What if you could automate digital forensics processes, centralize them, and then offer them at scale through the internet? Researchers at the Netherlands Forensic Institute (NFI) set out to answer the first question—then took the path through the second and third.
The Hansken “digital forensics as a service” (DFaaS) project is currently in its 10th year, recently opened to the international community and is continuing with research on some of the most pressing digital forensics questions of our time, including how to apply artificial intelligence.
Hansken is the oldest of a trio of international DFaaS projects, which include incident response-oriented counterparts Peritus—designed by researchers with the Brazilian Federal Police—and Netfox Detective, also based in the European Union.
Unlike those projects, though, Hansken focuses on digital forensics in criminal investigations. Following the conclusion of his series of papers about the platform and how it works, Forensic Focus spoke more with an NFI senior digital forensic scientist, Harm van Beek, about Hansken and what it is bringing to the digital forensics community.
The beginning: automating forensic tools and processes
The NFI isn’t only a research body. It also has an investigative branch responsible for reviewing evidence that’s being presented in court, especially for appeals. When questions arise around any type of forensic evidence, judges may refer the case to NFI to review, report, and if needed, testify as expert witnesses.
“It depends on the judge and… on the complexity of the case,” Van Beek explained. “It’s not that we can do better research or better case investigations. It’s because we are independent from investigative organizations and… from the prosecution office.”
Over time, as the NFI’s investigators evaluated cases each year—Van Beek estimates a range of 50 to 100 cases—they found themselves performing similar tasks and processes over and over. Automating those tasks would free them to do other work, so they initiated a research project to come up with a solution.
That was in 2005. Originally the project was an internship with a goal to interconnect several NFI-developed tools. The project caught the eye of the Centrum Wiskunde & Informatica—the Dutch National Research Institute for Mathematics and Computer Science—and the internship, extended through Dutch government funding, sought a way to automate concurrent or sequential data processing using NFI-developed tools.
The new solution was named Xiraf, and the NFI offered it to Dutch law enforcement agencies including the Dutch tax fraud investigation organization and the Dutch national police. In those years, said Van Beek, the different agencies asked the researchers to implement any functionality they wanted to add.

The project was successful enough that other agencies became interested, asking whether they could likewise interconnect their tools and solutions to the new platform. “That’s where we started thinking of using APIs to allow others to plug in their tools or solutions,” said Van Beek.
As more agencies came on board and researchers began to add third-party tools, though, knowledge sharing became increasingly essential. Redesigning the Xiraf R&D project to open its platform made it possible for others, such as universities, to use the APIs to interconnect their own tooling. “Their goal is not only to use the platform as an instrument, but also as a means for getting their results to work in practice,” Van Beek explained.
Integrating tools for a powerful—and defensible—knowledge base
Now named Hansken, the new platform started out in 2012 relying on the NFI’s tools, but as the project progressed, the researchers realized the benefits of including third-party tools. “A good example is that there was a need for supporting the Apple file system,” said Van Beek.
Rather than develop a new implementation, he went on, the Hansken team “wrapped” The SleuthKit, which supports APFS, for integration. “So now, if we run into an Apple file system, we spin a SleuthKit process to provide the data and extract the metadata.” These artifacts are then brought into Hansken to continue analyzing the results.
Another example: checking whether the clock on the computer ran on time. By combining the analyzed artifacts, said Van Beek, it’s possible to show points at which the computer ran on time, ahead, or behind.
The idea is to automate the capture of those artifacts so that other investigators can apply the process to their cases. “If an email is found and the timestamps are disputed, you can easily get a report, whether or not the computer or the clock or the machine this artifact was found on can be trusted,” Van Beek explained.
By now, Hansken consists of about 100 such implementations including:
- Tools that understand data structures. “They can extract what would be called traces or artifacts out of raw data,” Van Beek said, giving the example of a tool that extracts an email from an email database.
- Optical character recognition (OCR) from text and pictures. Likewise wrapping a third-party tool, this time from Google, said Van Beek, “We make it possible to get the results in the data model so that Hansken can store the results.”
- Artificial intelligence (AI)-based tools to help reduce large datasets, particularly pictures. The NFI’s data science group has trained AI models using known datasets to support specific needs, such as identifying shipping containers to help narcotics investigators.
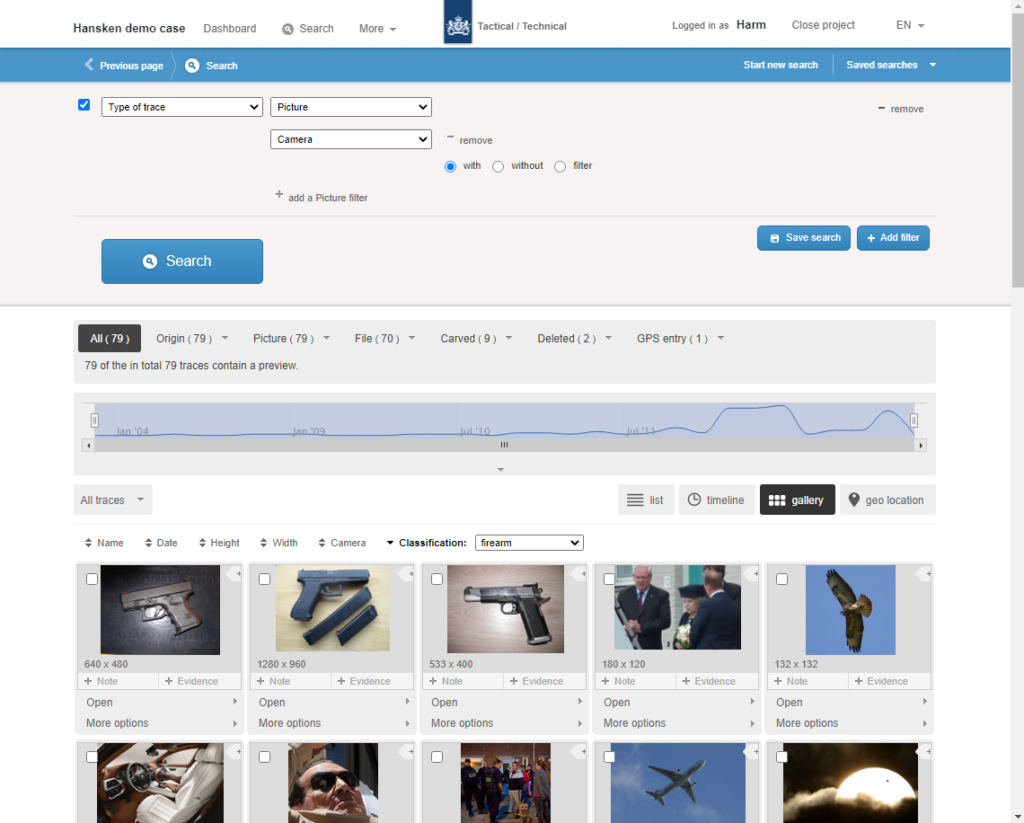
Applied in the aggregate to each piece of data, these tools collectively make for a powerful, growing knowledge base. “And so by now we have over 100 tools that, combined, give a very detailed view on the data,” Van Beek explained.
For example, a case investigator could use Hansken to “get camera data from a JPEG picture in a ZIP file attached to an email in a BSD database in a virtual machine in a file system”—all automated, without having to enable a single one of those tools.
From there, external tools connected to Hansken via API can visualize or graphically represent connections—such as email contacts—out of massive datasets, which could enable investigators to identify key persons.
Once fully processed, the data are stored in Hansken’s central database so that they are available to other investigators. With 1,000 CPUs and more than five terabytes of combined RAM processing in parallel, said Van Beek, “We end up with a database with maybe 10 million artifacts, but they are fully indexed. All metadata is there. We hardly ever need to post-process material, and that makes it really powerful to case investigators.”
It’s also easier for courts to evaluate digital forensic process. Van Beek described one significant challenge he participated in as an expert witness. “There was discussion in court on how the data was processed in the first case,” he said. “They really challenged everything in this process.”
Ultimately, the court agreed the process was solid and the evidence was trustworthy enough to be admitted at trial. “In the other cases, there’s no longer a discussion in court…. The judge has decided that this processing is okay and we use the same process and we can show we use the same process.”
Thus Hansken isn’t a knowledge management platform in terms of “libraries with written papers on how things work in digital forensics,” said Van Beek. Instead, the project seeks to automate the processes described in existing papers, as well as reference implementations on GitHub.
“We try to support the majority of the artifacts we see,” Van Beek explained, “like the common file systems, the common communication applications, like Microsoft Outlook for emails and WhatsApp for chats, for example.”
Like most other digital forensics tools, Hansken doesn’t support all searches. “One of our primary principles is we don’t want to reinvent wheels,” said Van Beek. “So if there’s a tool available and we can use it, then we will connect it to our systems.” This is done mainly on user request.
It also doesn’t run recursively over existing shared, saved artifacts or images, even after new tools are added. “We don’t do that by default because it might frustrate investigations,” Van Beek explained, giving the example of an investigation nearing completion, only to be presented with another million emails. “More is not always better in this case.”
On the other hand, bug fixes that could affect evidence—such as timestamp errors—do offer the opportunity for investigators to revisit data at their discretion.
Practical knowledge sharing: case investigative details
Along with tool development and knowledge sharing around data extractions, said Van Beek, the Hansken development team has focused on end user experience, putting investigative information in the platform so that case investigators can use and share it.
Yet as Van Beek has reflected in papers he’s coauthored on the topic, Hansken is very different from a traditional digital forensics lab environment. A one-day course helps investigators to smooth the transition from the traditional to the new platform.
Part of this: understanding new efficiencies, such as access to material. Before, said Van Beek, “They could ask digital experts to provide all the email from computer or all pictures from a phone and then get a report,” whether it was written or an electronic share.
They didn’t have direct access to the data, though, and that could result in confusion. “They had to think of the question in advance without knowing what’s in there,” he explained.
Hansken removes the data silo via web interfaces, which are currently offered in Dutch, English, German, and Spanish. “We tried to make it as easy as possible for everybody involved in an investigation to do their job,” said Van Beek, which means reducing the amount of back and forth between investigators and digital forensic examiners.
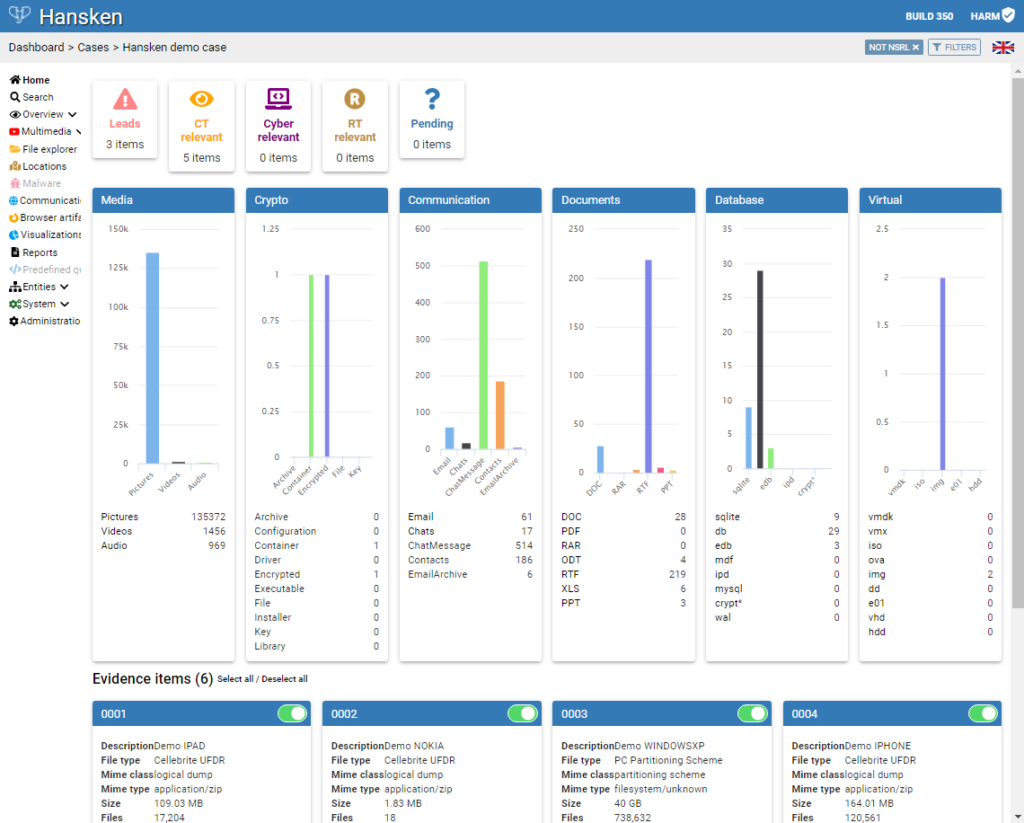
To that end, the interface makes it easy for investigators to use case investigative knowledge—suspect, victim, and crime information—to query, filter, and annotate artifacts in a dataset in much the same way they might shop, order food, access email, or other activities online.
“If there’s a question on whether this email was actually sent and you look at the header from an email routed through Google servers, that’s a question we can answer in an automated manner. You should not need to go to a digital expert for that,” Van Beek explained. Currently being researched: how this can best be automated in Hansken.
At the same time, though, those queries often give rise to additional questions about the artifact’s origin. “These are the forensic activity level questions,” said Van Beek. “How did this piece of evidence end up on this machine? Was it typed in by the suspect? These are difficult questions that we don’t have any automated solution for.”
In-platform discussions with colleague investigators or digital experts help close the gap. “For example, they can annotate an interesting email… to have a digital expert find out if the timestamps were right, or if the email was actually sent, or if the sender can be trusted,” said Van Beek.
This way, digital experts can focus more on those forensic activity level questions that can help put the suspect behind the keyboard or device.
But Hansken isn’t designed to complete an investigation, Van Beek cautioned. “The closer you get to the suspect—and that’s the person, not his iPhone, in court—the harder it is to… interpret evidence in the context of the case and the more you have to depend on your experts for the more basic questions,” Van Beek said.
“We still tell users, even though the process can be automated, still have your experts involved, since data changes… apps and operating systems get updated. So even though we apply knowledge we have from the past, it might in this specific case for this specific device, still be wrong.”
The challenges compound when it comes to knowledge or information sharing between agencies. That’s partly because of IT security challenges like firewalls, but also because the examiners aren’t used to sharing it. Traditional digital forensics tools are built to “sandbox” case results, keeping one set from contaminating another.
In this context, not everything should be shared with everybody, said Van Beek, because individual privacy—rather than organizational—is at risk. Investigators need ways to exclude private user data from that which is relevant to their cases—not just existing forms like timelines or content categories, but more specific ones too.
For instance: privileged communication between an individual and their doctors or attorneys. After a court ruled that case-relevant Hansken data must be made available to defense attorneys and their clients in the name of quality assurance, said Van Beek, this ability became even more pressing.
The Hansken team needed to find a way to filter the dataset by keywords or artifacts—including contraband—without denying access to relevant material. In collaboration with the Dutch prosecution office, the team came up with a labeling process that makes it possible to automatically exclude privileged artifacts.
Moreover, data changes limit even automation. “I personally think it’s impossible… to think that you can automate the entire process in a way that can be fully trusted in court and give you full details on what artifacts mean in your case,” said Van Beek.
Hansken’s future: automation through community
Currently, case investigative analysis takes place outside the platform, said Van Beek, using scripts or technology against APIs on the platform. “We are now at the point that we also want to put this knowledge in the back end of the platform and provide access to it via the API,” he said.
It’s a complex “layering” approach to digital investigation, which Van Beek said has been more of a challenge to automate than extractions themselves. “The biggest issue there is performance,” he explained. “We have a lot of data, we have a lot of tools and we have limited time. So how can we do that?”
He offers the example of, again, a computer’s clock running on time. Hansken’s artifacts are based on the knowledge of how machines work, but upgrades, differences in operating systems and versions, and other variables can all confound analysis, said Van Beek.
“Checking if the clock ran on time on a Windows machine is different from a Linux machine is different from an iPhone,” he explained. “And it’s also different from an iPhone 10 or an iPhone 11 or an iPhone 12. So such knowledge is not easy to capture and reuse.”
At the same time, though, this kind of testing is labor intensive, “and we do it over and over and over again because we’re shooting a moving target,” said Van Beek.
“So what we are doing is trying to find a way to capture this information, and not in the report that cannot be reused or automated or scripted again, but in a manner that we can still access this knowledge and this information in a programming way.”
In other words, the developers want to find a way to capture the result of an expert’s case-specific findings, then generalize it and replicate it so it can be used on other cases.
One solution for evaluating evidence and putting it in case context could be AI, but Van Beek said this is “tricky” because experts have to be prepared to explain in court what they did and how it works.
Researchers at NTNU – the Norwegian University of Science and Technology / Centre for Cyber and Information Security (CCIS) have been exploring “explainable” AI techniques for use with evidence evaluation. In court, said Van Beek, experts could explain “why a shipping container was identified as a container, or not.”
Even as all this research is being applied, Van Beek says Hansken is still a “monolithic” solution compared to its community-oriented product vision, which will create more of what he calls a “supply chain” decided on, supported by, and easily provided to the entire community.
It starts with a community-backed reference model: an extension of the DFaaS reference model Hansken has relied on for the past decade. The model would underpin a community-wide API that would allow anyone—from commercial vendors to individual researchers—to provide different parts of the overall process, decide on additional APIs, tools, and methods, and the way they all interconnect.
Effectively, said Van Beek, this would open Hansken up to “tools independent of who developed it, or where it was developed or how it is shared.” Part of that is the adoption of standards like the CASE ontology, he said, “so that not only knowledge between users of Hansken can be shared, but also that we can share or interconnect results from other tools to the platform.”
Inspired by Hansken’s model, the CASE ontology is designed to express artifacts, including their governance. To do this, though, digital forensic tools need to support CASE. “As in,” Van Beek explained, “they can export CASE expressions, then by exporting them, all the tools can import them and continue the processing.”
This is anticipated to surmount the lack of interoperability between tools, or as Van Beek put it, “getting results from one tool uploaded in the next tool.” “Hansken supports UFED reports and XRY reports,” he explained, “but we have to implement two separate pieces of code to support the two formats.” Likewise, the tools have to be updated separately within Hansken.
By supporting CASE, instead, only CASE updates would become needed. “But as long as the tools keep providing this, this standard representation, we can import the results,” Van Beek continued. “And that reduces a lot of the efforts we have to do right now to keep everything up to date.”
Making the business case for DFaaS
Van Beek’s final publication on Hansken detailed the difficulties of making a business case for DFaaS—even for a platform that streamlines investigations. “The biggest problem… is that the costs for setting up a platform like Hansken are very clear,” he explained. “You have to buy hardware, you have to get people who know what they are doing since they are working on this one platform.”
Some of the technical and organizational challenges are addressed by the OK Hansken program. This 3-year program focuses on delivering more professional Hansken services, support, documentation, trainings and building a Hansken Community where users can share experiences and knowledge.
This makes it easier for organizations to deploy a Hansken in their own environments. “It’s quite some effort to set it up because it’s a big platform,” said Van Beek. “So we want to reduce the efforts needed for getting Hansken up and running in your environment, and we want to make sure that users understand how to use it.”
Another part of the challenge, though, is demonstrating efficiency gains when no two cases are alike—even in the same category of cases—and investigators can’t re-investigate a case just to compare the Hansken platform with a traditional method. “You can do that for demos or for setups to measure it once. But in practice, you can’t really do that,” said Van Beek.
Likewise digital forensics experts. Van Beek said automating parts of their work frees some time, but those examiners still need a platform to store their results. Why, managers might ask, would they spend limited budgets on a much more expensive centralized storage solution, when standalone computers work perfectly well—and might even be better for some use cases, such as basic mobile device examinations?
“And do digital experts get better results using a platform, or do they still get better results using traditional tools?” Van Beek questioned. “Better” results might simply be the outcome of having used a traditional tool for 20 years, while managers gloss over the fact that the tool’s results were not available to the case investigator. In contrast, making a platform like Hansken available to investigators for true collaboration between them and forensic teams can facilitate cases both large and small.
“Those benefits are not really measurable in euros or in dollars or in time,” he said. “It’s measured in maybe better evidence, or more evidence, or more directed evidence.” The reverse—police making a business case for existing solutions—is difficult because the costs for doing similar investigations are scattered across both teams and the hardware they need.
On the other hand, Hansken’s centralized platform has been the only way to manage huge datasets that are relevant to many different cases. In fact, Van Beek said, a currently used dataset was seized in Canada.
There, a judge sought to limit the data’s use in criminal cases in the Netherlands. Originally, the order was to provide only subsets of material, based on keywords, to a prosecutor seeking the information.
“But the nature of the material is not such that we can easily make and provide a subset of the data,” said Van Beek, “since they want a subset of the artifacts such as email databases, and the structures of email databases are really complex… one email is not sitting at one place, but it’s scattered over the file.”
The Hansken team collaborated with prosecutors to come up with the idea to partially clone the indexed dataset, in part, “so that we can give investigative teams access to part or parts of the artifacts,” said Van Beek, “without having to duplicate or re-index everything over and over again.”
The material in this single dataset has now been used in more than 100 cases, with 100 investigative teams working in one platform or one dataset apiece. Van Beek said it would be “almost impossible” to replicate this work with the original images using traditional tooling.
Ultimately, Van Beek said, DFaaS is likely to move to the cloud, though that could take time because agencies lack trust in the cloud for seized evidence. Still, he said, “as the cloud evolves and gets more secure and gets better and better and better, I think in the end, everything will be moving to the cloud. And this includes storage solutions for investigative organizations.”





