
Hello, everybody. Greetings from the Netherlands and welcome to this presentation called “A Contemporary Investigation on NTFS File Fragmentation”. In the next 20 minutes, I will tell you all about the research and our paper, which has the same title as this presentation. So, let’s get started.
Before we go into all the details, let me give you a brief overview on what this presentation is about. For this research, we have created a data set by collecting NTFS metadata on 220 different laptops. With all this metadata combined, we were able to get a good picture of the file fragmentation state of real world computers. And with all this data available, we were able to make some implications about what this means for file carving.
The authors of this paper are Hugo Jonker from the Open University of the Netherlands, Joeren van den Boss from the Netherlands Forensic Institute and myself, Vincent van der Meer from the Zuyd University of Applied Sciences. I work there as a teacher and I’m currently a PhD candidate. And in that role, I was awarded the doctoral grant for teachers by the Netherlands Organization for Scientific Research.
Let’s start with some background and explain what file carving is. File carving is about the recovery of deleted computer files. A good analogy to explain the difficulties of file carving is by looking at this man who is carefully excavating a dinosaur skeleton. The work he is doing is time-consuming, there were probably no real pointers about where to start digging in the ground, and although it looks like most bones seem in the correct order, that’s not a certainty. It’s not even sure at this point, all the bones belong to the same animal.

These characteristics are also true for the recovery of deleted computer files. When a file’s deleted its records in the master file table will be removed. So there are no real pointers, or no pointers at all, as to where on the disc the content of the file remain. Information on where the file was allocated is now gone. And in the absence of this metadata, you have to search the entire disc to look for the contents of file fragments. This is computationally a difficult problem, especially if the fragments are not consecutive and in the correct order, which brings us to the relevance of file fragmentation.
So let’s talk about file fragmentation. What is file fragmentation? We consider a file not fragmented when its fragments are contiguous and in order. So when fragment A and B are in the right order, and well, there’s no space between them. If that’s not the case, we consider the file fragmented. So when there’s space between fragments A and B, be it unallocated space or data from another file, the file’s fragmented.
An important addition to this is the concept of out-of-order fragmentation, which basically means that the fragments are not in the correct order. This is not often mentioned in other studies and out-of-order fragmentation can occur in two ways, either contiguous out-of-order or non-contiguous out-of-order.
We can consider contiguous out-of-order files a very special case because in the 84 million files in our dataset, only eight were contiguous out of order, not eight million, only eight. So those are a real rarity. Now what causes file fragmentation? It basically starts with the fragmentation of free space. So when files grow, shrink, become deleted, the free space on the volume becomes fragmented. And eventually when a new file is written or is gross or is extended, the file system may be in situation where it cannot write the file consecutively on disc, which basically forces the file system to make the file a fragmented file, to allocate another part of the file on another section of the disc.
When we talk about fragmentation percentage, we usually mean how many files on a volume are fragmented versus how many are not fragmented. For this research we created two additional metrics to say something about the way an individual file is fragmented. The first is called the percentage of internal fragmentation, and it tries to express, given that a file is fragmented, how bad is it fragmented? And it’s defined as the number of fragmentation points a file has divided by the potential fragmentation points a file could have.
The second metric is called the out-of-orderness. In which we try to express, given that the file is fragmented, how bad is it out of order? How many files, how many parts of a file are out of order? And it’s defined as the number of backwards fragmentation points a file has divided by the fragmentation points it has.
So, let me illustrate that with a short example. Here you can see a file that consists of seven segments. You can see three arrows and each arrow indicates a fragmentation point. So the internal fragmentation of this file is three fragmentation points divided by six, because six is the potential number of fragmentation points, is 50%. The out-of-orderness of this file is (there’s actually one segment out of order) divided by the three fragmentation points this file has, is one third or 33% out of out-of-orderness.
So let’s talk about the collected data set. The data we collected was NTFS metadata from the master file table. It was collected between October 2018 and January 2019. And in total, we collected metadata from 220 different laptops. I should note that Linux only laptops or Apple laptops are excluded from this research, because we were interested in NTFS file system.
From all the encountered Windows configurations, almost all laptops ran Windows 10, only three Windows 7. Storage configurations: the dominant storage configuration was a single SSD and a single HDV. Also popular were laptops with a single SSD (70 times) and 36 times we saw a laptop with a single HDD, three times dual SSD. In total, we encountered two 729 NTFS volumes and almost all volumes (707) had a block size of 4K, which is thus the dominant block size.
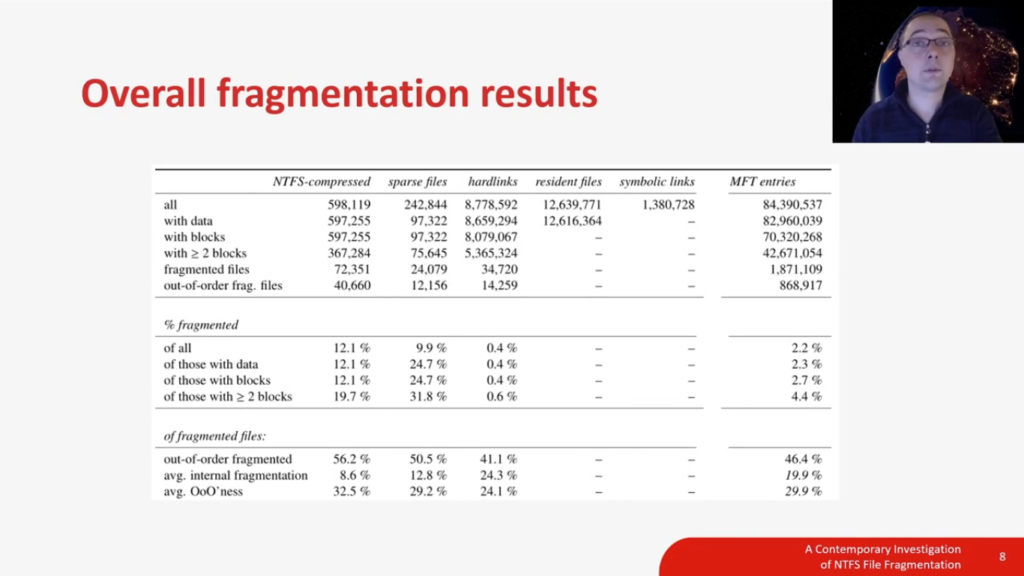
So now it’s time for the overall fragmentation results. In this table, you can see our dataset split out to NTFS file types. And in the last column, you can see the totals for all MFT entries. So let’s start by focusing on the last column, the total MFT entries. There you can see that the data set consists of 84 million MFT entries, but depending on the definition you use for a file, the totals are different. So if you are only interested in files with blocks that have actually blocks allocated on disc to them, there are 70 million files. And if you’re only interested in files that can actually fragment, so files that have two blocks or more, then we’re talking about 42 million files.
So the count of the total files influences the fragmentation percentage. So that’s why we have reported on four different metrics for the type of fragmentation, and the results vary between 2.2% fragmented to 4.4% fragmented. And in the bottom of this column, you can see that 46%, almost half of all fragmented files, are fragmented, out-of-order.
Let’s continue with this table of overall results, but now I would like to focus on two specific file types for this NTFS file system. And they’re called NTFS-compressed files and sparse files. So NTFS-compressed files is file compression done by the file system itself. So this type of compression is transparent to the user or the application, they don’t need to be aware of it. And of course it’s a lossless type of compression. Sparse files are files that only allocate non-zero data to disc. And this specific behavior makes sparse files suitable, for example, virtual machines or virtual disc images.
When we look at the fragmentation percentages for these kinds of file types, we see that NTFS-compressed is 12.1% to 19.7% fragmented, which is way, way higher than the average file is fragmented. And the same is true for sparse files, which are even more compressed more often (not compressed) fragmented than the average file is fragmented. When we look at the specifics of what type of fragmentation occurs, we can see that there are more or less even out of order fragmented, both NTFS and sparse files.
But something happens with the NTFS-compressed files. When we look at the internal fragmentation, which is only almost 9%, but compared to the average internal fragmentation which is 20%, it’s way less fragmented, which means that NTFS-compressed files are on average more often fragmented than other files. But when they are fragmented, the internal fragmentation rate is much lower than an average fragmented file. And to a lesser extent, the same is true for sparse files. Their internal fragmentation rate is 12.8%, which is also significantly lower than the average internal fragmentation rate, which is almost 20%.
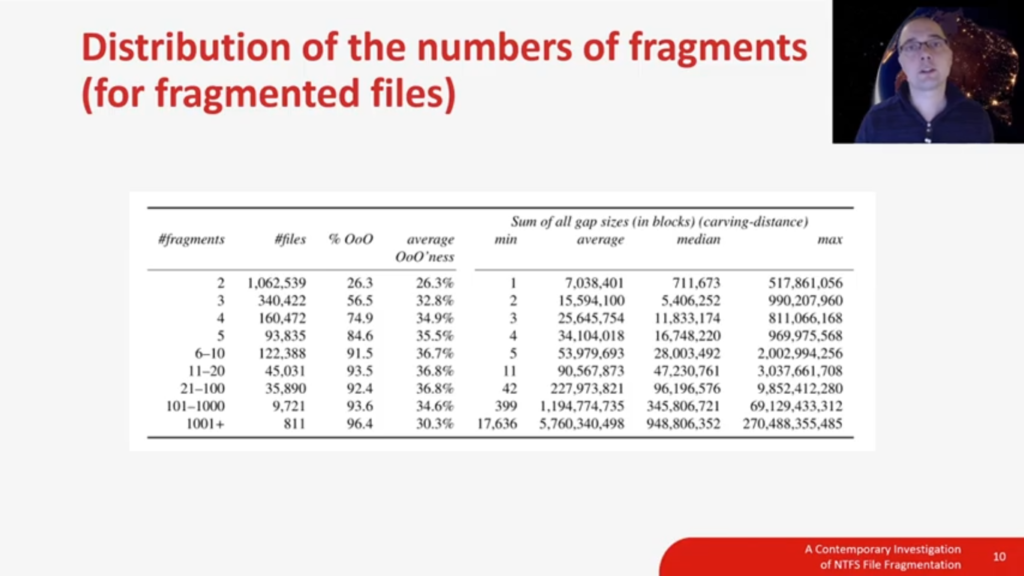
So let’s now zoom in on the fragmented files. This table shows you information about in how many parts files were fragmented in our dataset. So let’s focus on the first two columns. It shows you that over 1 million files were fragmented into two parts. The main takeaway of this table is these two, or bi-fragmented, files make up for over 55% of all fragmented files in this dataset. On the opposite side of the spectrum of fragmented files, there are the extremely high fragmented files. We encountered files up to 20,000 parts, but in this category of extremely fragmented files, we only did find system-related file extensions.
So with bi-fragmented files making up over 55% of all fragmented files, let’s zoom in on this specific category. We will discuss it using gap size and with gap size we mean the start of the fragmentation point to the start of the second fragment, the distance between those points measured in blocks is the gap size. The distance in blocks; blocks are usually 4K in our dataset, but they can be different depending on how the volume is formatted.
For in-order bi-fragmented files, we can see that most bi-fragmented files have a very short gap. So from the fragmentation point, there is a very short gap to the start of the next fragment. And when the gap grows larger, the amount of start of second fragments become less frequent. The same pattern holds true for the out-of-order bi-fragmented files, but note that the vertical axis on this image has a different scale, and that of course, in bi-, or, out-of-order fragmentation, the start of the second fragment is before the end of the current fragment.
There’s another detail I would like to point out, more or less a funny observation. You can see the spikes here in the data for in-order bi-fragmented files. And these spikes correspond with gap distances of powers of two: so 2, 4, 8, 16, 32, 64, 128, etc. This pattern holds true for a longer scale than on this image, there are always local maxima in the data.
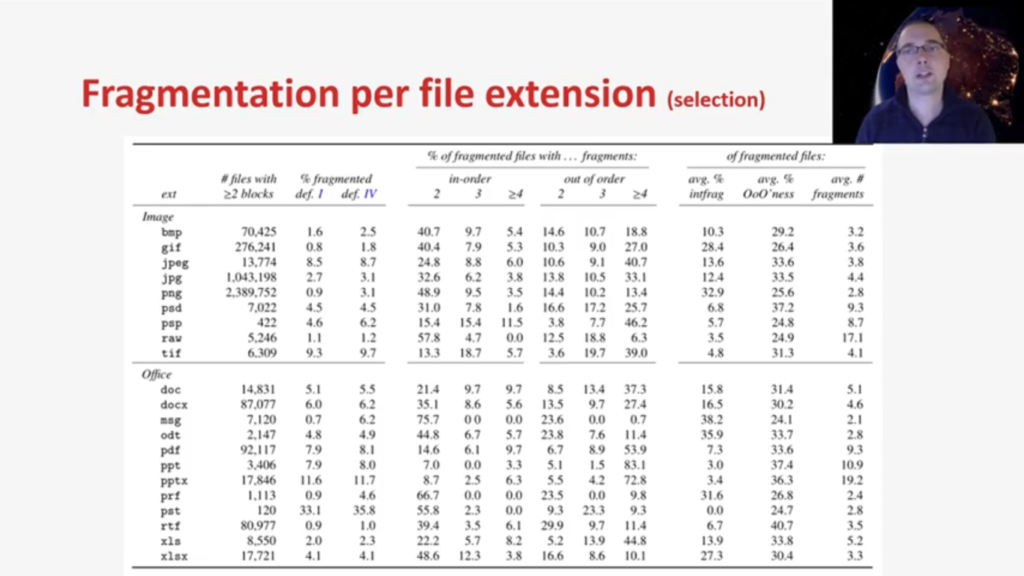
Next are the fragmentation results per file extension. To keep things readable, this table is a selection of a few popular file extensions. For the image related file extensions, let’s bring our focus to PNG and JPEG, which are image formats that are often of interest in forensic research. We can see the JPEG and PNG are by far the most used image formats, or the far most encountered image formats in this dataset. When we look at the fragmentation rates, we can see that both PNG and JPEG have a 3.1% of fragmentation, which is lower than the average fragmentation rate in this data set. Looking at the type of fragmentation for JPEG, we see that almost 60% of all JPEGs are fragmented out-of-order, which is noteworthy higher than the average of this dataset.
Now let’s bring our attention to a specific office document. And I would like to talk about a .pst file. A PST file is a data storage file that contains personal information used by Microsoft Outlook. It contains, or it can contain, email contacts, addresses and other data. So we can imagine why this file type would be of forensic interest. Looking at the fragmentation rate, we see that one in three PST files is actually fragmented, which is extremely high compared to other file extensions. When we look at the average internal fragmentation rate, however, for the PST file, we see that is 0.0, which is rounded of course, but that means that PST files are very often fragmented, however when they are fragmented, their internal fragmentation is very low.
The time for this presentation is of course limited. So I have to make choices about what to include and exclude. With this slide I will give you a brief glimpse of other results that are in the paper. So if you’re interested, there’s more.
What do these recommendation results mean for file carving? The overall fragmentation rates have implications for file carvers. First, an upside for recovery tooling: most files are not fragmented. Compared to previous older studies, our reported fragmentation rates are lower, which is good news because it takes a considerable amount of time to carve large disks and other media, even in the simplest scenarios. The low fragmentation rate is particularly good news for tools that assumes that files are never fragmented. The downside is that if a tool aims to recover fragmented files, it must account for out-of-order fragmentation. This impacts studies or carvers that only account for in-order fragmentation, and accounting for out-of-order fragmentation will have a negative impact on the runtime.
With regards to NTFS-compressed files: most carvers are unable to recover these types of files. This study shows that if such a carver aims to be really successful, it must account for the high percentage of fragmentation in this types of file. With regards to sparse files, we only find three extensions have a significant portion of them as sparse: .pst, .sqlite, and .db. All of these are significantly more fragmented than average. Again, if a file carver wants to recover these types of files, it must take these aspects into account. This study also reported on gap sizes. The reporting on encountered actual gap sizes allow for practical estimations of the performance impact on file carvers that take out-of-order fragmentation into account, and this can be input for new file carving strategies.
With this fragmentation study behind us, we are currently working on three projects. We are implementing a file carver that accounts for our out-of-order fragmentation and will allow us to implement and benchmark different search strategies. Secondly, we are working on a PST file format validator. And although the file format is documented pretty good, we now know these files can be NTFS-compressed, sparse and fragmented. Lastly, we are working on a study on file deletion on solid state disc drives.
And that brings us to the end of this presentation. I thank you for your attention, and I hope you enjoyed it. My contact information is on this slide, so please don’t hesitate if you want to send me an email. This recording will end soon, but I will be online to answer any questions and I’ll be more than happy to do so. So thanks again for your attention and bye-bye.





