
Holli Hagene: Hi, everyone. Thank you for joining us today for our webinar, FTK features that might surprise you. My name is Holli Hagene and I’m a marketing manager at AccessData. Before I hand things over to our presenters. I just wanted to mention that today’s webinar is being recorded. We will post the recording of the webinar on our social channels in the next few days, or you can visit our webinar page on accessdata.com to view both on demand and upcoming webinars.
Second, we encourage your questions, please type them in the Q&A box and we’ll answer them throughout the webinar. And at the end, if we have questions.
Now I’d like to turn it over to Michael Lappin, events technical engineering at AccessData.

Michael Lappin: Hey everybody, hopefully you can hear me. Good morning, good afternoon, good evening. Thanks for joining us, everybody, really glad you’re here. This is going to be good. I’ve got a really good presenter for us today, with some really good in-depth technical material that he is going to deliver to us. A lot of this, he actually learned in the field recently. He’s got some great stories. So we’ll see if we can’t get him to tell some of his stories and reflections on what he’s learned.
I’ll just go over the agenda real quick, and then we’ll get it over into the hands of Tim Stommel. I’ll introduce him. I have the privilege of doing that, which is great.
So let’s just go ahead and get started here. I promised him I’d get off stage by five minutes in, so that he can take over. We are going to fill the whole hour today with technical goodness, so put on your seat belts and get ready.

So like I said, Tim’s got some new things that he’s found; he’s been investigating for like 30 years, but he’s got some things that have caught his attention. He thought maybe it’d be a good idea to show our community a little bit about this.
He’s really digging deep today into regular expressions and how to use them, how to leverage and how to build them, so he’ll take you through how to do that. And then he also wants to compare and contrast when we use a live search, when we actually wait and leverage an index to run searches, and then when a filter file system search is actually sufficient. All of those have pros and cons. So he’s going to take you through that.
He’s going to look at some of the latest volatile data capabilities with the Forensic Toolkit. And then he will talk about some real-life use cases and investigations that he’s done that will really bring this around to us, make it real, because this is what he’s actually doing.
Now if you don’t know Tim, he has been doing this for a long time and he actually does investigations actively for us at AccessData today. So we actually offer those services, they’re very powerful. So he actually walks in with FTK under his arm and gets started. Obviously, his goal is always to figure out how to go as fast as he can to find the evidence as quickly as he can. So with that… so Tim is been everything from local law enforcement in Wisconsin and in Florida, to traveling the globe as a DEA special agent. He has spent plenty of time in some third world countries doing some things for our DEA. He’s a master jedi in forensic investigation. So I’m sure we’re all going to learn some tips and tricks today.

And again, he’s ready to do these investigations for you guys, if you need help, and he can definitely augment that and/or show you the way. So if you need his help, please do contact us. He’s going to put his contact information up at the end so you’ll be able to get a hold of him.
So just some of the things he’s going to get through: really cool regular expression, how to build them, how to test them, and then how to leverage them. He’s got some good ones today. A couple of my favorites: Colombian phone number landlines and cell numbers. Yes, he’s spent plenty of time in Bogota.
And then another one he’s going to get into is Visa credit card numbers in Canada. Slightly different than the US, kind of similar, but he’ll get into how we built that out and then he’ll share these… he can actually share these rejections with you, so you can use them.

Okay. With that, I’m going to hand it over to Tim. Tim, you want to jump in, introduce yourself and get started?
Tim Stommel: I certainly do. Thank you, Mike, for that introduction. Let me get my screen share up here real quick. All . Welcome, everybody. Thank you for attending today. Hopefully I can show you something useful here again, Mike. Thank you for that introduction. And yes, I’ve been with AccessData for about two years now. And I spent about a year in training, teaching pretty much our products and use of our products throughout the world, a lot overseas, online, pretty much had people from everywhere.
What I’d like to do today, and I hope you glean something out of this webinar is, you know, how can we use the power of these expressions searches in FTK and Enterprise. And when I talk about Enterprise, , it’s really FTK with a couple features you’re going to see.
And what Enterprise really does it allows us to deploy remote agents on devices in and view those devices remotely and collect from them. And it also gives us the capability of looking at volatile memory and using Volatility to look at those services running and things.

So what we’re going to be looking at… and one of the main things you’ll probably get out of today’s presentation is using live search and index search. They each have their positives and negatives, and I’m going to show you the limitations on each and really how you can develop these expressions, and once you develop them, how you can test them, because you definitely want to validate them. If you’re doing just a simple search, maybe not. But if you’re developing any kind of lengthy expression, you definitely want to validate it. And we run into this all the time.
And I’m being hit up by training in the last couple weeks with this a lot, we’ll get zero results. You don’t want to get zero results when you really have information sitting on that you really needed. So you definitely want to validate these things.
Being in DA, I work a lot of criminal cases. So how you find a specific artifact in your criminal case. How can you use combinations of keywords, operators, you know, TT search operators and then expressions to really find a specific item you’re looking for?
Since I’ve been with AccessData and actually, I just started a case yesterday. I’m looking at five servers with about 13 VM images. A lot of these PII cases you’re dealing with massive data sets. How do you drill down in those data sets and find the real PII information that may have been disclosed? I’m getting a lot of these investigations lately.
One I just had recently was a major financial company sent me 50 gigabytes of PST files, and again they sent me 125 keywords, and some of these keywords were really good expressions actually written all pretty lengthy keywords with operators and I had to add some expressions to the end to really narrow in what they were looking for.
But the problem was what they had was, they also sent me some very generic terms like 1040, T1, T2, 1099, 1020. And what resulted with those very vague terms was index looking for 1040 — we know it’s a tax document — but index went out and was grabbing 1040 out of meta data. It was grabbing 1040 everywhere could find it on the disk. So out of about a million email artifacts that came up, I had to return them unfortunately 43,000 items to go through, because it didn’t use limiters on their search terms and things. It really could have narrowed down.
So again, this ended up costing them, you know, a lot of extra money and time. We had to move them into a collaboration environment with our new Quin-C product. And they had to assign seven full time examiners to go in and and review this information. And again, just because they were using such terms. And that’s what we really want to avoid. So that’s where these expressions come into play.
Let’s look at FRK live search for all . And really, we’re going to be looking at three different areas of searching: live search in FTK; one of our tabs, the index search. And then in our Enterprise we’re going to be looking at the filtered file system search within the live search on a remote agent.
Starting with a live search, if you go into the tab — and we’re going to look at this in a minute — you’re going to have text, which is basically your keywords; patterns, which is what we’re going to be looking at, which is our REGEX patterns; and then hexadecimal.
REGEX patterns. I believe we’re using the ECMA script, I’d have to double check. But I’m 99% sure it’s ECMA script on the REGEX, and we’re going to be developing a couple of those.

One of the advantages of using the the REGEX is it recognizes all the spaces and characters. We don’t have to worry about what we’re indexing. Where when we go into the index search, we’ve really got to be cognizant of what characters are indexed, and it comes up all the time.
I just dealt with it this week, I had training reach out to me. They were trying to do just a simple pattern on money: 1 million, 2,000,00 3 million with a dollar sign. I spent half a day trying to develop a pattern for them. And I kept getting negative hits on index search and I kept seeing that it was hitting on you know 000.00 and not beyond that. And as I looked, I finally realized that I never indexed the comma. So the index was treating that as a space. And again, it wasn’t working because I didn’t index the right characters. But again, in live search, we don’t have to worry about that.
I’ll show you how you can use filters to limit what you’re searching and that’s really important with a live search, because a live search is going to go through the disk, bit by bit. So it’s going to look at the data, bit by bit. And again, we really want to limit it. If we’ve got two terabytes, we don’t have to every search go through and wait an hour for it to search two terabytes.
So again, we can use those filters and FTK has incredible filter capabilities and we’ll look at some of those.
Again, FTK live search is going to go through, bit by bit, our items are going to be actually returned in the hexadecimal view. We’ll see that one of the biggest issues with live search — and this is probably why you’re going to be using index search — is it will not look at compressed items, and we’re going to see that. So you’re not going to see data sitting inside of a docx, actually not going to be seeing data that’s in a PDF, in a SQL database, in a web cache, in a zip file, you’re not going to see any of that using live search because it is compressed, it’s not going to see it at the bit by bit level. And again, it’s very time consuming.
Operators. Again, you can go online, look up REGEX cheat sheets. Look at all the different operators you want. You don’t have to be a computer programmer to write these, really. You’re going to see we use five or six different characters or operators and syntax to write these things. It’s more the logic involved and playing with the logic to get the results you’re looking for.
All these are going to be the basic ones are going to look at. Grouping characters, you can refer to groups as you write them. Square brackets, ABC, any of the characters in square brackets are going to be… will show you this in a minute. These dash, going to use a range of one to nine, A to Z. How many times you want to repeat something. So again, n, so three times. So a digit three times. And comma is going to be three times or more. So basically to infinity, or you can set a range. So three to four, three to five times, we want the digit seen.

Word boundaries, we’ll look at word boundaries. So if you want to see just ABC and you don’t want to see ABC within A, B, C, D, E, F, G, we’re just going to get ABC and we’ll look at that. And there’s a difference. The way that live search and index search deal with words. In index, if I run the word Chris, I’m only going to get Chris if I did that live search, if I run a keyword on the characters, Chris. I’m going to get Christmas, Christopher. So that’s why really in a live search, you’ve got to use word boundaries if you don’t want all those other digits or numbers on both sides of your work.
Case sensitivity, we’ll look at that. Backslash D is going to be a digit, W for a word character. A to Z, zero to nine. Again, bear with me. If you know REGEX, you know all this. We’re going to go into how you can implement these and really use them within FTK.
Escape special character backslash. So again, a period is a special character. If you wanted to actually look for a period, you’d have to use a backslash.
And again, we’re going to look at all these when we get into it. Or operator, or and the question mark. We’re going to use quite a bit… zero or more, by using the question mark. It’s really going to say you know this this item either can exist, or does not have to exist in our expression.
So let’s go look in the expression and we can really see how these operators are used. This was actually a case I worked a few years back.
We had an informant. He gave us some information on a Colombian in Miami. This Colombian in Miami was in contact with a source of supply over in Colombia. Our informant gave us enough information, we were able to get a search warrant and from his house to seize two computers and three cell phones. We had to examine the information from the informant.
We knew that this guy was speaking with a subject and Colombia, by the name of Miguel. And they were going to be sending a vessel by the name of the Macel Mexico with a lot of cocaine. We did not have a phone number for him, and we were hoping… an informant said you guys were communicating quite a bit by text by email, and we’re hoping we can maybe identify this this number off of it.
Now, before I go into developing the search, just a little war story here. We actually did get the information we put up Columbia on this guy. Cell phone intercepted a cell phone, they spun us back up on cell phones here and as a result of all this, all these interceptions, about a week before Christmas. We were fortunate enough that we got the coordinates of the vessel located, where it was at. And the Navy deployed a quarter out of San Diego to intercept into the Galapagos Islands and we ended up seeing 9300 kilograms of cocaine.

Again, really, really good information off this information. Again, there’s our trophy photo. I don’t have the cop stache anymore, fortunately, but… Again, this was done in Mexico as one of two truckloads of 9000 kilos of cocaine we got off this case.
So let’s go look at now, how we can actually develop this expression. So let me jump over here into…
Michael Lappin: Tim?
Tim Stommel: Yep, go ahead.
Michael Lappin: We’ve got several people voting for you to grow back the cop stache.
And then, on the Q&A, Andy’s asking, have we ever loaded some of this data into Splunk and played with that a little bit around left pattern matching? I don’t think we have, I usually look at a workflow that goes the other way where we’re picking up on Splunk alerts and then adjusting data. Any comments on Splunk and rough pattern matching? Have you done that?
Tim Stommel: I have not at all. I’ve played with Splunk, but I have not, I have not. So, and I imagine you know the one thing with these patterns is, you could implement these in any product, so any product out there. I’m showing you how to use them in FTK. But again, I’m sure you could leverage these in Splunk also.
One of the things I like to use for developing these expression patterns — and there’s a lot of monitors — I use this one, it’s regex101.com. So again, I’ll get my tests that are for the Columbia number. I’m going to pull up on the numbers here.
Again, develop your data. So again, I knew I was looking for Columbia number, and numbers in Columbia: international, 4011; Columbia starts with 574 country code and then the 300 is going to be a landline, and if it’s a one digit, it’s going to be a landline. So again, we knew we were going to be looking for Columbia numbers. So I want to match any of these options, it may be in country and may not have the five, seven, it may be from the US. So again, just get your data set in there.
One nice thing about this regular expression. We’re going to be using a CMS prep pretty much the same as a PC PHP script. As you type your expression, you’re going to see explanations of your terms you’re typing over here. And if you do group. And you’re going to see your group matches here. And if you don’t know a certain operator, you can do good on here and look at qualifiers. So you can actually look up the qualifiers and things.
And again, it’s going to be very complicated, you’re going to see we’re only going to use a few expressions. So we’re going to look for 011. And again, it’s going to show you, boom, 011, and we’re going to create a group with 011, so 011 is going to be followed by a dash. A dash or space, or nothing at all.
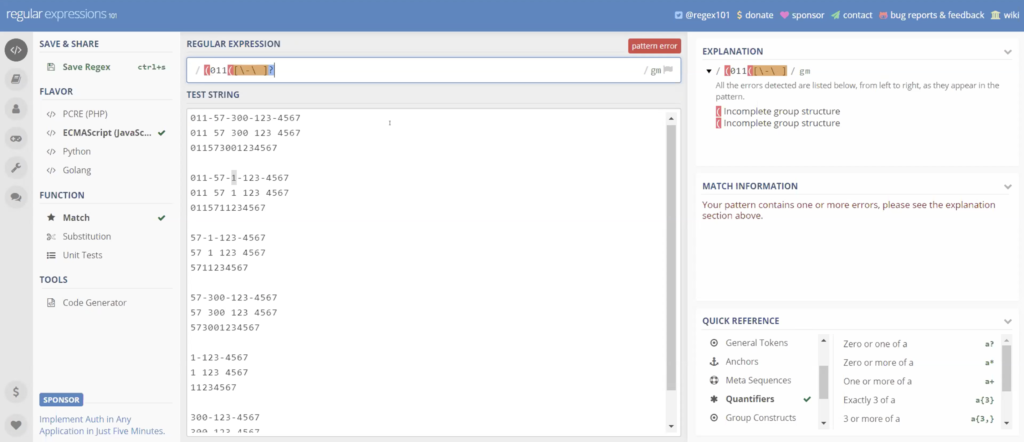
So we’re going to put a bracket because we want to include any of those. I’m going to use a backslash, backspace. So we got a dash or space. And a question mark to say, you know what, it doesn’t have to exist, which is our third pattern, no space, no dash. So again, basically we’re saying we got 011 followed by a hyphen, a space, or neither of them.
And I’m going to put another bracket. We’ve got a group here. Now, we actually got two groups, we’ve got the group of our dash in our space. The group of our 011. And again, the 011 may or may not exist. I’m going to put another question mark and again it shows us any of these patterns, depending on what I do next may follow.
But so far, it is matching the 011 with the space the dash or nothing. And again, just keep going. And you can see the results of your pattern as you write it. Next we want to five, seven. Five, seven, and again we want to follow that five seven by adash a space or may not exist. And again, we can see as I’m going here, and I’ll get the five seven with a dash 257 with space.
Alright, 011 doesn’t exist on these. If we look over here, we can actually look at each of the qualifiers or operators I put in. And again, over here we can see my groups as I’m creating groups.
This next one we got either 300 or a one. So we’re actually going to use it in here. So again, I’m going to start a new group. I’m going to start a second group within it. I’m going to say to be a digit of a three just straight out of three. I’m going to use a backslash digit. So instead of a three, you can use a backslash D, which means any digit 1290 to nine.
And I’m going to use a squiggly bracket and I’m going to say I want there to be two digits. What this is saying is, give me a digit three and give me two additional digits. So 300301. I’m going to put in an order. And I’m going to redo my second group, was just a backslash D or any single digit. And as I put my final group in the end, if you click on the parentheses, you can see where your groups are.
So again, I’ve got three digits, followed by two additional digits or a single digit, and again you can see it is matching my pattern for all these numbers. Now, that has to exist. I’m not going to use a question mark. We have to have a 300, or the one, or whatever those numbers are. My hyphen, my space, may or may not exist.
Next, we’re going to have three digits. Pretty simple. So again, I’m going to start a new group. Three digits. And keep going along with it, see everything’s highlighted and matching. And again, we’re going to do our space may or may not… just… and we’re going to finish up with four digits. Digit four times. Again, it could be any digit.
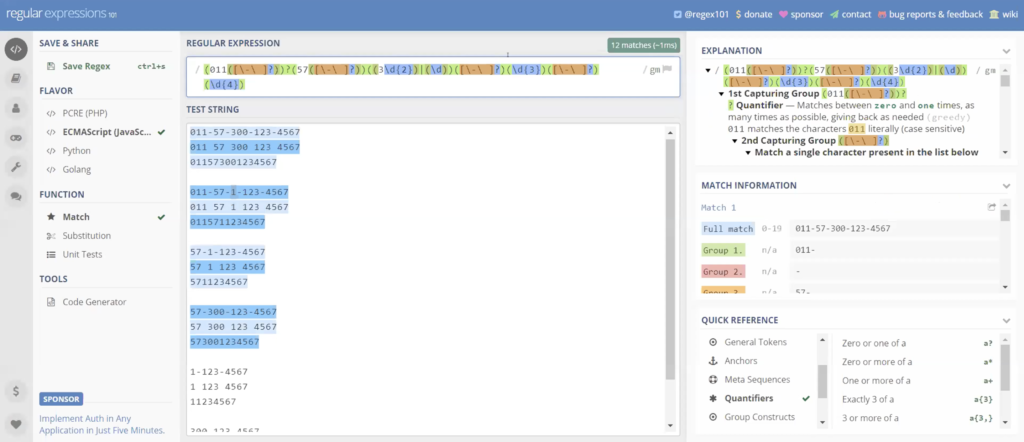
And I’m going to set a word boundary. So we’re going to meet as a backslash B at the beginning of my phrase. And a backslash the agenda, my phrase. And what that does is, if this falls within a pattern of other digits, it’s not going to select it. We’re only looking for that specific pattern.
So again, setting word boundaries, saying, I only want this pattern and nothing else. And let me see. Looks like I missed something in here, 573 digits or two digits. Well, you know what I forgot. Here was this, five seven does not have to exist. That’s why the last one. There we go. I forgot to say the five seven doesn’t have to exist. So these were not highlighted.
So again this is our pattern. This is our pattern we created for the phone numbers.
Michael Lappin: Hey, Tim?
Tim Stommel: Yep, go ahead.
Michael Lappin: Can you clarify something for us here? We got a question about the question mark. We know that in a lot of indexes that reads as as a wildcard. But as you’re building your regular expression, it may be used a little differently. Can you clarify the question mark, both here and then in FTK, how it’s recognized for us?
Tim Stommel: Yeah, we’ll be looking at that and search is handled differently, it is handled differently. In REGEX the question mark is a special operator. It says zero or more. So if you wanted a literal question mark, it’s up to a backslash looking for a question mark. But without the backslash, it is a special operator. And it’s the same zero or more of the item preceding it. And again in dtSearch, it is in dtSearch. It is a wild card and dtSearch.
And we’ll look at that when we get there. But again, now in REGEX it is a special operator. If we were looking for a question mark, we’d have to do a backslash escape it. And we’ll see that in a minute.
Michael Lappin: Thanks. Yep.
Tim Stommel: So let me go grab, not the rest of the information we’re looking for, I’m going to copy this over, put it into my data set. So we know the number matches. This is a good expression. So this is okay and I’m looking for this. We’re looking for a Columbia number near Miguel or the boat Macel, anything in our phones or emails or computers that we’re going to have this information.
So we can see already our pattern for our numbers working, it’s lit up. This, I’m not going to try and explain to you. I don’t have the time. Now, if you’re going to see when we go over to DP search. You can use it with an operator. So I want to find something within 10 words of another item.
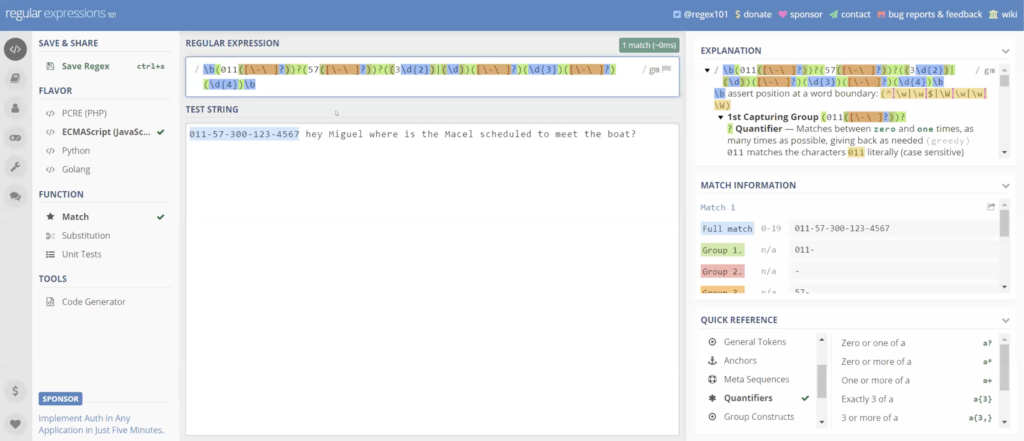
To do this in in projects is a little more complicated. I found it online. If you go read Jackson, type in the word near, you’re going to find this pattern. I’m not going to try and explain it to you. But again, this will do the same thing. It’s gonna be a backslash capital W plus parentheses, question mark colon backslash small w plus backslash capital W plus prophecy. Again, I’m not going to try and explain the logic of this to you. Now if you look online, you’ll find it away if you type in REGEX near.
And now we’re going to set the parameters. So how many words, I’m looking for within zero to 10 words of [indecipherable]. So again, I’ve got my expression for my Columbia number. I want to find it within zero to 10 words of Miguel. And actually, let me demonstrate something here… of Miguel or my cell.
And we should have a hit and we don’t. Something I want to mention: you’re not going to have to worry about this in FTK because they take care of case and sensitivity for you. But I’ve got a small m and a big M. REGEX cares about case sensitivity.
There’s things called flags there set after the expression. So you’re not going to set these forward slashes but they’re actually developed within the expression. But you’ll notice after the forward slash I’ll tell you the expression there flags, one flag is for case insensitive. So if I set that case insensitive flag, now it does not care about case sensitivity and we get our hit. This doesn’t care if it’s uppercase or lowercase. So again we can see this pattern’s, working it’s [indecipherable] our number within Miguel or sell, within 10 words.
When we look at FTK it’s already set, you don’t have to worry about it. And you can tell because they have a checkbox actually to turn it off. It says, you want to case sensitive. So let’s take this pattern, and we’re going to show you how to validate this pattern. Now let’s copy it and let’s go over to FTK.
We’re going to create a new case in FTK and I’m going to name this live search. I’m just going to standard forensic processing. Now while we get into index search, we’ll talk about more specific processing that’s important.
And one thing I do is, I’ll create Word and text documents with my test data and and so I can load a case and test case and test the validity of the information. And I’m going to load those documents right now. So again, just go out and create yourself some Word documents and text documents. So again, I’m going to load the content of a directory. That directory — that folder — just has my test documents that I created.
So again, evidence documents that I created. It’s saying, do I want to create in a content image? I don’t. I’m just going to go off the live data, you can create a custom content image before you import it.
And you guys have our past time zone and hit okay, there, it’s going to be quick. I’m only dealing with, I think, like, 10 documents. So again, it’s going to create the case.
And again, what I want to do is validate this. I want to make sure this works in a real environment.
Processing… And it’s finished. And if we click on my evidence docs, what we can see here is my document that I want to test for this presentation today. Let’s go over to our live search tab.
And again, we have in live search tab, we have text; we have pattern; and we have hex. We’re going to be looking at pattern.
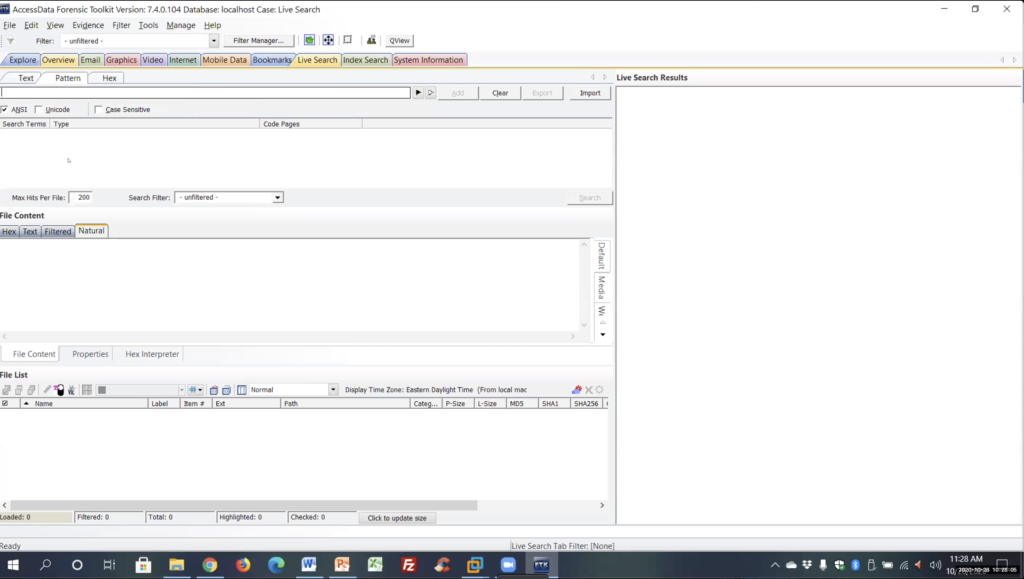
There is a black carrot here that you can use to design the patterns here. Again, I prefer to do it out in the REGEX tester, where I could see that actually works. And then we have a carrot here, which has already pre custom built on expressions.
We can go into edit, this is just an ini text file. And you can go in and delete any of these, change any of these. And this is where, if you want to create ones that you can share with other people in your group, share with other agencies. I just created some for a company in Canada, actually it was a government agency. I created a bunch of patterns for them. And we’re going to look at a couple of those. They want a driver license, health cards, Visa card, MasterCard, and I just gave him an ini file like this.
Again, you can see I already put this one in here. So I put in Columbia numbers equals and everything after the equal sign is what’s going to be put into the expression search. So again, you can create your own patterns here or put in your own patterns and have a drop down list.
So again, you can name it anything after the equals sign. And here’s the pattern we just created. Let me close that and you’ll see that it’s there. I added that here, Columbia numbers, and it populated the bar here. I’m going to add that.
One important thing I want to mention here again, we’re talking about live search two terabyte disk. You want to limit what you’re searching. So if you’re only looking at the web information limited to your SQL and your database files, if you’re looking at voluminous email that has attachments… but again, here you can search filters to only search certain information. I’m not going to go over filters right now. But again, in FTK, one of the strongest tools you probably have is your filtering, you can go in and you can actually create these filters. And it’s just endless, endless, endless options, properties for creating these filters.
[Indecipherable] expand the EVTX event logs and you can create a filter and say, I only want system EVTX logs with this event id, by this SID user, within this time frame. So again, you can develop these filters to search only what you want, really limit what you’re searching.
Again, this is a small case we’re going to send a search everything. So I’m going to leave it on filter hit search. And again, you can see here the job is going to go pretty quick.
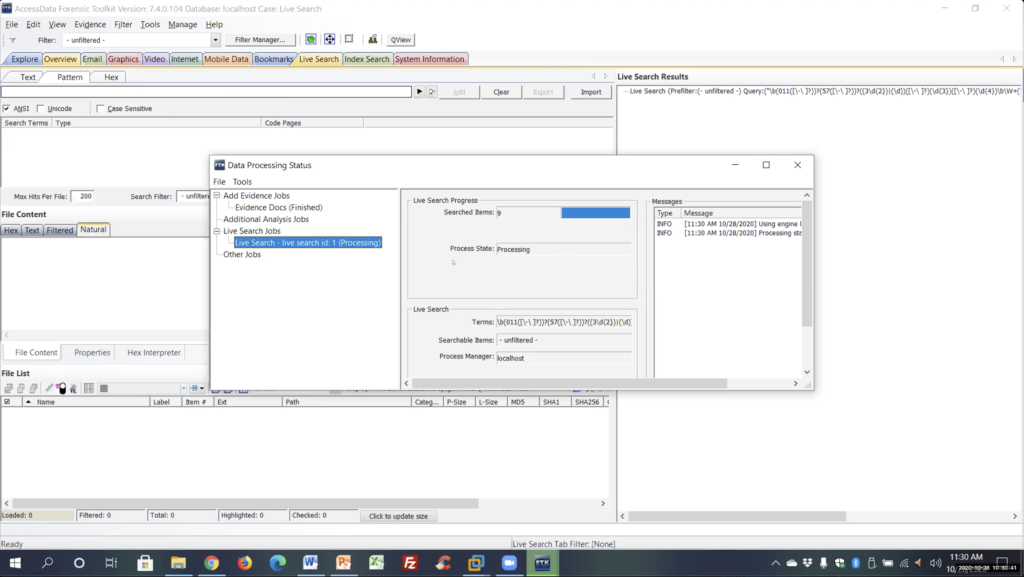
And again, I had a text file and a docx file with this information. It finished, my results are going to come up on the side here. And it says I had one hit and one file. And we can see that was the tax document. If I click on it, because it’s doing a bit by bit search, it’s going to show me the results in the hex. And we can see here the number and here’s our Chrome, the bolt muscle that it hit on. So it did find it. And again, you’re going to see it did not find the docx, because it’s a compressed file.
If we go over to my explorer just to show you, and we look at my Columbia numbers docx and we look at the hex, here’s the data. If we look at the hexadecimal, you’re going to see it’s all garbage as a compressed file. So this is what live search is looking at, it’s not going to find anything, it’s a compressed file.
And again, index search will find it. When we look at index search, you’re going to expand compounded files, index that information. It will find it. But again, just be aware that’s the huge limitation of live search. You’re not going to find anything sitting inside of databases, PDFs docx, etc. So a big limitation on online search. Alright. Make sure I’m not missing anything here on that.
Let’s go back to another example here. So, again, that was looking at a criminal case, trying to find information. Next example we’re going to look at is, this is for all you guys in incident response, doing exploits, trying to find information, maybe in DLL files, executable files, could be SQL injection across scripting. We’re going to look at a typical line out of a PHP web shell exploit. So again, here’s your typical… see this in a PHP exploit.
And all the ones I can find, pretty much, and I’m not very familiar with exploitation… a lot of the ones with the PHP web shells, you always have to get in the command within the executable code this sent across the web.
So I’m going to focus on getting the command, and this could be again anything. Anything that you’re familiar with, any of your, you know, any of your exploits. I’m going to be looking at the web cache, I was using the web cache. You see database, if it was Firefox and Chrome, we’re going to be looking at the SQLite databases and the app data.
So let’s go look at creating one for this. So let’s go back over to our store REGEX tester. Let’s throw in our test data. This is going to be a pretty quick and easy one to do.
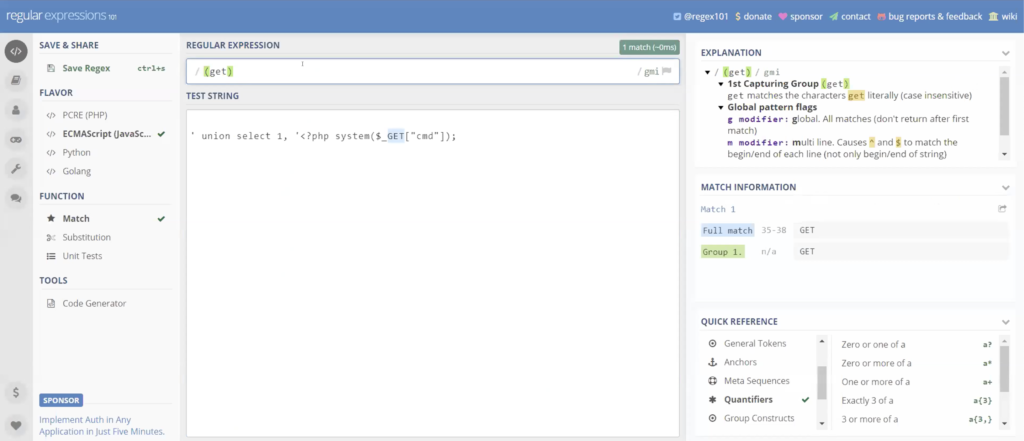
So again, here’s my line command line that I want to look at. So again, this is what we’re looking at. I wanted to focus on the get command. So again, this one’s going to be pretty basic. I’m going to make a group for get, create a group. So again, that was a backslash capital W plus parentheses, question mark colon backslash small w plus backslash capital W plus prophecy and then again within… I’m going to say again zero to 10 words.
And then I want it within command CMT. And again, this could be anything, any commands that you’re looking at. I used this recently on a case where, again, it was the one where they had 43,000 items ahead return but they’re really looking for a lot of things like social security number, social insurance number.
But again, they didn’t want just social security number, standing by itself in an empty form and in a document. So again, we would use social security number within zero to 10 words, have an actual digit string, you know, 10 digits, 12 digits, or you could even make it explicit digits string, like I did.
Again, we’re trying to narrow down, so security number within distance of an actual number set, so it can really help you to find your data and get rid of information you don’t want. So again, we can see that this work is already highlighted to get in the command.
Let’s take this again. And let’s copy this. Let’s go back out to FTK. And again, I had placed it, yeah, I had placed it already in the in the ini file. Let’s add that and let’s run the search on that and verify that it works.
Queued up, processing…
All right, it’s finished. And again, it should hit on the text file. And again, we could see here’s our text file. Now let’s actually go over to my VM environment. Let’s look at this on a on a real environment. I’m running a VM environment here with a domain server an SQL Server, our Enterprise product, and a Windows 10 machine.
I actually went out on this Windows 10 machine, and in IE and an explorer, I ran that command shell. And I can tell you, when I was trying to move this command shell around, Windows did not like it, kept deleting it on me. So as soon as I put in a text file, it would delete my documents, it recognized it as bad material.
Let me open up my Enterprise. And for those of you that are not familiar with Enterprise, it’s going to look the same as FTK. It’s 95% FTK. It has Volatility. So you’re going to go to volatiles tab. And as we’re going to look at this later it as a [indecipherable] to go out and retrieve remote data from a machine, which again, I have our agent deployed on this machine.
So again, I deployed a remote agent and I can go in and I can view this machine. I can capture a physical or a logical image of this machine. I can bring out anything I want off this machine, which is what I did. So I went in. I previewed this machine remotely. I found the web cache file and I brought it over to my system.
So again I export the web cache file, and I just loaded it as a case. So again, I loaded in the web cache file, I set up all my processing on it, again, I process that, I expanded it.
FTK, especially when I’m doing in-texts, FTK could see everything. One was expanded, and I indexed it. Unless I do the same live search here. So I’m just going to paste it in here. Let’s add it, and let’s search it. So now we’re actually looking at a real life event you should see in that web cache, if I went out and ran it on a web page.
Processing is finished. And it says that there’s zero results. Alright. It didn’t work. And again, why didn’t it work? Because our web cache file is a compressed file.
Index search: I’m going to be honest with you, I have not been able to get that expression near the one I was showing you with the multiple W’s. I haven’t been able to get that to work. And when you’re converting the TR1, sometimes it’s hard to get things to work, a lot of them will, some of them won’t.
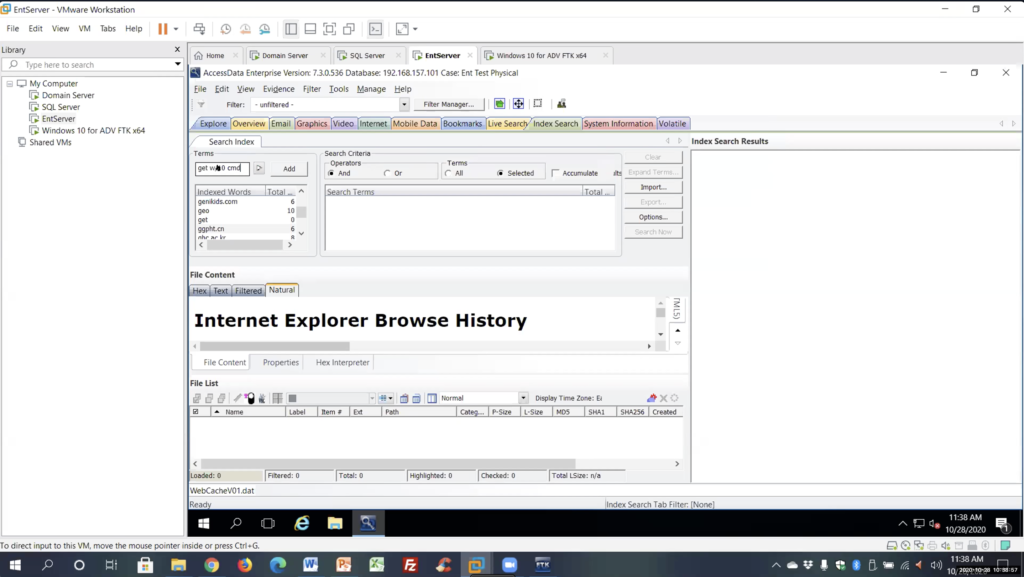
But again — and we’re going to go over this in a minute — there’s an easier way to do this index within 10, which is a DP search command of CMT. So again, get within 10 of CMT, not using any expression from REGEX or TR1, but we’re using keywords and we’re using a dtSearch operator. I’m going to add that, and it already tells me, we’ve got two hits by search.
And we expand this out. We’re going to see, in the web cache, there’s the command line that I ran. So again, index found it, live search did not find it, again, because it’s a compressed file.
Alright, let’s go back and let’s take a look at… these are just a couple other ones I did. I think Mike had mentioned, this is one of the ones that’s different. Canada. Canada. These are all the possibilities that can exist for Canada, for visa credit card numbers. So again, the first six digits. The rest is filler, with nine that I put in. But again, the first six digits. These are the only possible numbers that can be issued in the country of Canada, and they wanted to be able to search this.
So again, if you look, what you can see is, you know, the first one is 4500 followed by a dash or space. And then followed by 03 and then two additional digits or 65, by two additional digits. And then we go to the next number, 4502 dash space, 22 additional digits, or 28 by two digits, or 31, and just keep going. And then I finish it all up with: all of them have to be followed by four additional digits.
So again, just play with logic in your patterns. If it doesn’t highlight, change things around, regroup things. Try and get them to match. I can sometimes spend a day just trying to get things to match to get what you want.
Here’s another good example for emails. Going through what we went through, it looks complicated, but really it’s not. So the square brackets say: anything within those square brackets needs to match in the first part of your email. So, [email protected], have to match these first set of brackets. So the backslash W means any word character, 018 is the upper lower case.
Okay, it can contain a period and underscore, a percent, plus or a dash, any of those are going to make up the first part of your email. The plus sign just means any of those can appear as many times as possible. Then we have an at sign, I directly match the at. And then after the at sign we have again backslash W is a word, character, zero to nine, capital, a lowercase A to Z, a period or a dash. So then again this would be accessdata, this would be hotmail, gmail… And again, the plus sign just means as many times as possible.

Then we have a backslash period, again, backslash because period is an operator. So we’re looking for an actual period. You got to use the backslash to escape the operator.
And then a to z, upper, lower case, to four times. Again, this will be your.com, your.net. And if you put this in and run this, this will find any email. It should find any email. So again, not very complicated if you really know what you’re looking at.
Alright, let’s talk about the index search. Index search, very important. Indexing options and case processing.
So again, and this has nothing to do, even, with doing expression searches. But anytime you’re going to do a case in FTK, when you set up your case, case processing, expanding compile files, very important. If you don’t expand it, you’re not going to see it.
We’re talking about your ETFs, event logs, we’re talking about zip files ,were talking about database files, is the database SQLite, database files. If you don’t expand it, you’re not going to see the information and it’s not going to be indexed.
If you expand it, all that information is going to be indexed. So you can search any information and your logs, any of that data and that meta data. You can search by index. Because once you expand it you can also index it.
Another thing we’re going to look at is indexing options. Certain characters are not indexed: commas, question marks, dollar signs. You’ve really got to be careful what characters you index. If you don’t index [indecipherable], your index search is not going to find it. It does not index a hyphen. So if you’re looking at a social security number and you don’t index the hyphen, it’s not going to find it. It’s going to treat that hyphen is a space. So again, it’s not going to work.
And these are things, as you start doing, you’re going to be like, why isn’t it working? Well, because I didn’t index a certain character. So you’re going to run into this a lot.
And index search searches are very fast. More time upfront doing the index, but searches are pretty much immediate, very fast.
One nice thing we’re going to look at in index searching — and again, you don’t have this capability in live search unless you go in and change your keyword and every expression — is, we can combine keywords, DP search operators, and TR1 expressions, all within the same command line. And we’re going to look at that.
Very, very convenient. The only drawback of index searching is spaces. And we’re going to look at the limitations of TR2 expressions. But spaces are treated as word breaks, so you cannot do anything with spaces, and I’ve tried every possibility. There’s nothing you can do. Even treating the word breaks as word breaks. There was nothing I could do to use spaces in index searching. So again, that’s really the only drawback.
dtSearch operators. Again, you can pull up the whole list. These are the main ones, you get your Boolean operators. Your and or not. Again, we looked at instead of that large expressions that we had and REGEX just within the W slash whatever number within 10 words, five words. Equal signs as numerical patterns. So again, if you index the hyphens, you could actually just do equal equal equal equal. Equal dash for more equals. That’s going to look for an exact pattern on Social Security numbers. So again, we’re not using actual TR1 or REGEX, we’re just using a dtSearch operator to find that pattern.

Question mark was mentioned earlier in dtSearch. A question mark is any single character, a wild card. A star is any wild card of any character. I was mentioning earlier that if you ran Chris in live search, Chris is going to give you Christopher or Christmas. If you run Chris in index, it’s going to give you only Chris. If you put a star before and after, Chris star Chris star, ot is not going to give you Christmas, Christopher, or anything else. So looking for any number of characters before and after Chris. So again, that’s a wild card and it’s going to do that for you.
Two squiggly lines is going to give you a numerical range, and then any expressions you run. And most, a lot of the the the REGEX expressions will stay the same. And we’ll look at what needs to be changed. But again, it has to be started with a quote, two pound signs and end with a quote for index search and relativity to actually recognize it as an expression. These are the limitations of converting REGEX to TR1.
We’ll go over these really quick. All characters in dtSearch are normalized to lowercase, so REGEX must contain lowercase characters only, you don’t have to worry about case in case sensitivity. You don’t have to worry, it’s going to recognize the upper lower case. But again, only lowercase characters when you’re doing TR1 expressions.
Spaces. I mentioned this, or interpretive breaks. There is an operator that we’re using, REGEX backslash as for a space, you cannot use it in index searching because spaces do not exist. Again, I said you got to encapsulate it with the quote. And the anchors, you do not need the anchors in MTR one.
So the word boundaries, again, Chris is Chris, it sets word boundaries. It’s not going to find… you’re looking for 123, it’s not going to find ABC123456. It’s looking for just 123. So again, the word boundaries.
This is just a little example of how you can write the same thing. I think this one’s a lot, six, seven different ways. The same thing. You definitely get the logic of this one [indecipherable] exactly searching for it. But we’re looking for the keyword money. So again, a keyword add search operator within 10. And this first one we’re saying zero to 9999 so all one, two or three digit characters. And we’re using a dtSearch operator. This one, again, we’re saying money within 10, a pattern of one digit or two digits or three digits, same thing, that these four.
We’re using a keyword, we’re using a dtSearch operator, and we’re using a TR1 expression. And again, you can see these TR1 expressions are the same as the expression. Nothing’s different, but this one we’re saying we want the digit to have one character to three characters.
This one we’re just typing it out: digit or digit or three digits. This one we’re just saying the same thing, zero to nine, zero to nine twice, or 093 times. Again, this always just typed it up, once, twice or three times. You can see there’s multiple ways of writing the same thing, and trying to get the same results.

Let’s take a look at one example. We’re going to do an index search. This one I actually did for a government agency up in Canada. Same with the credit card numbers. Every province had a different driver license number. This was for Ontario.
So again, the driver license number starts with the first letter of your last name, followed by four digits. A dash, four digits. Then youe year’s divided, two digits, but it’s actually got a dash in between. So this is your dash year, month and day. Something that was thrown in has it makes it a little more complicated is for month [indecipherable], instead of being January to December, they add 50.
So this is the pattern we’re looking for. So let’s go out and let’s write this pattern one more time in our REGEX. Let me go grab my examples for that.
Let’s throw in our test data. And let’s write this again, follow it step by step. I’m going to start with it. I’m going to throw each of these five digits into its own group again. Pretty easy. It starts with a letter. So I’m going to use a to z. So again, I’m looking for any letter A to Z, if we’re doing this in REGEX I would actually have to put a to z and capital A to Z. But again, dtSearch and TR1 does not look at case. So just a to z. And then it’s going to be followed by four digits.
So there we go, we got our first match. And again, we’ve seen this before. We’re going to put in our hyphen, our space, and a question mark to cover all those possibilities of a hyphen, a space, or nothing at all.
Let’s get into our second set. We’ve got four digits. Actually, this one is five digits, because the year, we can’t really set any parameters on a year. Really, for the year, it could be anything from one to nine. So I’m not going to do anything with the year. So again, this is just going to be five digits.
One letter short, but you can use here is a backslash with a number is going to repeat the second group. So if I look, this is my first group. This is my second group. Instead of having to type this again, I could just do backslash w and it’s going to repeat the second group, so I don’t have to type that again. I took it and backslash 2 took care of the hyphen, the space, or the null space.
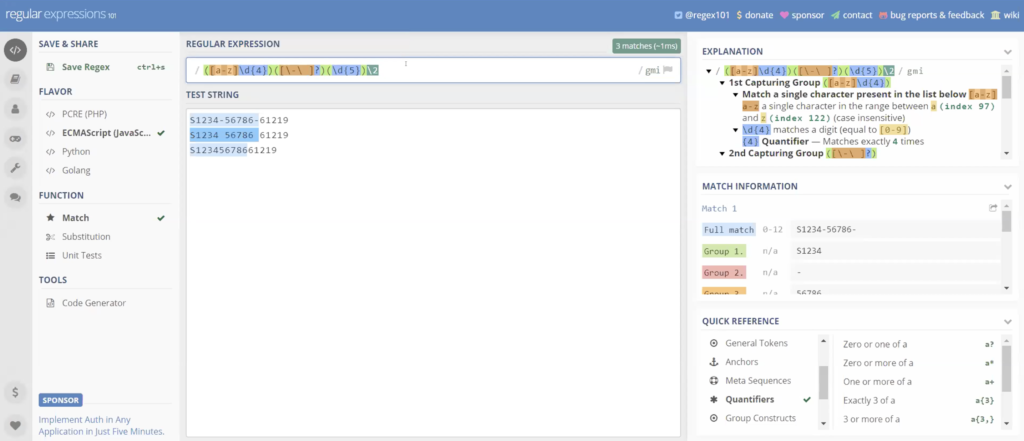
Again, and if you go out and you research just the different options on any REGEX cheat sheet, you’re going to see all the different options. It’s just a way of shortening. And this last one is going to get a little lengthy now because we are looking for the first digit of the year, again, could be pretty much any digit. So we’re just gonna say backslash digit and now we’re looking for the month. Again, remember, it can be January to December or 50, what’s going to be 51 to 62 for females.
So let’s start with the January to December. And then remember they’re going to be represented by two digits. So January is going to be 01, February 02, so we know it’s going to be a zero and it can be anywhere from one to a nine for January to September. 01, 2, 09, or now we’ve got to cover October to December, so we know it’s going to start with a one.
And a 02, a two. So there’s going to be 10 to 12 for October to December. Oh, sorry, square bracket, and we got to worry about females. We got to add 50. So we know it’s going to start with a five, and it’s going to be 51 to 59. And all we got to cover October to December, we got to add 50 so it’s going to be 6060. Let’s make sure I’m getting this right, yeah, 60 to 62 would cover adding 50 for a female. That covers all of our variables. So we’ve got January to September or October to December for men, and then adding again for females 51 to 59 or 60 to 62.
Now we want to look at the days. So again, we’re going to do the same thing. So days can be, this can be zero, because it’s going to be two digits. So 1294 days. So we’ve gotta go 1019, 2019, or 20 to 29, we’re trying to fill all the days. So what is it, 1 to 31, so we did 1 to 9, 10 to 19, we’re doing 21 to 29, and we’ll finish up with 30 to 31. So again, that covers all of our days.
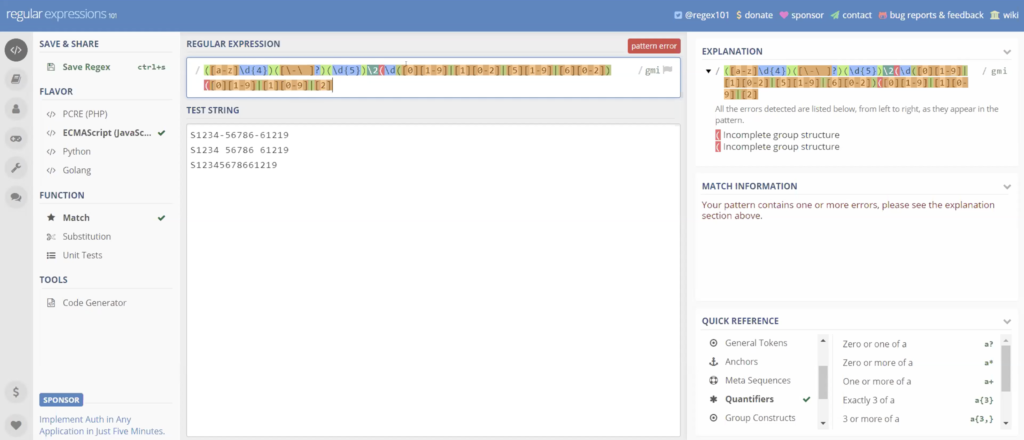
And if I throw in the last bracket, you can see now, it hits on all of our items. And again, just to take playing around, it’s not really the operators is the logic. You’re really not using that many different operators in here. So it’s just playing around with the logic and making sure you’re getting what you’re trying to get.
So again, here’s our expression. We don’t need backslash. We don’t need capitals, and since this isn’t going to work, we can get rid of the spaces. Spaces are not going to work. So this one is not going to hit no matter what we do an index search. So we don’t need the spaces.
Alright, let’s go out and test our expression on some test data, validate it. Let’s go over to FTK. Now we’re going to look at index search.
Michael Lappin: On five minutes here, Tim.
Tim Stommel: Alright. Not a problem.
Actually, we could use the same case. I will start a new case, we’ll just use the same case on index search. So index search, open this up again. You have your carrot here. You can edit and add your expressions in here, just like you could on the other one.
We’re going to paste this in here, we’re going to add it. Yeah, we’re going to conduct a search on our data. Well, what happened?
You know what? We did not do the indexing on this, so what happened was, we did forensics processing. So we didn’t index the dashes and that’s all going to work. So we’ll create a new case and will run this. You can see the results with the case.
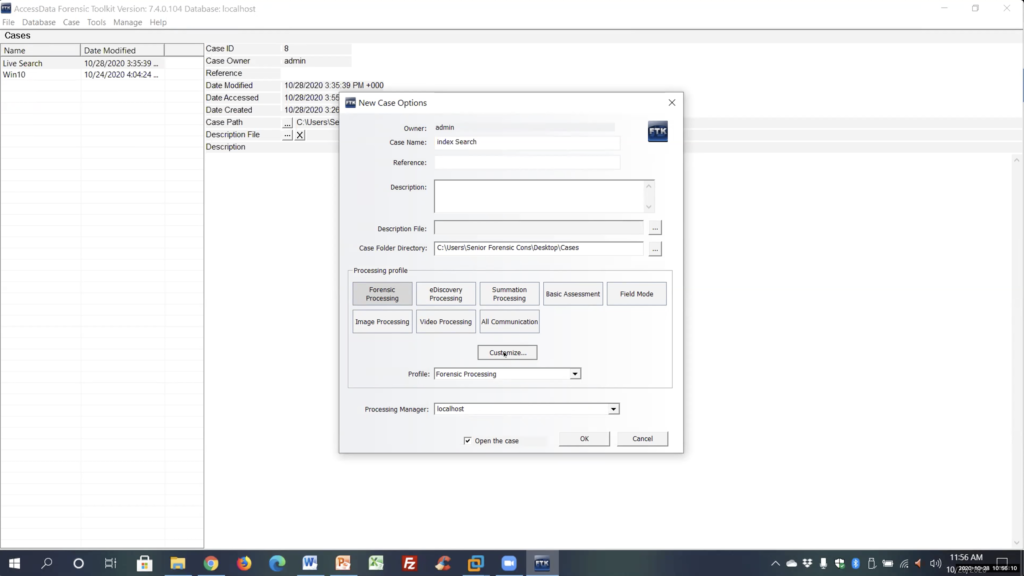
Now, we’ll name this live search or index search. Again, here’s where we want to customize and again I was talking about expanding comp on files.. We want to make sure we expand the right file.
We’re going to select their expansion files indexing options. I’m just going to click modify for TR1, it’s going to treat a hyphen. Again, here’s where you can select your characters. Alright, we’re gonna hit ok, we’re gonna hit ok.
Let’s create this case. Alright, let’s add my test files real quick, contents of the directory.
Let’s scroll down. Let’s do a webinar, let’s do some evidence documents. That’s it. Okay, and let’s process real quick. And leaving me just enough time to run this expression.
Again, I’m not going to get probably time for it, but using our finished… let me click over to slide when we finish this up. Again, I’m going to throw my expression in here.
What’s going on? I’ve got some something that is not working. Let me do this. Let me just grab it off my sheet. Not sure, was working in the tester, but let me… oh, you know what, my fault. Sorry, guys. I think we’re clear that we’ve got to start it with, and I told you this, a quote. No, it’s an expression. Put me on the spot.
I’m under pressure here, Mike, to finish up. Let me try that again. Shift’s on, control, make sure we’re at the end of the expression here, to my other quote, but add it. Alright. So let me search it
Again, you can apply your filters. Here’s our results.

And if we look down, again, index hit on both the docx and the text document. So again, that’s index searching real quick. Enterprise file filter system, deploying agents on remote machines. You can collect remotely. It allows you to create filters while you’re searching on a live system. And again, you can use REGEX searches on your remote system, so you actually can search on the live system and just get the results you want back on a live system.
One last thing I want to mention before we finish up here is volatile memory. Most people think about using Volatility to look at services, but again you could dump your memory dump into FTK index and use the same techniques, keywords, operators and expressions to search your memory for type text, for anything you can think of: usernames, passwords, search your memory dump using these tools.

And again, that was all the information today. There’s my email address if anybody wants to contact me. This has been recorded. You can replay it, so I know it was a lot of information, again, a tool does a lot, so I hope you pick something up you can use. And again, email me if you need any information.
Michael Lappin: Thanks everybody for sticking with us here and watching him go through all that. Really, really interesting. And again, reach out to Tim if you want some tips and you want some ideas, or if you need some real help. We’re here for you. Hey, Holli, is there anything else we forgot to mention as we close out today?
Holli Hagene: The only thing I wanted to mention was that there is a survey after we close out the webinar, if you’d be kind enough to answer that, it’s only four questions. Other than that, we’ll send out the recording when we get it.
Michael Lappin: Fantastic. Thanks again, everybody. And Tim, great job, as always. Thanks so much for helping us through all that and teaching us everything, hopefully we’ll have another one soon.
Tim Stommel: Alright. Thanks, Mike. Thanks everybody for attending.





