
by David Spreadborough, Forensic Analyst at Amped Software
Police Officers and investigators have to deal with video all the time. It is one of the most common forms of physical evidence. However, even in 2024, digital video is not without its challenges. In this short introduction to a new information series over at the Amped Software blog, Forensic Analyst David Spreadborough examines some of the key points.
Many of you may have seen our previous blog series on CCTV Acquisition. Over the past year, it has prompted many further questions from those investigating video and CCTV. The vast majority of those concerned several core video components and the tasks required to ensure integrity during any conversion stage. An informative series on video formats and conversion was therefore born.
We have broken it down into four main articles, with an introduction post already available. During the series, we will cover:
- Proprietary data
- Codecs and formats
- Conversion
- Decoding
Proprietary Data
The video originating from CCTV and surveillance systems forms the bulk of our video workload. There are several reasons why, and during the series, we take a step back in history to examine the decisions made in the transition from tape to digital files 25 years ago. Understanding those decisions gives insight into why certain processes are required to be completed today.
Most video luckily starts in a standard form. Although some data gets modified, the majority retains the important puzzle pieces of that standard.
However, multimedia requires a container and this is where most manufacturers make their modifications. Again, there are understandable reasons why, but if you link that with the knowledge that they do not need to publish these changes then it does get a little confusing.
The way that a manufacturer formats their data must then be researched so it can be used correctly during an investigation.
Think of individual jigsaw puzzles, all correctly boxed, with a picture of the finished puzzle on the top.
Now imagine 16 of these, but all the pieces, of different sizes and connections, are all in one big container. And there are no pictures to help sort and put them back together.

That’s the world of CCTV! Luckily, as we will learn later, there are solutions to this challenge.
The technical term for diving into a CCTV file and sorting all the puzzle pieces is, “The Lossless Extraction of Data from Proprietary Formats”.
That data consists of video streams, audio streams, and data timestamps relating to the captured moments in time.
Some of you may be thinking that you just use the player that came with it.
To quickly preview an incident and ensure that you have the data you require, a proprietary CCTV player may suffice. However, the shift over the past 10 years from video presentation to forensic video analysis was partly because most player applications have limitations that can cause evidential problems.
Some of the most common challenges when having to deal with proprietary players:
- Installation requirements
- Different versions for different codecs
- The sheer number of different players
- Requirements for old operating systems
- Limited playback control
- Uncontrolled scaling of the viewer
- Hidden in-player processing
- Skipping/dropping frames on playback
- Cropping of video
- Poor color/luminance presentation
- Only single-image export
- Video export adding further compression
- No native export
- No data information
- Difficult to use
The most problematic to the analyst is when the player does things to the video without telling you. The hidden in-player processing is unfortunately very common and it hides the “real” image from the viewer. For this reason, screen-capturing quickly dropped down the list of conversion methods many years ago. Yes, it is required in extreme circumstances, but it’s a last resort.
Codecs and Formats
When there is a requirement to convert data originating from a proprietary format, we must know how to maintain integrity. In the post covering Codecs and Formats, we take a deep dive into many of the common encoding types being used within our forensic field today. The information will help us make the right decisions later on.
We start with image compression, as this is the task of the Codec. Codec stands for Coder/Decoder or Compress/Decompress. It is a clever 2-part process. Decisions can be made on how to code/compress something if that can be added later during the decoding/decompression stage.
And this is the reason why analysis is so important when using video for legal purposes in an attempt to prove facts.
With video, you are viewing a digital representation of a scene, object, or event. It is not a person, a vehicle, or an item, but a collection of small pieces of color that your brain interprets to be something. You must then consider that one of the purposes of compression is to remove as much data as possible without being too noticeable. One of the methods to achieve this is to fool the brain, and remove information that our brain can make up! Add to this the many visual defects that happen during the video generation process and you can easily see why some people make mistakes when viewing and interpreting small detail within footage.
This brings us nicely to “The Forensic Line”. This is where viewing footage must turn to forensic video analysis. How do you know if you need to cross that line? It is the moment you ask a question about what you are seeing.
“Is it?”
“It could be?”
“It looks like…”
At that point, being aware of compression will help you make the right decisions, and the video can be sent for further analysis if required. This ensures facts are presented within a legal environment and not as subjective opinions based on what the viewer believes.
Conversion
After gaining insight into why most of an investigator’s video starts as volatile digital data, we learned about the codecs used and how they require correct formatting. This will help us when we move to the next article on conversion.
Conversion has two main aims:
- To enable the complete analysis of the multimedia and associated data (time).
- To enable the further processing of the multimedia, ensuring presentation authenticity through restoration and enhancement.
When dealing with the proprietary data we looked at earlier, there are several stages to the process that ensure the data is not changed.
Identify:
Identification of the format is not the same as simply reading the file extension. File extensions are not controlled. Any developer can name their file type with any extension. Consequently, there could be several different formats, requiring very different data extraction techniques, but all having the same file extension.
Extract:
The first thing is the unformatted video. Rather than one big chunk, where it may be all mixed up, we need to separate the camera streams. This ensures that other videos, the date and time information, or other metadata do not corrupt and interfere with the correct decoding.
Next, we have the date and time information. This must not only be extracted but referenced to the frame numbers in the video.
With other formats, there could be audio data too.
Format:
After the data is extracted, it must be formatted correctly, using an open standard. The video therefore may be placed into a compatible container, such as Matroska (MKV). For the date and time, our .time file format is simply open text with Frame Number > Frame Type > Date Time.
From a single proprietary file with no audio, four other files are commonly created.
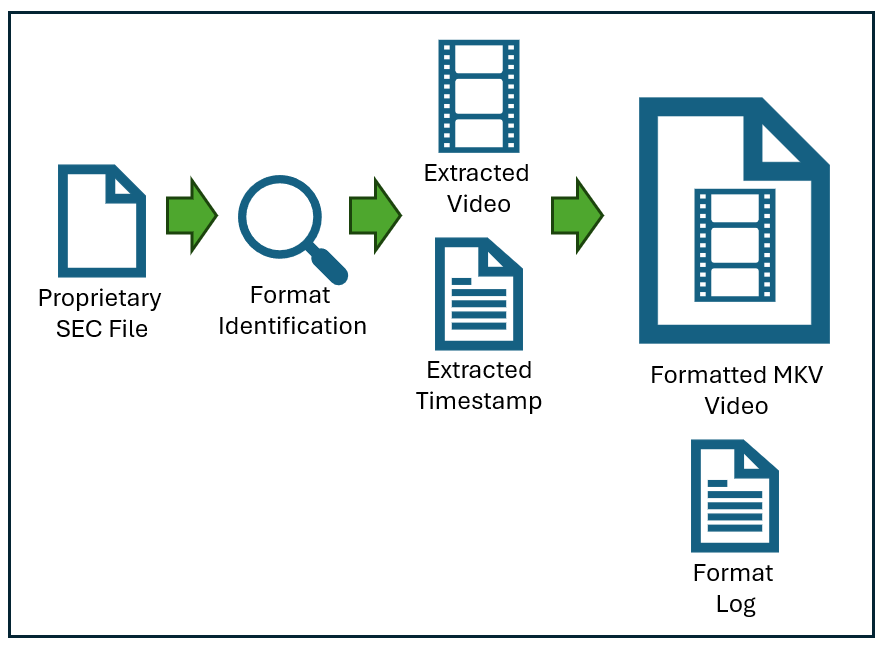
- Extracted video
- Extracted timestamp
- Formatted MKV
- Format log
The great part is that, rather than having to do all this manually, it is all built into the Amped Engine.
Decoding
Now that we have a correctly converted video file, in a standard container format with no loss in visual quality or evidential integrity, we can analyze and view it.
However, we have learned that compression is a 2-stage process, and there are several ways to decode/view a video.
There are various decoding libraries. Microsoft has some, Apple has some, and different applications use different libraries. All of these play a part.
In the last article of the series, we compare some of the decoding engines in Amped FIVE and look at the differences.
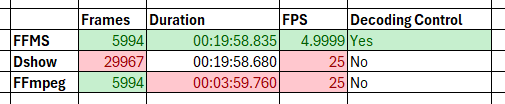
It’s not just how the video is played back, but also having control of how it processes luminance and color.
Both of these image components can be analyzed and changed if required. This is especially important when attempting to restore and enhance dark video. If the luminance is not handled correctly, no amount of processing will recover data that the decoder didn’t know was there.
Conclusion
We hope you have enjoyed this preview of the new series. Remember, the introduction post is available now, so head on over to learn more. Don’t forget to subscribe to the blog, so you’ll get a notification of when the next posts in the series are released.





