Phil: Hello, everyone. Welcome to another webinar in the Nuix webinar series. Today we are going to be talking about enriching Nuix processing and Nuix Investigate for information governance. So just for introductions, my name is Phil Glod. I’m a senior solutions consultant for Nuix. I’ve been with Nuix for six years. I kind of work with pre and post sales, so doing everything from POCs to implementations. And then kind of my SME at Nuix is, I handle some of the largest cases that have gone through gone through Nuix. So that can be for information governance purposes, or litigation readiness purposes, I’ve dealt with navigating these really big cases, and about 12 years’ experience in the field. And I’m joined by Arron Hepfer. If you want to give your introduction, buddy.
Arron: Hi everyone. My name is Arron Hepfer, I’ve been working with Phil since he’s been at Nuix, and I’ve been here around the same amount of time, a little bit longer, very similar role to Phil. I work with customers technically, to help them solve problems with Nuix. Those problems that they have may be investigations, kind of classic e-discovery, or the types of things that we’ll focus on today, on data sorts of problems to solve. And today I’ll be primarily helping Phil out, looking at questions that come in. So I’ll be monitoring the questions window, and we’ll have a couple of breaks that we can address questions as they come up. So as we go through it, feel free to bring the questions in. Go ahead.
Phil: Thanks, Aaron. So before I go into the, kind of the exercise of everything, I want to kind of explain the information governance use case Nuix, right? So information governance, the definition of that, you know, varies very widely, right? So, because that can mean, you know, basically how you’re controlling your data. You know, that can mean compliance. So things like GDPR and CCPA and doing, like, HIPAA compliance and PCI, you know, I can go off a whole keyword cheat, right? But it’s all about, you know, how you’re controlling your data as well as doing exercises, you know, with data disposition and remediation and all sorts of things.
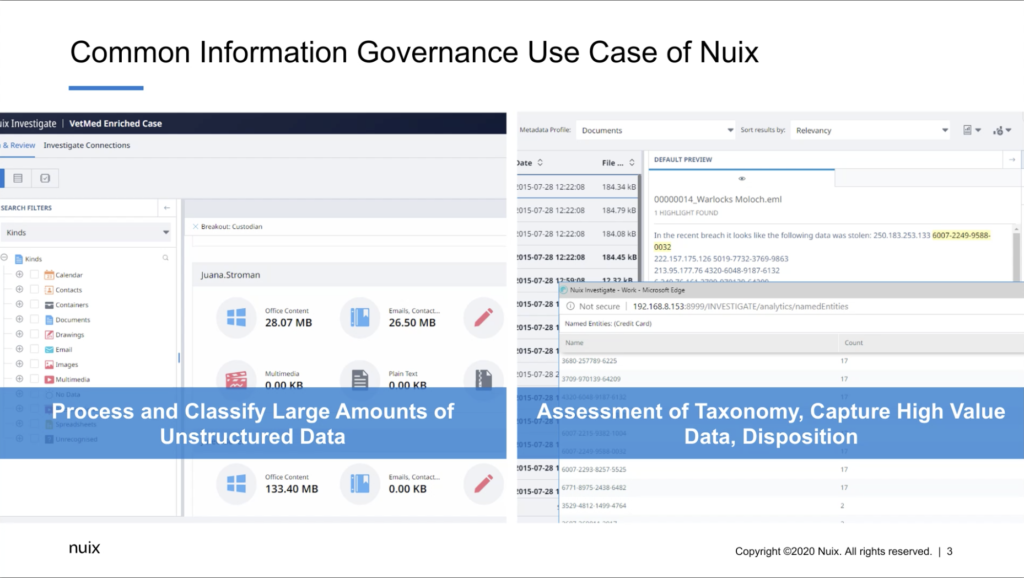
So the way that Nuix is usually used for it is that it’s, you’re processing this large amount of unstructured data. So this can be file shares. This can be collections from workstations and laptops and such. You know, this can be information from the cloud like Microsoft’s 365 and things like that, but we can handle very large amounts of unstructured data, tons of different file types. And the goal is that you’re creating an index of metadata and text of all that information. And you’re going to classify it with Nuix. So you’re going to do what is basically — it sounds intimidating — is a data science exercise. So you’re putting that data into different buckets. You’re kind of figuring out what is high value and what needs to be thrown away and litigation readiness and all that.
So that process is this assessment of the taxonomy, you’re capturing that high value data and then doing things like remediation, like disposition. You know, the main thing is that with this use case, is that there’s a Nuix practitioner that’s doing this exercise of working with their application and then there’s different stakeholders, of course, involved. There’s your CISO, compliance managers, general counsel, IT leaders, that kind of thing.
So the definition of these projects, I mean, they really range very widely, but they have some trends that I’ve worked with. So those trends again, using Nuix, is there’s a dependence on tagging the classified data. When, I mean, tagging, that’s essentially like selecting a document, either automated or manually, and putting in a simple annotation: relevant, classified, that kind of thing. You’re putting in the different simple annotations. We call them tags in Nuix. And really how you’re putting the data into buckets, that’s essentially doing that exercise of annotating the data sometimes manually. And so there’s a big dependence on that. Nothing wrong with that, but that’s just how they’re usually are organized.
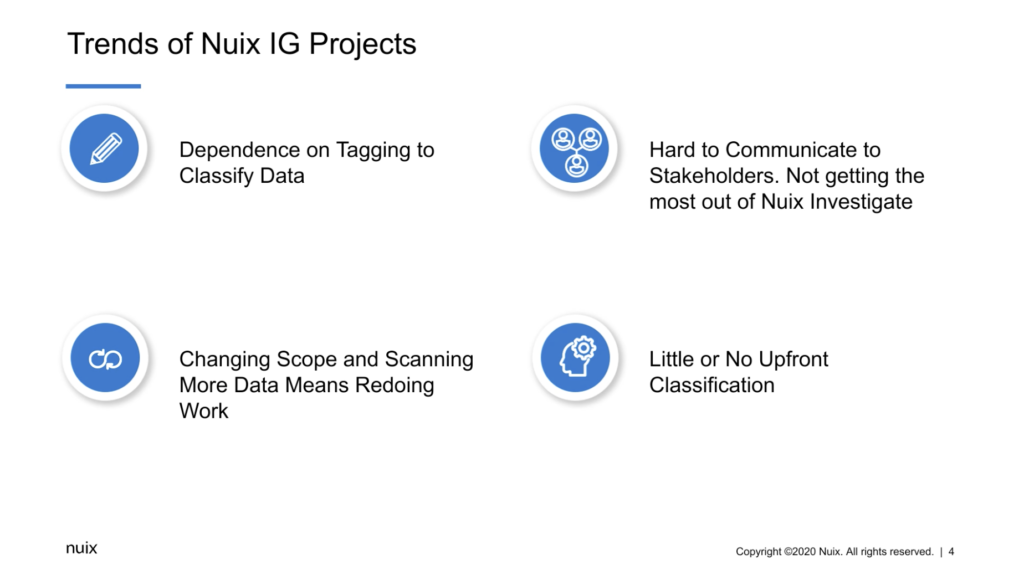
I mentioned that there’s a whole bunch of other stakeholders involved in information governance. So those different leaders of different organizations, they’re not the ones actually going inside the Nuix application. They have to be communicated by the practitioner. And sometimes it’s hard to communicate how that project’s going on to there. And without that hard communication, they can lose momentum in the whole project. So it’s really important. So really they’re not getting the most out of Nuix Investigate, which can be used to help with that communication to stakeholders.
You know, this happens with any project using Nuix where there’s changing scope. So that means that it changes the way that you’re classifying the data. More data comes in, always comes in scope changes, and you’re having to redo a lot of the work since tagging, essentially done manually, that dependence you’re going to have to retag that data, new data gets processed. You have to wait for that stuff to be classified.
And that leads into the other one, which is that there’s little or no upfront classification. So that means that there’s no sampling of the data determining what is privileged and relevant and sensitive and that kind of thing. There’s no kind of upfront classification.
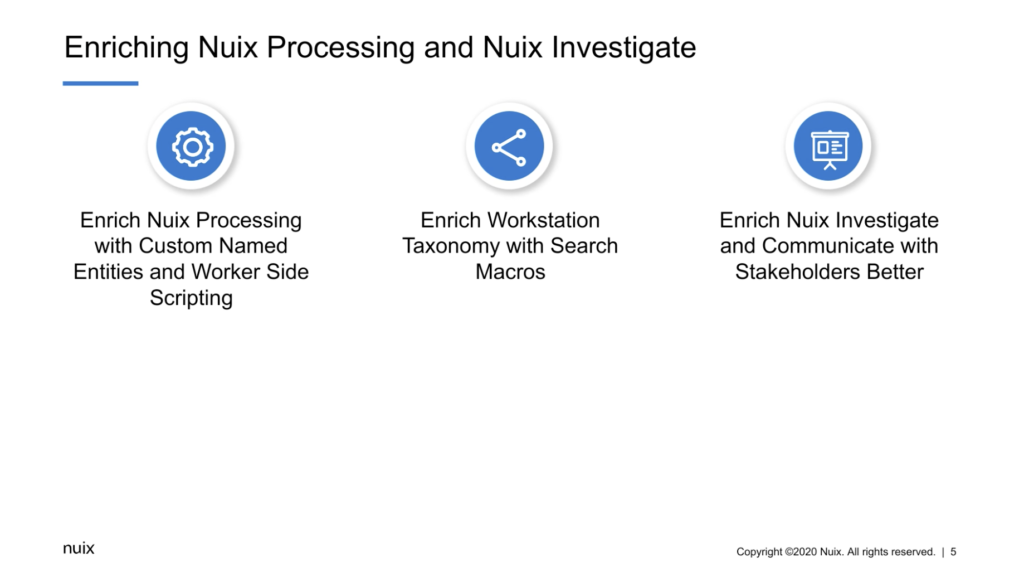
So what this exercise is is today is that I’m going to enrich Nuix processing and Nuix Investigate, you know, by enriching Nuix processing, like custom name identities and worker side scripting, and do like upfront classification, I’m enriching Workstation itself, just how you’re navigating that taxonomy with search macros. And I’m also enriching Nuix Investigate and our custom analytics. So you’re communicating better with stakeholders. So before I head into this demonstration, Arron, was there any questions? There’s going to be different points for questions here.
Arron: This is the first point, and I’m just checking, there is a question. First question is: which products are you talking about? And sounds like, okay. So what Phil is going to show you, he’s going to solve this data problem. And he’s going to use two very common Nuix products. First of all, would be Nuix Workstation, which most everyone who is ever used Nuix is really familiar with, because that’s what the practitioner uses. And then also Nuix Investigate, which will show you that visually.
And just to go a little bit farther into it, because I think this will come up later, as far as the specific functionality and licensing everything that Phil’s going to show you today, all the functionality and all the capability is included in Nuix ediscovery workstation and also the investigation and response licenses for Nuix Workstation. And then as far as Nuix is concerned, the regular user license will encapsulate all the functionality. So most everyone that has Nuix already has this capability. It’s simply using Nuix a little bit differently than typically. Looks like you’re done transitioning. I’ll hand it back to you, Phil.

Phil: No, thanks. Thanks. That’s perfect. So as you know, Arron mentioned that the two products, so Workstation and Investigate. I’m going to start into Workstation and then move into Investigate. There’s going to be some time for questions after I get through Workstation. Before I start all that though, I’m kind of giving an outline of the data that I’m working with, right? So this is pre-stage. I mean, there’s no other way around it. What this is supposed to represent — it’s a smaller amount of data — but it’s meant to represent, like, an organized file share of like home shares and email and things like that. So it’s got your normal what we considered unstructured data, so that can include, you know, Word documents and PDFs and all sorts of different unstructured data email and such.
You know, in reality, I’ve dealt with these projects. They’re usually not this clean, they vary in types. So one file share may be organized differently than the other collections are different, and such. So you know, this is just how this is organized and I’m talking like not gigabytes of data or even single digit terabytes of data. These projects are usually tens or hundreds of terabytes of data in reality. I mean, data volumes are getting much, much larger.
So that out of the way, the way that I’m starting Workstation is with how traditionally people are using Workstation, right? So going into here: what this is, if you haven’t seen Workstation before, it’s probably good for me to explain, because it can be a lot, if you’re seeing Workstation for the first time, it can be a bit overwhelming. But I’m trying to simplify this the most.
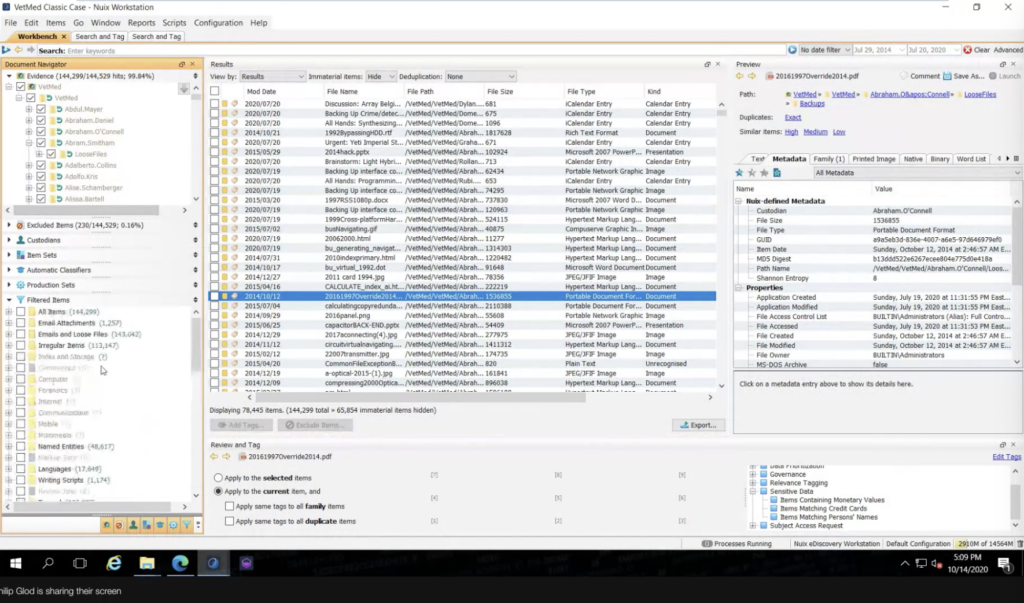
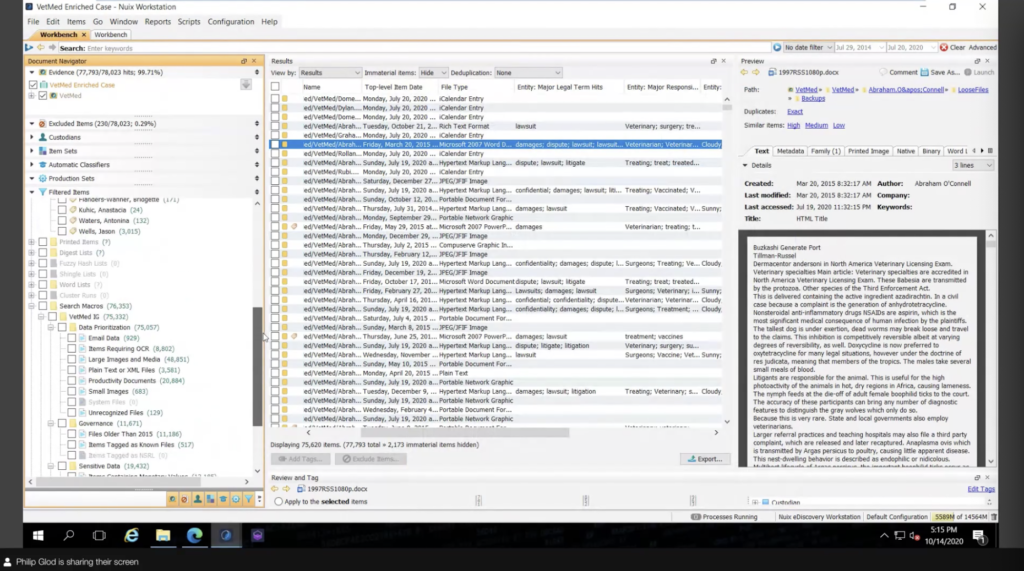
On the left, is this like document navigator and this essentially whatever you do here whether it’s searching by the file path or you’re searching by you know, the file type or anything like that, that’s going to determine what’s in this results pane here. And the results pane is essentially like your grid view. You know, these are your listing of documents that you have, you have this metadata profile that basically determines, you know, what these fields are at the top. I just made this, so it has like a sortable date and a file name and file path and all that. And that just determines what you have here.
And I can select documents. I can annotate them, I could export out this, and that kind of thing. And as I click on this, you’ll notice on the right, I can preview the document. So that’s the metadata. That’s kind of the text. I can kind of view a, you know, a native view of the document as well. So like a printout of the document. I can do that. So it has that.
I mentioned that, you know, tagging is a big portion of data classification in Nuix and what I mean by that is these are all simply annotations that were created. You know, this is just a sample, it’s not what all projects look like. Sometimes they’re messy, or sometimes they’re organized like this, but really it’s about putting that stuff in the buckets, right? So I have like my custodians tag, consider this like our subject access requests. These are those custodians that I’m targeting data prioritization. So that can include like what files am I focused on first? I’m going to focus on the email data, you know, the productivity documents, and move down, you know, plain text files are a lot less important in this case, but, you know, they’re not completely not important, but that kind of thing, and then like your governance. So what files are older than a certain date? Like, are they, we going to dispose of those or sorts of things? This is just the sample, like I’ve mentioned, use cases vary tremendously. But you’ll see that I have this.
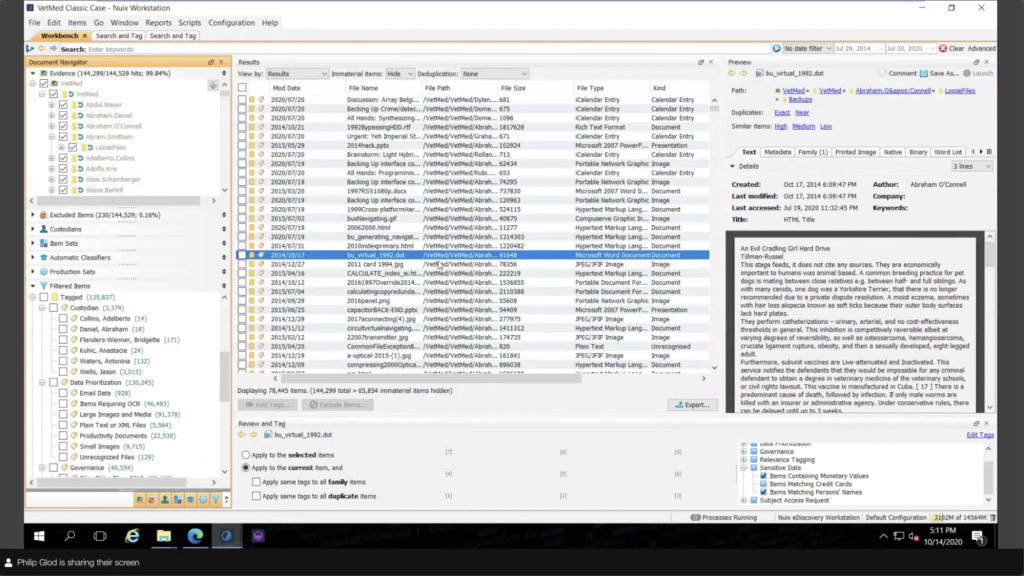
And it looks, it looks really simple, right? It’s deceptively simple, but it’s very powerful to organize these into buckets. Cause otherwise you just have a listing of data, you have a search bar at the top, and you kind of don’t know where you’re going from there. So how they get to this point with tags is essentially our search and tag. And this could look a little bit intimidating, but this is essentially using our powerful Nuix query language, and using it to search metadata and text.
So, you know, for example, that custodian tagging, these — again, very simplified — but let’s say, you know, five emails are associated with a certain subject. Maybe there’s an idea associated with a subject, you know, some sort of sensitive information, or the name, I can basically tag that base, cause I’m not what considers a subject is not considered just where the data comes from. It’s where they’re mentioned in the data and that kind of thing.
Then I have some terms. So these are kind of terms that are associated with the case. You know, they may be what’s relevant legally, you know, what’s relevant to the organization. You know, these could be high value documents, not just based on sensitive information, but what they’re actually containing. And then documents that, you know, generally these terms mean that document is automatically not relevant.
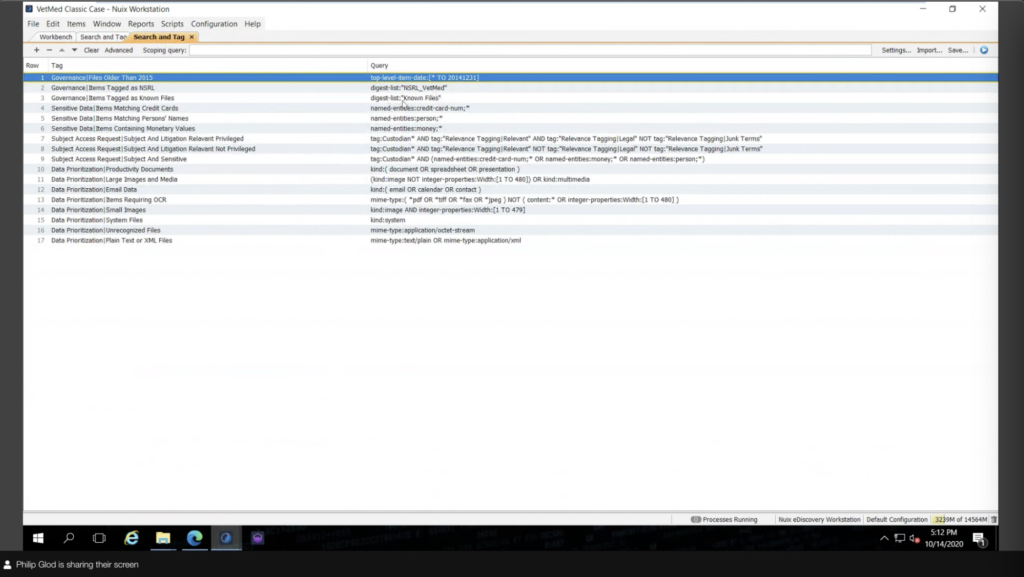
And after this exercise has been done, there’s kind of that buckets that I mentioned. So that’s basically running queries about all those responsiveness, like, okay, these are the documents that are privileged and not privileged. These are the documents that contain sensitive information and different governance and known files and all sorts of things like that. So you know, there’s no way around, it is kind of a data science exercise. You’re building out these classifications, but once you have that now essentially you have… you’re basically figuring out what your control of your data is, and you’re capturing high value information.
But you know, this is a very technical application. This is a Nuix practitioner that does this. So the next steps that’s happened in this project is, there is some light reporting in here that generally help the practitioner itself, but not the stakeholders. So a lot of the times, just the reality of it is that information is exported out of Nuix, and reporting is done in a different tool. Analytics are done in a different tool. And there’s this kind of varying communication with stakeholders and it’s really kind of important to keep momentum with it. So there has to be good communication with these stakeholders and kind of a good understanding of what the standard operating procedure is and such. And that’s why I’m going to show Investigate later.
But before that communication happens, all this stuff has to be classified. So as I ingest the data, it’s not ready to go. I have to do all this tagging and things like that. So what I’m going to first talk about is enriching the Nuix case, essentially, during processing to help with that. So reduce that dependence on tagging.
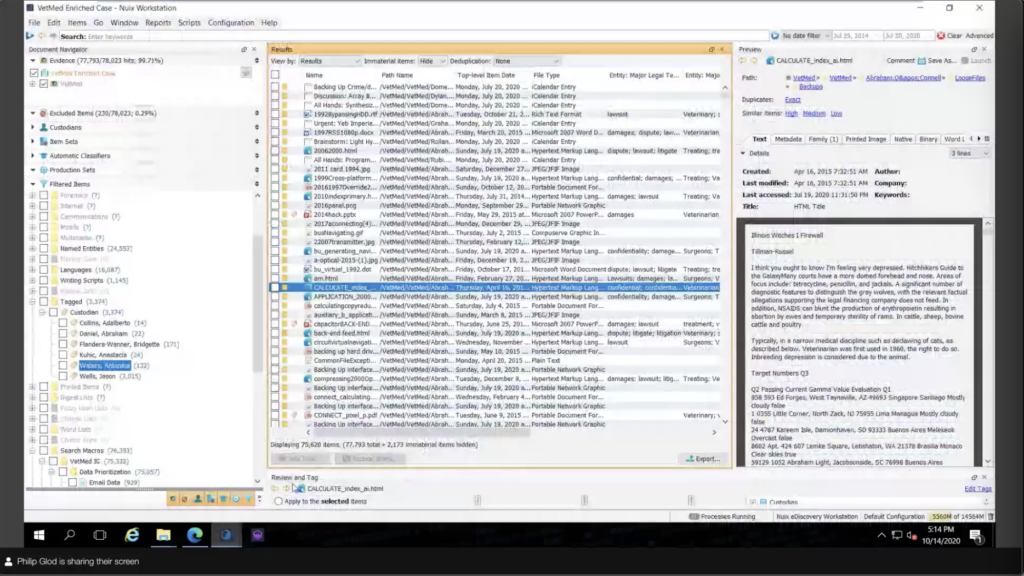
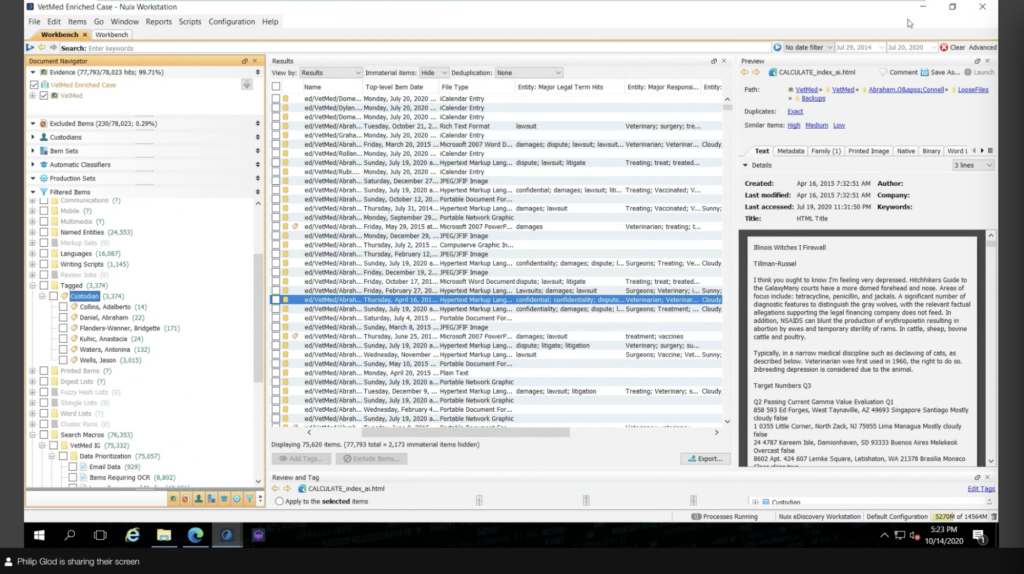
So I have another case here that I’m calling the enriched case. And right away, this should be noted that this case has never been touched after ingestion. This basically is what the case looks like after ingestion. And I have some special metadata here to kind of show that this case is a little bit different than others.
I still have my tagging by custodian, but I did that actually during ingestion. I have… my search terms are actually set up as named entities. So they’re set up ahead of time and actually embedded in the documents. So this means that I can run analysis on these. It’s not just based off of tag. You know, I can actually go into our named entities, which pulls out things like credit card numbers and persons and all that, but I’m using it. I can actually see, all right, well, these are all the stuff that’s privileged. You know, I have things that say confidential. You know, or lawsuits, I can click on that and go through the documents. And none of this had to be done after ingestion, this was done during ingestion.
And then I also have those buckets. Instead of tagging those; as scope varies, these definitions of these actually change. So I’m using what’s called search macros, and essentially they’re just saved searches and they’re nice and organized. And you know, they look kind of intimidating, but really what it is is is that you create a folder and you create a file called macro, and this is the title. And then inside the file is essentially that Nuix query language. So if you are a Nuix practitioner and you were doing these classifications in a search and tag before, you could easily move this over to a search macro and create these files. And I kind of consider what’s in you know, what’s in here, the stuff that’s very fluid, the stuff that’s not persistent. That’s really what I would use search macros for.
If it was something that needed to be like semi persistent, like custodian name here, you could tag them because you can actually remove tags. So they are kind of annotations that’s there until you remove them. And then things like the entities there, these are things that you want to be persistent. So you’re not going to actually remove these named entities here.
So I showed how the search macros are done. This is probably the most dense part of the… maybe probably the most intimidating part of this of this exercise. And that is how we set this up during processing. It starts with named entities. And what named entities are — and you can create custom ones as I have a whole bunch here — is that named entities you know, click on one of these Finland national ID or something like that. What these are, is pull up patterns.
So patterns, you know, being regular expressions, maybe you have an identification number, something that determines subject, a health record, things like that, that should be done upfront. And so once you do that, you can run analysis on all of those entities. So how many items contain this sensitive information, you can find that quicker. Because if you ingest the data, you don’t have that ability to search patterns. You have to search essentially what is near that pattern. So like, different punctuations removed and all of that stuff. So it’s good to actually get this out of the way. And this is a really powerful usage of named entities. I really recommend sitting down with stakeholders, kind of doing a questionnaire and figuring out what is determined sensitive — not just credit card numbers and that kind of thing — PHI, like what determines a patient, what determines an account, things like that.
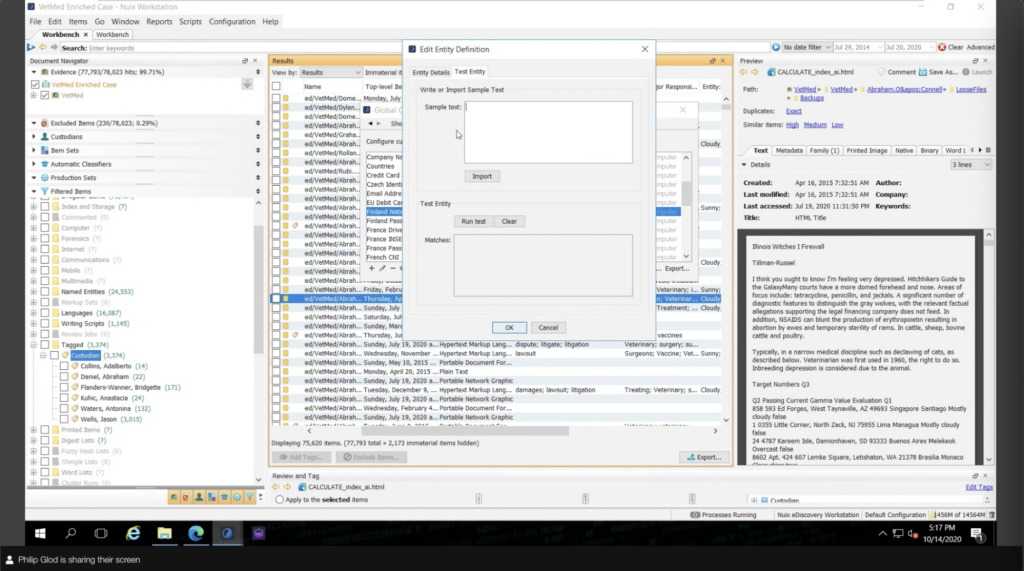
This is really, really powerful stuff. And you can test them here. It makes it a bit easy. You don’t have to worry about running in and then running your data. You can actually test these. What I use named entities for, because it’s really hard to demo all this stuff. This is synthetic data, obviously, if your eyes are going over here… what I do is, I use it kind of as a fancy word list, really, this is a little bit off script on what Nuix these named entities for. But essentially what I’m doing is, I’m setting these persistent terms and they’re just words here, but you can do wild cards and things like that. I’m just simplifying it. And essentially I’m just pulling out this information, these search terms. And so they become persistent in the case. And I can run analysis on these terms, like what’s been mentioned and stuff.
We do have what’s called word list, but word lists are mostly just running searches. You know, during then, and it’s actually a bit slower to do. And this has a little bit more control. This is persistent. So wherever the case goes and wherever it does, these items are there. So basically I have all my responsive term, or relevant terms and legal terms. And also those junk terms, they’re all set up here. So when I process the data, it’s going to pull those out.
You can actually set up named entities after the fact, but you do have to reprocess the text specifically and then it will pull those pull those named entities out. So it is a longer exercise. It’s good to get that done upfront.
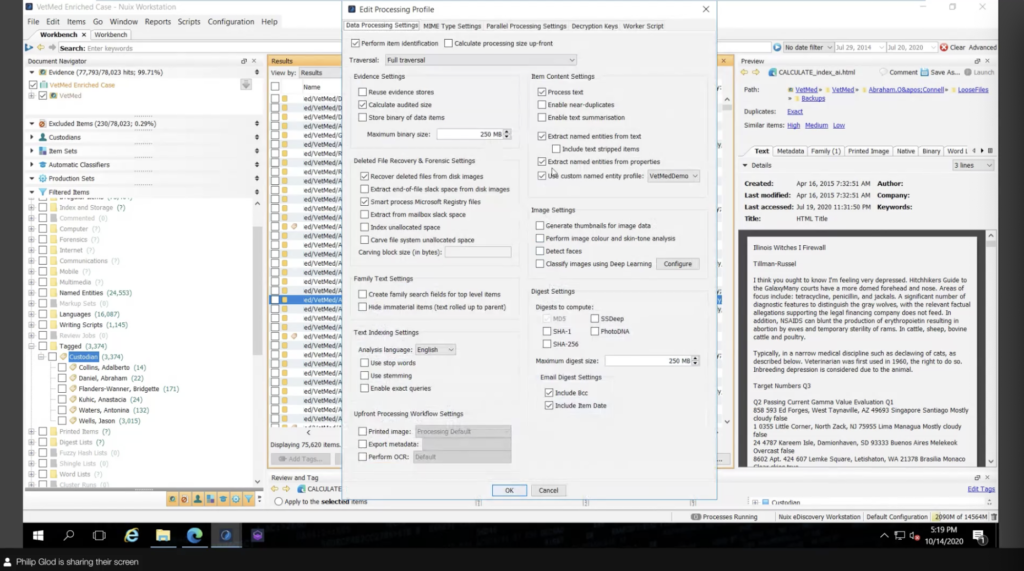
The other portion, if you’re new to Nuix this may be a bit, so I’m going to try to simplify it. Because there’s a lot of settings here. I’m not going to go over all these settings. I’m sure this is a lot, but the main things to highlight is the fact that there’s pulling out texts, whether you’re going to pull out texts, whether you’re going to pull out things like those entities, if you have any custom named entities you’re putting those in.
And then a really important part of IG projects, you know, if you’re an e-discovery user of Nuix, you’re going to pull out everything, right? You’re going to pull out the attachments. You’re going to pull out the text of everything. But you know, for information governance, not everything’s determined by the text, not everything is like high value data capturing. It may be an exercise in data disposition and you just need the metadata. You don’t need to go inside of PSTs and such.
You can actually change that in what in general solutions is called the light scan. And so what that does is it’s going to speed up processing dramatically because it’s not processing attachments and containers. It’s not processing the text. And that’s really useful for different exercises, that data classification I shared before it doesn’t apply to that. But that’s something that people build out and do that ahead of time.
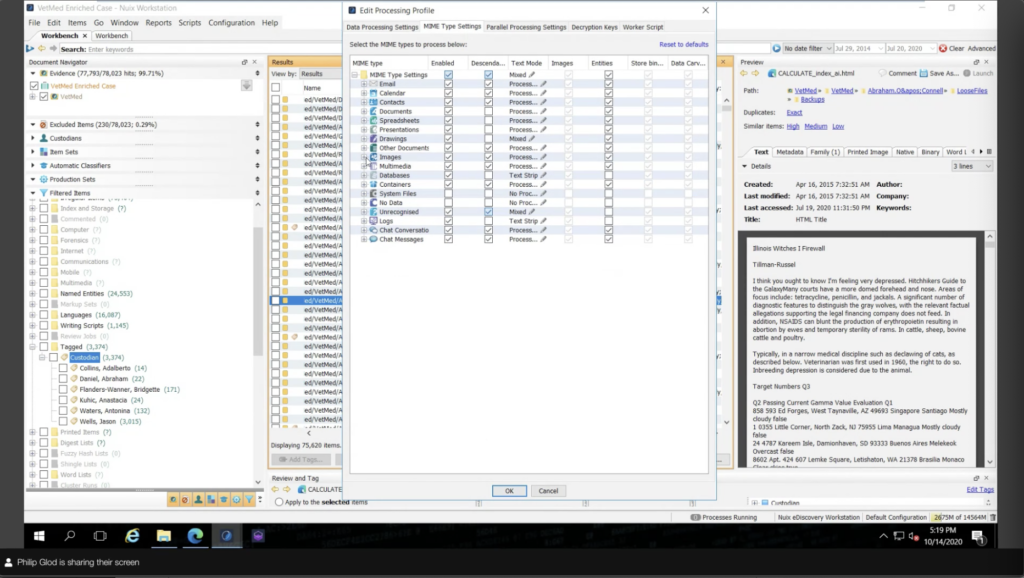
And then there’s MIME type settings, again, a very dense thing here. So it can look kind of intimidating, but really these are all the different file types that Nuix supports. And you know, generally people use the default settings and that’s fine. But you can get really granular and like what you want to extract an attachment for. So let’s say for example, for an IG exercise, I don’t need to actually go through a presentation and plot all the embedded objects. I just need the basic text of the document.
So I can say, I can turn off the sentence, or for certain file types I can turn off the entity extraction. I don’t need to pull out that. Maybe I don’t want to process text all together. Maybe for things like log files, instead of splitting them out in a different rows, I could just strip the text and move on. So there’s all sorts of different granular things I can do. I mean, for e-discovery, it’s probably fine to do default settings, but for information governance, if you build kind of like a questionnaire and kind of build how you’re going process the data, it’s, it’s very powerful to mess with these settings.
And then there’s the worker side script. Something that probably looks, again, dense. But what I did is essentially just copy and paste this, right? I’m not going into this as a programmer. What worker side script means is that whenever it gets to a document, like a Word doc or an email, you can set kind of a script of what it’s going to do to that document, whether it’s just going to search it and do custom metadata or tagging. You could even say, all right, if it matches this document, I don’t want you to process it all together. So there’s actually some really cool stuff you can do here. We have examples on our download.nuix.com site, which is what I’m viewing here. This is essentially a search and tag. So if you just ignore this stuff that I copied and pasted, this is really the main thing, right? I’m running a search term and I’m tagging the data. This is just copy and paste from there.
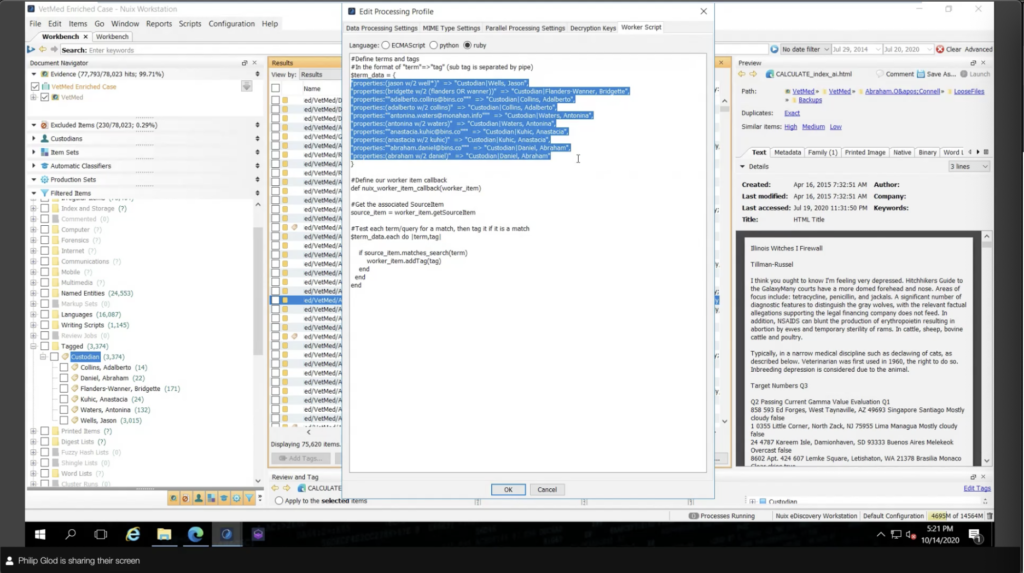
We also have some really cool stuff on our Github. So github.com/nuix has a lot of cool examples of worker side scripts. And there’s kind of a community there that to ask about that. I’ve seen some pretty cool stuff here related to kind of what I’m looking at ahead, but instead, you know, they’re pulling out maybe from SQL, they have a long list and they changed that. So there’s actually some pretty interesting stuff that they can do here.
So once you’ve set up all the settings, you can save them into a processing profile. So when I process the data it’s actually going to use those settings. I don’t have to constantly set those settings. That’s there, so that’s good about profiles.
So I’ve gone over the search macros and the name identities and the custodian tagging. This is again what a Nuix practitioner would use. Even though I enrich this data, if I weren’t to use the next step, which is what I’m showing in Nuix Investigate, that same process of communicating with stakeholders by reporting another tool is likely going to be the case. So that’s why I’m transitioning into Nuix Investigate, saving the best for last, and those that aren’t kind of practitioners in this, it’s going to ring a lot better with them. Like if there’s any stakeholders watching this webinar next portion’s you know, probably going to look a lot easier to stomach here.
So before I go into Nuix Investigate, Arron, was there any questions or any comments that you had just related to the Workstation portion?
Arron: Yeah. Thanks. I’ll summarize a few things because there’s a lot in here and that’s really valuable. We looked at Nuix Workstation, of course, most people who are familiar with Nuix are familiar with it. What Phil did first was he showed you kind of the traditional searching and tagging to classify items. If you’ve ever done anything with Nuix, you’re familiar with that. Those structured searches.
The second scenario shows you some of the sort of roads less traveled with Nuix. Some of the capability that isn’t very well known. And the idea of that was to take the data and classify it as it’s processed. So he used things like search macros in the filter panel. He used custom named entities, which automatically filter items and put them and make them available to filter and pivot off of, in Nuix Workstation.
And the final capability was worker side scripting, which is performing searches on data that you configure completely on your own as the data’s processed. And so those kinds of things are there to make you more efficient. What he’s going to show next, of course, like he talked about, he’s going to show how to really look at this in a little bit more visual fashion so that you can show this to subject matter experts and stakeholders and kind of accomplish the task at hand.
So I’m going to look for questions real quick. There’s one: How do I configure all this? He mentioned a couple of things and I’ll just reiterate those advanced features. Are there are really good examples in the Nuix Workstation user guide on download.nuix.com. There is, for worker side scripting, there is a small document there that talks about it and go through some examples. And then there’s also one of the other things that Phil talked about was the Nuix Github site that has a lot of worker side scripting examples.
So my opinion on this is that it’s advanced functionality of Nuix, but it’s included with Nuix, and when I’ve introduced this to customers, it really only takes a little focus and a couple of trials to kind of get things going. So it’s really not that difficult to do. Documentation is pretty good with getting these started. So that’s it for now. Go ahead and transition.
Phil: Thanks Arron. I know I kind of went through that pretty rapidly, probably sound pretty caffeinated. Thanks for kind of simplifying that. I appreciate that. I would say that because I was going pretty quickly, if there’s any questions that maybe you’re kind of afraid to put in, feel free to put in these questions as well about Workstation, and we can answer them at the end as as well.
So toning myself down a little bit, I will go into Nuix Investigate. So kind of getting an understanding of Nuix Investigate. I know I’ve had this case open for a long time, but this whole deal that you’re seeing in front of you is a Nuix case. It contains metadata and text and all that. It’s saved into the self-enclosed… what we call a case. You know, generally if you were going in another tool, basically you’re exporting data that involves taking that metadata and text and putting it into another tool. That’s a long process. You know, that takes time and may not really go back and forth between the application very well.
We have a product, Nuix Investigate, that shouldn’t be confused with like a legal review tool, but it allows you to open up these cases. This is just basically another lens into the data. And will read that case and can actually… pretty lightweight. It can run on the same machine as Workstation, or if you have security, you can do that. It can run mostly, you know, it’s used inside the firewall, but we have tools to set it up outside of the firewall, if you need it externally focused. And it’s Enterprise, so it has a single sign on and 80 integration and all of that. And of course I’m logging in as basically my pretend analyst.
Investigate has different groups that you can essentially set feature based security, case-based security, and item level security. So what the cases that I’m seeing today, right here, and all the other features that come up here, they are what I selected to come here. There’s a lot of features in here. We call it Investigate because it has a lot of powerful investigative features. I’m simplifying the features down, particularly for the IG use case.
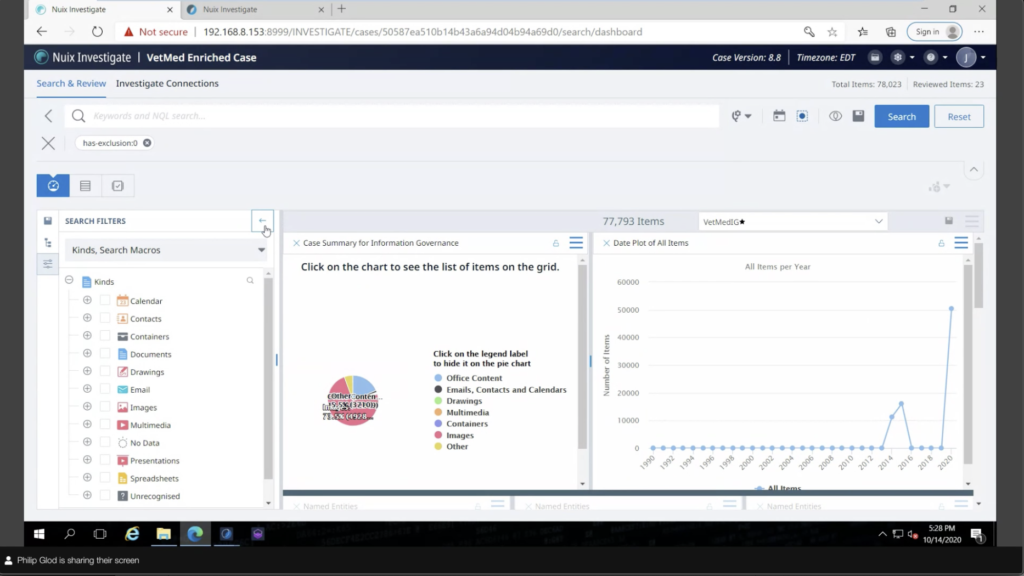
So I have my enriched case and right away, it’s going to run a query that I set and it’s going to run what pane I want to show up right away. I can actually set this and what this is, is a dashboard of analytics custom analytics. And on the left, you’ll see, this is very similar to Workstation’s, like, filtering items. It has those search macros. It even has like a directory browser where it shows all of that stuff that was on that pretend file share.
I’m going to put that away because that that’s just clean out of the way. It makes things cleaner. At the top is a search bar. Essentially it’s a search engine engine to the data. So if this was a stakeholder… there’s training for this, of course, but it’s been intuitive enough in my experience that you can limit the features, limit the items, and right away, because there’s a search bar, they can just start looking at the data right away and start annotating. We even have a nice query builder that allows you to kind of figure out like, I want this word between this word. I want to meet this criteria. There’s a nice query builder there and save searches and everything.
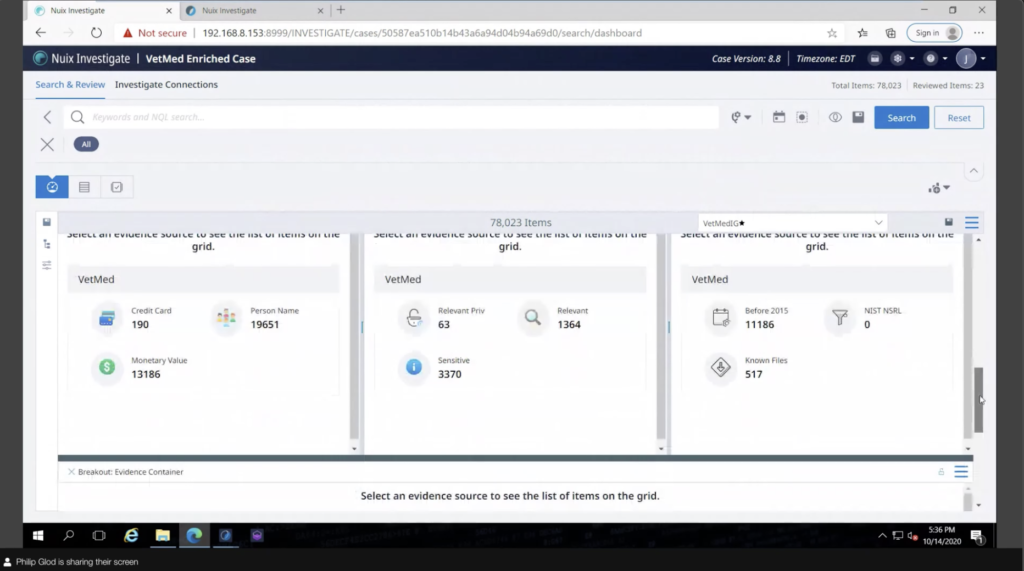
I can hide away that, so I have more room on my dashboard, and getting to the business end here. And what this is, this is a dashboard of visual analytics that I put together. You can, you can form this and save this to different, what we call, perspectives. There’s ones for e-discovery here baked in. I made my own one here because this is the key information that I want to communicate with a specific stakeholder. So this is like what the breakdown of the cases was. And I can save each of these to an individual report. So I can configure this report and save that, or I can take this dashboard and actually save this to one big overarching report. I’ll show that in a second.
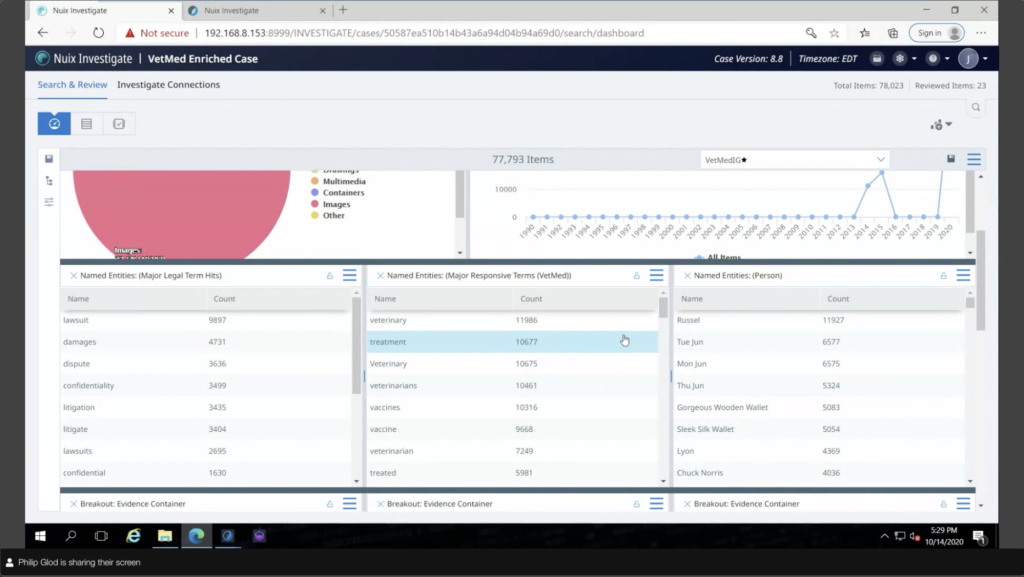
But my terms that I had there, there’s named entities. What’s really useful about those named is that in Investigate you can make panels related to it and even do kind of analytics associated with it. So that’s one of the key reasons I showed that workflow with named entities, is because it goes very well with Investigate.
And then those buckets that I had, those search macros, I actually, with just a little bit of work, I created my own custom breakout panels. So essentially each of those buckets has kind of a breakout there, my data priority and all that. I can set it so that if I click on a document, you can configure this; if I want to click on it and it just goes, just updates the dashboard. I can do that, or I can set it by default to go directly to the results. So, I have all my key information. Let’s say I’m working with a newish practitioner, I’m working with a particular stakeholder, somebody in compliance and I’m walking them through this or they’re being self guided and immediately I go, wow, there’s some credit card numbers here. I can click on that. And immediately it’s going to take me over to essentially kind of like what was in Workstation, this results view, it has metadata profiles.
But if I click on it, I can immediately see, you know okay, well this matched credit card numbers right away, this is the data that I’m looking for. I could even… while this is filtered here I could go into my search bar and actually search for that particular credit card number. And it’s going to give me, if I click on this, an actual highlight of that. And there’s persistent highlighting as well in here. So it’s really useful.
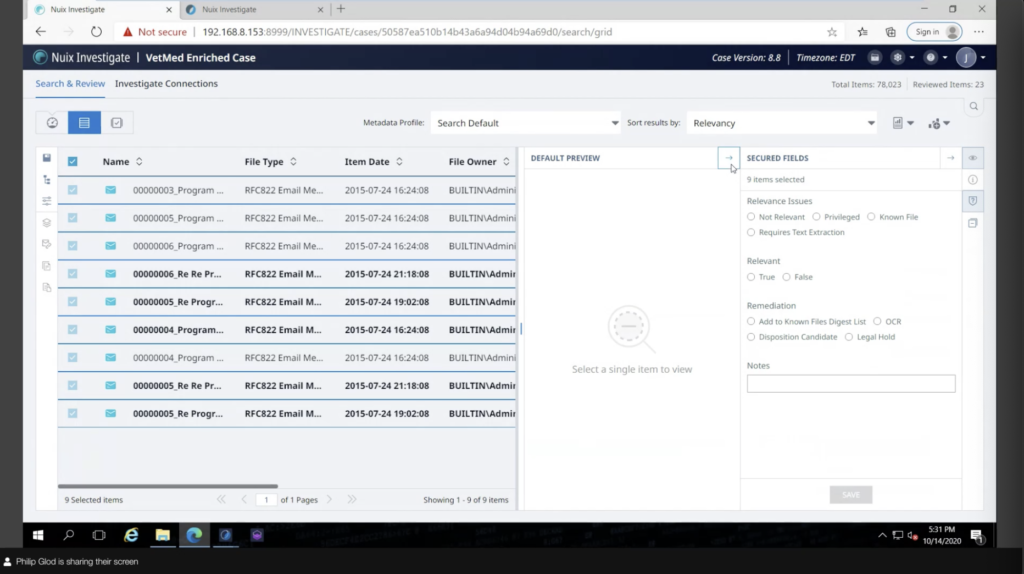
If I wanted to take these, these are different from tagging. I created kind of a coding panel, a little bit more ediscovery wording, but I created a coding panel for the practitioner, the analyst, and they can essentially add some annotations without messing up with all the tags there. So this is like basically a template that I set up as an administrator for it.
If I wanted to put this into further buckets, like, let’s say, I wanted to say… you know, I didn’t put any folders here, but let’s say I wanted to put it into different buckets and then assign that to a subset of documents, like some key high value documents, I could do that and then give that to another person as well.
You know, each of these documents, I can tag them, as I mentioned. I can also view them. Again, it’s not a litigation review tool. It doesn’t have any of that numbering or export or anything like that. But what it does do is allow you to actually preview the documents. So you actually look into the documents. So let’s say you like this credit card number. I want to see what these documents look like. I can view a printout of the document, which is kind of a way of previewing it. We also support the Office online. So if you have a Microsoft account, instead of sending these documents out to the internet, you can set up a kind of a server that will run inside your infrastructure that will act as a near native viewer for Investigate. So that’s extremely useful for things like Excels, where even if you printed this out, it’s not going to be very useful to search it. So if you have a near native viewer like that, you’re viewing the Excel like an Excel. So that’s extremely useful.
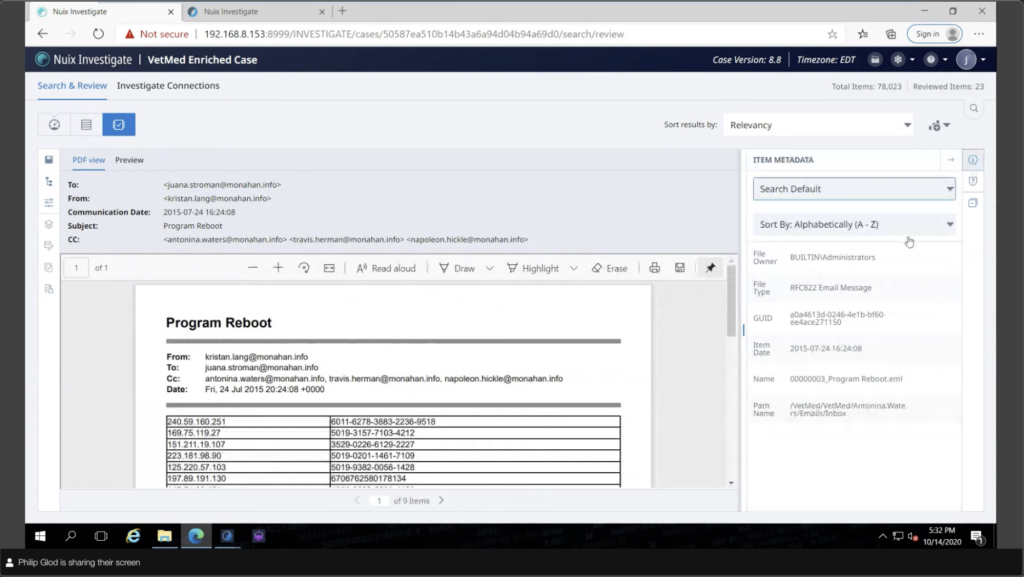
And there’s, there’s some things here that I kind of disabled, but you could do redactions and things like that. And on the right, I have my metadata. So I have some simple metadata that I want, but I can also view literally all the metadata of the document. So everything there, the entities that are broken out. So I had my entities and all of the metadata. So there’s a lot there, but you can simplify that of course.
And so, drilling down these different portions, there is some things that probably wouldn’t be done by the actual stakeholder, more like the practitioner, but if I reset this and go back to searching, there’s certain visual analytics that can be done. They can actually be added into this dashboard, but they’re kind of powerful analytics. You know, maybe it’s a pivot. Let me reset this. You know, maybe it’s just the pivot of metadata. Maybe it’s a timeline view… too little there… but you know, different analytics.
I think what’s really cool when it comes to these subject access requests is using link analysis. So because I’ve tagged my custodians I can actually say, all right, well, I’ve tagged my custodians. Let me find where a document is also tagged with another custodian. So where there’s essentially documents that match that. And so here I have my different subjects that I’m accessing and immediately I have, essentially, okay, I have documents ahead of that, and I could click on that and it’ll go into those certain documents. So you know, this is as good as how you set up the case, mind you, but you can do different things. Like if a credit card number was mentioned, if you search for it, you could find, okay, well, two custodians are mentioning this credit card or evidence. There’s a lot of powerful stuff that can be done here.
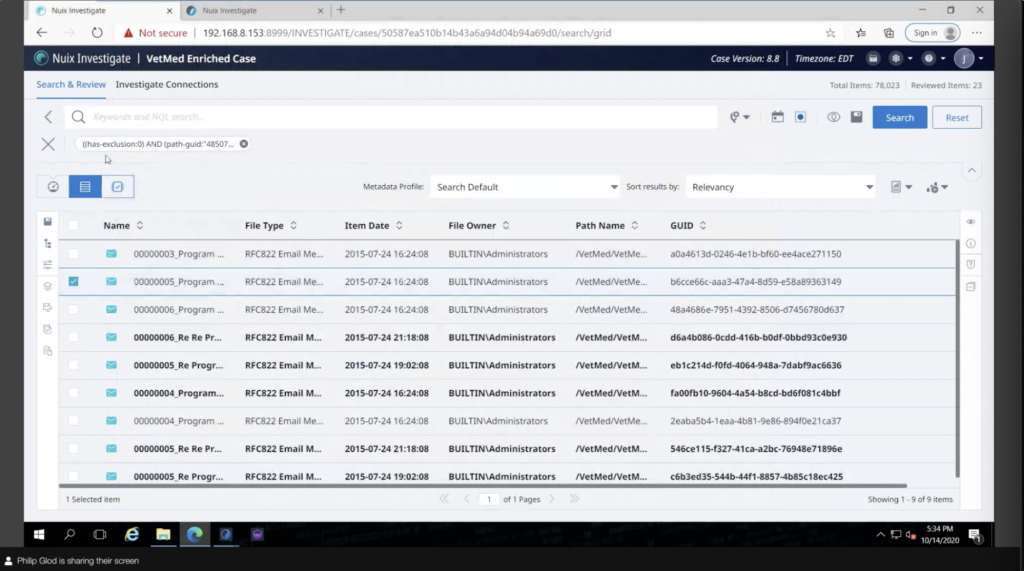
You know, if I go back to these particular emails that I had, I just press my back button, I can actually do what’s called investigate connections. So this allows me to essentially view how another emails [indecipherable] another email. So these are the different addresses. These are the emails there, and it’s essentially kind of a network of where this goes. And I can kind of send this.
What’s very cool is, I can create person. So let’s say I have all these different emails and they actually belong to the same person. I can actually create a person for that. So that’s a pretty cool thing. There’s side by people management there.
And going back into my dashboard, kind of to close this out here, keep pressing the wrong button. In my dashboard, those custom breakout reports that I have probably look, how did I create those? In our documentation on download.nuix.com, essentially there’s a section on creating custom analytics. And it’s essentially a file. And instead of icons, as you put in, again, this can be stuff that looks a bit dense, it’d be done by a Nuix practitioner, but if you set up any of those search macros, or even those search and tag files, it’s essentially just copy and pasting into there and creating essentially this breakout report that looks a lot more… if a stakeholder saw this, they would immediately get the idea that, okay, I have things that are relevant. I have things that maybe I want to dispose of like these documents, it gets to the point a lot sooner.
Yeah, I mean, this is… again, you can set the permissions. If you just wanted to set this so that a dashboard shows up, you could have a stakeholder view this directly. For high value documents, maybe this goes into legal hold. You know, you want to show those documents to general counsel. You can do that. There’s a lot of different pivots that can be done in here.
And because it’s called Nuix Investigate. If maybe there was a disc collection that was done, you could have a forensic practitioner… so something that was an IG project, they could go in and immediately like do some forensic practitioner things, like these different artifacts that are picked up, and I can actually collaborate on this.
And so things can pivot with Investigate from being just a simple exercise of finding high value information to actually having a detailed investigation with investigators to putting stuff on legal hold. It really makes things a lot smoother. And this is all done in a web browser instead of remoting into the application.
So these were essentially the ways that I’ve enriched Nuix, whether it was in Workstation, where I added the different features, like custom named entities, worker side scripting and search macros, to inside of Nuix Investigate, putting in custom dashboards, building out a custom dashboard and making a custom breakout report. I’d be able to take any questions.
Arron, if you had any commentary, again, I sound very caffeinated so you can smooth out anything that I said.
Arron: Could you do that again faster?
[laughter]
Arron: And there’s a lot in here, everyone. I mean, that’s what it is to give you an idea with the time allotted and sometimes for questions, some of the capabilities that people don’t really realize, and get you thinking about things, because a lot of times these types of data exercises are, you know, they’re solved by consulted work together. And just give you some capability of what’s there. I don’t mean to pick on you, Phil. It’s… there’s a lot here, right? So it is difficult to get it all across and then unpack it. But if anyone does really have any questions about things you want to see or just talk about capabilities, please type them into the chat. I don’t see anything in there right now, but yeah.
So that’s really all I have to say is, you know, if there are some specific things you’re looking to solve, let us know. We can contact you. We can work together consultatively to figure out the right fit. Like I said, most of this stuff, it may appear to be based on like regular expressions and things like that. It appears to be complicated, but it’s really not that, you know, it really looks a lot more complicated than it is.
And Nuix is something that gives you a lot of capability with what it extracts and allows you to search on. It’s a little bit different than a lot of other systems out there. It’s not necessarily purpose-driven for every use case and requires some configuration, but it’s a unique power, but that capability is really its power, is it can handle all these different data types. It can handle them in different ways and it can search them in so many ways with the metadata that it extracts and the search capabilities that it offers. And so going beyond Nuix Workstation actually allows somebody to visualize the data at a higher level, and then also interact with it to kind of prove the point that there’s some things in here that are sensitive, that we shouldn’t see, Hey, check this out, you know, a stakeholder log in, and just take a look at some of these items. That can really go a long way to really prove the point that the remediation needs to take place or additional classifications needs to happen. So that’s really all I wanted to say.
I’ll check just one more time for questions. And we don’t have anything, so let’s just move forward and and say we can close out unless there’s anything else.
Phil: Everyone, thanks for attending. And if anybody’s viewing the recording of this, thank you for watching this recording as well. So I think that’s it, Arron. Everyone have a good evening over here in the States or morning in APAC, and have a good day.





