
In the following article, Martino Jerian, CEO and Founder of Amped Software, will introduce the Image Generation Model. He will discuss its importance for professionals in the field of video forensics.
The generation of digital images is a complex process that involves physical and digital components. This produces an encoded representation of the light information from a given scene, in the form of 0s and 1s. However, due to technical limitations with imaging systems, this representation may differ from what was initially present in the scene and can be less intelligible when used for investigative purposes. To address these issues, image generation models have been developed in order to detect any introduced defects, followed by corrective methods that ensure an accurate valid representation is obtained.
Why do we need the image generation model?
The image generation model is something Amped Software has been teaching in their Amped FIVE training classes for years. Its understanding is a crucial step toward mastering forensic video enhancement.
Furthermore, knowledge of the image generation model can help professionals confidently explain their processing and manipulation activities to courts where such evidence is used. By correcting defects that are created during capture and obtaining a more accurate representation of the scene (or subjects or objects) compared with that of the original material, practitioners may demonstrate how their efforts aim at reconstructing a faithful representation of what has been captured. To those coming from traditional forensics domains, this could be thought of similarly to conducting fingerprint analysis using reagents — only in this case non-destructive steps are employed in order to achieve repeatable results.
What is the image generation model?
The image generation model represents a conceptual understanding of how the light coming from a scene in the physical world is converted into an image, and in the case of a digital image (or video) ultimately a sequence of 0s and 1s.
The image below summarizes the various phases of the image generation model: scene, camera, storage, view, and their respective subphases.
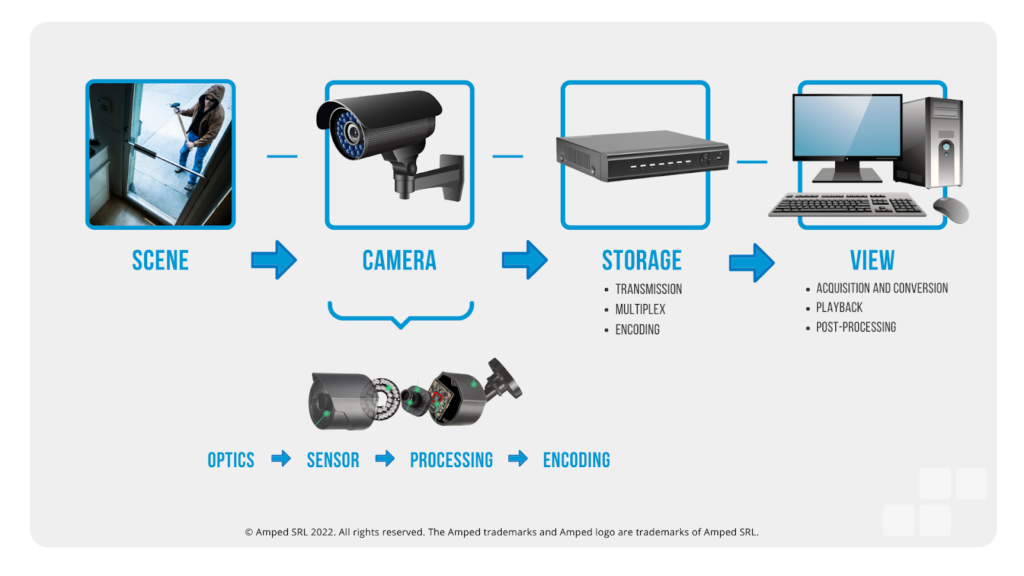
In each step of the process, there are technical limitations that introduce some differences between what would be an ideal image of the real world and the actual one out of/from the imaging process.
A very straightforward example is the lens distortion introduced by wide-angle lenses: straight walls appear curved in the image because of the features of the camera optics. Since the actual walls are straight, and not curved, the distortion correction allows producing an image that is a more accurate representation of the real scene.

Many different defects are introduced in the various parts of the image generation model. Understanding the actual model for a specific case and which defect is introduced at each stage is key to scientifically enhancing the image.
Amped Software decided to use the word defect as a general term to describe any kind of problem, issue, or disturbance of the image. There’s no specific technical term generally used for this variety of topics, due to the technical limitations of the imaging process, so they opted for this word.
In the following, Amped Software will refer to a generic case where a scene is taken by a Close-Circuit Television (CCTV) system, encoded in a Digital Video Recorder (DVR), and later displayed. The actual situation may vary from case to case, and it’s important to be understood by the analyst. The image generation model for an image acquired by a digital camera or smartphone will differ, but the same general concepts hold.
What are the various phases of the image generation model?
At a macro level, the following are the phases of the image generation model:
- Scene: this is the actual scene or event happening in the physical world, whose reflected light is going to be represented in the image.
- Camera: the light coming from the scene passes through the camera optics, then hits the sensor, which converts the light into a digital signal; this is then processed in various ways inside the camera and encoded into a usable format.
- Storage: the signal coming from the camera is transmitted, potentially multiplexed with signals from other cameras, and encoded in some way by the DVR, which usually includes strong compression.
- View: while the image has been technically generated at the previous phase, actually further processing is often needed to be visualized by the operator; depending on the system, acquisition, conversion, and playback are typical steps that need to be taken into account.
What defects are introduced at each phase?
Read the full blog post here to download the table summarizing all the defects and possible solutions, in the right order according to the image generation model.
Conclusion
It is essential that the notion of this topic shall be considered a cornerstone of their training courses and that greater efforts be made to ensure its widespread comprehension within our industry.
Should you be interested in further info regarding this matter, feel free to contact Amped Software.





