Mark: Okay. Good afternoon. Welcome to the next full paper session. We have three papers for you in this session on forensic methods. So, Janine will start shortly with a paper on evidence tampering, we have a paper on forensic image generation, and we have our last paper on document similarity matching. So it should be a good session. Thank you for joining us and Janine, you can take it away.
Janine: Okay, I hope everything will work fine. Let me test something. Oh, great. Just as expected: doesn’t work. Okay, anyway, welcome to my presentation about digital evidence tampering or about studying digital evidence tampering.
As Mark already said, my name is Jane Schneider and I’m at the IT Security Infrastructures Lab at the Friedrich-Alexander University Erlangen-Nürnberg. And yeah, let’s have a look at why we should care about digital evidence tampering.
Yeah, should we care about this? Is it a real thing? Are there cases where digital evidence was actually tampered with or is it just an academic scenario? And of course, one can ask, is it possible to tamper the digital evidence? Because it’s usually protected against manipulation by hashes, checksums, even blockchain, and yeah, why should we care?
Okay, and we should care because there are actually real world cases where people tried to tamper with digital evidence. In the case of the U.S. v. Tucker and State [of Wisconsin] v. Mercer, the suspects tried to delete evidence and they did a pretty bad job and they did harm rather than good, but they tried it.
And there’s also a German case where text messages and emails were falsified. I cannot tell you any names because of the German legal system, but I was involved in the forensic analysis and they tried to actually tamper digital evidence so that the police would come to a wrong conclusion.
Okay, so therefore we at the FAU, we think that it’s important to study the nature of digital evidence tampering and to study how tampered data can be detected. And since we are interested in successful forgeries and how to detect them, we cannot study this in the real world because we wouldn’t be able to notice a good forgery.
So the best way we can study this is currently to conduct controlled experiments. And we did that in the past. We conducted three studies with seven experiments so far, and in our last study one of the experiments failed, so we had to repeat it, and the second try also failed. And we were wondering, “Why? Why could that happen? We put so much thought into these experiments.”
So, and therefore we revisited our past studies and experiments; we examined the different task descriptions, the participants; how the studies were conducted; we analyzed the factors influencing their experiments and their success; and we derived three lessons learned, which we want to share with you guys in case you want to do some experiments on evidence tampering in the future.
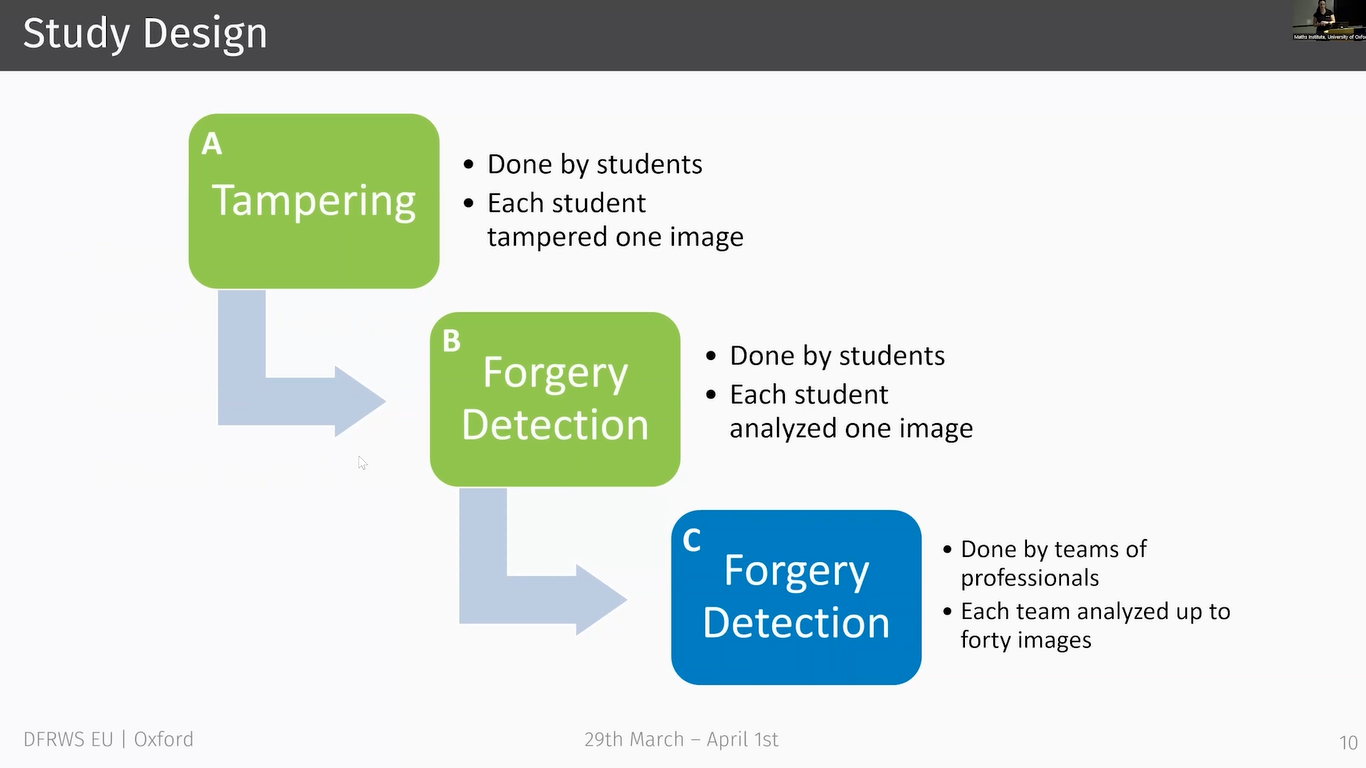
Okay, let’s have a look at past studies. And the first thing I want to show you is the studies’ design, and the study design was similar for all three studies we conducted.
There is always a tampering part and a detection part which is conducted with students. And this is depicted in green here. And in some studies, actually in two studies, we had an optional part C, which was only a detection experiment, but yes, I said it was only in two of the studies.
And in part A of the experiment, as I said, it’s done by students and they were given an image which they had to manipulate in such a way that the tampering task was fulfilled. And after the tampering, the forgeries created through part A, together with some unmanipulated images which we call originals are used to create an image pool.
And this image pool is used in part B of the experiment, and from this image pool, the participants of part B, they are given one or more images from the pool which they have to analyze and then decide whether it’s an original or a forgery.
And in part C it is done by teams of professionals which received a series of images and also had to decide on each image if it’s an original or forgery. And in every part of the experiment we recorded the experienced motivation and the time effort.
Okay, just to give you an example of how these tampering tasks look like, this is an actual tampering task from 2016, from the first experiment we’ve conducted. And actually I was a student at this time and participated in the experiment as a student.
So I know both sides. And let me tell you this, it’s fun on both sides as a student and as a researcher, it’s fun. This is another task from 2019. And the difference is maybe some of you recognized in 2016, the students had to add evidence in 2019 which we had to repeat, the students had to remove evidence.
Okay, this is a table which gives you an overview of the experiments we’ve conducted. The yellow ones are adding experiments and the green ones are removal experiments. And who of you did participate in the Forensic Rodeo, the DFRWS Forensic Rodeo in 2019 and or 2020, 2021?
Great, then you have been part of a digital evidence tampering experiment. These two experiments were DFRWS Forensic Rodeos. We tried to integrate these in our studies to improve or to increase the number of participants.
And as you can see here, is it working? Yeah, here, let me change this to pointer. We had 15 participating teams with 66 participants in 2019, and they analyzed 183 images, which is great. And we had 14 participating teams with 42 participants in 2021, and they analyzed 101 images. And as you can see, this is much more than the students could ever do.
Okay, let’s have a look at some data. I will show you some more plots after this slide, but just to explain the plot a little bit, you can see here one of the student experiments. Their plot depicts their forgeries, which were analyzed; their X axis shows you the tampering effort; the Y axis, the detection effort; their blue points are the forgeries, blue means that they were correctly classified as forgeries; if they are red, then they are incorrectly classified as originals; and the regression line gives you an idea of the trend, which we can see in the data.
Okay, and if we compare the data of the student experiments we’ve done so far, you can see that there is a trend in this experiment and this experiment. The first trend seems to be that it’s worth putting more effort in a forgery because with more tampering effort, their detection effort also increases.
But interestingly, we see an opposite trend in another experiment where they had to add main memory evidence. We can also see that we cannot really evaluate this experiment and that we cannot see any trend in these experiments.
And the two bottom experiments are the ones that failed. You can also see that the number of correctly classified images is much higher than the number of incorrectly classified images, and yeah.
This is another plot I want to show you. As before I will first explain the plot, and then we have a look at the comparison, and yeah, on the X axis, you can see the different experiments and the number of images classified as forgery or original.
On the Y axis, you can see the effort in minutes on the slides before it was also minutes, I forgot to mention that, I’m sorry. And the orange line is the average effort.
And on the left hand side, you can see the student experiments; on the right hand side, the Rodeo; and the plot actually shows you the analysis effort for all images, including originals.
Okay, this plot is assembled like a confusion matrix. And the first thing we can observe here is that the diagonal from top left to bottom right is more populated than the other diagonal. So it means that the participants were pretty successful in correctly identifying the images as originals and as forgeries.
So they not only correctly identified forgeries as forgeries, but also originals as originals. So there has to be something which can be used to identify non-manipulated images. And we can also see that the average effort for the Rodeo tends to be minutes or even seconds. And the effort for the students was much higher. It sometimes took many hours.
So, and this is because of the competitive nature of the Rodeo, of course, and also because it’s a team effort, so we cannot compare these two experiments at all. We can also see that there are many, many outliers in the Rodeo data, but also in their students’ experiments, there are some outliers.
Okay, since I want to tell you what we’ve learned from our experiments to improve them, I would like to talk about the problems we have incurred and the lessons learned we have derived from that.
So, the first thing we have to talk about is the participants, the number of participants, because participants in these kinds of experiments have to have a specialized knowledge, and recruiting experts is pretty difficult.
But also, recruiting students with specialized knowledge is difficult. So usually we try to recruit students from our forensic classes for the experiments, but as I said, their classes are usually pretty small. We had more students attending the classes and participating in the experiments in the last two studies or experiments, but the number was comparably small.
So we try to integrate the Rodeo, but as you saw, the evaluation of the data and the comparison is not that easy.
So, the first lesson learned that we can derive from that is that the number of participants will always be low, and we have to accept that. So, to try to increase the number of participants by integrating CTF contests isn’t that helpful. And instead, one can hand out more than one image, for example, yeah.
The second problem we observed is that not all task descriptions are pretty straightforward. So, in case you remember the task descriptions I showed you before at the beginning of the talk, some of you may have thought about how you would solve that task.
And if I would ask you how would you solve the task or how would you do it, we would probably have many different ideas and probably we would have some things we have to clarify, especially for the removal part, because you can ask some questions about removing evidence tasks.
Like, for example, would it be a successful forgery if I just wiped the disc? Or would it be in successful forgery if I just deleted the browser history? And in terms of the experiment, it would not be a good forgery because it’s actually pretty clear that it’s tampered with or manipulated.
But in the real world, you would probably just delete everything or try to delete it. And since our main focus is on undetectable forgeries, we have to clarify such things.
And there’s also another aspect which I want to mention here is the term ‘inconsistencies’. And this term is pretty difficult to define because to give you another example, is a timestamp that what was changed an inconsistency or is a timestamp changed because the system did something? Or is the absence of a particular file an inconsistency, or part of a garbage collection mechanism? So this isn’t trivial.
And this is the second lesson we’ve learned from that. An ambiguous task description can blow up your whole experiment. And this is why one of our experiments failed, actually. Therefore, if you conduct such experiments, you have to carefully consider the task, you have to consider the goal that you want to achieve, and yeah, you have to define the traces in terms of the traces of the manipulation in terms of the experiments and what is allowed and what is not allowed for the participants. And it really helps to carry out a small preliminary study. And even if that takes time, it will be worth it.
Okay. The last aspect I want to talk about is noisy data. So the two aspects we talked about so far led to difficulties in the data evaluation, but there’s also another aspect, and this is the different knowledge and motivation level of the participants, which can lead to inconclusive data.
And to give you an example again, a student with little forensic expertise and motivation may create a forgery that is then randomly given to an experienced student who recognizes the forgery rather quickly. How to evaluate that?
Or a very motivated student can create a forgery that is only roughly analyzed by a student with a lot of other courses and little time, maybe the student has a student job and the forgery is therefore incorrectly classified, but not because it’s a bad forgery, but because the analyst didn’t have the time to analyze it as well as the student may want to.
And this is the last lesson we’ve learned: noise and outliers caused by different knowledge and motivation levels can be avoided. For example, by selecting a set of good forgeries and especially the outliers can be kind of sorted out if you let these participants analyze the images at least twice.
And you can also assign students with similar skills and knowledge to groups and let them in their group analyze the images. And yeah, these countermeasures actually also help against the other problems we experienced.
Okay, to conclude this talk, studying digital evidence is in fact important because as we saw in the beginning, there are real cases. We have to deal with digital evidence tampering somehow, and conducting studies and experiments in this area isn’t trivial.
You have to be aware of the pitfalls of experiments in these areas, because there are a lot of domain-specific plot twists which are not foreseeable in most of the cases or in some cases and involve experts on empirical studies. And fun fact, we actually did this, but as I said, there are many domain-specific things like the task description.
And yeah, maybe if you keep our lessons learned in mind, you will do more successful experiments in the future. And yeah, that’s it. I hope it helps us and you in studying digital evidence tampering. And thank you very much for your attention.
Mark: Okay, Janine, thank you very much for your talk. I appreciate you referring to Rodeo participants as professionals. I don’t know how professional I’ve been in any Rodeo, but thank you very much for that.
We have time for some questions, if there are any questions online or in the room here? No, Okay. So, I had one sort of wondering. So, in terms of the motivation of students to find, to either plant, or tamper or to discover something that has been a forgery, would it be a good idea to explore the kind of idea of a red team and a blue team at similar skill levels, right?
So, you know, the professionals are doing the forgeries and also the ones, you know, kind of a competition that way. would that make sense to kind of overcome maybe some of those problems you mentioned?
Janine: Yeah, yeah, probably. Or maybe, I didn’t think about that yet, but if you have groups and they want to beat each other, be better than the other group, yeah, maybe it would help.
But the thing is, you have to be careful in adding some kind of time constraint or something like this. Just that the student experiment does not become a rodeo because the Rodeo data was really pretty hard to evaluate. So if they have enough time to do it as a competition, it would actually be a good idea to try.
Mark: Cool. Good stuff. Any other questions here then in the room or online? No? If not, please join me in thanking our speaker again. Thank you very much.
Janine: Thank you.