
Jamie McQuaid: Hello everyone. Welcome to today’s session on forensic considerations for cloud data storage. So who’s this presentation for? I wanted to introduce it with some expectations here. So generally we’re going to talk obviously about some cloud services. So I’m hoping that most folks have at least some basic understanding of cloud usage, you know, the basic terminology, but maybe you’ve got some limited usage. I’m aiming kind of middle ground there. So if you’re brand new to cloud, there’s definitely going to be some terms thrown around that you may not recognize. So keep Google handy. Or if you’re well-experienced and using cloud, hopefully you still learn something from this today. So I kind of tried to balance it out a little bit.

But what are we going to look at? Cloud storage options: we’re going to focus on AWS and Azure for this presentation. I know obviously there’s a lot of other ones, Google, Oracle and, and plenty of others, nothing against them. I just spend most of my time in AWS and Azure. So that’s that’s where we’re going to focus our efforts. There’s plenty enough to talk about for those two alone.
We’re going to first talk about how to use it securely. And when I’m talking about using, we’re going to talk about using it as a piece of our toolkit, but also how to collect it from an evidence standpoint, there’s kind of two pieces to this that we’re going to dive into. So using it securely is going to be important, but also how to collect it while maintaining the integrity of our evidence, just like we normally do with, with any sort of evidence that we deal with.

And that’s going to be a reoccurring theme throughout, is really managing our evidence in the correct way and the way we know very well and is well established for many years. So let me change the slide here.
Who am I? My name’s Jamie McQuaid. I’m a technical forensics consultant for Magnet. I’ve been here for just about eight years now. And I’ve been around DFIR long enough to see many technology transformations. I know that makes me feel really old and whatnot, and I’m sure many of you have as well. You know, the big ones come to mind is volatile data, like memory, and mobile devices, obviously acquiring those come with additional challenges. A lot of it’s live data and stuff like that, constantly changing. We’re not only dealing with hard drives and dead box forensics these days. There’s plenty of other avenues that we need to deal with when dealing with evidence.
And cloud’s another piece to that. It’s another transformation in technology that we need to recognize, right? And it’s important to evaluate any technology for its value, right? You don’t want to overemphasize it, but you can’t ignore it either, right? As examiners, it’s our job to go where the evidence is, whether it’s on a person’s computer, their phone, in the cloud, wherever it is, if the evidence is there, we need to understand it well enough to speak to it and collect it and analyze it the way it should be handled properly.

So that’s really what the focus is going to be here. And really that’s what we’re going to center around. So a brief agenda of what we’re going to talk about, and I hinted to a little bit already is, first off, we’re gonna talk about cloud as evidence storage. So adding it to your toolkit, right? The cloud is just another computer that you can use to keep your evidence.
Now, a lot of people, they do everything on prem, off network, air gapped, all of that. Some other good organizations and teams don’t, there’s different ways to handle different things of evidence, different considerations that you need to have. So cloud as evidence storage may be accessible or usable for you, it may not. It may be eventually down the road, as well. So there’s definitely some considerations you’re going to have to make as well.
Personally, it’s something I use quite a bit, and it’s certainly something that adds value to my analysis in my capabilities. Right? So we’re going to talk about why you would use cloud as evidence storage. We’re going to obviously talk about security considerations, because usually that’s the biggest flag that people come up like, oh, it’s not secure. I can’t, I can’t use it. So we’ll talk about those and see how those can affect your investigations and the way you store evidence or use the cloud. And like I said, we’re going to talk about using AWS and Azure. I’m kind of going to flip back and forth between the two and, and show parallels.

It’s really neat to… the hardest part about learning cloud is — especially if you’re using multiple cloud technologies or providers — is really just trying to understand what the equivalent is on the other provider, it’s like, okay, Azure calls it this, what does AWS call it? It’s actually really one of the harder of learning things with cloud. Microsoft got a really good document to compare that, but again it’s… there’s many parallels and they each have their own value too. So sometimes AWS may be a better option for a particular feature and will Azure may be better for something else, right. Utilize what’s what’s available to you and what works best, just like, you know, in forensics, you have a toolkit, use the best tool for the job.
But then we’re going to flip it on the opposite side and say, okay, we may use it as a part of our toolkit, but we may use cloud storage as part of our evidence as well. We may come across and say, Hey, we’ve got to do a cloud collection here and collect some of this data. Right? And there’s lots of cloud storage evidence locations, you know, we support a lot in AXIOM, but there’s just, there’s plenty out there. I’m going to focus on the platform based ones with AWS and Azure. And we’re going to talk about the sources within those.
Obviously we can expand that to many other services, Dropbox, box.com, even Microsoft 365. I’m not going to get into here, but there’s still another source of evidence with that. So we’re going to talk about those sources, we’re going to talk about considerations during your acquisition of what you may want to evaluate and use when you’re doing them. And like I said, again, back to AWS and Azure.

And then we’re going to go into some examples. I’m going to show you what some of these examples are, and you can collect them in many different ways. I’m just going to give a few tidbits and in ways that I collect some of this data.
So let’s dive right in. The types of cloud storage. Obviously there’s lots of different ways you can use cloud storage or use any sort of storage mechanisms. The two we’re going to focus on here is object storage and compute storage.
Object storage: usually when people think about cloud, the first thing they think of is object storage. Usually that’s S3 for AWS or container/blobs service in Azure where you’re storing files, or just your images, your case data, whatever you want to do from from an evidence standpoint, or from an investigative standpoint, you would use object storage for that.
But then you can go a step further with compute storage. And obviously, you know, people usually talk about like, oh, I’m going to collect an EC2 instance from AWS and everything. Well, you’re not collecting an EC2 instance, you’re collecting the storage volume too, is just like, you’re not going to collect my laptop. You’re going to collect the hard drive in my laptop and analyze that. Right. Nobody really cares about the screen or the… I guess maybe the printer, but whatever.

You’re not worrying about that. So we’re going to talk about compute storage, specifically EBS volumes and AWS disc or attached storage in Azure, obviously the big pieces there, and that’s where the bulk of ours are, but there are other areas that you can consider storage. There’s a lot of data lake processing options, but also databases. Yeah, you could run a database on an instance where it’s included in the compute storage, but both AWS and Azure offer services that manage that for you. They’re already managed, and they just give you the database to manage it. So again, depending on your investigation that may or may not apply. We’re not going to get into that too much here, but there’s plenty of other sources as well; containers, obviously another one if you’re using or investigating those, they may be at a different location, different place that you may want to consider.
And then logs will come into play in a few places as well. We’re going to get into that more on the… later on. So, but I figured I’d start here and we can continue on with the logs after, but it’s it’s going to be vital for tracking activity in the cloud.

So cloud is evidence storage. The first question is going to be: well, why would you do it? Why would you use cloud as opposed to an on-prem lab or data center? Well, the reasons may vary for each organization. For me, the first big one is unlimited storage potential. I’m sure most of you have probably hit a case where you ran out of storage somewhere and you kind of hit a roadblock and you said, okay, we’ve got to go buy five more drives to get this going, because we don’t have enough space to manage it. You always have that one case that just balloons to a huge amount of storage. Well, with the cloud, you could technically never run out of space again, well, assuming that you can pay for it and afford it. They’re always going to have that capabilities, but again, it will be important to keep that.
Processing options. Lots of different processing options, both on types of platforms to run: Windows, Linux, Mac, you can run processing on that. So all the tools that you can imagine, right? I’m a big Windows, Linux person. I use Windows and Linux quite a bit for my investigations, but I don’t use Mac a lot, but I could certainly use it sometimes, that can be very helpful in my test scenarios. I’m like, oh, I got to reproduce this, but I don’t want to buy a Macbook just to do this. Well, I could spin up an instance, spend two hours on it and get what I need. That can be really helpful and adds to the cost savings for a lot of the hardware and storage costs that that we come across.

And then speed. I’ve got a decently fast computer here. I use it. Yeah, I’ve got another faster one that I do some heavier processing on. Great. But that stuff gets old fast, and sometimes you can’t keep up and you want something faster. Guess what? You can just pay for it: in a click of the button, you’ve got faster processing, you’ve got more memory, you’ve got all of those things. Again, it comes at a cost, but if you’re a consultant working with a client who said, they need it now. Well, they’re willing to pay a premium for it, then that’s certainly to it.
So that’s also important, sharing with external stakeholders. That’s a big one for me. It’s you know, the days of seeing DVDs, USB sticks, all of that. I just, I hate it. So sharing stuff securely with your stakeholders is also very valuable in terms of cloud storage.
And then also, cost savings. Like I said further up. There’s certainly things that can cost a fair bit using cloud, but if you use it in a smart way, you can save a lot of money in terms of hardware costs, storage costs. Because a lot of what you’re doing can be temporary, or it can be permanent. Maybe you’ve got something you need to run constantly 24/7, whatever, great. But if you don’t, you can instantly spin something up and then tear it down for the exact amount of time you need to use it. And you’re not paying for that time in between, that idle time of your computer just sitting there in a lab, right? So you’re paying probably a little bit more of a premium per case, but you’re not killing time or wasting investment in that time between. So the fact that it can be so temporary is actually the biggest part of the cost savings.

So let’s start with security, because that’s going to be the biggest question for most people, is how do we demonstrate the integrity of all evidence? So how do we do that today? How do we demonstrate the integrity of our evidence today? If we ignore cloud for a second, how do we do that?
If you go back far enough in your forensics 101 training, usually the two biggest controls on that is we limit access and we control access, and we use a chain of custody to track who’s touched things, we limit access using evidence vaults, or lock up things into a specific room or have control over it. And then we use chain of custody forms. You know, I still use them to this day, use chain of custody forms to track that evidence.
Well, that’s just access controls and auditing your access. We can do that with computers very well, and we can also do it with cloud. All the cloud providers provide really helpful access controls. ‘Helpful’ is a loaded word there! Access controls and audit access. So you can control who can access, what they can access, what they can do with the data that they access: they read it, can they write it, can they delete it? Can they whatever? You can control, to whatever degree you want, that allows some very good granularity that we’ll get into for some of these sources.

And then how do you, how do we prove that your access controls work? How do you prove that, like, okay, you set these up, but how do you know they’re working? Well, you can use your audits, controls and access controls to audit who access them, right? That’s your chain of custody. It’s the same parallel. They’re just on a different level, right? So not only do you want to control that access, you can audit and improve that access too.
So let’s talk about AWS first. Storing evidence in AWS, like I said, we’re going to focus on object and compute storage. The first one for object storage, we’re going to talk about S3 buckets. And this is where you’re going to, you know, from a storing evidence standpoint, you’re going to your evidence and E01s, AFF4s, your forensic images, or it could be just files. It could be zips, it could be just files, but you can store that data in the S3, just like on a network share on your local machine, or I guess, in your lab or on your local machine as just a storage drive, same concept applies.
You can also archive it again, if you need to have requirements to keep your case data for several years, that can get very expensive, even on prem. So finding a good, cheap way to do that archive wise can be really important. Same thing goes with computing storage. Well, you probably want to process this data at some capacity, whether it’s local or in the cloud will depend on your situation, but you can certainly utilize that computing capacity. And like I said, the benefits of it, obviously I mentioned earlier, and you can run your active cases while in the cloud and then bring it back.

So again, it will vary quite a bit. The nice thing about S3 and a lot of the storage process: it offers durability and high availability. So you can with S3 and the computing storage, you can actually have that security so that, you know, well, if you have to drive to [indecipherable], you’ve got to have those considerations. A lot of that’s built into the cloud providers as well. So that could be really helpful.
So let’s start with access controls in AWS, and I could probably do a whole talk just on this! I can actually probably do a whole talk on every single one of these slides. So we’re getting at it a little high level, but I wanted to introduce a lot of these topics first.
So the first way you’d manage access controls in AWS is through IAM. It’s basically where you control the users, groups, roles, policies, and stuff for individual users or services. You know, most people know what a user group or role is. It’s really… you apply policies to either of those or any of those. And it says what the user or service or role can or cannot do.
So what they have is AWS managed policies. And they have customer managed policies as well as inline. But focusing on the first two for a second: AWS managed policies, they have lists of policies that you can allow or deny any given thing for a hundred different situations, more than a hundred, but lots of different situations. AWS has a list of policies that you can utilize and they’re predefined and work really well.

But if you want to get more granular with it and define your own policies for specific things, customer managed ones work quite well. And you can define that, set those up. I’ve got just an example of the IAM policy there for Amazon’s managed policy for S3 read only access. And that’s, it’s a JSON. It, it generally looks like that. It basically allows you read only access so you can get or list the S3 data, but you can’t write to it or delete or anything like that. That’s a very simple policy.
Inline policies, don’t get into it too much, but really those are specific to an individual user and you want to target it for say, Jamie needs this policy in this sense, you’re not going to build it so that everybody can use it. It might have something referenced specifically for me, you would then use an inline policy for that.
Now, we were talking about the users and the services and stuff, but you can also use bucket policies. So when you go into S3, you create a folder, it’s called a bucket. You can set up policies specifically in those, and you can say, okay, everybody has access to this bucket, but only these three people have access to this one. So everyone who has access to the account can access the one, but not the other one. You may control access to it. So it basically does it on a higher level per bucket. And it’s structured in JSON, very similarly to the IAM policies, but you can control access that way against people within your own account.
Then the other one is bucket ACLs, or access control lists. Now these are a little bit older, not used quite as much anymore, but what they do help for is if you’re trying to get a little more granular within a bucket, bucket policies supply to the entire bucket, but you may have files or objects within that bucket that you want to control access to. You can do that with ACLs a little bit better. It allows more granular control at a project basis, which can be helpful.
And then, the last one I’m going to mention here is pre-signed URLs. Okay. We talked about stakeholders and sharing data securely with stakeholders. Well, we’re not going to give them an AWS account and say, go into my AWS account. Here’s your login and go in that way. You could, but you probably don’t need to for all your stakeholders. Well, what if you could just securely give them a URL that’s time sensitive and controlled to specifically for them, you could set up pre-signed URLs to share private objects with others folks temporarily. You can generate these by the CLI or the SDK. We’ll talk a bit more about this, show some examples later on, but you can actually apply these and send this URL to say your stakeholder and say, Hey, here’s your report, click on it. It’s good for the next 24 hours, that thing will die and nobody will have access to it again. But it’s specific to you. So can be really helpful for sharing data externally for folks that are part of your organization or anything like that.
So what about encryption? We’ve talked about access controls already, and probably some of you have been like, well, we should have talked about encryption first. Well, yeah, I kind of debated back and forth. Should we talk about encryption or access controls? Encryption fit well here, because I wanted to introduce it here. And obviously you’re going to want to encrypt your data while on the cloud. And there’s lots of options to do that. Some are… the encryption is solid verbal to AWS and Azure is very good. They have their own self-managed, or AWS managed encryption options for S3 and EBS. You see further down there, they allow you to audit just by the click of a button. You can turn on encryption for both S3 buckets or EBS volumes. The default is off for both of them, but again, it’s literally a click of the button. You can see in the screenshot there, the default AWS slash EBS, that’s to turn on the basic AWS management.

Now, technically they control the keys, so they could decrypt it. They have their own processes around that, your data is secured, but maybe you need to take that extra step. Now I’ll use the default AWS managed stuff for my day-to-day activities in the cloud, but if I’m dealing with evidence, I’m probably going to use something a little bit more secure, using either KMS here, where I’m going to use my own customer manage key. In those situations, I can import my own key material to use, and actually allow myself to manage it. Now, AWS is not going to help you if you lose that key. So it’s really important for you to recognize the importance of setting it up this way, and then being cognizant of the risks that are involved with it.
So you can even go as far as using CloudHSM, which is hardware backed. So you can actually use hardware backed keys, and that may be a requirement if you’re in FIPs environment or something like that, that you actually have to use a certain level of FIPs 140, I believe, dot two or three. But if [indecipherable] will satisfy that and allow you to do that hard work back key management. So there’s lots of different encryption capabilities or options that that we can get into here.
We’re not talking a ton about EFS, but EFS is just like a network share for file system. You can use cloud client-side encryption too. So if you’re on the box, you set a BitLocker on that box. It’s got nothing to do with the cloud. You’re setting it up in that system. And you can control that yourself. Right? So that’s outside the scope of AWS. They have no visibility to that. And then you would manage that yourself as well. So client site is also an option to that.
So now, what about audit access? You need to be able to prove that you did what you said you did. So the big one for AWS is cloud trail. Cloud trail will audit all access via… that is called via the API, which is either through the console, command line, or the STKs. So it’s basically anybody accessing anything in AWS. It gets logged in CloudTrail. The last 90 days gets dumped into CloudTrail as a service. And you can download either the JSON or the CSV. Older stuff, uou can set to save to an S3 bucket, which again is going to be helpful because we’re going to use that. So we use S3 buckets already and you can save that indefinitely. You may want to save that forever, or at least six, seven years, depending on retention policies and whatnot. And that’s a JSON.
Now if you want to analyze the stuff again, the last nine days is easy. I would… in the console it’s pretty easy, quickly to do a quick audit on things. And we’ll show that in a little bit. And then in the cloud you use a console, or if it’s in S3 bucket, Athena is a good service. Even if you’re not great with SQL, it uses SQL queries to query that that JSON stuff in S3 for… to go through like an entire organization’s worth, it gets messy. But again, even if you’re not that great with SQL, it’s a good way to do so.
Maybe you want to download those. Maybe you’ve downloaded that CSV or JSON data and want to download it to your own infrastructure here. You can use anything to analyze it locally: elastic search, Cabana Splunk, Grafana, even AXIOM. I know some other folks are chatting a little bit about that in other talks that you can ingest some of that stuff right into AXIOM. So that can be very helpful.
And then there’s other types of logs, you know, we’re just talking about AWS access, but you may want application log access. So specific applications that are being used in your infrastructure, you can use CloudWatch to do that, custom scripts. We won’t get into that too much, but one thing I wanted to call out that may not be visible or people may not recognize is, the one thing that CloudWatch and the application logs don’t track is your EC2 instance access. So somebody SSHing or RDPing into your computing resources, that doesn’t get picked up because you’re just… it’s network activity or it’s activity just to the actual host.
Oh, guess what? We know how to do that. We’re examiners. We know how to analyze event logs and unified logs, syslog, depending on the US. We’ve been looking at that access and access controls, and you can look for Windows events of log in and log out activity and stuff like that. That’s your standard forensic stuff, so that still doesn’t go away when you’re dealing with some of these auditing sources. You still just want to consider that, Hey, all this stuff is going to be here. All of the on-OS type stuff is still going to be on those systems. And we want to collect those and analyze those as well, depending on the case.

So let’s flip over to Azure here and talk a little bit about the same things here. So let’s real quick and go into the same type of parallel stuff about storing evidence in Azure. We’re going to talk about object storage and computing storage, again, just like we did with AWS. They’re called a little different things. There’s different features involved with some of them. So I’ll call some of those out as I go through it.
Object storage generally, we refer to that as blob storage. Again, same idea, you’re dealing with files, images, stuff like that. That’s where I store a lot of my images, in terms of keeping a large list. I can only have so many hard drives and stuff available to me. It’s a pretty good collection, I guess! But same sort of concepts apply where you’re doing with object storage and then computing as well. You’re going to want to do some processing. You can use VMs and the disks associated to those.
So how does access controls look in Azure? Luckily, if any of you are familiar with using Windows active directory, this is very familiar to you. Azure active directory is a very similar setup. If you’re not, it’s kind of new, you’re still dealing with users, groups, roles, same sort of thing. You can set up access policies and it’s very easy to follow. But ag,ain, the nice thing is if you are familiar with active directory, which has been around for forever this will be a somewhat familiar transition for you.
One thing I wanted to call out here at the bottom is shared access signatures, and we’ll show it off here in a little bit, but the really nice thing it’s very similarly… the pre-signed URLs with AWS. this allows you to create a URL, a security… temporarily giving access to to an object or an asset for someone in your… outside of your organization. So you don’t have to give them AWS or Azure access. You let them log in and you give them a URL and they can directly access it for a short period of time. So I’ll show that.
And the nice thing with I really like about the Azure ones is you can restrict it by IP address. So I can say, Hey, give me your organization’s IP address. And we’ll lock it down to just that, or give me your IP address, and we can lock it down just as only you can access this and you can control by the the IP addresses as well as all the other time and other limitations. So that can be really helpful.
So what about encryption? We talked about encryption for AWS. For Azure, very similar. They have a key vault that allows you to store, generate keys, secrets, certificates, sorry. And allows you to manage those in one spot across your account. And again, by default, they have a lot of encryption turned on all already on both the blob storage and the VM disc are encrypted by default, but they’re using the platform managed keys, which is good for a lot of my data. I just, yep. That’s good. That’s how I do it. But you may want to use the key vault and use customer managed keys in the same way for any of your evidence, because you may have stricter controls or may want to consider that for it. So that option is very easy to drop down and set up the keys and then select whatever ones you want to use for it. But encryption is on by default for both of those Azure resources. If you want the additional steps, using key vault is definitely the way to go for that.
Another note is data in transit, by default it’s encrypted and will deny HTTP traffic. So that’s important to recognize that is going to be encrypted by default. And you can allow HTTP traffic if you want, but the default is having it on. So maybe you should just keep the HTTPS set up and away you go. It just, it’s, it’s a better default to have. So I applaud that and then suggest, unless there’s a very rare situation where you don’t want encrypted traffic.
Another one that’s actually kind of neat, you can set it to prioritize routing over the Azure network. So instead of finding an entry point wherever, as soon as it gets to your your storage account or anything like that, it can find the closest access point to the Azure network for whoever’s accessing that data and enter there and traverse across the Azure network, making it just a little bit more secure. Yeah, you’re still encrypted, but the less stuff that goes over the internet — now, you’re obviously trusting Microsoft to do that as well — but I’d rather trust Microsoft over it, then say you know, just the, the general 1200 ISPs that it has to travel through her or whatever, along the way, you know what I mean? Right? It’s it prioritizing routing over the Azure network as opposed to the public internet. It’s just an extra layer, to me which I also like.
So how do we audit access in Azure? Lots of different ways to do that as well. Here is logs again, logs all day every day, they have the activity log which allows you to track subscription activities. You can export that into a CSV, just like we did with a cloud trail in AWS. And you can dump that subscription level activities out very easily, but it gets really complicated if you start doing that on a single individual resource, the access logs and stuff, you know, you can look at individual ones, but if you want to track that across a lot of different resources, different accounts and stuff, you probably want to start using log analytics via Azure monitor.
Really nice way to consolidate your logs and do your analysis that way. You just need to enable it through the diagnostic settings, and it’ll start feeding it through to your workspaces and you can do plenty of analysis within the cloud, or you can dump any of that stuff out, just like we had talked about earlier.
So you can also use log analytics for application logs. It’s not on by default, but you can configure an agent to say maybe you logged your application, your web application logs stuff to a text file. You can have the agent pick that text, file up, read it with a little bit of work, and then it gets pulled into the rest of your logs as well, that works quite well. And then the same thing goes with our VM access when you’re accessing it through RDP or SSH, your Windows or Linux boxes. You’re going to still want to audit that access and take a look at it. So be aware of those limitations as well.
Okay. So now that we’ve talked about using cloud as a storage mechanism in our forensic toolkit, right, as something we would use to expand our toolkit, what about evaluating it as evidence? This might actually come up before you end up using it as a cloud storage. So I don’t know which one’s going to come first for you, but being aware of it either way is going to be helpful in understanding your your investigation to it. So we’re going to talk now about cloud storage as evidence, right?
And guess what? All of the things we just talked about still apply. They also apply the same way, if you’re collecting evidence from any of these sources, they’re the same things. You’re just using them in a different way. You’re using them as part of your toolkit if you’re using cloud storage, or if you’re investigating them the same protections, the same rules apply. I threw in logs there, because now we’re going to get into actually a little bit more detail to it.
But it’s important to recognize that yes, a lot of the object storage, compute storage, databases, containers, images are also, you know, nothing changes. It’s just your purpose for them changes. You may deal with them in a different way, but they’re still going to have those same rules around auditing access or access controls. And that can be very helpful.
So some initial considerations here. You know, how you collect it is going to vary for each case or even your organization. And these are kind of considerations I take to whether I want to analyze it in the cloud or bring it back local or whatever I do in between. Is your analysis being done in the cloud or local? That’s an important thing to consider, right?
Or even further after that, even if you do bring it local or it is local, are you going to be storing it in the cloud afterwards? You know, it’s not going to do it… there’s no point in copying it local, the cloud data. If you’re just going to push it back up to the cloud after you’re done, it’s just going to cost you more money. Right. It does get pricey moving things in and out of the cloud. Generally, you get cheaper preference if you keep data in the cloud. So if it’s in the cloud, analyze it in the cloud, if that’s a general guideline for me if it’s in the cloud, analyze it in the cloud, if… especially if it’s going to be stored in the cloud afterwards. If not, you may want to bring analysis back in, but don’t, if you bring it back into the cloud again, you’re adding costs every time you move stuff.
Generally uploading stuff to the cloud isn’t costing too much. But bringing it out of the cloud does, and it may actually be cheaper given that we deal with large amounts of data. It may actually be cheaper to spin up an an instance or a VM to do your analysis in the cloud than it would be to download it and then push it back up. It actually… running that processing in the cloud may actually be your cheaper option in a lot of those situations.
So again, it’s a consideration you’re going to have to make in your own investigations and in your own processes, but both are viable options. And I actually go back and forth with it. Sometimes I’ll want something local, some things I’ll want to analyze in the cloud and it never needs to leave the cloud because it’s going to be stored up there as well. So yeah, it does vary.
One thing to note. If you’re dealing with intrusions or malware cases — this is an obvious thing, but if the account you’re looking at is compromised, not just the instance but the risk of like, maybe there’s an access keys on the instance or something like that — if the account… there’s risk of the account being compromised, you probably want to not just isolate the instance, but you might want to actually move the data off of that account until you’re sure. Right? So make sure you have the capability to move something to a trusted account if that’s a necessary part of your your investigation. Not all cases need that, but definitely for malware intrusion type investigations that’s something you should consider as regular part of your process.
And another note about forensic containers and I’m talking about like stuff like E01s, AFF4s, images, stuff like that. We’re used to dealing these regularly, you know, you’re going to have your, I want to say physical disks, but they’re not physical disks. You’re getting physical of the partition or the… it’s really a logical of the… you’re not accessing the physical desk most of the time, but you can get grab, like I said, the EBS VM disks, and you can do an EO1 image and the EFF4 image of those, or you may be getting for… probably for the most part is logical containers. And that’s what we deal with quite a bit when you’re dealing with other sources. So these could be used to be files, right? They could be just a log, right? A bunch of our CloudTrail logs, or anything like that that could just be files or pieces of data.
You’re dealing with like LOR containers [inaudible] even a zip’s a container. It keeps our data enclosed. The key thing here is the point on containers is us as examiners need to recognize that a lot of what we’re doing in the cloud and collections, you’re pulling stuff via an API. And you need to recognize that you’re not accessing stuff at the disk level. You know, this isn’t an NTFS volume that you’re grabbing, you know, the MFT and going at it just like you traditionally would on a physical hard drive. So recognizing the separation of those things is really important to know what to expect and what’s working and what’s not. So that’s what I wanted to kind of just touch on here just a little bit.
And this applies to any collection, but especially for cloud collections, is you’re pulling those individual files, logs, whatever it is into a container. You know, you can be creating that container yourself. Your tool may be creating that container. More common ones would be grabbing S3 data or blob data from those object storage, or other services like Dropbox, box.com, Google Drive, whatever, those are just files that people have. And they get stored that way.
Each one of those are pulled via APIs. And every API is different. You know, when companies already like Dropbox, API and Boxes and Azures, and AWS has those, they have API to access that data, but they’re all built differently and they give you access to different things. They store the data differently and they access it differently. And you’re at the limitation of that API, or that the mercy of that API, of what you can do. Three main API ways you can use APIs, public APIs, private APIs, and scraping public ones.
You’ll typically see well-documented, you know, AWS, Azure, generally have a very public API that allows you to do certain things with their SDKs or CLI and allow you to pull that data. And it’s well-documented. But there’s also other utilities and tools that have private APIs. That is a little harder to, to uncover unless you’re a partner with them and they provide you with that, they’re not going to detail every single piece to it. So it’s kind of a little bit of reverse engineering to try and figure out how those private APIs work. And it’s not a one-to-one because you don’t work for that company. Right? So it’s good to recognize when you’re using public versus private APIs and what the limitations are.
And then what if the service and that doesn’t give you access at all? Well, okay. The only other option is really just loading up on a webpage and scraping that data down, which works in many situations, but it’s not ideal, right? But there’s pros and cons to each one of those. And it’s really important to recognize that this isn’t file system level access. It’s a service that lets you pull files, and you’re going to have limitations to that.
Timestamps are the big one. And that’s probably the one, what I wanted to get at here was, some allow the original timestamps when they store the data. Some don’t. Some of them blow half that away and just say, okay, well, here it is, this is when it was uploaded. You know, they don’t have Mac times and they’re not well as defined as, you know, NTFS or FAT 32 or anything like that. They’re defined how they define them. They may have a last modified time up there, but do you know if that last modified time means the same thing as it did when that, you know, when was it last modified when it was in the cloud or last modified when it was… the transferring between volumes gets well-documented, you know, everyone’s got those SANS posters of like, okay, you’ve moved files between the volumes, the creative time gets updated and everything. Well, that’s, that’s also a thing in the cloud you need to recognize.
So sometimes still allow the original timestamps, other services don’t, it varies between the services. So you’ve got to recognize when you’re pulling from different services, what those limitations are. Sometimes they’ll be blank. You made you pull it down and there’s no created time there. Okay, well, they don’t have it, right? Other times it’s the API limits it and you can’t get it. Now, they could have… if the API overwrites the time during collection, the only option sometimes is to make note of it when it was on in the cloud service. And then either note it in your notes or logs, or stomp the file, which is usually frowned upon in a lot of situations. But that’s, you know, the timestamp’s not wrong, but the API is limited in that fact that it doesn’t actually give you access to that information. There’s nothing wrong with it. It’s just how that API is designed. And that’s a limitation of your… the way you’re collecting that data.
You know, I guess you could go to Amazon or Dropbox and say, okay, I need to forensically image this hard drive, mail it to me. Then you were back to our original thing, but that’s not a viable option for most situations. So we were at the mercy of some of those APIs, right. It’s really important to recognize that and as we go through here.
So let’s look at some ways and do some examples here and talk about accessing AWS and Azure methods. You know, I’ve talked about these already, but the main ways to access both AWS and Azure data is through the console or the portal, through the web page, basically. We’re going to talk about CloudTrail and blob SAS acquisitions there, CLI, we’re going to do S3 there, the SDK; that’s just your tools. AXIOM uses the SDK for a lot of things as well. So we’re going to show AXIOM using the SDK to pull EBS and S3 data as well. There’s pros and cons to each of them. So let’s take a look.
Collecting S3. So many of these are worth it. Like I can collect S3 a million different ways, I’m picking CLI for this example, just because it’s a fun example. It requires access keys to set up. I already have those set up. So what I’m going to do is, I’m going to flip over to my right man line here. If I can find the right one, oh, that’s really ugly, but we’ll we’ll open up a new one. There we go. One of my other windows timed out.
Okay. So what we’re going to do here is, we’re going to do AWS S3 [indecipherable]. So most of the CLI for AWS is just, I’ve already got it installed. I’ve already got my access key set up for my account, so I can use AWS command. And S3 is the service we’re going to look at in LS. That’s just, if you know Linux, you’ve used LS a million times before, but it’s just going to list all the buckets that I have in my account.
Okay. That’s pretty simple. I got three buckets in there. We could do AWS, S3, LS S3, and take a look at what’s in the recce connect. Here, there’s a couple of files in there. Cool. Nothing too exciting, but let’s say we want to copy this data down. We want to collect it. Well, it’s as simple as just doing S3 copy and we list our recce connect. It does. It’s an autocollect, which I always typo it, but we’ll see. And we’ll put it to my desktop. So J McQuaid desktop, and we’re going to go recursive. Lots of options to do this. So just bear in mind that I’m doing some very simple commands here, but we run that… perfect. We just downloaded those five files. Very easy.
Now, if we go back to our slides here and we go back to our slides, that’s pretty quick and easy to do, but we just threw those files on my desktop. Mac times, [indecipherable] changed all of that stuff. There’s no [indecipherable] to it. So you’ve got to manage your own setup that way, but if you’re just collecting [indecipherable] files and you don’t care about that type of thing, then that’s fine. The contents of the files are saying the hashes is still matching and that’s the metadata is the only thing that’s changed there. But again, quick, easy, very great way to do it. But there are other ways to do it, which we’ll show in a few seconds. But again, that’s another great way to collect data is the CLI.
Another example, EBS volumes, let’s, let’s use AXIOM for that. And what we’re going to do is… what it’s going to do is it’s going to create a snapshot of the EBS volume and then copy it to S3. So let’s open up AXIOM. I’ve got AXIOM open up here. We’re going to go to cloud. We’re going to go to AWS, and it’s going to ask for my region, access key and secret key. I hope I still have that open somewhere. Yeah, I do, good. Never share these with people. You guys are seeing it right now, but after this is done, I am going to go change that because this would give you access to my account, but that’s okay. There’s enough time in between that you will not see it.
I’m going to S3. Well, that looks like same thing we just looked at. We can go under recce connect here and just grab those files if we wanted to… cool. It’s this exact same thing we just did for us three. What about EC2? We can go into the EC2 incidents here. I’m gonna go edit. I’ll just go view instances. I should have one in there. Yeah, there’s just one that I set up just as a test, a [indecipherable] instance. It goes into the next stage phase.
Here we put a description. We can put the format, VHD, VM decay, pick a bucket where you want to save it to, well, hopefully you’ve created a bucket beforehand. You don’t want to probably save it to another evidence bucket, but you can save it to that bucket. And then just remember there are costs of moving this data and storing this data so we can remove it automatically for you. I sometimes uncheck that and and remove it later myself, just in case there was something wrong with the acquisition. I don’t like removing it and doing the extra step twice again. But again, totally up to you, if on your process, I’m not actually going to do it for this case just for time’s sake, you hit next. It goes, it does the snapshot, like I said, and copies that data over. So lots of good things there.
Note, again, encryption, if you’re collecting that data encrypted, you may want to make sure you’re capturing the keys, especially if it’s customer managed. You want to capture those keys. Otherwise you’ll never be able to decrypt it as well. So note about encryption again, the nice thing here is you’re putting stuff into a container it’s maintaining that forensic process. But there are some limitations to collecting via the SDK, and that’s not just an AXIOM limitation. The SDK has its own limitations as well. You know, one terabyte max, there’s some timeout capabilities there that that you need to be aware of. And that can be really important to note.
So what about Azure blob storage? Well, let’s dive into the portal and take a look at this. We’re going to generate an SAS token and URL to get temporary access to something. So let me go to my thing here, maybe this one. Yeah, there’s the console here, but let’s go over to Azure and I’ve got a storage account here with cases and evidence. If I go into evidence, there’s one picture.
So if I click on that picture here’s the URL to access it. If I click on… copy that and paste that into a new tab, not found. I can’t access it, because it’s a private storage. Okay. Well, I want to share this with someone. How do I do that? Generate SAS. This is going to be shared access signature. Generate it. You can set up your keys anywhere you want. You can set up permissions, read, write, whatever, you can set up a time limit. This limit is going to go on for, you know, just a little bit today, a couple of hours. I can even allow my own IP address only, or whoever’s IP address. I’m not going to set that, but you can certainly limit it to IP address. And the default is HTTPS. Generate that token, copy the URL. Let’s do the exact same thing we just did. Boom, there’s the picture. Right?
So that’s a very easy, quick way to share data for different accounts. And it can be really helpful to share with people external to your organization, that can help. It does take more effort to set up. You can automate it, you can script it. You can do a lot of that stuff through CLI and scripts, but it does require a little bit more effort than some of the other methods.
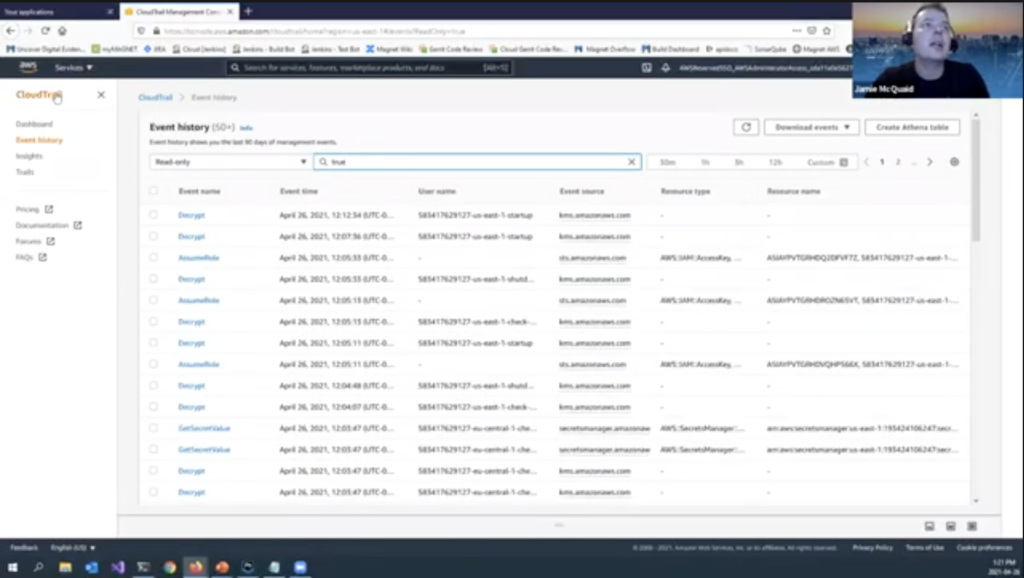
Okay. What about CloudTrail? Accessing CloudTrail, collecting CloudTrail logs. We said this is for auditing purposes, last 90 days are within CloudTrail, the older stuff’s in S3. Let’s take a look at that. We’ll open up my other window. Let’s see. Here we go. So we’re in CloudTrail. I went to event history here and I’ve got some… this is again, the last 90 days.
I’m in my account here. Let’s go with name, and let’s say terminate instance. So I want to track… oh, that’s going slow… terminate instance. There we go. There’s every time that I’ve terminated an instance in the last month or so. I’ve terminated a few instances there, and you can get details about that instance and there’s the event record and that’s what it looks like, you know, whether we’re copying it out and and storing it in S3 or within CloudTrail, you can download those that event history right here as a CSV or JSON. So again, copying that local or keeping it in the cloud your analysis, either way works quite well.
So that was a really quick way to kind of go through some of the… let me flip back to the slides here is a really quick way of the pros and cons. It logs everything! CloudTrail can log everything for anything. So when you’re looking at it, it can get very noisy there’s pros and cons to that. And one thing, like I said before, CloudTrail’s good for API access, but it doesn’t include logins into your instances or network traffic. Those don’t count. You need to look at those elsewhere. So really important to remember that as we go through these things and and track that.
Next up, troubleshooting issues. This is kind of a joke, but it’s actually real. Uou know, just kidding, like there’s many ways you could have issues when you’re collecting this data or using a storage: timeouts, rate limits, service limits, stuff like that coming. I guarantee you 90% of the time though, it’s probably going to be around permissions. The challenge of troubleshooting is always going to be kind of a double-edged sword.
Seriously, most of the time it’s going to be permissions. If you think of all those times, we talked about, you know, securing your data and your evidence in the cloud and picture that basically working against you in every possible manner. That’s really where you’re dealing with it. You know, it’s great if you’re trying to secure your data, it’s awful if you’re trying to collect your data. So remember that when you get really frustrated, because you’re using some of these controls, whether you’re using it to secure your own data or when you’re collecting evidence for a case, that can be really important to recognize that always check your permissions because there’s different degrees of it. Like I said, in the access controls for AWS, IAM access policies, the bucket policies, the bucket ACL’s, all those come into… there’s organizational controls, service controls, lots of those are permission layer upon layer.
And usually the default is just to deny it, unless you specifically say allow, it’s going to deny you access. And I personally, for me, I’ll go through the troubleshooting steps to know that my stuff is going to be denied by default, even if I miss something because that’s going to be my main focus with it.
So that’s everything I’ve got. Hopefully this was helpful for folks and we can go through, feel free to reach out to me. You can ask some questions here on the Discord. Email me afterwards, Jamie.McQuaid@magnetforensics or my Twitter handle is @reccetech. Feel free to reach out, love to chat about cloud forensics. Anything cloud or forensics, not just cloud forensics, but I’m happy to chat about any of this or any questions you guys might have. So thanks for watching and have a good rest of your day. Bye bye.





