Good morning. Good afternoon. And good evening, everyone. It’s a pleasure to be here. My name is Marco Simioni. I am a PhD researcher at the Digital Forensic Investigation Research Laboratory, University College Dublin in Ireland, as well as research engineer for IBM Research Europe in Ireland.
And today I’m presenting you our work with the title “Monitoring an Anonymity Network: Toward The Deanonymization of Hidden Services.” The presentation structure is as follows: we will start with some context that will allow us to discuss the problem statement. I will introduce then our proposed methodology to address the problem. I will then introduce the results of our simulated experiments conducted on the I2P anonymity network, and then we will discuss the conclusions.
Let’s start with some context. So first of all, let’s introduce what anonymity is. We will use this popular definition where anonymity of a subject means that this subject is not identifiable within a broader set of subjects – the anonymity set. And anonymity networks, also referred to as privacy-enhancing technologies, or sometimes as darknets, are overlay networks that provide anonymity.
So a user of the anonymity network from an external observer is not identifiable within the broader set of all the users of the anonymity network, as well as for example, a service, for example, a website, delivered within the anonymity network from an external observer, the website is not identifiable within the broader set of all the websites delivered within the anonymity network. Usages of the anonymity networks include private individuals who want to protect their own privacies, businesses to keep data confidential, journalists to protect anonymous sources and activists to report abuses and so on. And also criminal usages such as commerce, largely around narcotics and illegal financial services is very popular.
There is a presence of victim based crimes, such as child exploitation and illicit or illegal pornography, and also anonymity networks have been used by malware developers as the communication channel between the infected machines and the Command and Control server.

And in all these cases an investigator who wants to locate an offender, for example an investigator who wants to locate the organization behind the Command and Control server or an investigator who wants to locate the responsible for delivering the e-commerce delivering illegal financial services. For the investigator locating these servers look, first off locating the IP address of those services is paramount information.
But let’s introduce the concept of overlay network, first. Overlay, in this chart we have at the very bottom, a gray pane that represents an underlay network, for example, the public internet, where a number of hosts are interconnected and communicate with each other. Among these hosts we can have a number of hosts running a special software.
These hosts form, then an overlay network. These hosts can communicate between them, the interconnections and the visual links between these hosts can be completely independent from the underlying links. And they form a complete independent overlay network that can serve different purposes. It can for example provide Voice-Over-IP communication, or it can provide, for example, anonymity in the case of anonymity networks.
If we compare the users, if we compare a typical scenario in the Clearnet where we have a user who wants to access a website, let’s say www.google.com. The user enters this address in the address bar of the browser. And the first thing that happens is that the machine has to translate this address into an IP address so that the browser knows where this service is being delivered and how to connect to the service in order to access it.
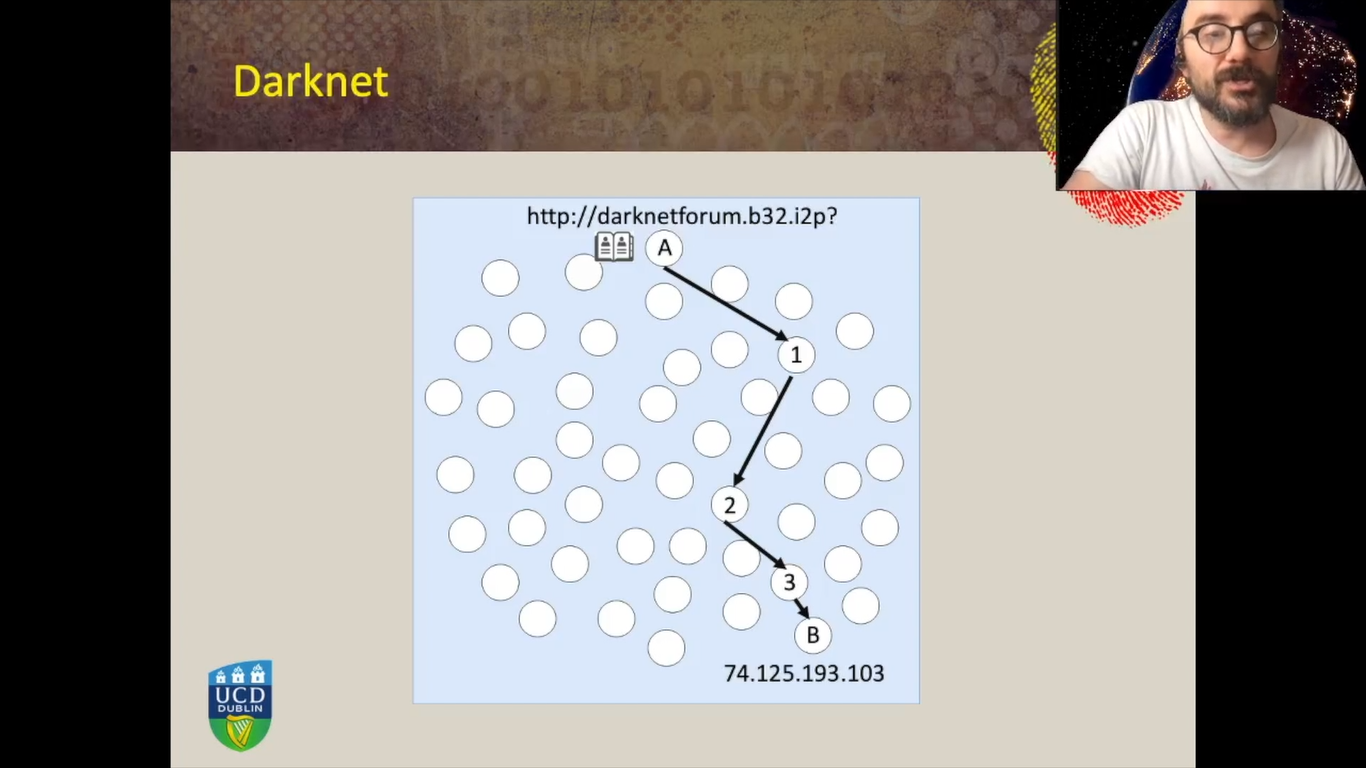
On the anonymity networks, however, consider the similar scenario where we have a user who wants to access a service delivered within the anonymity network, such as a darknet forum, for example. They enter the address in the address bar of the browser and then the special software needs to find a way to reach this service. Typically, there are orchestration nodes in this network and there are what can look something similar to an address book of nodes connected and available on the anonymity network. Most of these anonymity networks leverage routine mechanisms such as the onion routing mechanism whereby the machine in order to access a service first has to establish a path, by choosing for example, in three routers at random, among all the available routers in the network, form a path with the special requirements of encryption and routing, and only then this path can reach the ultimate destination.
However, in this case the machine A does not need to know the IP address of the machine B. So machine B, the IP address of the machine B, is kept hidden from machine A. There are several other features whereby machine B also does not know the IP address of machine A thanks to the special encryption router mechanism, as well as router one only knows only sees incoming connections from a router number, from the machine A. It knows that this connection must be forwarded to router number two, but it doesn’t know what the ultimate destination is. Router number two only knows and sees incoming connection from router one, knows that it has to be forwarded to router three, but it doesn’t know that the connection is originated by router machine A and it doesn’t know that the ultimate destination is B.
So how can an investigator locate the services of the server delivering this darknet for them? So how can that investigator discover the IP address of a service, website, for example, delivered within an anonymity network. For example, I2P or TOR.
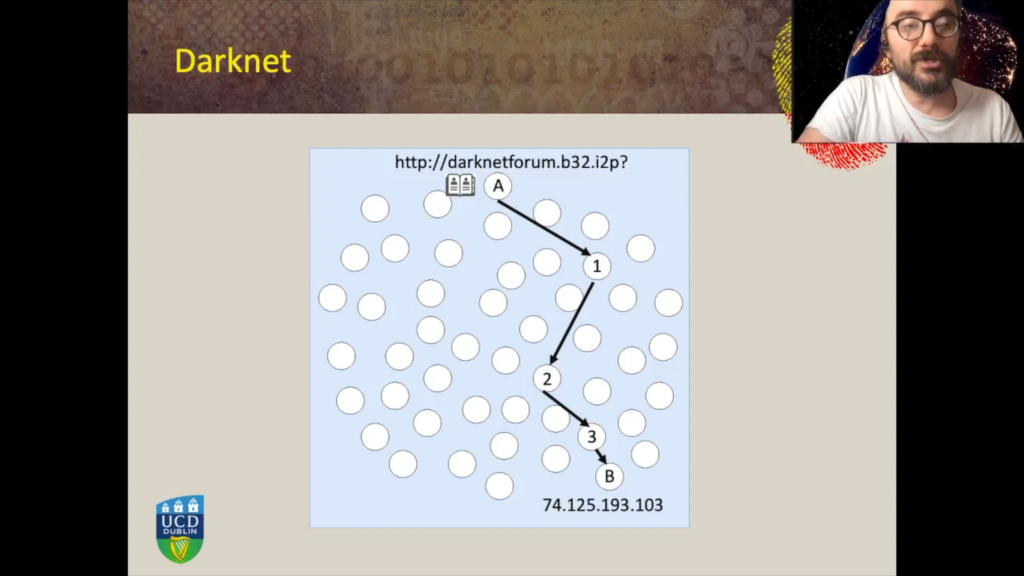
So when we started this research we noticed on a very popular website and this website was a directory of hidden darknet markets. And we took these screenshots and we noticed two interesting elements. The first is that darknet markets in this case and darknet websites are highlighted either in green or in red. And according to the website, the color indicates if the website was available at the time of the screenshots, or not.
Each of these darknet websites also has a second interesting element, which is the number that you see close to the name of the website. So if we look at the market there is a 97.31 percentage shown on this picture and according to the deep dark web website, this represents the average availability of these darknet markets. So they did not disclose how this was measured but presumably they were pinging and trying to probe the website at regular intervals.
So we came up with the idea, so what if we can measure the fingerprint of the availability of a website? So what if we can measure, for example, at regular intervals if a website delivering under investigation is available or not. And we represent this as a vector where at the intervals K, either the vector, it’s a binary vector where the availability can be either zero or one. One if the website T is available at the interval, K; zero, if it is not.
What if we can also fingerprint the availability of all the nodes connected to the anonymity network? So all the nodes connected to the overlay network. So for each of the known nodes of the network, we generate a vector, again, where at intervals, K let’s say, for example, every minute we measure and we keep track if the node was present and available on the anonymity network or not. So we result with one vector that represents the availability of our target website under investigation, and then a number of vectors that represent availability of nodes and availability of IP addresses on the overlay network.
And then we look for fingerprint matches. So we try to find, okay, which one of the nodes has an availability fingerprint that closely resembles the availability fingerprint of the website under investigation. We’ve chosen a very simple metric, the Hamming distance. And so we calculated the Hamming distance between the availability of vector T and the router one, the availability of vector T and router two, T and router three and so on and so forth.
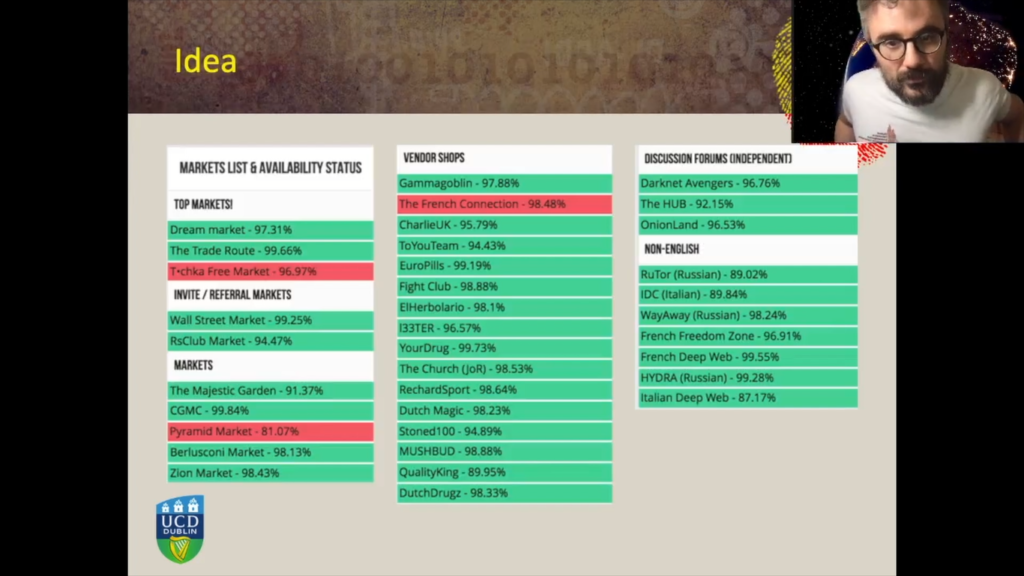
And we then deployed a monitoring infrastructure on the I2P network. So we deployed a number of nodes on the I2P network, and these nodes were collaborating with the network and each day they were interacting with a number of other nodes. So they had knowledge of a number of other nodes connected to the network. And this monitoring infrastructure was taking a snapshot every minute of which nodes were available on the network and which were not. At the same time we deployed a target node. So a node where we were hosting a hidden service, a hidden service that we controlled.
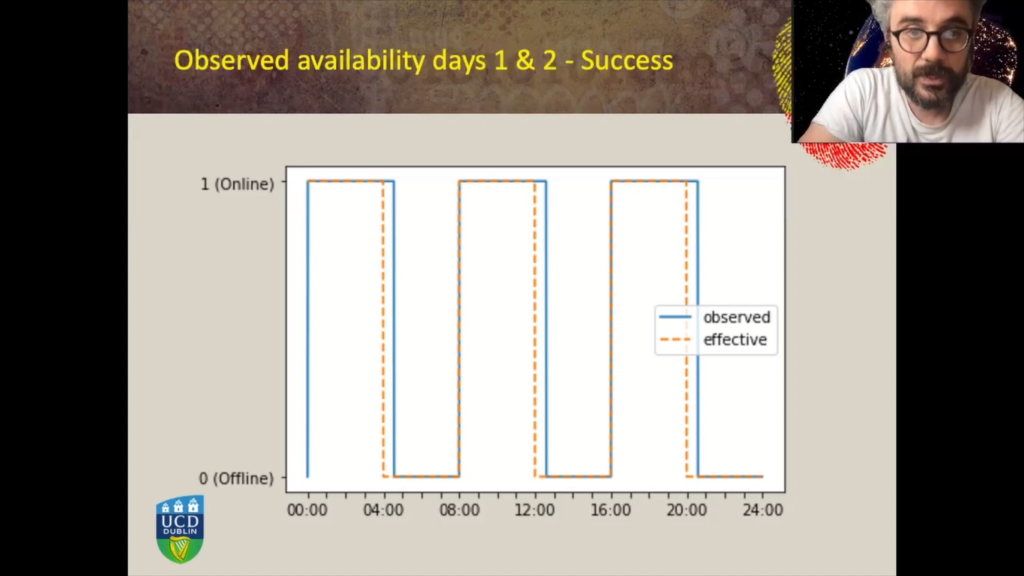
And we injected a very specific availability pattern to this target node. In this chart, we represented a three day, sorry, six days of experiments. For the first two days the availability pattern shown on the picture shows that we had four hours of availability followed by four hours of unavailability of the website and so on and so forth. So basically, you know, in other words every four hours we were turning on and off, on or off the website, for the days number one and two.
For days number three and four, the availability pattern looks something like seven hours of availability, one hour of unavailability and so on. For days five and six we had 11 hours and a half of availability and 30 minutes of unavailability. So we then used our monitoring infrastructure to monitor all the available nodes, we generated the vectors that we introduced before, we calculated the Hamming distance between our target node availability and all the nodes present on the network.
And for days number one and two, where we had something like 40,000 observations, so 40,000 routers, nodes, connected to the network, where we scored, where we calculated the Hamming distance between our target availability pattern and all these 40,000, and then we sorted the availability vectors by Hamming distance, and we ranked them, the IP address of our target node ranked first at the very top of the list out of 40,000.
So these results were very promising. And this is how the availability, the observed availability looks like when compared to the effective availability. So they’re very similar. We can notice a small delay in the detection of the on/off transitions, and this is due to internals of I2P. And there is a 30 minutes delay. When a node goes offline before it gets removed from the distributed database, there is a timeout that has to elapse. So there’s this 30 minutes timeout.
And we repeated the experiments and for days three and four with the given availability pattern of seven hours on, one hour off, seven hours on, one hour off. We repeated the experiment, we had our measurements’ infrastructure in place, we generated about 43,000 availability vectors, all for the nodes available on the network. Again, we measured the Hamming distance between all these vectors and the availability pattern that we were looking for.
And this time the IP address that we knew was hosting the hidden service scored 58 together with 3,600 nodes. So it was not as good as we expected. And when we looked at the observed availability pattern compared to the effective availability pattern we notice again, the 30 minutes delay in the detection of on/off transitions. And this time, the impact of this delay is very consistent. So we thought, okay, so what if we managed to filter and cancel the noise introduced by this 30 minutes timeout?
And we applied a filter so that we were able to cancel this noise. We repeated the measurements between, we recalculated the Hamming distance between the filtered, between the target availability fingerprint and the 43,000 filtered availability fingerprints. And this time our IP address when we sorted the availability fingerprint by Hamming distance, the availability pattern of the target node scored first. So it ranked first at the very top of our observations.
OK. This is the observed availability after we applied the filters, so after we canceled the noise introduced by the 30 minutes timeout.
For days five and six, however, we observed that where we had an availability, injected availability pattern of 11 and a half hours and 30 minutes of availability and 30 minutes of unavailability, when we scored them, when we ranked them, the IP address of the hidden service we knew that was hosting the service under investigation ranked 50, along with other 3000 routers. So it was not very promising and when we looked at the observed availability pattern, well, this time the observed availability shows a hundred percent of availability. So there were no transitions detected at all due to the internal timeout that I described before. And there was no way to apply any filtering to try and cancel the noise introduced by these timeouts.
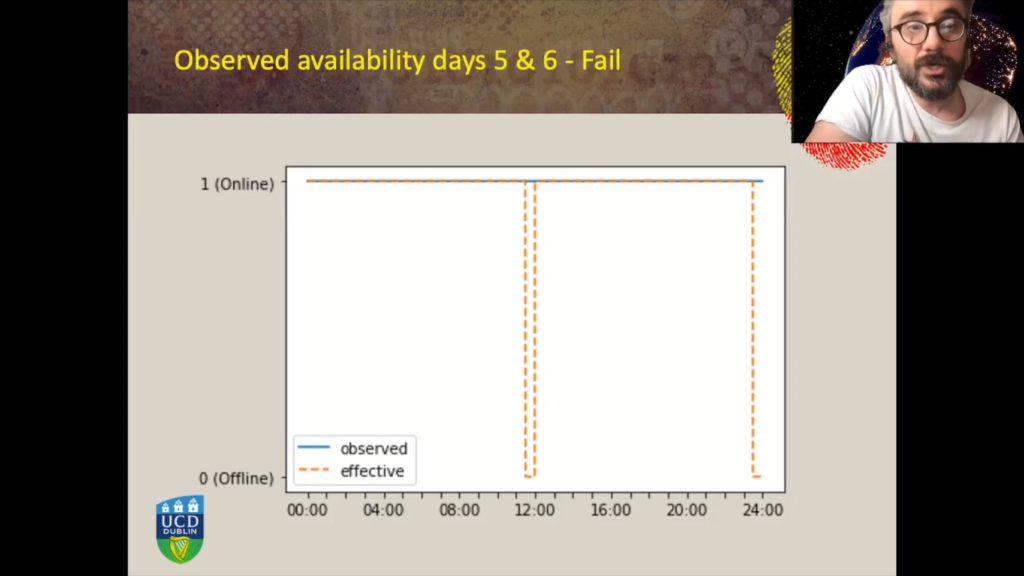
And then here one of the possible ways to overcome this is to modify the internals of the I2P router of our monitoring nodes. So we modified the source code and reduced these 30 minutes timeouts. This, however, was outside of the scope of our experiments, where we wanted, for this specific research we wanted to keep the I2P routers as genuine as possible, and we did not want to modify the behavior of these routers in order to be as stealth as possible with our methodology.
So in conclusion, our research demonstrates that if under the assumption that a website has a unique enough availability fingerprint, either because it is spontaneous – websites have maintenance windows, they suffer from outages, or it can be induced. Websites, especially in the darknet world, are often under denial of service attacks.
And there is a way to measure the availability fingerprint of all the nodes connected to an anonymity network. Some anonymity networks like I2P provide this capability as a feature of the network where you are able to discover the presence of all the other nodes so that you can build your routing path. Other networks may require external observation. So other networks such as TOR require the collaboration for example, of an internet service provider and recent research demonstrated that it is possible to detect TOR traffic at scale. Researchers designed Dante, a framework for monitoring darknet traffic at scale.
And such a method, for example, could be used to identify which IP addresses in a given ISP domain are indeed collaborating with and connected to an anonymity network. So under these two assumptions, we demonstrated that it is definitely possible to match the fingerprints that we are looking for and ultimately to discover the IP address of a hidden service being delivered within an anonymity network, or at least discover an IP address that had a high, very high probability of being involved in the infrastructure that is delivering the service within the anonymity network.
So I thank you for your time and please reach out for questions and collaborations. Thank you.





