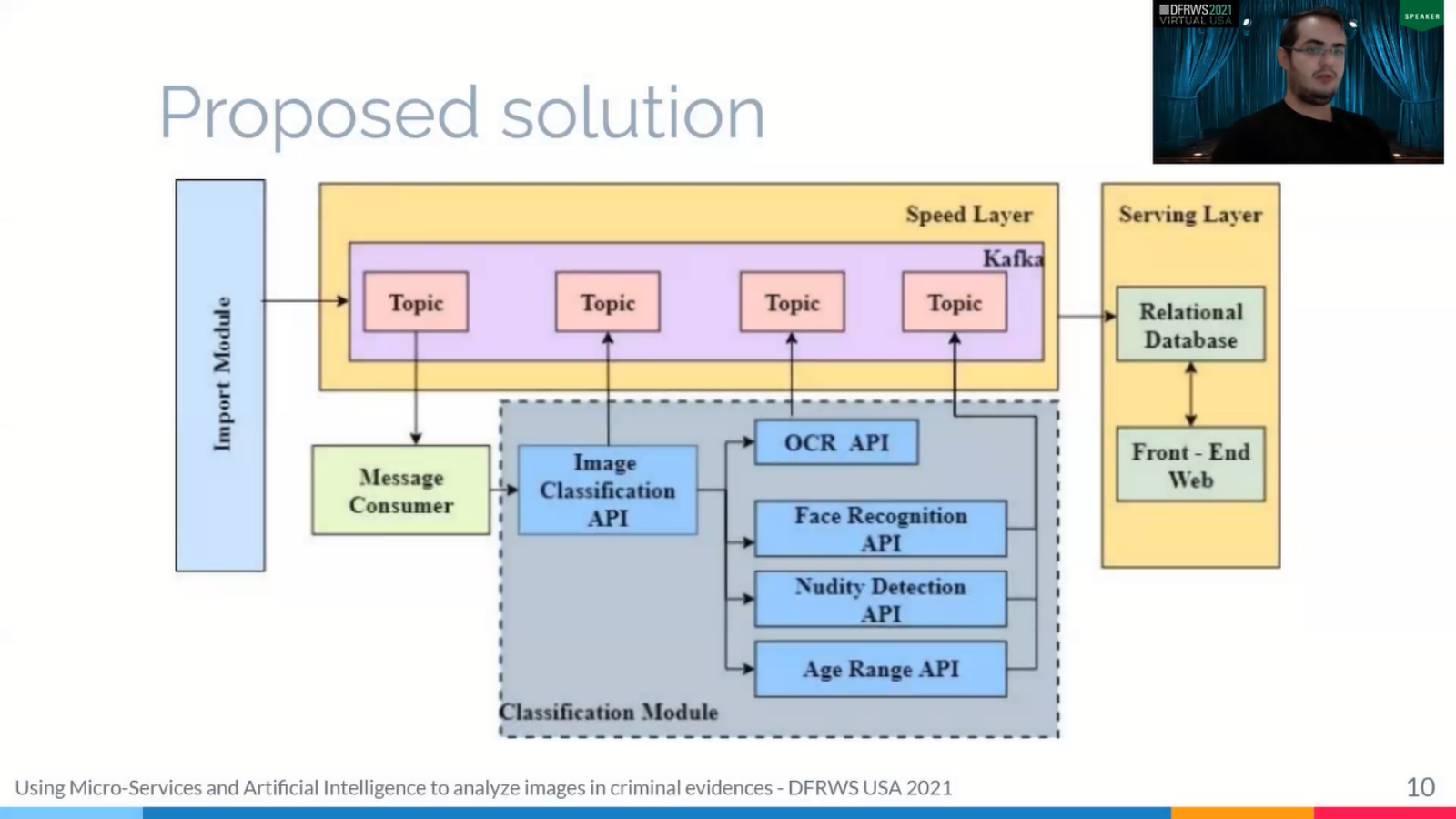
Now, the system was developing in the microservices architecture that provide more flexibility to the solution. Thus we can separate the viruses and managed them individually. We felt this interrupt the, the rush out the platform. Okay. And in the, in the first live that I am present, they propose that architecture.
So how can we observe that [system] is based on a lender architecture, a data processor that would design to have a massive quantity of data by take advantage of [both the] batch process and streaming process matter. So we have an important model that the interest audit in decision, a speed layers to process the data [distributed] and power away a classification model that provide many intelligent solution to image that image classification and [inaudible] results.
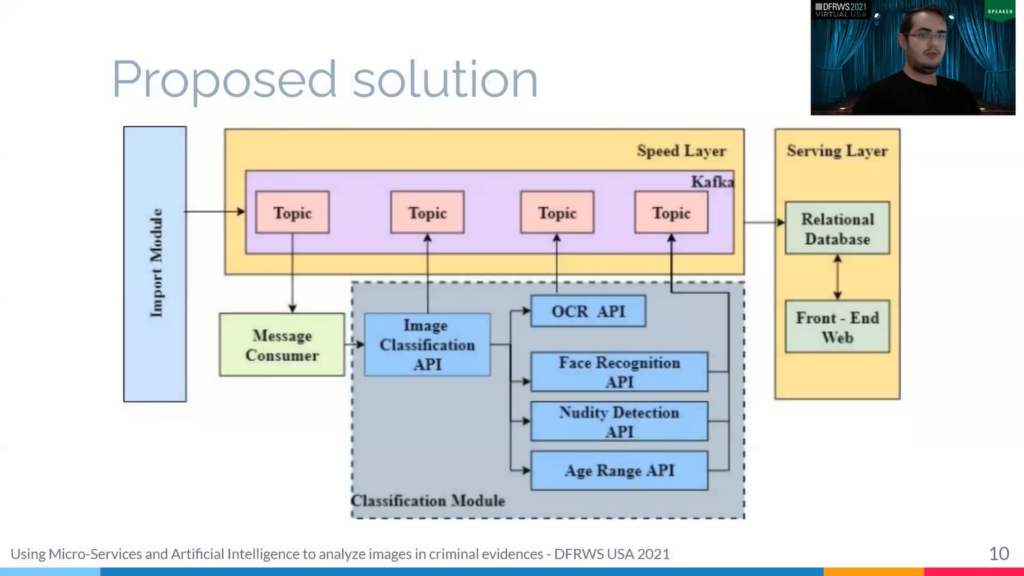
Thus we [initially train]… the importing model is responsible for extracting and pre-processing evidence data. In these images, you can see the tasks realized by the model, the model received the evidence concluded by a compressed file containing XML ? file. And we thought formation back on the device and a directorial such as emails audio files.
So, the important one, we transform it and, and read this data and return the relationship between files and files information to say, [extract] data in a dot file session and a relational database.
Well, next, we will talk about this speed layer. So, this speed layer is responsible for providing first for providing first that data process, and in this layer we have an Apache Spark Cluster and one master and two working nodes in which the master is responsible to coordinate the data processing step and another essential component in this layer is the Apache Spark.
Kafka is the messaging node that is responsible for profile communication outsets. So if classification API needs to send some data to model for them, this communication is made with Kafka, so Kafka also used for communication between master and work nodes.
The next module is the classification module. This module is responsible for classifying images from the evidence and comprises several, uh, micro-processors, and intelligence algorithms, such as API to object detection, facial recognition, relevant text detection and nudity detection and all this.
So we present some developed solutions. The first solution is ammunition and guns detections, and we developed our own dataset with 7,034 guns images and 2,200 ammunition images for creating these algorithms. So these images are extracted from movie clips, real images in evidence and public images.

So to make this the, to make the classifier, we use transfer learning on so weights for the training model to create a new model. For the test we used YOLO models, so, these images are resulting with the ? classifier. We tested this classified dataset with 600 image, 300 positives and 300 negatives. And this image is summarized as samples collect by this classifier.
Another developed classifier was Brazilian identification document detection. This is important too, because these documents can identify relationships between suspects. So we push through, they just have deal with 1200 ID cards images, and these images are extracted for evidence using real images in evidence and public images, and, as the ammunition and guns detection we use transfer learning in the YOLO to create these classifiers, and 300 images are used to test this classifier.
Next. Another classifier is paper documents and chat screenshots. These classifiers are interesting because both files can contain relevant information to the investigation. So, to view this classifier data set with about the 13,000 documents, image such as papers, bank statements over the documents with detection.
To chat screenshot detector we viewed the data set with about 8,000 images. And we increment the data set with 9,495 negative images. We set by two thousand images for validation. And the tests are realized with the data of real lab test with, uh, 8,783 image, which 283 images are documents, and 87 are chat screenshots. For specifier we used the transfer learning on InCeption V3 and retraining the model on the final weights [phase?] of the network.
So, for the nudity data detection, we use Nude Net, which is an open source neural network for the classification, detection, and censorship of nudity in images. The purpose of this detection is to assist in the identification of sexual abuse and paedophilia. We tested this tool with 176 nudity images.

For face detection we use Python’s library face recognition to extract feature vectors from images present in the evidence to identify possible known criminals from the evidence.
The problem with this solution is that the search space is massive, so provides problem. When you use the K-Means [cluster] algorithm, they all went to a similar face and speed up the search. This is possible because when we search our facing database process, we can scan a large part of this dataset and searching smaller sets and drastically reduce the number of comparisons.
So the last component in the architecture is the serving layer and this layer is responsible for storing all data and offers mechanism for data visualization. In this we developed our web interface to access our data visualisation dashboard with relevant information about the test … Some sharp informed data about results followed by the classifiers and all the details on evidence data search has now emerged number of chats, emails and all.
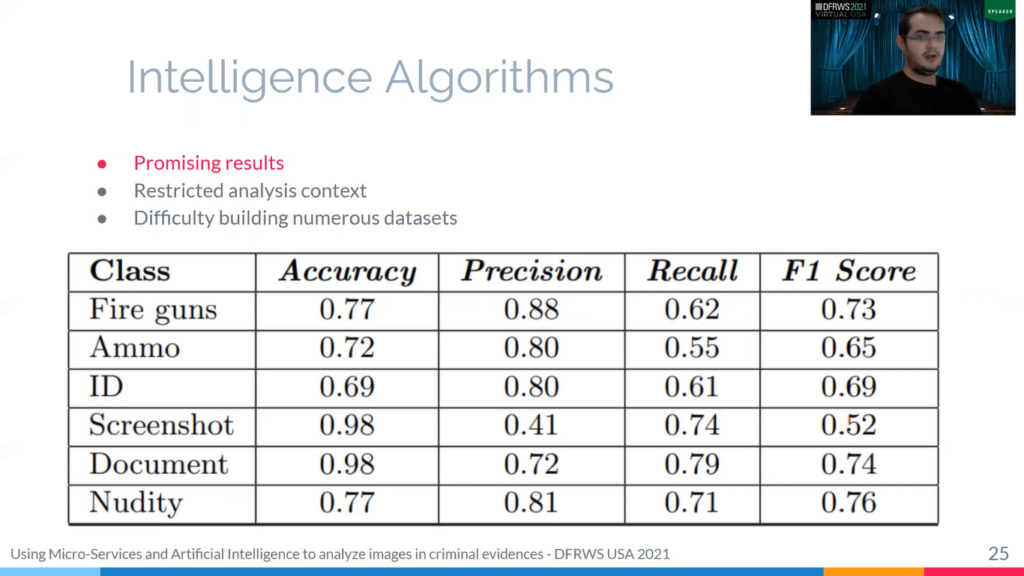
And now I present some results with this platform. First we obtained promising results with the developing an intelligence algorithm. Analysis context is rather restricted and difficult to get the numbers dataset. We manage to create classifier with a very good level of accuracy and precision. I think that they were, , the vast majority of the results, about 70%.
They come in with a big time reduction of the face dataset with dashes, with linear search and with different cluster numbers of 200 groups. And as we cannot see the number of clusters influences the time to find a face. We run 500 rounds of tests were performed by searching in a database with 7,602 storage spaces. And, and we noticed that after 10 groups, the average time to search a face does not have significant improve with more groups.
So comparatively with the linear algorithm with 10 groups, we can find a face about 10 times faster. After we realized testing in this speed layer, we conclude that Spark provide image processing approximately three times faster than the serial processes. The speed layer processes close to two images per second.
So evidence with 30,000 images can have all these data analysed in four hours and 30 minutes. An analyst finished analysing these images in several days using that data extraction method.
So we can conclude that this platform has a high potential to speed up the investigation evidence process. Lastly, we managed to build the big data platform to analyse data from criminal evidence and the proposed architecture allows that many analysts can access this same evidence without the need to load the files in local machines. The development of intelligence algorithms offer solutions to speed up the analysis time and the microservices architecture offers modularity and flexibility to the system.
Thus we can remove [?] or new APIs in the platform we found around the rest of this issue.
Thank you very much for your attention and any questions can be sent to this email: gbrsouza20 at gmail dot com.





