by Robert Craig and Michael Lambert
Abstract
Samsung devices are a large portion of the Android OS market. Samsung has its own Internet Browser, “sbrowser”, installed onto their devices. All web browsers leave artifacts from user activity. The “sbrowser” cache files were similar to other browsers. An embedded source URL gave insight where the cached image came from. Looking at Internet History, cookies, and the cache file itself, an investigator can gain insight where the cached image came from and the likely web page it came from.
Contents
Introduction
Mobile device examinations have become an integral part of criminal investigations. Suspects use the device to plan and perpetrate their crimes. One aspect of an investigation is what Websites the user visited. Mobile devices have the options to use multiple web-browsers such as Chrome and Firefox.
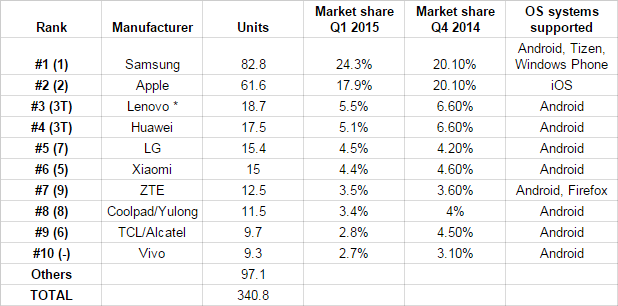
Samsung began rolling out the latest version of its Android-powered Samsung web browser found in the latest Galaxy smartphones, and it represents Samsung’s desire to create a browser built around compatibility, functionality, and ease of use [1]. On the Samsung Developers web page it explains, “Samsung Internet for Android is a Simple, Fast, and Reliable web browser for your phone and tablet. It has replaced the Android Stock browser on Samsung Galaxy devices since 2012 to provide a browser highly optimized for our devices.’[2]. In the figure below (Fig. 1), Samsung is the leading producer of smartphones. This means as mobile device investigators encounter the Samsung devices they will see more and more of the Samsung Browser. There is also the possibility the browser can be on other devices. The Samsung Browser is also available for download on the Google Play Store.
For the purposes of this paper the Samsung Browser will be called the “sbrowser”. This is from the Android Samsung Browser package name “com.sec.android.app.sbrowser”(Note how it is with a smaller case “s”).
The sbrowser is similar to any other web browser found on an Android mobile device. It will store Internet history, cookies, and web page cache files. The files located in the cache can assist investigators in identifying where the cached images came from by reviewing the Internet history and cookies, a correlation with the cached images can be found.
Literature Review
Cache files are artifacts that are left over from webpage visits. The presence of metadata within a cache may be an integral piece of evidence for an investigation. This however is hampered by issues retrieving that data. Storage location and type may be different depending on the specific app.
Hoog 2011[4] states that the webview cache database provided the metadata about the cache files stored in cache directory [5]. In Chandrakumar 2014 [6], it is reported there is large cache format diversity surrounding apps. App developers are at liberty to choose which format their cache would be appropriate for them and single apps may use multiple cache libraries. These cache structures are often not documented. Chandrakumar 2014 spoke of analyzing generic caches, in doing so Chandrakumar was able to map data found inside of the generic cache folders. This data included but was not limited to constants for header records, length of URL and the URL of the cached data.
Martini, Do and Choo [5] speak of how cached files “may expose evidential data that was temporarily stored by the app; however that non-standard binary format is commonly used and unless that format can be decoded the binary analysis of the strings may be the only straightforward means of analysis.” Martini, Do and Choo advised format of the files are subject to the choice of the developer but things such as header analysis and other standard forensic techniques could be used to determine the potential file type which could be used to potentially decode the file. If decoded these cache files could be extremely useful to cases as it may expand upon traditional web history data and confirm site visits, times of visits and possible content of the site visited.
Method
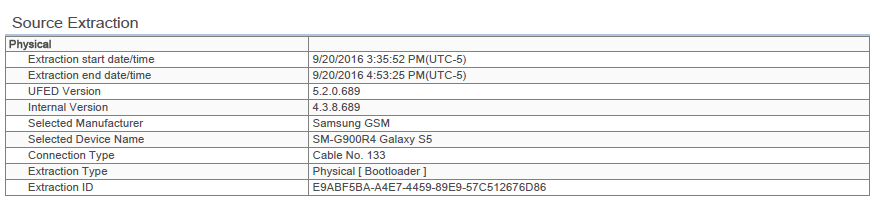
For the mobile device a factory reset Samsung S5 (model SM-G900R, US Cellular, Appendix A) was used. The Android OS version on the device was 5.0. The mobile forensic software used to acquire physical acquisitions was Cellebrite’s UFED4PC v5.2.0.689. Cellebrite’s Physical Analyzer 5.2.5.24 was used to analyze the data.
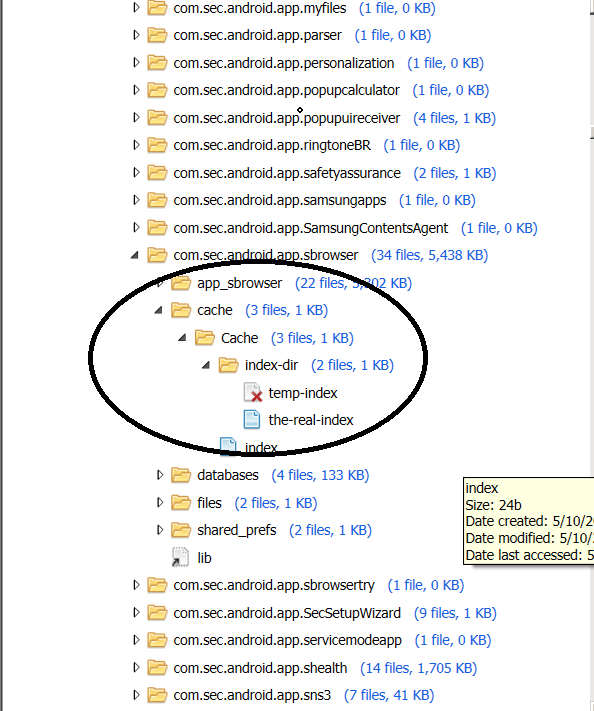
A base physical image was done first on the device (Appendix B). Looking at the App Data Storage Directory the com.sec.app.sbrowser cache is empty (Fig. 2).
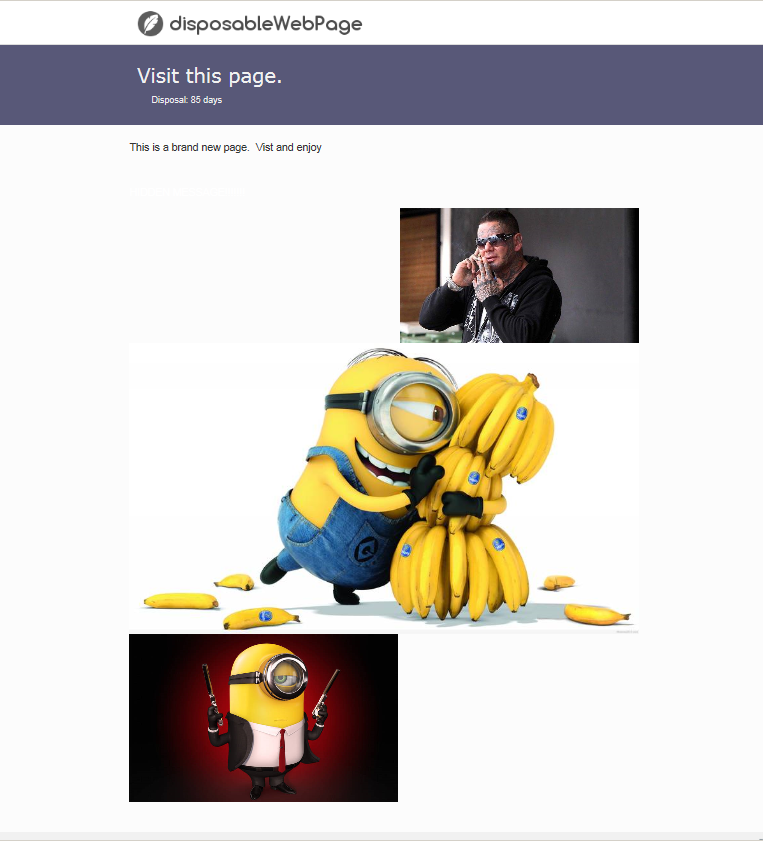
A test web page was created for web browsing (Fig. 3). This allowed control of the content on the page. The purpose of the testing focused on what images would be stored in the cache. The purpose of Minion images used in this research was mainly used because of their bright color and distinct characteristics which assisted in analyzing numerous image files.
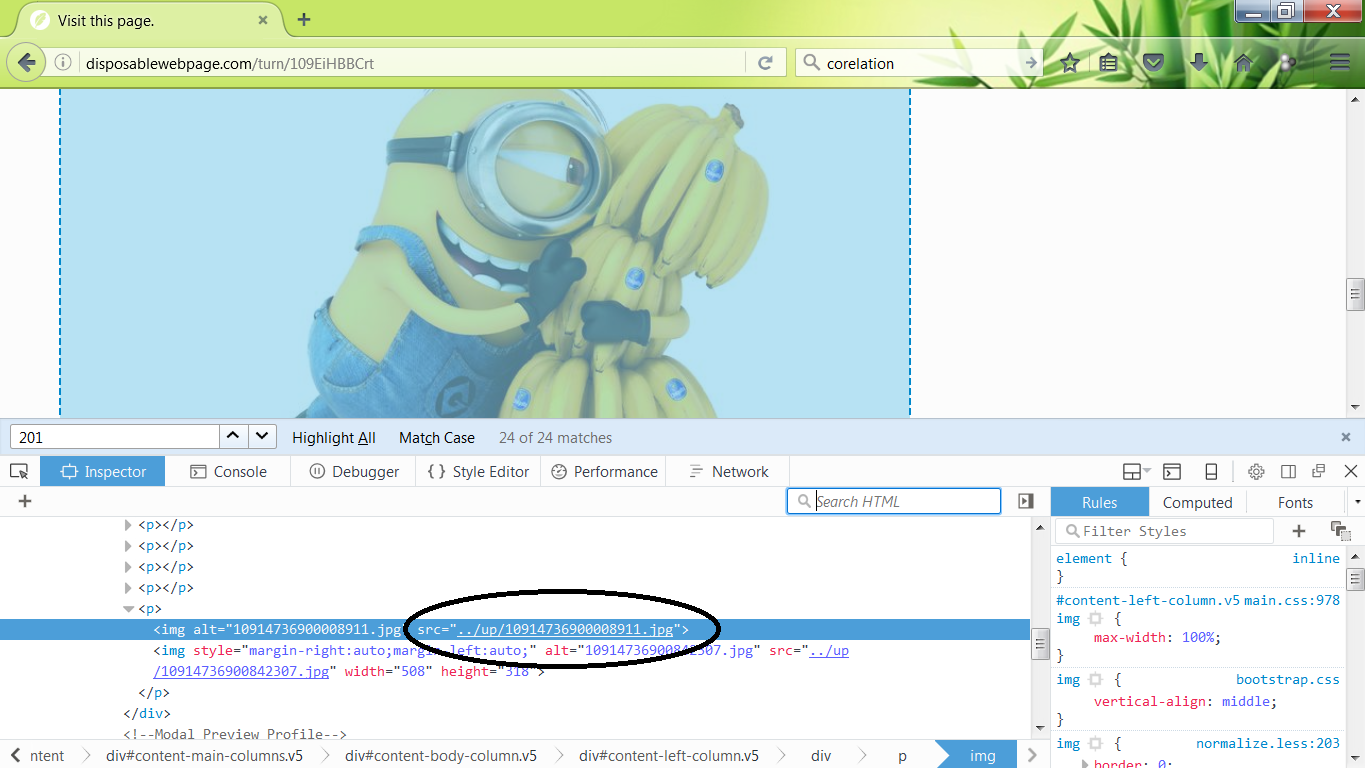
The mobile device was then connected to the Internet via a Wi-Fi connection. The sbrowser (Fig. 4) was opened. The home page was Google.com. The URL of the test web page was typed in, and the sbrowser displayed the web page. At that time no further browsing was done.
The same procedure was then done on the device to acquire a physical image (Appendix C). The second physical image was placed into Cellebrite’s Physical Analyzer 5 (PA5). It should be noted here a physical acquisition will likely extract the Cache folder. It has been experienced by the testers that a logical or file system extraction will not extract the Cache folder contents.
After the second physical extraction the mobile device was turned back on and reconnected to the Internet. A revisit to the test web page was done. Prior to returning to this test web page, it was edited (Fig. 5). The image of the tattooed man smoking and talking on a mobile device was changed to another minion. A third physical image (Appendix D) was done using the same acquisition procedure.
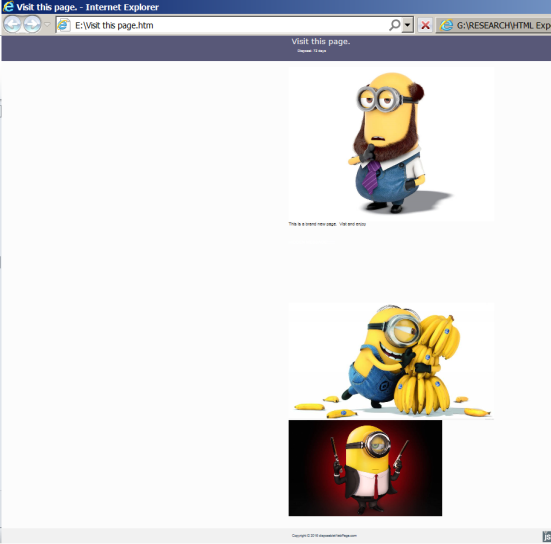
Findings
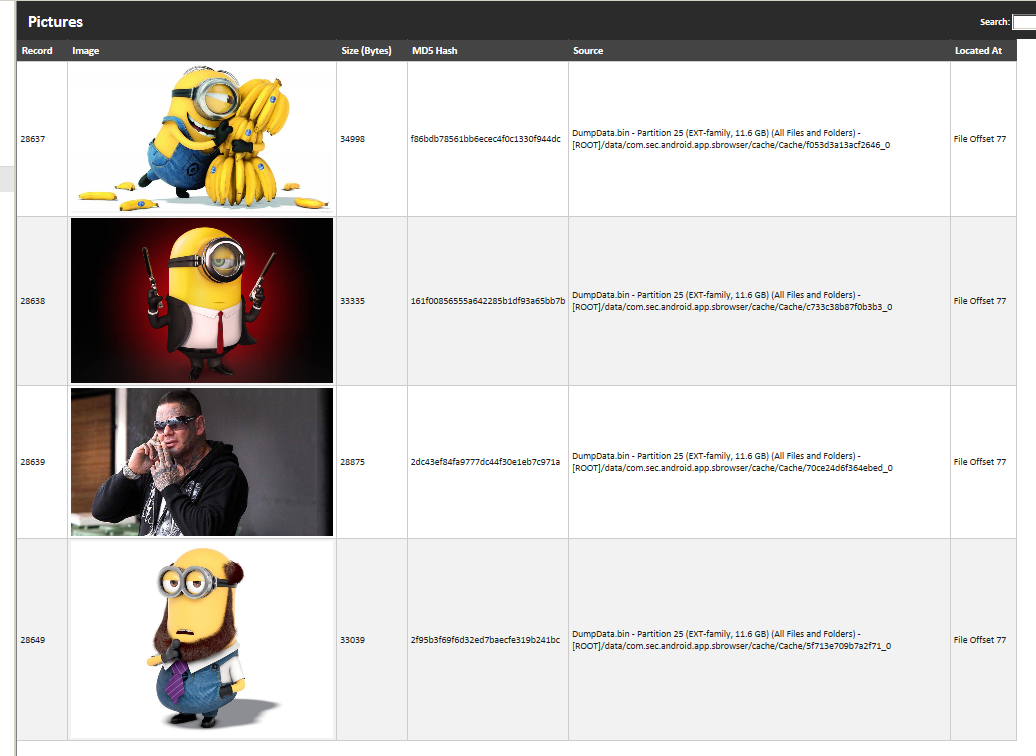
There were notable artifacts located in the Cache Folder. The full path to the cached images was /Root/data/com.sec.android.app.sbrowser/cache/Cache/. The web page images are embedded in a cache file located in the folder. The carved web page image file name has hexadecimal characters and is 16 characters long and ends with “_0”. This is how Cellebrite’s PA5 automatically carved the image out and named it. The images from the cache were bookmarked (Fig. 6).
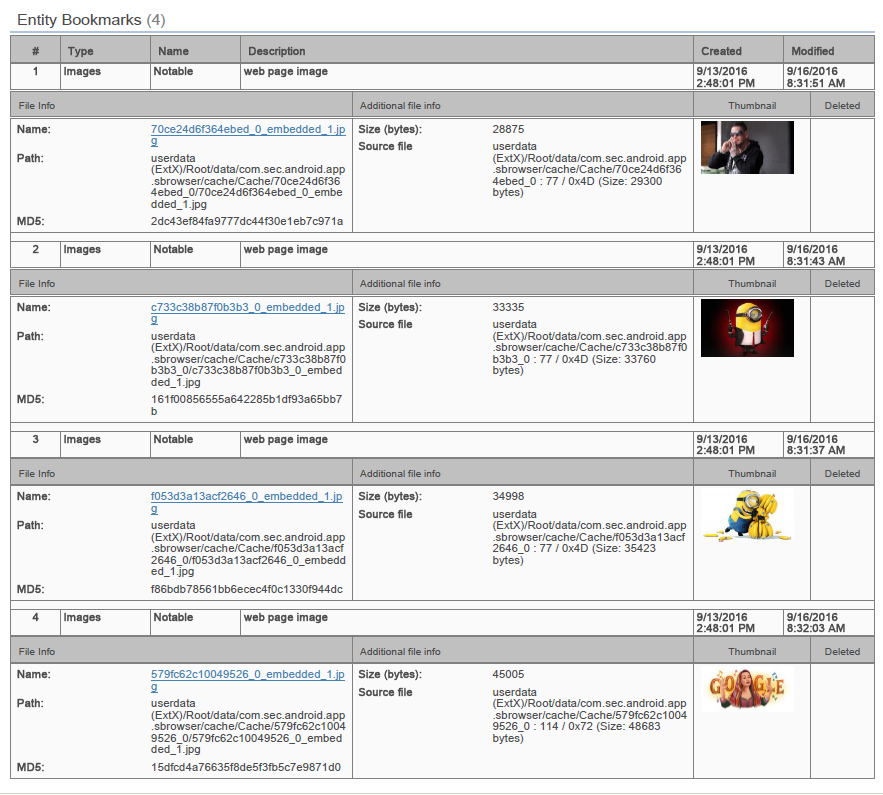
The cache file does contain additional information. It contains the URL of where the web page image came from. This URL actually points to the original image that is used to build a webpage. This URL is located at the File Offset (FO) 24 (0x18). This seems to be consistent with all the cache files examined. The first (FO 0x0) 9 bytes of the cache files had the same header. At FO 12 (0xC) for at least 2 bytes or possible 4 bytes the hexadecimal in little endian will give the length of the URL. At FO 16 (0x10) for a length of 4 bytes is a value. This value at first was thought to be a date and time value. Using tools DCode v4.02a and RevEnge v1.0.34 to try and find a date and time value were unsuccessful. It was thought that these bytes may be in reference to the size of the embedded image. The values or combination of the values did not add up to the size. After the embedded image there is additional information (discussed later) that has server connection information. The value of the 4 bytes or a combination of values did not match the location of the end information. Also, the values did not add up to the length of the file. Below is the .jpg of the minion holding bananas in hex view (Fig. 7). The header, size of URL, URL, and the .jpg header can all be seen. Note the URL in the web page cache file is similar to the URL in Fig. 3.
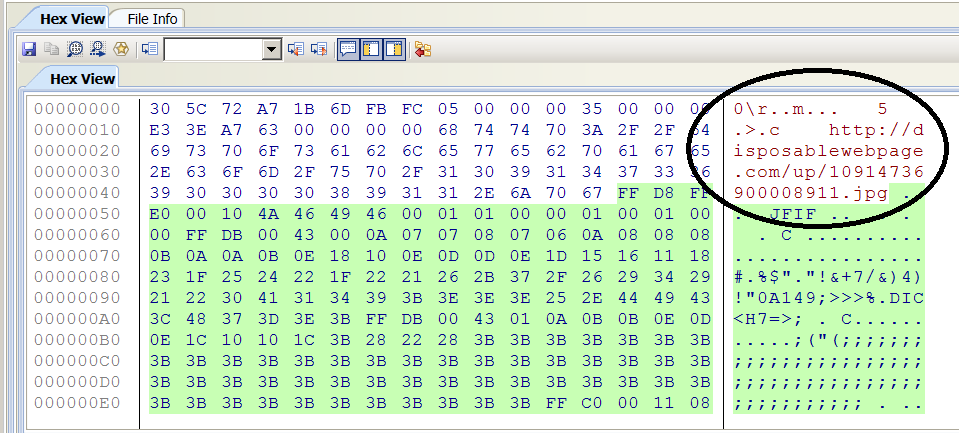
Fig. 8 shows the end of the cache file has additional information. This begins after the end of the embedded image. There is a server response that the request has succeeded (HTTP/1.1 200 OK), and the date and time. 8 bytes before HTTP/1.1 200 OK is a 3 byte long value, in this case 0xFC 9A 2E. This value somehow is connected to “the-real-index”. The browser appears not to store simple cache index data in the index file. Chromium uses a similar indexing. As explained by the Chromium Org, the “index” is extremely static, and the actual index data should be stored in a file called “the-real-index”[7]. It was observed that sbrowser has an “index” file that is small in bytes, but has a larger “the-real-index” file. The 3 byte value discussed earlier was a constant in “the-real-index”. In further testing an additional 3 byte value appeared during another web browsing session. The 3 byte values appear to connect web browsing sessions with the cache file, and “the-real-index”. The name of the server is also provided. The last modified date and time listed is of the actual image for the web page.
The actual cache file has its own date and time created, modified, and access. When the cache file is created on the device it will coincide with the time visiting that page.
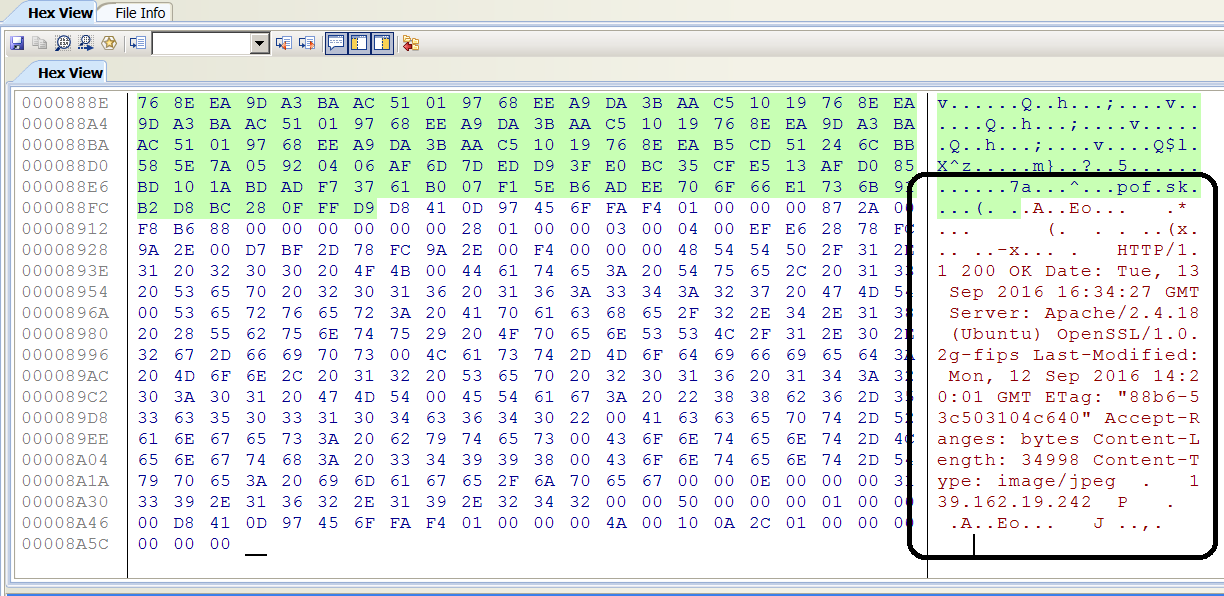
The web history from the first physical extraction shows the last time a user visited a website (Fig 9). It should be noted that the time of the last visit is 09/13/2016 11:34:26 (UTC-5), and the server date and time above (Fig. 8) shows 09/13/2016 16:34:27 (GMT). The date and times are the same with consideration to the time zones.
The third acquisition was analyzed again in Cellebrite’s Physical Analyzer. The image of the new minion (5f713e709b7a2f71_0) was created in the cache and that cache file’s creation, modified, and last accessed coincide with the time the page was visited. The other two minion web page image cache files f053d3a13acf2646_0 & c733c38b87f0b3b3_0 (Fig. 10) last modified date and times changed. The last modified date and time changed to the time that corresponds with the time the test web page was revisited. However the date created and last access stayed the same. The file itself did not change though. The MD5 Hash value of the file from both physical extractions remained the same. The minion web page image cache file that was no longer on the test web page dates and times stayed the same.
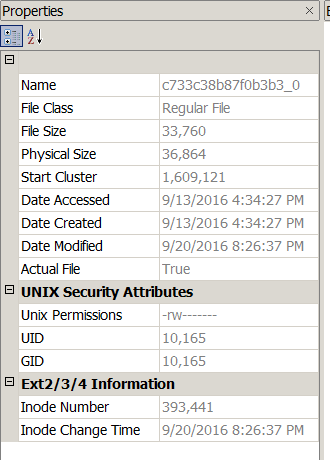
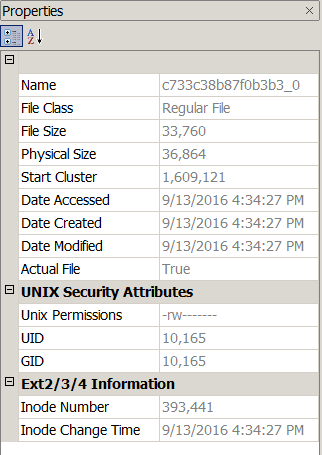
FTK v3.3.0.0 Imager used to display properties of the file below from the second and third physical extractions. The MD5 Hash value for both files was 809316767a22d168fefbadc92dcedcc8.
Internet Evidence Finder (IEF v6.8.2.3062) was also used on the third physical extraction. This was mainly used to verify the images. IEF did report the file the web page image was at. IEF did display the image. When it was viewed in hex view the entire cache file is viewed and not just the embedded image. Just like Physical Analyzer, there is no reference in the report to the image’s resource URL.

Conclusions
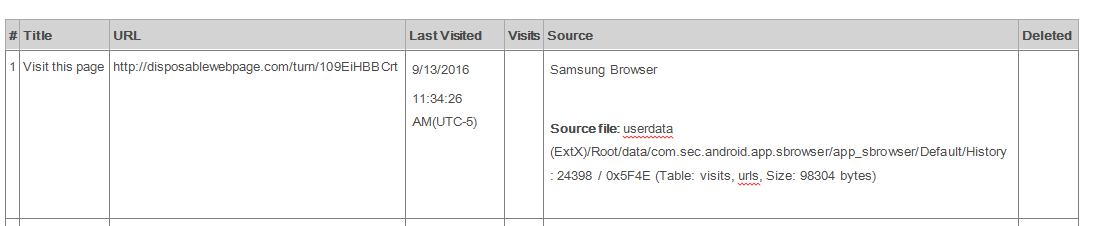
A controlled web page was used to add cache contents to the mobile device. The first (base) physical extraction showed the Cache folder to be empty. The mobile device after visiting the test webpage populated the Cache folder with web page cache files. There was a source URL for an embedded image within the web page cache file. We know the date and time when we visited the web page from the Internet History. Cookies also showed the date and times of visits to the test page. These Cookies will show session times and first visits also. Date and times coincided with the web page cache file and the domain name of the URL within Internet History. The URL in the web page cache file had the same domain name as the web page as visited. There is a strong correlation between the cached image file and the web page visited in the Internet History. It is likely that a user could have viewed the cached image while visiting the specific web page that has the same domain name as part of the URL. In testing “http://disposablewebpage.com /turn/109EiHBBCrt” was the specific webpage. The cached images made reference in the source URL to “http://disposablewebpage.com/”. There is a relationship with the domain. However, the specific webpage of the source URL in the web page cache files was not referenced. So, in the test scenario if two different pages were used, it is possible that the source URL would have the same domain name in it, but not referenced to the exact webpage. Web pages will pull the resource from where the image is stored, either from cache or the server.
The images in the cache can be correlated to a web-site that was visited. The files give an indication that images found in the cache are the likely ones viewed while the user visited the specific website with the same domain name.
More research needs to be done on “the-real-index” and how it correlates with the cache files. This research focused on the embedded source URL and embedded web page cache image. Findings could show a user likely viewed the image stored in the cache file while visiting a web page at the time.
There are constants that do appear when within the cache. These constants come before and after the image in set locations. It is unknown if these constants change between devices or OS versions. These constants also appear in the deleted cache files which would indicate that there is cache information to be gained, if not already overwritten, in the unallocated space of a device that can be linked to a recovered image. Additional research needs to be completed in this area.
Reference List
[1] Spence, E. (2016, January 31). “Samsung Challenges Google as New Android Browser Beats Chrome”. http://www.forbes.com/sites/ewanspence/2016/01/31/samsung-android-browser-v4-html5/#12f1ed7e45ce. [2] Samsung. (2016, March 21). http://developer.samsung.com/technical-doc/view.do?v=T000000202. [3] Victor H. (2015, May 25). “Top 10 Smartphone makers in Q1: Sony and Microsoft Drop Out of Picture, Chinese Phone Makers Take Over.” http://www.phonearena.com/news/Top-10-smartphone-makers-in-Q1-2015-Sony-and-Microsoft-drop-out-of-the-picture-Chinese-phone-makers-take-over_id69643 [4] Hoog, Andrew (2011). “Android Forensics Investigation, Analysis, and Mobile Security for Google Android”. Syngress, and Imprint of Elsevier. [5] Chandrakumar, F. (2014, June 2). “An evidence-based Android cache forensic model” [6] Martini; B., Do, Q.; Choo, K-K R (2015). Chapter 14- “Conceptual Evidence Collection and Analysis Methodology for Android Devices” In Ko R and Choo K-K R, editors, Cloud Security Ecosytem , pp. 285-307, Syngress, and Imprint of Elsevier. http://dx.doi.org/10.1016/B978-0-12-801595-7.00014-8. [7] [email protected] (2013, Apr 11). “Do not store simple cache index data in “index””. https://bugs.chromium.org/p/chromium/isses/detail?id=230332.Appendix
Authors
Robert Craig is a Detective with the Walworth County Sheriff’s Office in Elkhorn, WI. He has been involved in digital forensics since 2009. He obtained his EnCase Certified Examiner (EnCE) in 2009. He also received formal training on the Cellebrite software in 2013. While employed at the Sheriff’s Office and in training Robert has conducted hundreds of examinations of digital evidence such as mobile devices and hard drives. In 2016 he completed a MSc in Forensic Computing and Cyber Crime from University College Dublin, Dublin, Ireland.
Michael Lambert is a Detective with the Walworth County Sheriff’s Office in Elkhorn, WI. He has been involved in digital forensics since 2013. He received formal training on the Cellebrite software in 2013. While employed at the Sheriff’s Office and in training Michael has conducted hundreds of examinations of digital evidence such as mobile devices.





