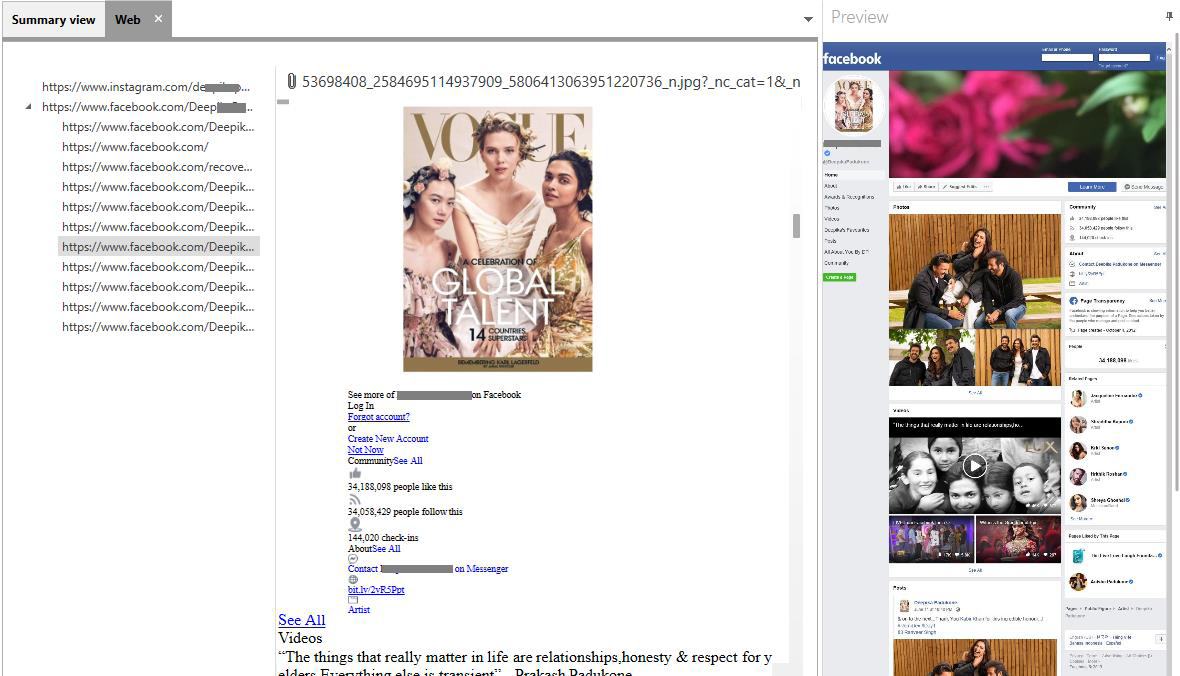
‘17.5 Zettabytes.’ This is the amount of data that the IDC estimates will be generated annually by 2025, and among those numbers, cloud traffic is expected to grow and reach 18.9 Zettabytes by 2021.
This tremendous amount of cloud data is generated and fueled in the course of building driver assistance and autonomous vehicle technologies; IoT devices including sensors in our bodies, homes, factories, and cities; high-resolution content for 360 video and augmented reality; and 5G communications globally.
As many digital forensic investigators are facing so-called ‘digital transformation’, finding evidence data from various cloud services is a highly demanding and important mission for digital forensic investigators. Cloud forensics is no longer optional but an essential solution, since many law enforcement professionals work on cases with devices with deleted data, which needs further investigation of the backup data. Plus, there is a tremendous and growing number of smartphones, IoT devices, automobiles and many more smart devices which store all their data only in cloud services.
This article is to introduce the cloud forensic solution of HancomWITH, a step-by-step guide about data extraction and data view using MD-CLOUD. Various cloud and email services are supported, and data stored in social networking services such as Twitter, Facebook and Tumblr can be extracted by MD-CLOUD.
MD-CLOUD Overview
Product Highlights
– Supports extraction from global cloud services such as Google and iCloud
– Supports extraction of Cloud-based IoT device data
– Supports extraction from cloud services based in East Asia, such as Baidu and Naver Cloud
– Authenticates via ID and password, two-factor authentication, Captcha, and token credential information found locally on smartphone images, such as iOS Keychain
– Includes automated web scraping tool for recursively capturing public webpages
– Provides automatic evidence-tagging feature for intuitive searching
– Natively integrates with MD-RED
Key Features
Supports a wide variety of cloud services
Google, iCloud, Samsung Cloud, Naver Cloud, Evernote, One Drive, Baidu
Supports email extraction
POP3 and IMAP, as well as specific support for Gmail and Naver Mail
Supports extraction from social media services
Current support for Twitter and Tumblr, with Facebook support under active development
Specializes in East Asian cloud services
Baidu Cloud in China
Naver Cloud in South Korea
Acquisition of cloud-based IoT device data
IoT data extraction from AI Speakers and Smart Home equipment
Supports authentication via both public and unofficial APIs
Supports various authentication methods
ID and Password
Captcha image tests
Two-Factor Authentication messages
Credential data pulled from smartphone dump images (such as iOS Keychain)
Provides automated web capture feature
Automated web-crawler capable of recursively extracting from a target web page
Real-time extraction progress monitoring
Displays the progress of ongoing extraction jobs in real time, from zero to one hundred percent
User-friendly interface
Features a simple, intuitive, and effective user experience that warrants little training
Native MD-RED integration
Imports credential information found in suspect smartphone images that have been analyzed in MD-RED
Intuitive ‘Evidence Tagging’ based search feature
Automatically tags and categorizes data as it’s extracted from the cloud so that it can be quickly searched, grouped, and organized
Built-in data preview
Supports previewing any selected image, video, document, web page, email, and many more
Supports filtering by date range and file type
Allows users to limit the results of their analysis only to the time period and file types relevant to their case
Hash based data integrity assurance
Guarantees the integrity of the evidence data through powerful hash algorithms such as MD5 and SHA256
Report generation
Provides simple-yet-powerful report generation tool that supports both PDF and Excel formats
Below is a simple but useful guide on MD-CLOUD for those investigators who would like to maximize their digital forensic skills and be prepared for the cloud data tsunami.
1. Data extraction using ‘Credential information’
1.1 Create New Case
MD-CLOUD can access cloud services in several ways. Apecific services may ask the user to complete an additional verification process, such as a Captcha entry or two-factor authentication. To start new cloud data acquisition, select ‘New Case’ and set the case name and path. This time we’ll try using credential information.
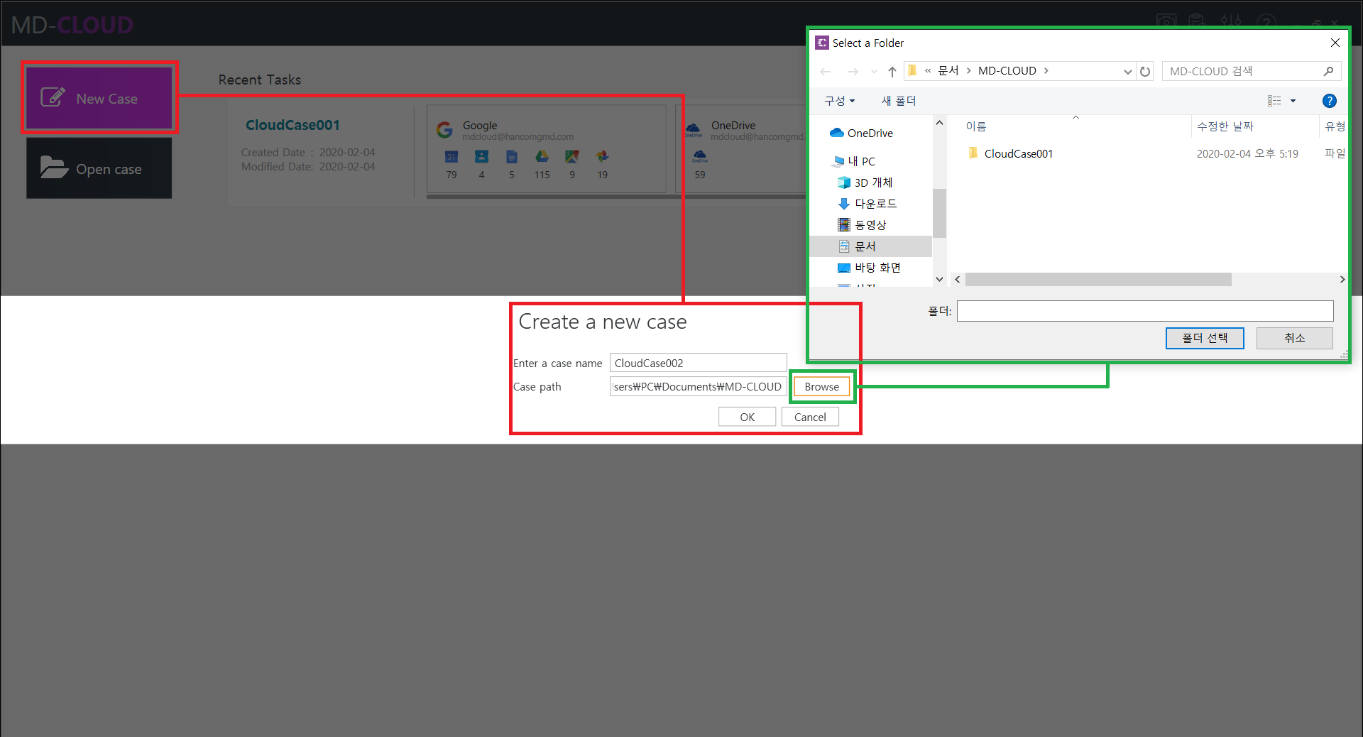
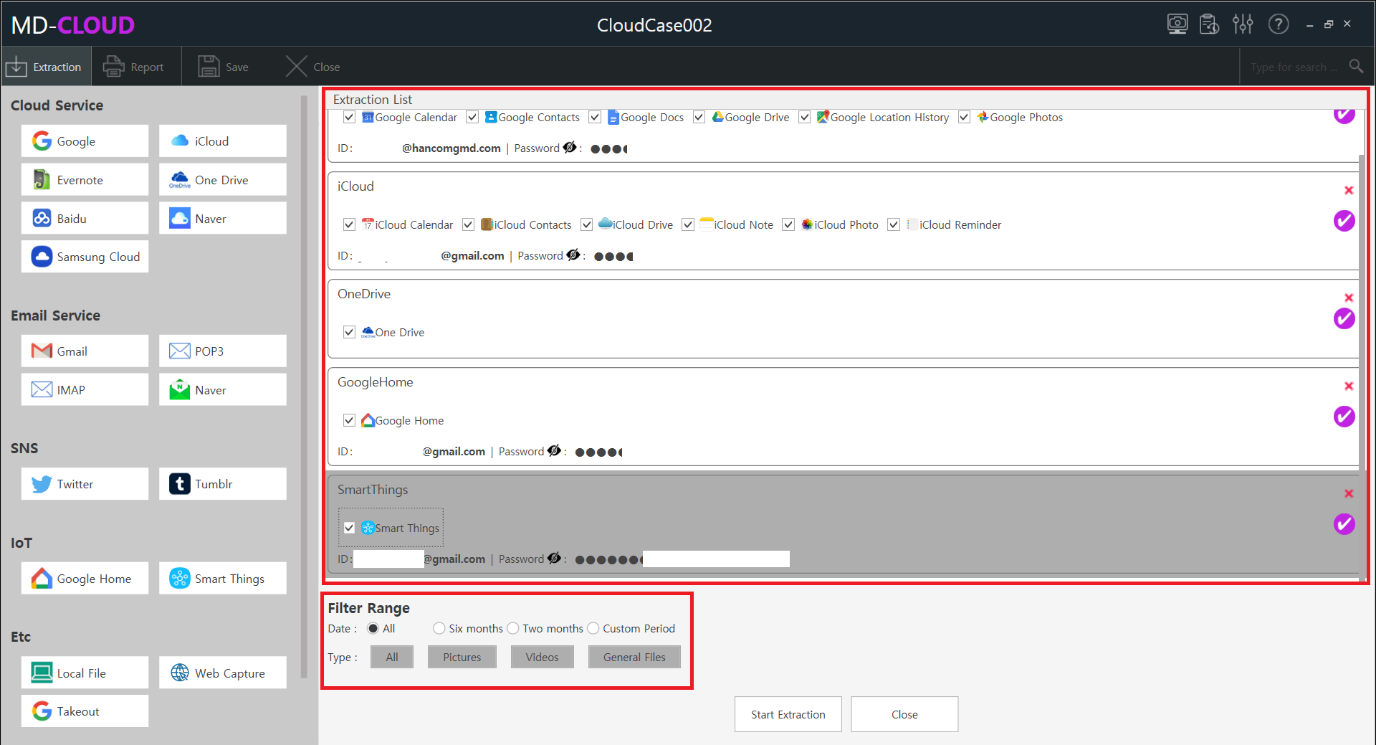
1.2 Select service and proceed with data extraction
Various services such as cloud, email, SNS and IoT devices are supported by MD-CLOUD. These are displayed and categorized by type.
In this sample case we will try extracting data from Google. Select the Google icon on the left side of the screen, and then with the checkboxes, the user can perform selective data extraction. Date range and extraction type can be set before proceeding with the extraction process, then the resulted data will be collected on the extraction of filter conditions. Furthermore, even after the extraction is completed additional data sources can be added to the existing case without having to create a new case.
2. Data View: Contact/Event/Note/Email/SNS/Web Capture/Timeline Feed/Search View
2.1 Extraction Summary Dashboard
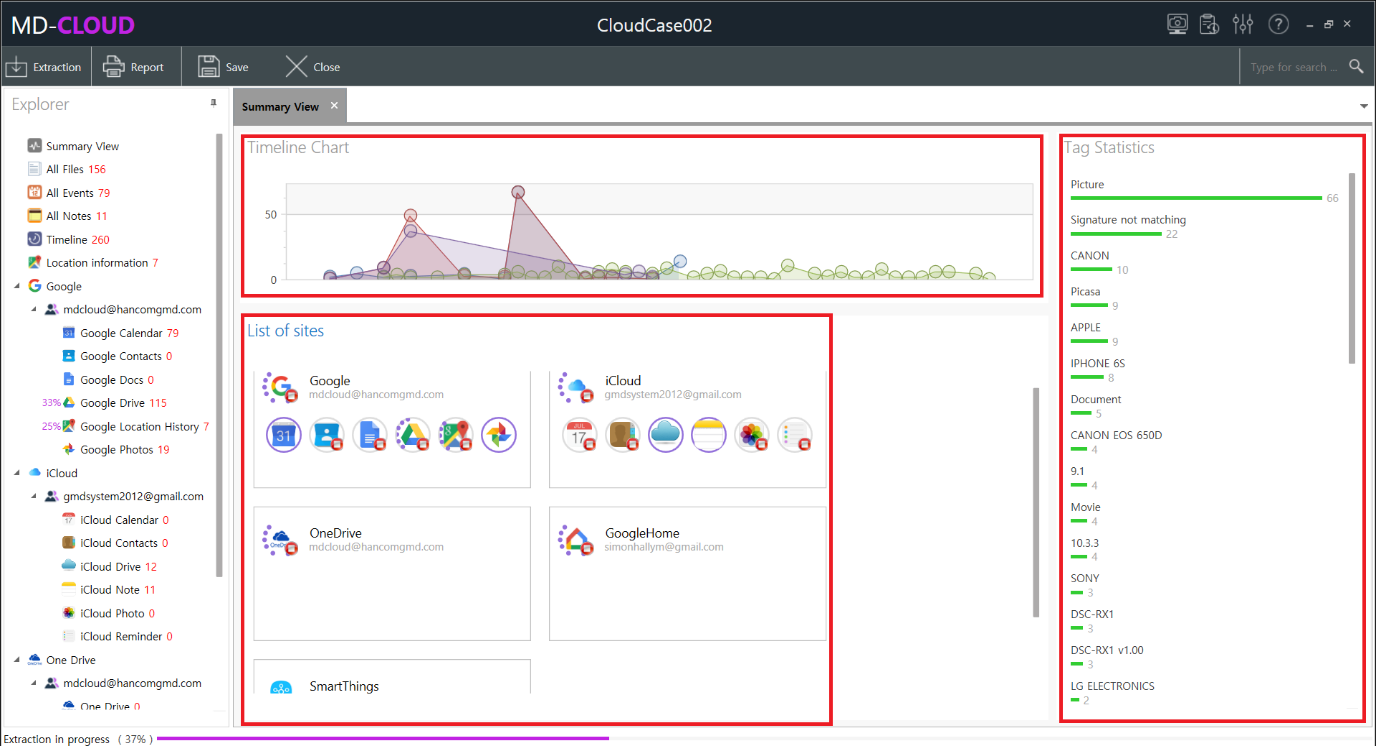
Once you start the extraction, a Summary View will appear and display the progress of ongoing extractions and some other miscellaneous information.
- Timeline Chart: Displays the amount of data that has been extracted so far, relative to the dates associated with the extracted files (created / modified / uploaded time).
- Tag Statistics: MD-CLOUD automatically categorizes extracted files using tags that are generated through file metadata. The statistics of the tags are displayed here.
- List of Site: Summarizes the progress of extraction from data sources. It can be completely stopped by clicking on the stop icon.
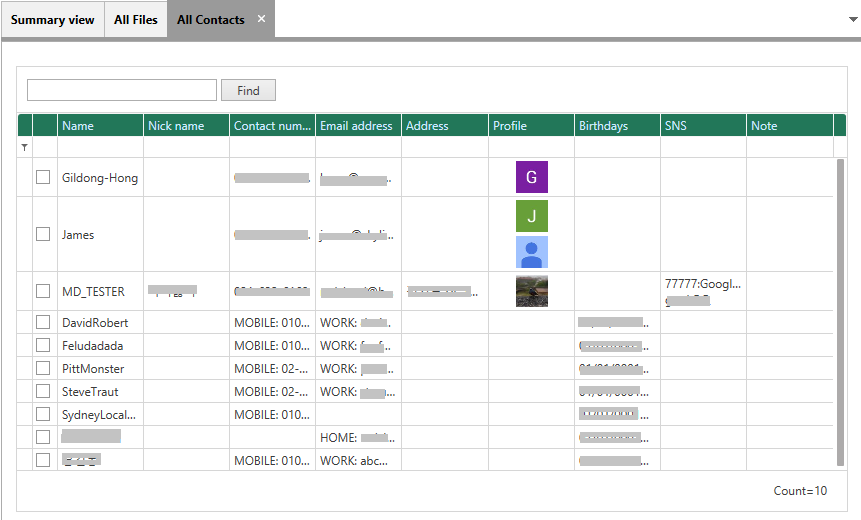
2.2 Contact View
Displays contact information such as contact name, nickname, contact numbers, email address, address, profile, birthdays, etc.
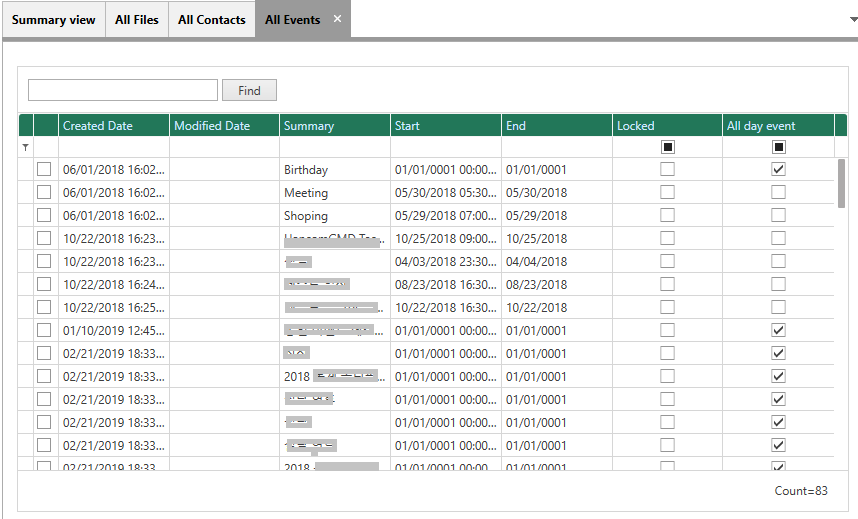
2.3 Event View
Event data such as birthdays, shopping, meetings, driving, celebrations, conferences, seminars, and other events.
2.4 Note View
Displays notes collected from Cloud services such as iCloud Notes, Evernote, etc.
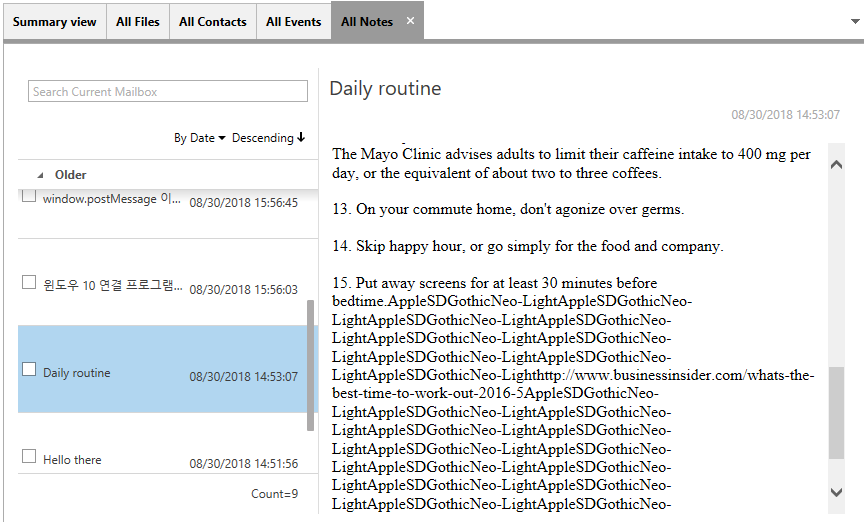
2.5 Email View
Email View allows users to group and sort based on date, subject, ‘from’ field, credentials, etc. Email items can be searched using the inline search box.
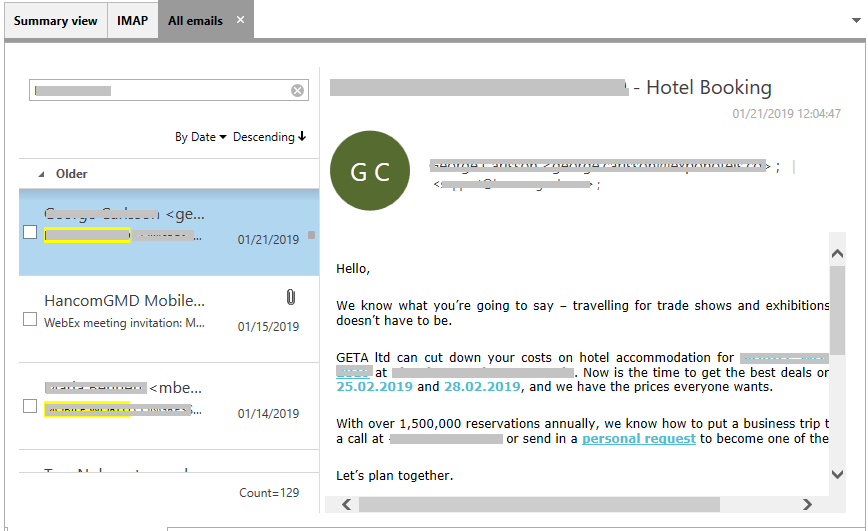
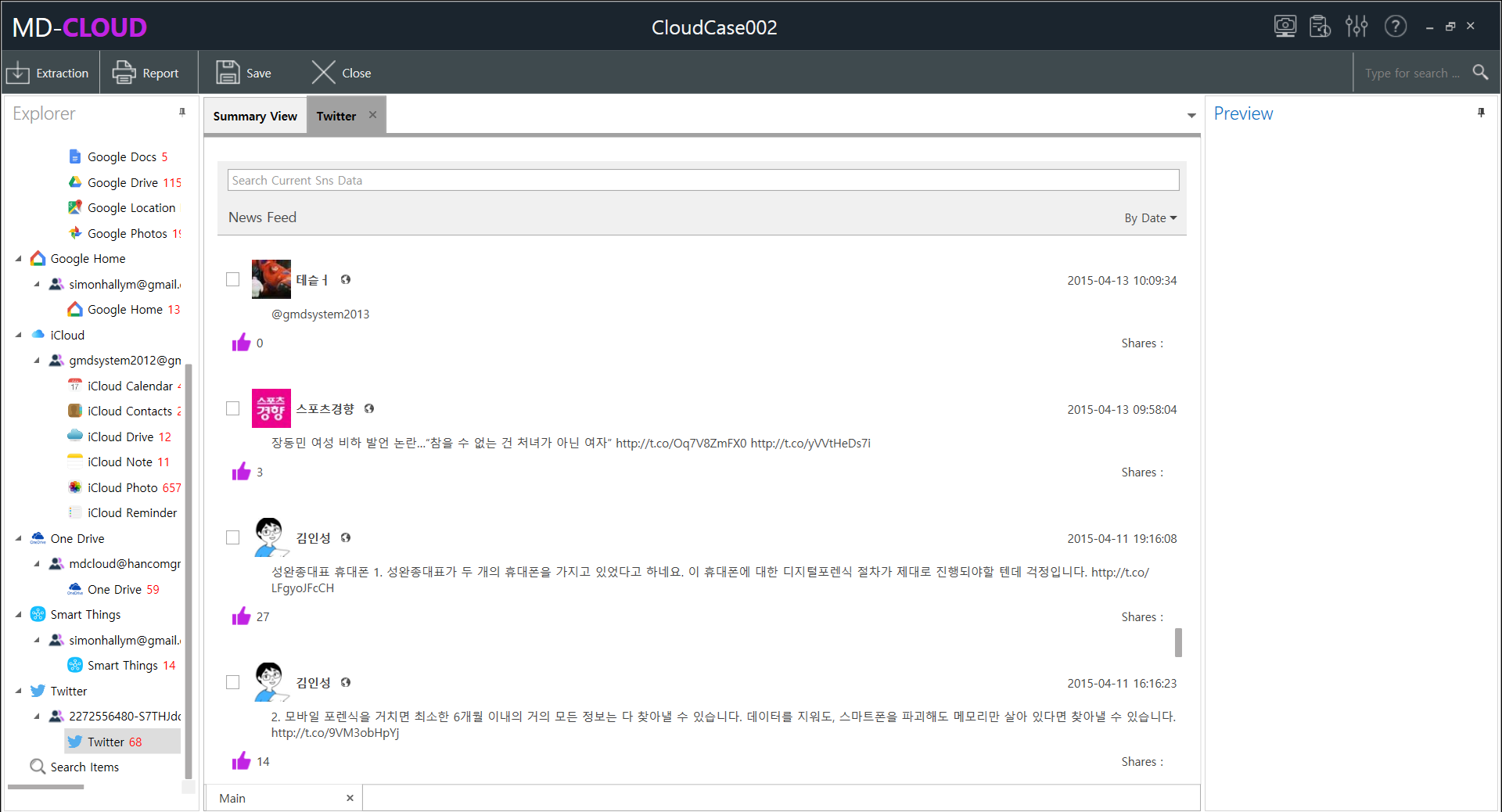
2.6 SNS View
Posts, multimedia, files and other information extracted from social network services such as Twitter, Facebook, etc. are displayed here.
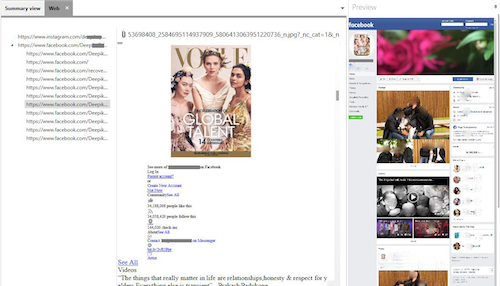
2.7 Web Capture View
Contents that have been extracted through data crawling on the provided links and their sublinks will be displayed in the Web (Web Capture) View. Multimedia, posts and other public contents can be extracted from some sites like Facebook, Instagram, LinkedIn or any other webpages. It displays the below information.
- Link information: A list of extracted main links and their sub-links are displayed here.
- Content View: Displays the content of the selected link.
- Preview: Displays the overall look of the webpage.
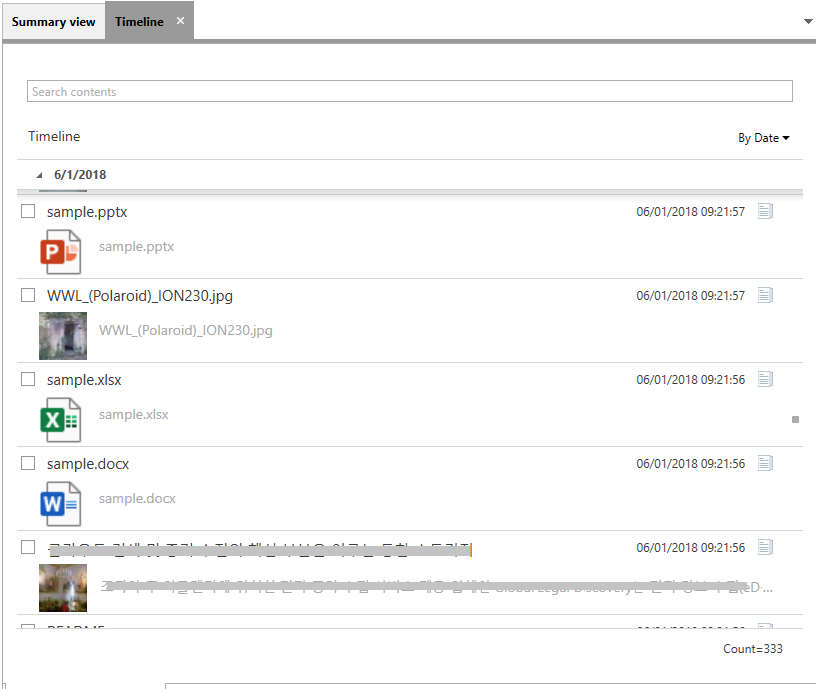
2.8 Timeline Feed View
Displays the data from every category and arranges them by date (default), subject, content, type or credential.
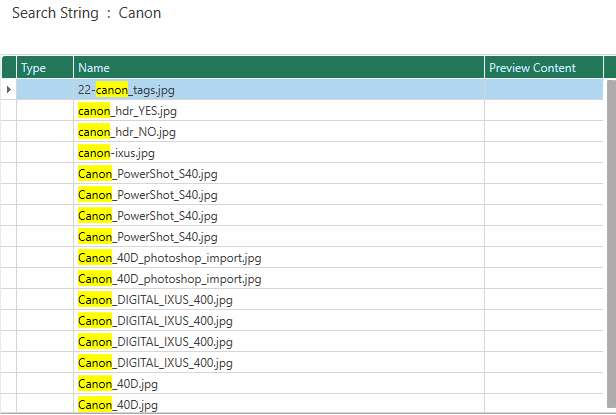
2.9 Search View
When searching keys from anywhere in the entire application, those search keys are maintained in the Search View. Double-clicking on the search key, you can see a list of the search results.
3. Generate Report: Case Info/Options/Layout
After the data extraction, the user can generate a PDF report of the case, which will display all the information of the extracted files and thumbnails of multimedia data. Below we have attached a screenshot of an extraction report for Google Home.

The call for MD-CLOUD will gradually increase as it has great practical value and importance as a data acquisition tool that can investigate mobile data backup and new data stored only in cloud storage. Our effort to add various data extraction sources and product advancement on MD-CLOUD will continue.
If you are interested in cloud forensics and want to learn more about MD-CLOUD, please check the product specification at the below link, and reach our team via [email protected].





