
Hi, my name is Jens-Petter Sandvik and I’m a PhD student at Norwegian University of Science and Technology (NTNU for short). In addition to trying to finish a PhD, I’m working for the Norwegian police in the national cyber crime center. My co-authors are professor Katrin Franke at NTNU, Habtamu Abie at the Norwegian Computing Center and Andre Årnes at Telenor group.
This presentation is about a file system used in…operating system designed for IoT nodes called Contiki. (I have to apologize to all that came here for a presentation on the popular and vitally important drink by the same name.) The contributions of the paper are to investigate and disseminate forensic knowledge about the Coffee file system, to reconstruct and chronologically order the historical file versions, and to develop COFFOR, a tool for exporting data from the file system.
IoT forensics has gained a lot of attention in the last years with increase in network connected systems around us. IoT systems can include the most miniature medical implants and environmental sensors, to colossal serve farms, providing cloud services and industrial machines, and the infrastructure between these systems.
There is a wide span of operating systems, file systems and system architecture for IoT devices. A short and incomplete list is shown here. Linux and Linux-based operating systems are probably the most used operating systems, as they are readily available and can run on a considerable number of platforms. For file systems, the most used file systems are FAT and ext4 for the same reasons.

Contiki Next Generation (also called Contiki-NG) started as a fork of Contiki OS and is under active development. This is a version that we base our work on. The operating system is designed for resource constraint devices and the minimum requirements for running are 10 KB of random access memory and 100 KB of non-volatile memory.
One of the major advantages of using Contiki is that most IoT specific protocols are already implemented and readily available for developers such as 6LoWPAN, CoAP, MQTT and RPL. Unfortunately, the routing protocols for thread used in matter is not among the supported protocols. Contiki is used in the Thingsquare platform, but I’m not aware of any further commercial products currently using it.
Regardless of this, the Eclipse Foundation’s annual developer survey revealed that 5% of the IoT device developers had used Contiki for some projects. This can, of course, include testing and prototyping that don’t make it into a commercial product.
Cooja is a network simulator included with Contiki that can simulate a network of Contiki nodes. It does come with the gateway routers that can communicate with a virtual network on host. It is also easy to move the nodes around in the physical layout of the network. The firmware for the nodes can be compiled to run natively on the host architecture, or it can be compiled to the target architecture and run on emulated hardware.

We used an emulated sky device for our tests and load status messages to the window on the right side of the screen here – you can see there the coloured output. The rest of the screen on the right shows the simulation control in the upper left corner, a window for writing notes in the upper right corner, the network layout in the middle left window, and the timeline showing the nodes’ activity at the bottom.
The Coffee file system is designed for flash memory and the peculiarities of flash memory, and is designed for low resource usage. There are no centrally stored metadata for the file system, as we can find in other file systems. FAT has the file allocation table and TFS has the master file table, and ext file systems has the Superblock.
Coffee will instead scan the file system at boot time and build the metadata structures in RAM, similar to yet another flash file system. All metadata information needed for the file system is contained in the file headers. The file header, excluding the file name, is only 10 bytes, so there is not much space for metadata.
In memory, there is a pointer to the following free page, a list of the files with their offsets, and a list of active file descriptors with their read and write pointers. The file system metadata held in RAM is not written to disk. As a side note, there are a couple of advantages to this, as the consistency to the file system is easier to ensure. Data that is not there can’t be corrupted. It also removes the needs for some writes to the file system. There is only the root folder in the file system and the file names are the unique IDs used for accessing the files.

The Coffee file system consists of sectors and each sector includes a number of pages. The pages are the smallest writeable unit in the file system, which means that any byte written to a page will trigger a whole page write. In the system we were using, the flash consisted of 16 sectors and each sector consisted of 256 pages. Each page is 256 bytes.
A writing operation in flash can only flip bits from the value one to zero. This is called “programming” in flash terminology. It should be noted that Coffee uses inverted bits, so all bits are inverted when written to the flash memory. This means that setting a flag in the header from zero to one will be translated to flipping a bit from one to zero in the flash memory.
A whole sector must be reset to flip a bit back to one in the flash memory. This means that if the value in the file needs to be reverted to one, the value must be written to a new, unused page instead. A garbage collection routine will run when the file system needs to allocate more pages than is available in the file system, and erases as many sectors as possible.
In Coffee, the term “active page” means a page allocated to a currently existing version of a file. The term “obsolete page” means a page that has been active, but does not belong to an existing version of a file anymore. Obsolete pages are free to be garbage collected.
If a file extends into another sector and the first sector is erased, the file’s pages at the start of the then existing sector will be marked as “isolated pages”. These exist as file fragments without a final header, and will always be at the start of a sector. “Deleted page” is a term we used in the paper to mean either an obsolete or an isolated page. “Unused pages” are unallocated, erased pages where all bits are set to one.
This slide shows the header fields for files, the flags used in the header and an example of a file header at the bottom:

The header starts with a two-part field that points to the log file, if one exists. Note that this value is relative to the start of the file system, not a page’s physical address in a flash memory. In the sky mote, the file system starts at byte offset, 10,000 hex, or page offsets 100 hex of the flash memory. The following four bytes are number of records in the log file and the log record size if the defaults are not used. To be honest, I haven’t seen these fields been used in the files I have examined.
The next field is the number of allocated pages for the file. The actual file length is not recorded anywhere, but is found by searching for the first nominal byte from the end of the allocated area. This means that the file in the Coffee file system can’t end with a zero byte, and ending zero will be interpreted as a byte after the end of the file.
At last, there is a file name. For most architectures this is 16 bytes long. The file contents starts right after the header. At the bottom is an example of a deleted file with a log file. The flags fields say that it’s a valid or located obsolete and modified flag. Flags are set, which means that this file has been modified and deleted. The name of the file is file 003.txt.
The log file is found at the file system page offset 237, which means page offset hundred plus 237, which we see here as part of set 33700. At this location, the flags state that this is a log file. The name is the same as original file. The green marking is a log file header that lists the pages that are changed in the original file.
In this case, page number 5 is changed twice, followed by two changes to page number 3. After this header the pages are unchanged for the first 256 bytes is a new page that will override page number 5, the next 256 bytes will overwrite the same page. Then page number three will be overridden twice. The text file 3B#000 is the start of the new content.

When a file is created, it will allocate 17 pages for the file, unless the defaults have been changed when compiling the firmware. If the writing is appending to the file, that appended data is just written to the base file because it is the same data at the beginning of the file, so no need to flip any bits there. This means that there won’t be any log file attached to the file if data is only appended.
If the file size of the file increases to more than the allocated number of pages, a new file is allocated with twice the amount of allocated pages. This means that there is only a very limited set allocated files that is possible in the file system. Any other modifications lead to a log file being written.
The log file lists by default five pages and contains four records. A record is one page that will substitute the corresponding page in the base file. After all the records are used any subsequent modification will write the last version of the file to a new file and the modification triggering the new allocation will be written to the first record in a new log file.
The figure on the right side here shows that allocation. Along the horizontal axis is the number of modifications, and along the vertical axis is the page offset of the memory. The blue line is allocated area and we can see the dent in the step at the first modification that shows the creation of the log file. The red line shows the obsolete pages. The file exists between the blue and red lines.
When files are written and modified, most allocations are following right after the last allocated file. The exception is where there are not enough consecutive sectors to allocate the file. If there are more sectors later in the file system, the new allocation will start at the sector boundary for the next available sector. Otherwise, garbage collection is invoked to erase used sectors that do not contain any active pages.

One thing that sets this file system apart from other flash-aware file systems is that the garbage collection routine does not move active pages into new sectors to save more space. The active files will be where they were written. This has two noticeable effects. The deleted pages that reside in a sector with active pages will survive the garbage collection, and the file system can be full if there exists a moderate number of files in the file system. If one active file is in each sector, no more pages can be erased and any new allocation will fail.
The file system was tested by writing and deleting files, analyzing the resulting memory. We made a test for examining the files in the file system, for examining the log files, and for the garbage collection. The first test was reading and writing several files, appending data to file and deleting some files. We could then analyze the header and see that it behaved as anticipated, with one exception: an append did not leave any visible trace of the append operation. And the file looks just like it was created like that.
The log file writing showed that one write operation often caused two log file entries. One where about half of the changes were included, and the second with all the changes. This might be caused by a write before that was full and was written to disk. As mentioned, we also observed that the last version of a base and log file is copied to the new base file and the write triggering the creation or the new file was written to the log file.
We created files and deleted every second file after writing. When the end of the file system was reached, the next operation triggered a garbage collection, but the allocation failed as the garbage collection was not able to free up space in the file system. This showed that there was no reordering of pages during the garbage collection.

As the file system doesn’t move active pages to new sectors, old versions of files exist in a file system until a sector is erased. We know that files are written consecutively, so the diversion histories for the files in one sector are easy to reconstruct. The challenge is to establish the history of a file where the fragments are spread across several sectors.
These versions can be from different garbage collection runs and the sector can survive many garbage collection runs as long as one file in the sector is not modified very often. In our research, we considered two methods. The first was to analyze the file offset in a sector, and the other was to examine the file contents of the file versions. The two methods show some promise, but also have some limitations.
The file offset analysis is quite simple. As the sector size in general is not divisible by the file size, the first file in the second sector will not start at the sector boundary. We assume that the files are all the same length as files in a resource constraint device probably are kept small due to resource constraints.
We can generate a sequence of offsets the first file in a sector will have by the equation shown here. The idea is to find out-of-sequence sectors. These sectors indicate that there is a skip due to the writing skipping an active sector. The file offset in the first sector is always zero, as seen here with A0 = 0. And the remaining is given by the previous sector offset plus the sum of the file sizes successive writing will pass to the next sector.
As the body of this equation here…of the files that will overshoot into the next sector, starting at offset zero. The offset might give us the second file in the sector, hence the modular file size. It can be rewritten to take the start offset into account in the denominator of the fractional, but we didn’t do that in the paper.

To test the file offset analysis, a mote that wrote two files was created. The writing rates for the two files offset to 1 second per write and 100 second per write. These values were selected such that the files often were in different sectors. The firmware was also patched such that the allocation offsets were printed to the simulation log for each allocation.
The results were promising, but we soon detected the limitations to this method, as seen in the table to the right: 4 sectors remained at the end of the simulation run. These were sectors 0, 1, 6 and 13. The first file in sector 0 and 1 does show the expected file offset for two consecutive sectors: 0 and 8. Sector 6 also follows this correct sequence.
The list shown in the previous slide goes 0, 8, 16 to 10, 18 and 4, which seems to be correct, but the 6th sector did hold an earlier version than the ones in sector 0 and 1. This is because the file offset starts over at zero after a garbage collection, the same sequence of file offsets will be repeated for every sector, except for those skipped due to active sectors from earlier rounds.
There was another limitation that became apparent. Looking at sector 13 (or the INHEX in this table) adding even offsets shouldn’t result in an odd offset. The assumption of an invariable file size doesn’t hold. We observed that sometimes a base file of 17 pages was created, and instead of adding a log file, a new base file was created.
This means that the method can be used for detecting writes that have happened after a skipped page and decide whether there have been any file size changes. The reset to offset 0 for every garbage collection means that this is not a method that works particularly well in most cases. And we discussed this a little bit more in the paper.

The next method is focusing on the contents of the file as they are modified. The idea behind this is to use measures of difference between versions to find the probable version history. As the version history is consistent within a sector, the task is simplified to comparing the last version in one sector with the first version in another sector.
The assumption to this method is that files are gradually changing such that two versions of the file that are written with an extended time interval between them (or more precisely a considerable number of changes in between) are more different than files written with less number of changes in between.
A ring buffer is an example of a file that behaves like this as the content is already writing the oldest parts, thereby overwriting increasingly more of the original version. The method is not suitable where the same parts of the file are changing as the difference between the versions is also the same.
We considered two metrics for the difference between two files: the Levenstein distance (also known as edit distance) and Myers’ diff algorithm. The choice didn’t matter for our test files, as both would give similar results. But the Myers’ algorithm might be usable in more cases.
This is because the edit distance only reports the number of edits needed to go from one version to the other when scanning the file consecutively, while the Myers’ diff algorithm tries to find the longest common substring and the shortest edit script. We did not test the performance of one over the other, though.

For testing the file content analysis, we considered three types of file writing strategies. The first is similar to a ring buffer where the location of the write was increased by one for each modification. The second method was where a single value was changed at the exact location in the file. The last method was where the whole file changes for each write. The figure on the right reveals that only the history of the gradually changing file will be possible to order as a similarity measure is strictly decreasing.
This also means that ordering is not dependent on a number of writes between the versions, with one exception: when the whole file has been changed. And like when the write pointer has reached back to the point where it was in the original file, the similarity has become zero just as the case for the completely changing file.
Another interesting observation is that if the similarity changes as nicely as in our synthetic test, the number of writes between the two versions can also be estimated.
Contiki comes with a program for exporting the file system from a flash memory file containing the Coffee file system, but this program only exports active files and does not show any information about where in the file system the file has been found. Therefore, we made a tool to extract forensic information from a file called COFFOR, for Coffee Forensics.
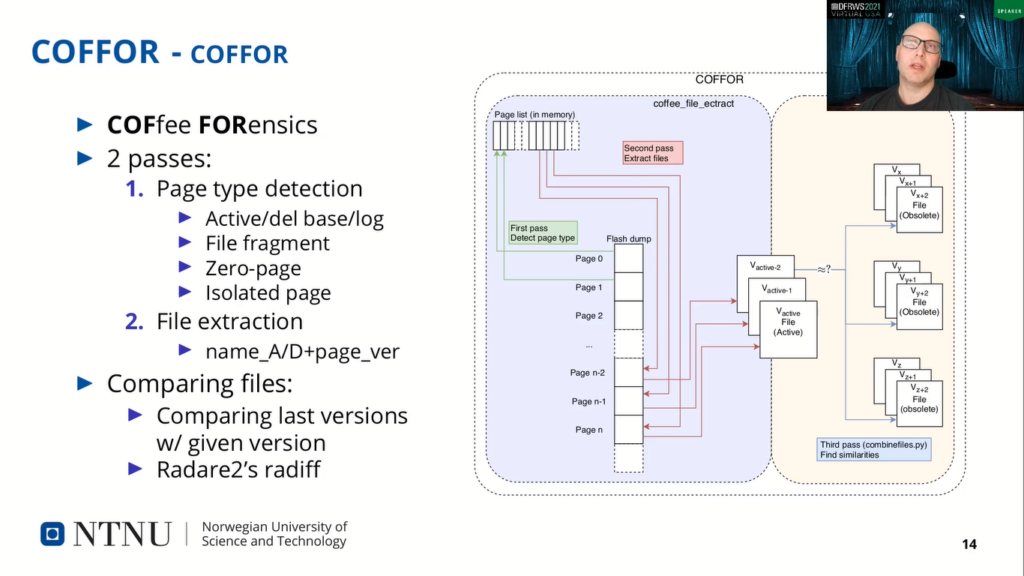
The tool consists of two programs.
- The first, called Coffee file extract, is a C program that will first analyze the pages of the flash memory image and categorise the pages, as shown in the green arrows on this figure.
- The next step is to export all files and the naming scheme is shown here in a table here…and that is the red arrows in the figure. And the filename is followed by underscore as a status of whether the file is active or deleted on the page number of the base file offset.
The last information is the version of the file. It is important to note that this tool will export each version of the file and not the log file itself. The last step is optional and is the comparison of file versions. The program is called combinefiles.py and is basically a short Python script to combine the given target file with all the SOAR files provided at the command line, call Radare2’s radiff on each set of two files and print the similarity between the files.
The COFFOR tool was able to classify all pages in the flash memory dumps we generated. Given the simplicity of the file system, I think there is not much room for special cases and unknown states.
The exported file version was also identical to expect output from the motes, except that one write operation generated two writes to disc, thereby creating two versions where the first only contained a part of the complete modification happening in that write operation. The tool was able to classify all pages in the flash memory dump, however, it should be tested in a wider variety of flash dumps and acquired images from physical systems.
The use of Radare2’s radiff program works well, but one or more version distance measures should be implemented in the program to eliminate the need for an external program package. With that said, we did not try to create missing file versions because the strictly decreasing file similarity with increasing version distance made it a trivial task. For the other file writing types, the method was clearly not going to work. So for a subset of files, it would work, but this should be better tested in real life.
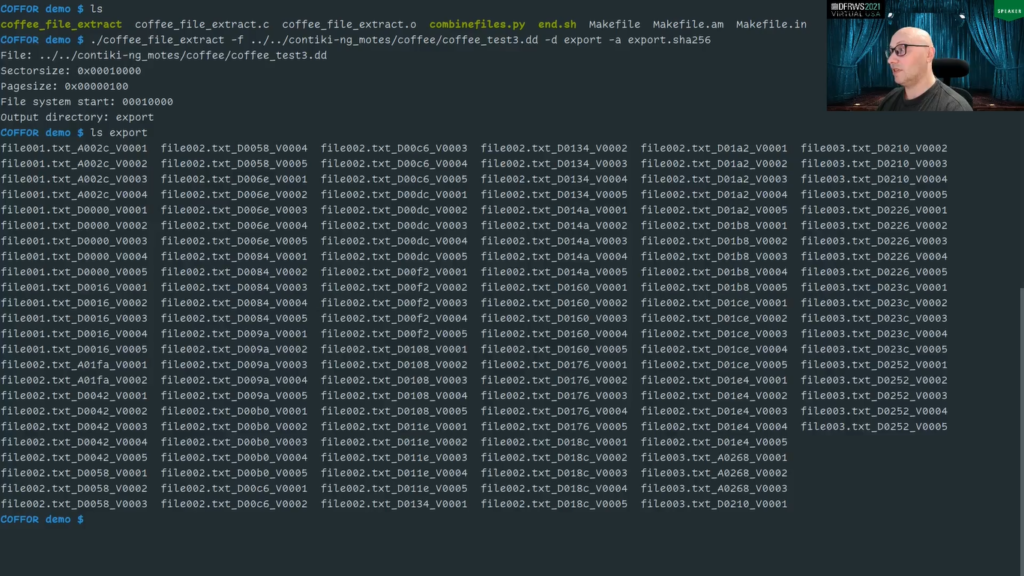
I can give a short demonstration of the COFFOR tool here now. We will see here…we are in a source directory of the COFFOR tool, and we will use the Coffee file extracts. We need a image file. Let’s use one from earlier. We need an export directory. Let’s just call that one export and we want to store the hash values in its own file. Let’s call up the export.sha256.
So then we have our files here and the hash file is also populated with hash values here. The hash values are calculated by the COFFOR tool in memory before it’s exported. So that means in order to ensure that the files has been written correctly, and/or that they haven’t been manipulated afterwards, we can use the sha256…sum program with -c to ensure that. We see here, all the hash values of all files matches.
And then we can use the combinefiles script in order to find the similarities between the files. We use the file 002. I want to have that first version of the active files and I will compare it with all the last versions from the deleted files. So, use the same file name and we want the deleted file, all locations and the version 0005 (that is the last version in each base log file version there).
So here we see, everything comes out quite fast. This is the file location as given in filename, and this is the similarity, and this is the edit distance, or the distance from the original file to the tested file. And here we see one that is the same, that is because the last version is copied to the new base file, and so of course this one will be correct. We see also this is a gradually changing file, it lines up nice here. So, super cool, right?
The COFFOR tool and it can be found on my github page shown here. It is released under GPL3. So that concludes my presentation. Thank you for your attention.





