By Barnaby Skeggs
Preamble
Since the release of Windows 8, and the ‘Metro’ interface, touch screen input has been implemented in a rapidly rising number of Windows devices including Microsoft Surface Pro/Book, 2-in-1s, convertible laptops and tablets. Microsoft has catered for this trend, implementing conversion between touch/pen handwriting to computer text in software such as OneNote. In this paper I will detail my research into the forensic artefact ‘Waitlist.dat’, which I believe to be associated with this functionality.
I identified the ‘WaitList.dat’ artefact while investigating a Windows 8.1 PC for the presence of a known email. I was provided with a copy of this email, and part of the investigation involved identifying whether or not this email ever existed on the custodian’s computer. After processing the .PST and .OST mailbox archives on the PC, I did not identify the existence of the email. I then processed shadow copies, carved and processed for various mailbox stores and email files, and still did not identify the email. As a final attempt, I ran a string search for the email subject line across the whole forensic image. I received 1 hit within ‘WaitList.dat’. Investigation of this 140mb file identified metadata, and full body text of over 36’000 emails and documents, spanning back 3 years.
Acknowledgements
Shaun Bettridge – Peer review, contribution to data structure analysis and being a sounding board for ideas throughout this analysis.
Carl – Peer review.
WaitList.dat
‘WaitList.dat’ (WaitList) is a data file which has been found to contain stripped text from email, contact and document files. The population of data within WaitList is associated with the ‘Microsoft Windows Search Indexer’ process. This process locks the WaitList file on a live system.
WaitList is located in the following directory on Windows 8.1 and 10 systems (may exist on other OS versions, however I do not have systems to test this):
C:\Users\%User%\AppData\Local\Microsoft\InputPersonalization\TextHarvester\WaitList.dat
I have only identified WaitList on PCs which have utilized touch screen handwriting recognition features. My own touch screen laptop did not contain this file, as I had not used the feature. In order to test its creation, I setup and began using the handwriting recognition in OneNote, and WaitList was soon automatically created. The following morning full text extracts of all emails I had received overnight were populated within WaitList.
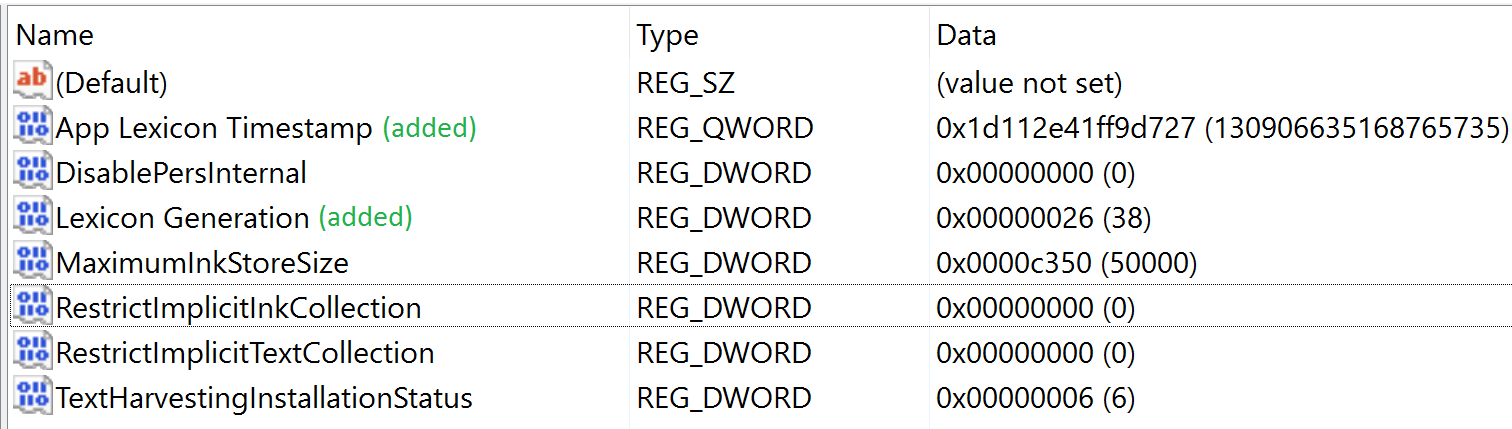
Registry comparison before and after my test showed the following registry key modifications:
Key: HKEY_CURRENT_USER\SOFTWARE\Microsoft\InputPersonalization
Lexicon definition: the vocabulary of a person, language, or branch of knowledge
The “App Lexicon Timestamp” key is a Windows 64 bit FILETIME (Big Endian) timestamp which matches (within ~10 seconds) the installation time of the COM Class Object ‘UserLexiconManager’. This is not the date when this key was created, or the date from when WaitList population commenced. On my PC, this date was prior to my purchase of the laptop, likely associated with the initial Windows 10 installation.
Alternatively, these registry key values can be created by enabling ‘Personalised Handwriting Recognition’ for a supported language in the Control Panel.
Control Panel\Clock, Language and Region\Language\Language options
Theory and Further Research
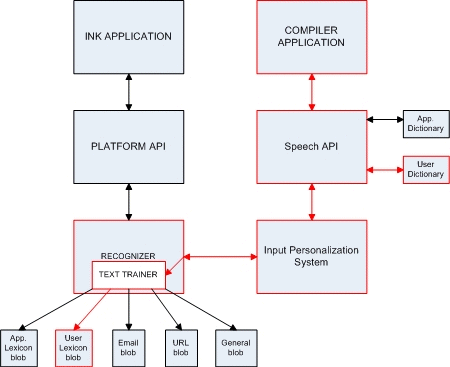
As of Windows Vista, Custom Dictionaries have been used to improve handwriting recognition results. This has worked by the Input Personalisation System (IPS) collecting user data, which a ‘Text Trainer’ ‘tunes’ and stores in ‘lexicon blobs’.
The text trainer stores Application Lexicon Blobs, and User Lexicon blobs. Both blobs can be used by the Handwriting Recogniser, and both blobs are updated when new data is received by the IPS, thereby continually improving handwriting recognition accuracy.
For more information on this process, please read:
https://msdn.microsoft.com/en-us/library/bb265252.aspx
Representation of the relationship between Ink Applications and the IPS
The following files exist within the same directory as WaitList.dat:
%User%\AppData\Local\Microsoft\InputPersonalization\TextHarvester\TextHarvester.dat
%User%\AppData\Local\Microsoft\InputPersonalization\TrainedDataStore\en-AU\*
The ‘DocID’ (Offset 0x1C detailed in Data Structure below) appears to match entries within WaitList to values within TextHarvester.dat. This link will be investigated and detailed in a future blog post.
Whilst further research is definitely required it is possible that the ‘Microsoft Windows Search Indexer’ collects and stores user data in WaitList, following which TextHarvester acts as the ‘Text Trainer’, tuning the user data into TrainedDataStores (User Lexicon Blobs) for use by the ‘Handwriting Recogniser’.
If you know more about these files please contact me at [email protected].
File Contents
The following data has been identified within WaitList.dat records.
Microsoft Outlook Email:
· Date/Time
· Email subject
· Sent flag
· Type (Email/Document/Contact)
· Recipients (Does not distinguish between ‘To’, ‘CC’ and ‘BCC’)
Note: Does not store ‘From’ value, however this can often be identified in email signatures)
· Meeting Location (only when email is a calendar invite)
· Body of file
Contact:
· Address
· City
· State
· Country
· Full Name
· Title
· Contact Details (email/phone/url)
Note: Contacts added from Skype/Lync may be recorded as a ‘sent’ email item, due to the way Outlook imports/stores the contact.
Documents (.pdf, .xlsx, .txt, .doc and .docx files have been tested):
· Date/Time
· DocumentID (use to compare document indexes over time) – format unknown
· Body of file
· Company
It is likely that other values are stored in additional data types, however this is the extent of data I have identified in my testing procedures.
Forensic Application
WaitList provides an additional source of evidence for email and document discovery. In addition to the existence and content of a document, WaitList will store multiple indexes for a single document over time. This provides a forensic examiner the ability to view historical iterations of a file, even when shadow copy is not enabled, or when the file has been deleted/wiped from the hard drive.
The population of data within WaitList.dat is associated with the ‘Microsoft Windows Search Indexer’ process. This process locks the WaitList file on a live system. Existence of an index record within WaitList only indicates the existence of the file on the computer. User interaction with the file can only be inferred when the metadata stored within the record (e.g. ‘Sent flag’, ‘Recipient’) indicates a user action.
An email or document can be recorded in WaitList without being read or opened by the user.
Limitations of the Microsoft Windows Search Indexer apply to all records within WaitList. For example, files within an archive (.zip, .rar etc.) or encrypted documents cannot be indexed with default ‘Microsoft Windows Search Indexer’ settings, and therefore will not be stored within WaitList. Scanned (non-text searchable) PDFs may appear as records, however the body text will be empty.
For more information on the ‘Windows Search Indexer’ visit:
https://msdn.microsoft.com/en-us/library/ee805985(v=vs.85).aspx
‘Microsoft Windows Search Indexer’ will index emails and their attachments at a similar time. As a result, these files will occur within close proximity of each other when they are written to ‘WaitList.dat’. Whilst there does not appear to be a direct parent to child relationship value, the attachment files will contain matching ‘Recipient’ values to their parent email. ‘Date/Time’ and ‘Recipient’ values can be used to associate emails with their likely attachments.
Parsing WaitList.dat
WLrip.py (WLrip) is a python program I have written to parse the contents of WaitList.dat, based on my understanding of the data structure specified below. WLrip will extract the metadata and body text of each record to a new .txt file, and produce a metadata report in .csv format.
Running WLrip with the ‘-x’ option will produce a .xlsx report with hyperlinks to each .txt file created. This is the recommended method to run WLrip, however it requires the Python ‘XLSXWriter’ module (https://github.com/jmcnamara/XlsxWriter).
Recommended execution of WLrip.py is as follows:
Wlrip.py -c -x -f <filename> -o <output directory>
Arguments:

I have done my best to write this program in a way that allows it to capture new values (which I have not yet encountered) in the ‘other’ field. Values captured in the ‘other’ field will be appended with a [type], to indicate the field value stored in the data structure. Please send unknown values to me and I can implement them in future releases.
https://github.com/B2dfir/wlrip
I have also compiled WLrip into a portable Windows executable using pyinstaller.
https://github.com/B2dfir/wlripEXE
Data Structure Analysis
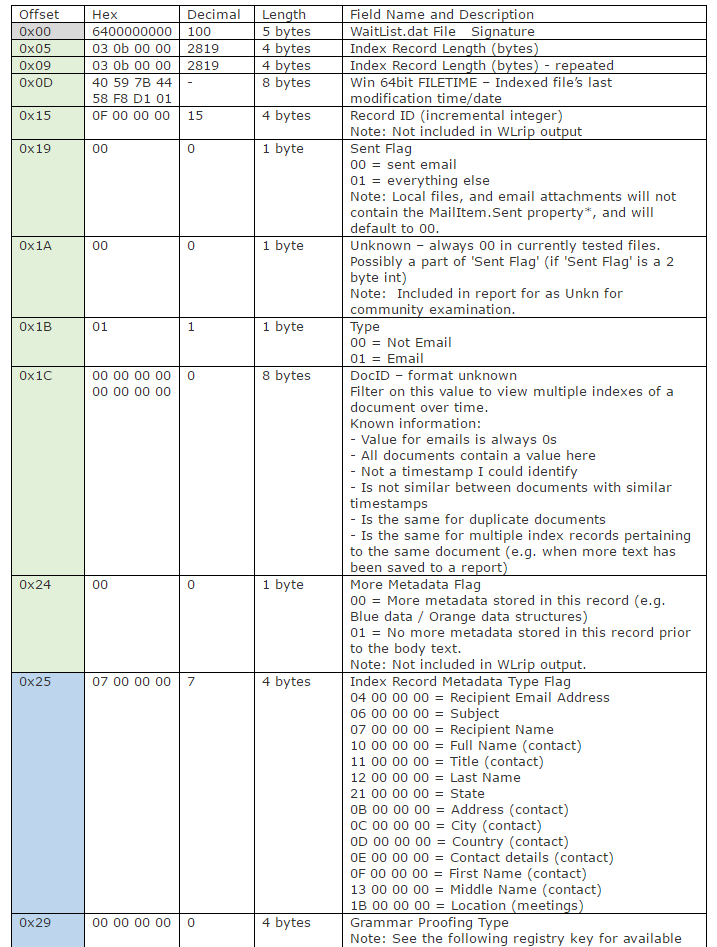
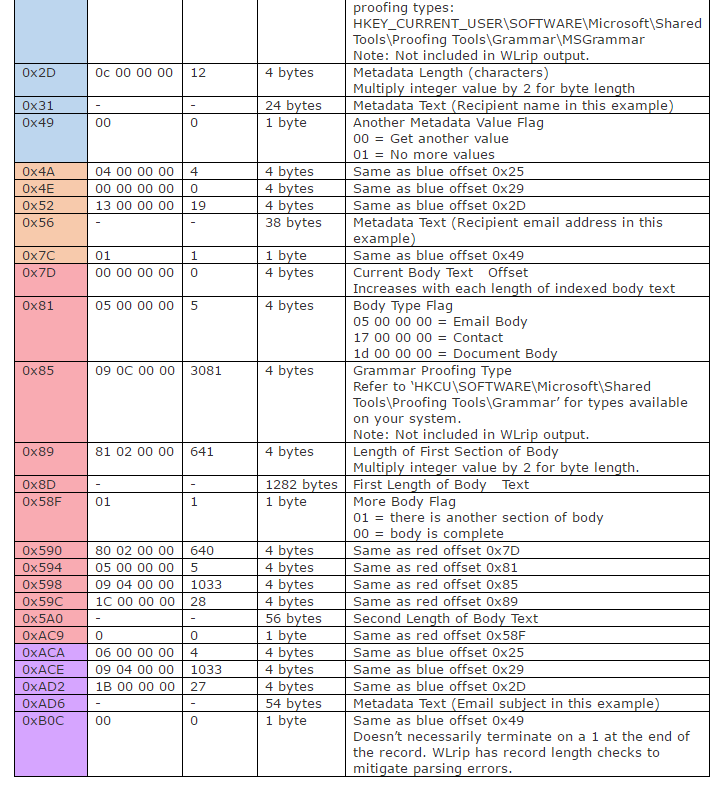
I have performed analysis on the data structure of WaitList in order to understand how text and metadata are stored within each record. All values are in little endian.
Data Structure (Hex)

Data Structure (Detail)
* For more information on MailItem objects, see:
https://msdn.microsoft.com/en-us/library/office/ff861332.aspx
Conclusion
WaitList is an additional source of email, contact and document evidence to add to our arsenal of forensic examination and e-discovery tools. Should you have any questions, recommendations or corrections for any of the detail in this blog, please post in the comments section below.
———————————————————————————————————————
Author’s disclaimer: The information detailed within this report is based on my limited testing and analysis of the ‘WaitList.dat’ file. I do not currently claim to have a complete understanding of the structure or function of this file. Confirmation and testing of my findings by the broader forensic community is required before this information should be relied upon.
About the author
Barnaby Skeggs is a digital forensic analyst and incident responder based in Perth, Western Australia. This project has piqued his interest in research, and sharing knowledge within the forensic community. Barnaby currently works at KPMG Forensic, assisting clients with forensic investigation and incident response services. To follow his future research and forensic insights, subscribe to his blog at: https://b2dfir.blogspot.com.au/





