Introduction
Creating test material for computer forensic teaching or tool testing purposes has been a known problem. I encountered the issue in my studies of Computer Forensics at the University of Westminster. We were assigned a task to compare computer forensic tools and report results. Having already analysed test images by Brian Carrier (http://dftt.sourceforge.net) over and over again, I found myself creating images manually, which appears to be the best and only way of doing this. One of my lecturers, Sean Tohill, confirmed this is indeed the case and a test image generator is long overdue.
The need for such a tool is twofold. In educational setting, the problem of plagiarism can be mitigated by giving each student an individual image to analyse. In application quality testing, one of the tests should be to feed several similar but not identical images to the forensic tool, and compare results, which should be identical.
Designing and writing such a tool became my MSc dissertation project, which I have now completed, and Mr Tohill became the project supervisor. One of the outcomes was an application, which creates images based on a scenario defined by the user. Each image representing the scenario is slightly different but they should all be equal in complexity, allowing their use in education and software testing.
This article describes the project and introduces the resulting application, which I have released under GPL for anyone to use or modify. The tool is available on Github (https://github.com/hannuvisti/forge.git). It is guaranteed to work on Ubuntu 12.04 but other linuxes are probably ok as well as long as they have /dev/loopX devices for loopback mounts.
Design principles and choice of tools
The original design had two objectives: to create forensic test images based on scenarios with a random element added, and to design the tool in such a way that it can be easily extended without modifying existing code. This led to the following set of requirements:
- Create NTFS file systems – FAT12/16/32 would have been another option but NTFS was chosen due to personal interest and detailed timestamp handling.
- Provide web browser based user interface to create scenarios, initiate image creation and display image contents.
- Modular design – file system code and actual data hiding methods should be outside the main processor loop. Their interface must be documented to allow addition of new file systems and data hiding methods.
- Implement several different data hiding methods to provide a proof of concept.
- Allow timeline management in scenarios – design the application to protect against timeline contamination due to file system operations by the application.
- Provide means of automatically creating variance between images
NTFS suits well to object-oriented programming due to its design. Due to time constraints, programming languages and tools were not thoroughly evaluated. After a short period of tests and prototyping, I chose Python 2.7.x as the programming language over Java, mainly because of Java lacking unsigned variables.
User interface and database connectivity was built with Django. Django is a complex framework but its built-in “admin” interface gave the database administration part used in scenario design without programming effort.
Building a scenario
The only requisites and preparatory actions are database initialisation – in practice inserting file system and data hiding method information to the database for modularity purposes – and uploading of raw material files. The application provides means to complete these tasks. Database initialisation should be done once after initial installation. Raw files can be uploaded any time and shared between scenarios. Raw files are categorised to “trivial files” and “secret files”. Trivial files are used as bulk to populate the file system with irrelevant information. These files are categorised automatically by their kind; picture, audio, executable, document etc. Secret files are the ones used in data hiding methods. The user must assign a numerical “group” to these files, for reasons that will become apparent later.
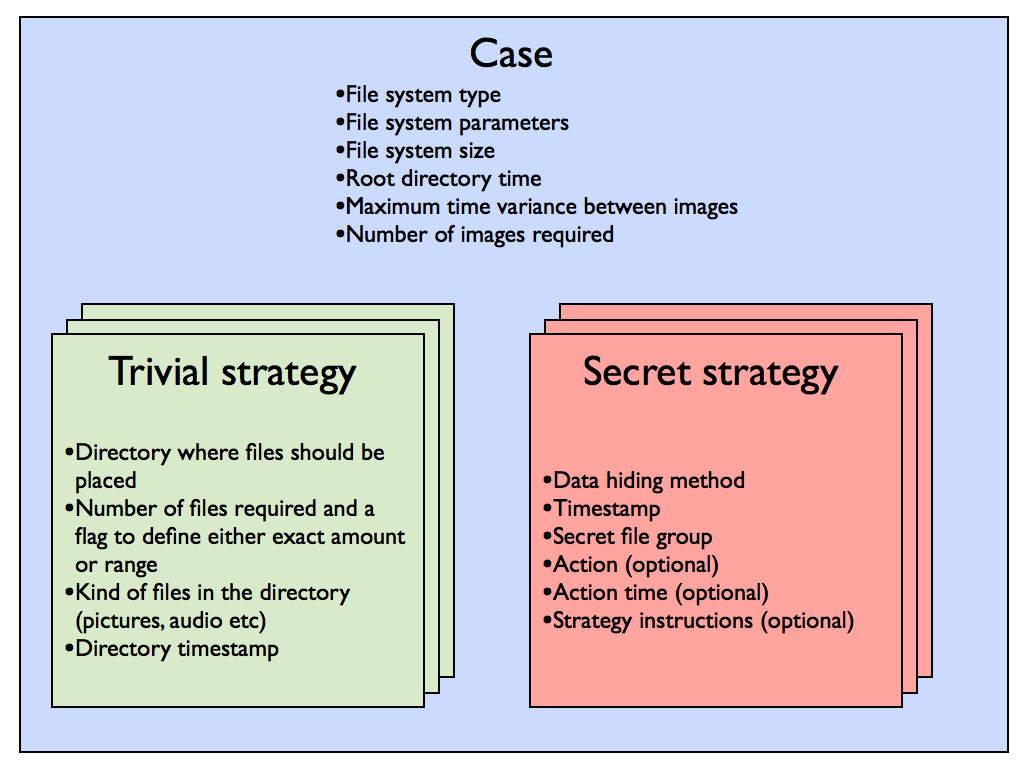
Case
The core of a scenario in ForGe is called a case. Case defines file system level parameters. Currently only NTFS is supported, FAT is already in the pipeline. Each case can create several images that all fulfil the overall scenario but are not identical.
Trivial strategy
Trivial strategies instruct the creator how to build the bulk or uninteresting part of the image. There can be as many trivial strategies in a case as the scenario requires but at least one trivial strategy must be present. Secret strategies generally require “raw material” on the image and this raw material is provided by trivial strategies. Individual files are chosen randomly from the trivial file repository according to “kind” parameter.
Secret strategy
Secret strategies implement data hiding methods to images. Currently implemented data hiding methods are:
- Alternate data streams
- File extension change
- Concatenation of files
- Deletion of a file
- File slack space
- “Not hidden” – just place the file to the image.
While a trivial strategy places several files to the image, a secret strategy always operates on exactly one file, which is chosen from the secret repository according to a “group” parameter. If a file is unique in its group, the file is always placed on the image. This allows scenarios where all students must locate certain files, but also scenarios, where the file is chosen randomly from a pool.
Hiding methods have additional “action” and “action time” parameters. If these are present, MACE timestamps are modified to correspond to the chosen file action, for example read, copy or rename.
Timeline management
ForGe manages timelines by modifying raw file system data on an unmounted image. This avoids contamination of timestamps, where a disk operation to modify files or timestamps change one or more timestamp parameters. On NTFS, both $STANDARD_INFORMATION and $FILE_NAME attribute are modified to correspond to file time or action time. The current version does not modify timestamps in directory indices but I will add this to a near-future version.
A case can contain “time variance”. If this is set to 0, every image gets an identical timeline. Upon a non-zero time variance parameter, a number is chosen randomly between 0 and time variance parameter to each individual image. This represents number of weeks added to each time attribute on the disk. The benefit to have time variance in weeks is in preservation of time of day and day of week. If an educational scenario were based on something happening on a night between Saturday and Sunday, this would be the case on every image, just different weeks.
Results
ForGe reports either success or failure for each created image. Failures can occur on some or all images if for example the file system runs out of space. ForGe can also be used to print a “cheat sheet” to display the contents of an image.

The cheat sheet displays the results of trivial strategies (/pic and /docs directories). Hidden items explain, which files have been hidden and where. For example, scotland.png can be found in an alternate data stream of file /pic/IMG_8568.jpg. England.png is hidden in file slack and could be extracted with command
dd if=hidingmethodtest-1 bs=1 skip=12720128 count=1353 of=england.png
Targets and locations for hidden items are chosen randomly, making each image representing the scenario similar but not identical. The images should be equal in complexity as well, as the same data hiding methods are used throughout the scenario, only locations, timestamps and possibly source files vary.
Extending ForGe
To create a new data hiding method, a new Python class must be created. The class interface is very simple and included in documentation. Basically, the class must implement a method hide_file that takes the file and parameter array as parameters, and returns a set of instructions or raises an exception in case of failure. This new class must be declared in database but existing code needs not be modified.

The image illustrates this. The required database elements are path to the file to be included and name of the data hiding class. Priority must be set as well and equal priorities are allowed. This is to ensure the image creation does not contaminate itself. For example, if a file were hidden into file slack and the file deleted, and then another file would be written on the image, it is possible the file would be overwritten. Thus, priority one methods are those that modify a mounted file system directly. Priority 2 handles deletions and priority 3 unmounted file system raw modifications. More priorities can be set if needed, this is the current setup.
File systems can be added in a similar way but the interface is more complex. Documentation to do so is included in ForGe documentation.
Conclusion
ForGe is a tool to create relatively simple test images rapidly. Creating ten images takes less than a minute. Its limitation currently is its focus on single files. If more complex structures, for example web browsing history, need to be included, ForGe is not able to do that with reasonable amount of work. Even in those cases, ForGe would speed up creation of the base images.
Pros:
- Fast
- Creates NTFS images. Most test images available seem to be FAT
- Graphical user interface
- Pays attention to order of actions when building images, to avoid contamination in scenario or timeline
- Easy to install and configure
Cons:
- Works on single files only – cannot be used to create email archives, web browser histories etc.
- Database management is not perfect – if for example the user wants to delete files in hidden files repository, they must delete both the database entries with the user interface and the physical files with rm.
- NTFS system file attribute times mostly correspond to image creation. Root directory time is set but $Bitmap etc. indicate the time of last action in image creation. Deciding what would be the correct MACE timestamps for each system file according to the scenario with actions is not a trivial task and currently not implemented.
This was an interesting project to do and I am currently working on FAT16/32 extension. I will also add modification of directory index timestamps soon. NTFS is a versatile file system that allows complex timestamp manipulation; ForGe tries to leave timeline as uncontaminated as possible and is able to use some of the more complex NTFS timestamp oddities.
I would be delighted to hear comments and improvement requests.
Hannu Visti






@Hannu (and to anyone interested in this)
Coincidentally this topic has been talked about very recently here:
http://www.forensicfocus.com/Forums/viewtopic/t=11023/
Very good news that something like the hypothetical tool discussed is real.
jaclaz
I’ve heard quite a lot of talk of the need for such a tool in many forums. I think ForGe is a good start, as adding new data hiding methods to it is ridiculously simple. The framework already handles mounting and dismounting of images, deletion of files that need to be deleted, modification of MACE timestamps if needed, and correct order of all actions to avoid contamination.
If someone wanted to add a “hiding method” that for example copies web browser cache to the image, it would be a couple of lines of Python code and a new row in the database. The code would just call mount, copy files, call dismount and return a free form string to be added to the “cheat sheet”. If time modifications would be needed, the return structure would just contain file paths and their required timestamps; the core engine would then do the actual timestamp modification to raw file system data.
I chose intentionally only trivial hiding methods I could easily verify, as verification of the quality of created images was a part of my MSc dissertation but adding more complex functionality would be easy as the framework is there.
Adding a file system is a bit more complex as the class interface requires more methods. I am now in process of adding FAT12/16/32 and hope to complete this in the coming week or two. I’ve written most of it already, timestamp modification is the only missing part. I just have a quick Java project I need to do before returning to this ….
Hannu
Hannu,
This sounds like an impressive and useful piece of work. Well done.
I am hoping it will help with some stuff I am working on – I will be grabbing this from Github very shortly.
Do you intend to maintain and further develop it? (I suspect that on the strength of this you have a successful career in front of you and may not have the time to do so.)
BryanThe Snail
What a Great Idea! I’m sure something like this, once fully fleshed out (with such things as Web History, Temp Internet, Messaging etc.) would be heavily used in the academic world. Congrats..
Rob
Very nice post. I just stumbled upon your blog
and wished to say that I’ve really enjoyed surfing around your blog posts.
After all I’ll be subscreibing to your feed
and I hope you write again very soon!