Hello to all of you. My name is Hemant Rathore and I’m here to present the work “Robust Malware Detection Models: Learning From Adversarial Attacks and Defenses.” The other authors of this paper are Adithya Samavedhi, Sanjay K Sahay, and Mohit Sewak. First of all, let me thank DFRWS USA 2021 for accepting this work and allowing me to present the work in the forum. So let’s start with our claim.
So we will first start with introduction, followed by literature review. Then we will talk about the research motivation and the proposed solution. Finally, we are going to discuss the experimental results, and conclude with conclusion. So let’s start with introduction.
So let’s start with the basic definition of malware. The term malware comes from the term known as malicious software. According to NIST, malicious software enters the computer system without users’ authorization and do some undesirable actions like stealing of confidential information, sending some spam SMSs, bringing down the servers, et cetera, et cetera. Malware includes viruses, worms, Trojans, ransomware, et cetera.
Initially malwares were developed to show one’s technical knowledge or skill, right? But now today it’s a profit driven industry. According to Forbes 2020 report cybercrime will cost around $10.5 trillion annually by 2025. Of course, these malware attack a computing platform.
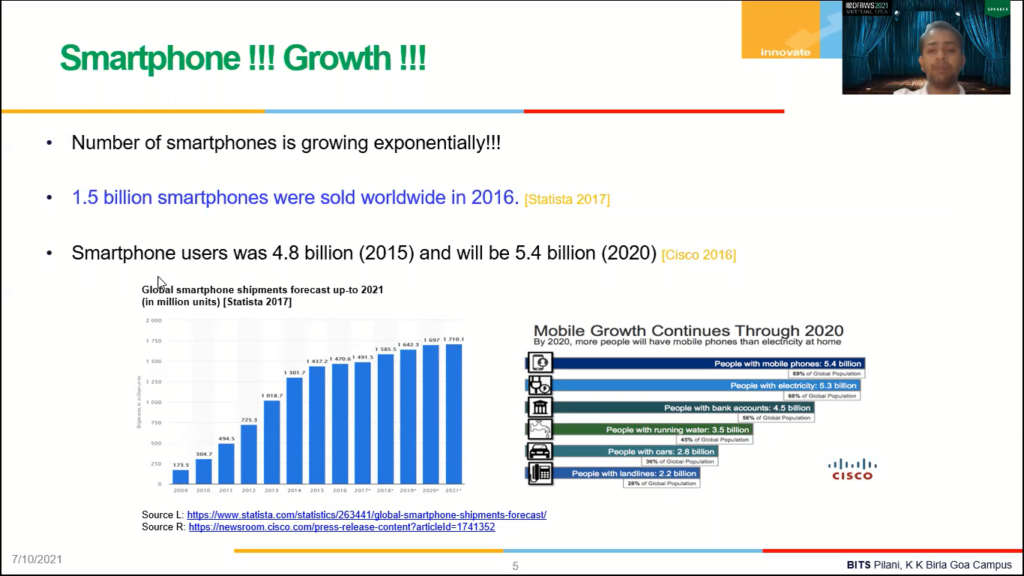
So let’s talk about the computing platform known as smartphones. The number of smartphones has been growing exponentially in the last decade, right? So here, the graph on the left hand side shows the number of smartphones shipped in the last decade. In 2009, the number of smartphones shipped were around 173 million. This number is expected to reach to 1,710 in 2020 – 21, right? The number of smartphones or mobile phones people are using today is around 5.4 billion, which is more than the people having, which is around 69% of the global population, which is more than the people having electricity, running water, bank accounts, cars, landlines, et cetera, et cetera, right?
So the number of smartphones has been growing exponentially and they have penetrated very deep into our pockets or our lives. Right, of course, these smart phones use operating system for resource management. If we look into the smartphone operating system market in 2009, it was pretty divided, right with shares like Blackberries, Symbian iOS, Android, et cetera, et cetera. But if you look today, it is having a duopoly of Android and iOS, with Android having a market share of around 85% and iOS is having a market share of around 15%, right? So that is why we choose Android smartphone for analysis in this paper.
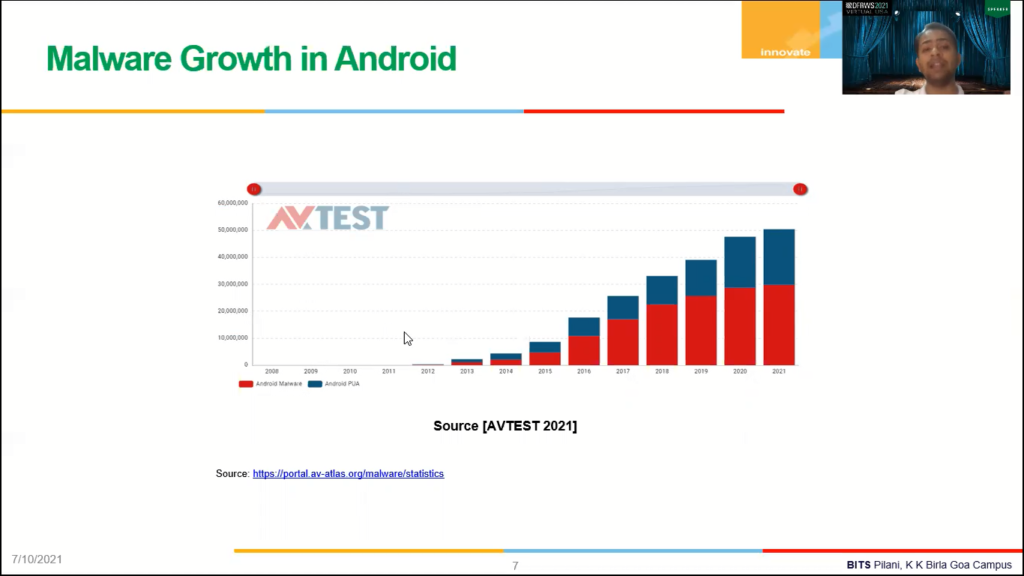
If you look into the number of malwares on Android platform, we see that there has been exponential growth in the last decade in this area as well, right? So in 2009, when the Android was just launched, there were a thousand malware found in that year, but this number is expected to reach around 50 lakh in 2021, right? So the growth has been growing, the growth of number of malware has been growing exponentially here, right? And that is why we are building Android malware detection system.
Right, so let’s talk about literature review already done in industry, right? So this figure talks about the malware and this is detection done by different researchers in this area, right? So malware detection system can be built based on that platform, right? It can be based built for Android, it can be built for Windows, it can be built for Alexa etc etc.
This detection system can also be based on different viruses, right? Or different malwares, that include viruses, worms, ransomware, et cetera, et cetera. I think that would be the types of malware, there are two types of malware, first generation and second generation, right? So if you look into the basic idea of designing the malware, it has two purposes. One is to attack a system. Second, secondly is to evade the detection process, right?
Now in first generation malware, right, there is a code to actually attack the system, but in second generation systems, second generation malware, there are two parts to the malware code. The first is to attack the system. And second is to evade the malware detection system. So if the research can be done based on with the help of encryption on polymorphism or metamorphism, et cetera, et cetera. To build a malware detection system, first, we have to analyse them.
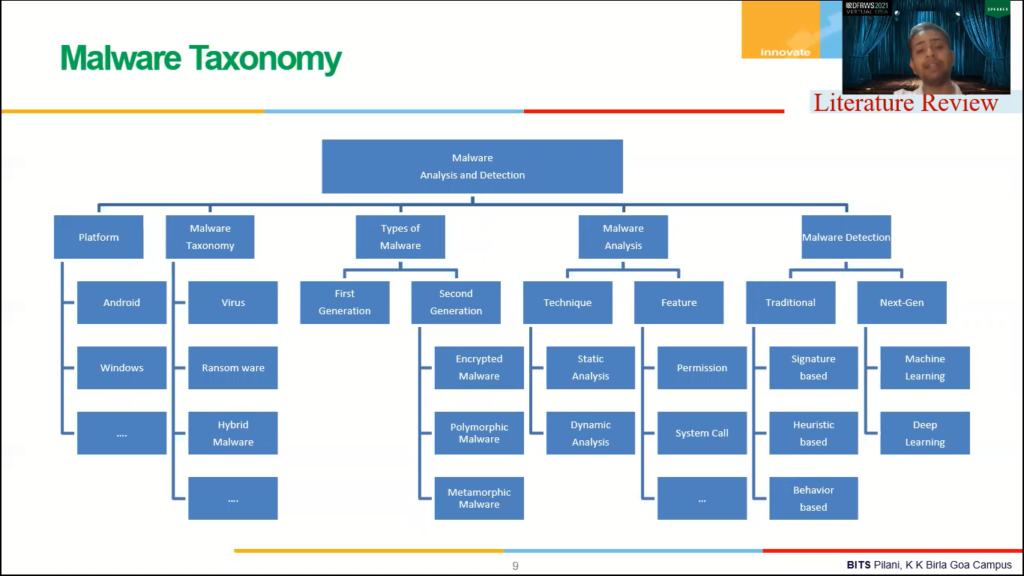
So there are two different techniques to analyse the malware. First one is called static analysis. The second one is called dynamic analysis. In static analysis any sample is actually analysed without executing it, right, without executing it. Different types of things, features that can help us in separating malicious and benign files. For example, some static features are like permissions, intent, we take pay calls in case of Android, right?
In case of dynamic analysis, all right, that sample is actually executed in a controlled environment to extract some features that can help us in separating malicious and benign files. Right? So an example of dynamic feature is called system code.
Right, now, if you look into different type of malware detection systems, traditionally, they was in, there are signature heuristics and behaviour based detection systems, but these systems are getting saturated. And now researchers are looking for, to build a next generation detection system based on machine learning and deep learning.
So this is what we are going to talk about in detail in this paper.
So as we already see, there are two types of malware, static malware and dynamic malware. Static malware are also for first-generation malware where malware structure remains fixed. In the case of dynamic malware, it is also for second generation malware where there is a code to actually do a malicious activity, plus a code, right, which evades the detection process.

So malware structure change again and again, to evade the detection process. So it can be done using encrypted malware or oligomorphic malware or polymorphic malware or metamorphic malware.
So how they can evade the detection process, they can use some obfuscation techniques. So there are very large number of obfuscations. Many obfuscation techniques can be used, a garbage, in such a garbage code, adding an equivalent instruction, adding that jump instruction, changing the flow of data flow, of control flow, compression, et cetera, et cetera right? So traditionally the malware detection systems are based on signature and heuristics, but now we are trying to use machine learning and deep learning to build the next generation malware detection system.
So let’s look into signature-based detection system. So signature-based method, use a unique string. We call it a hash? as that sometimes to identify the malware. Now, these signatures are often generated, disseminated and maintained by domain experts. So that means that it’s a highly human driven process according to who, the typical time window between malware release and its detection is around 54 days. And 15% of the samples are still getting undetected after 180 days, right?

So it’s a human written driven process. And since the number of malware has been growing exponentially, this process is actually very slow, right? In terms of building the signatures and deploying it on the user, on the client. Right now, malware can easily evade the signature detection technique by changing a small bit of code, a malicious code, right, without affecting the semantic of the code, right?
And the fundamental issue with this approach is it’s a reactive approach. That means that once the attack is done, then on the defensive we come. So that is why it’s a reactive approach. And it cannot save us from something called zero day at that.
Then we look into the second, the second technique, which is used very heavily today is called a heuristic based detection mechanism. Their domain experts will try to write rules and patterns to separate malicious and benign files.

The rules and patterns are written in such a fashion that they can detect a variant of the same malware family without raising false alarm. I mean, it’s a good approach. It’s a proactive approach, right? To which resource ignition is a reactive, of course, this is a proactive approach, but the fundamental problem here is it’s a human driven process. I mean, a human driven process, it needs a lot of domain knowledge and the most important problem is a lot of false alarms, right? So that is why there is a restricted amount of heuristic [inaudible] using today’s analysis.
And this is how our traditional detection system, it looks like: actually it has client and the server, right? The supply chain is typically a laptop and server and is on the anti virus side. The anti virus will scan internet to find, to find new malicious sample. Once they find it, they will try to generate a signature for it. That signature is stored in their database and it gets sent up on the hard laptops when we update our definitions, virus definitions, right? We do it every day, right? And once the virus definitions are updated, this when we run the scan, right? Each test file regenerates its own signature and that signature is matched with the signature that already there in the database, if there is a match, then there is then a crawler? and that file is essentially delivered or quarantined.
So this is how to date it is used. But of course, as we already discussed, that amount of malware has been doing its formation right? So that is one challenge the community’s facing. The other is the sophistication of malware. The third one is all the heuristic and statistical detection processes, right? So now people, researchers are back to use machine learning and deep learning to build malware detection systems.
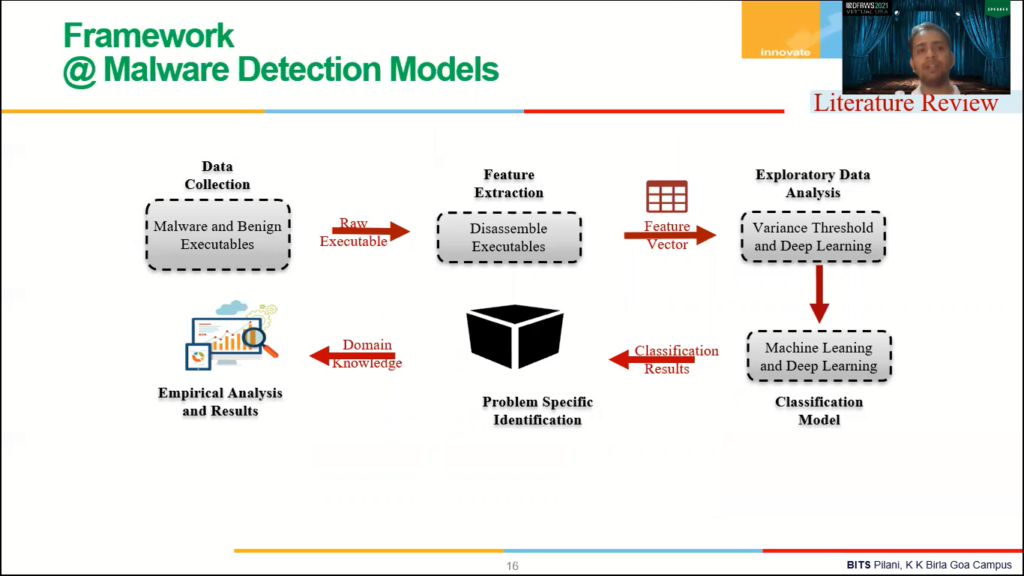
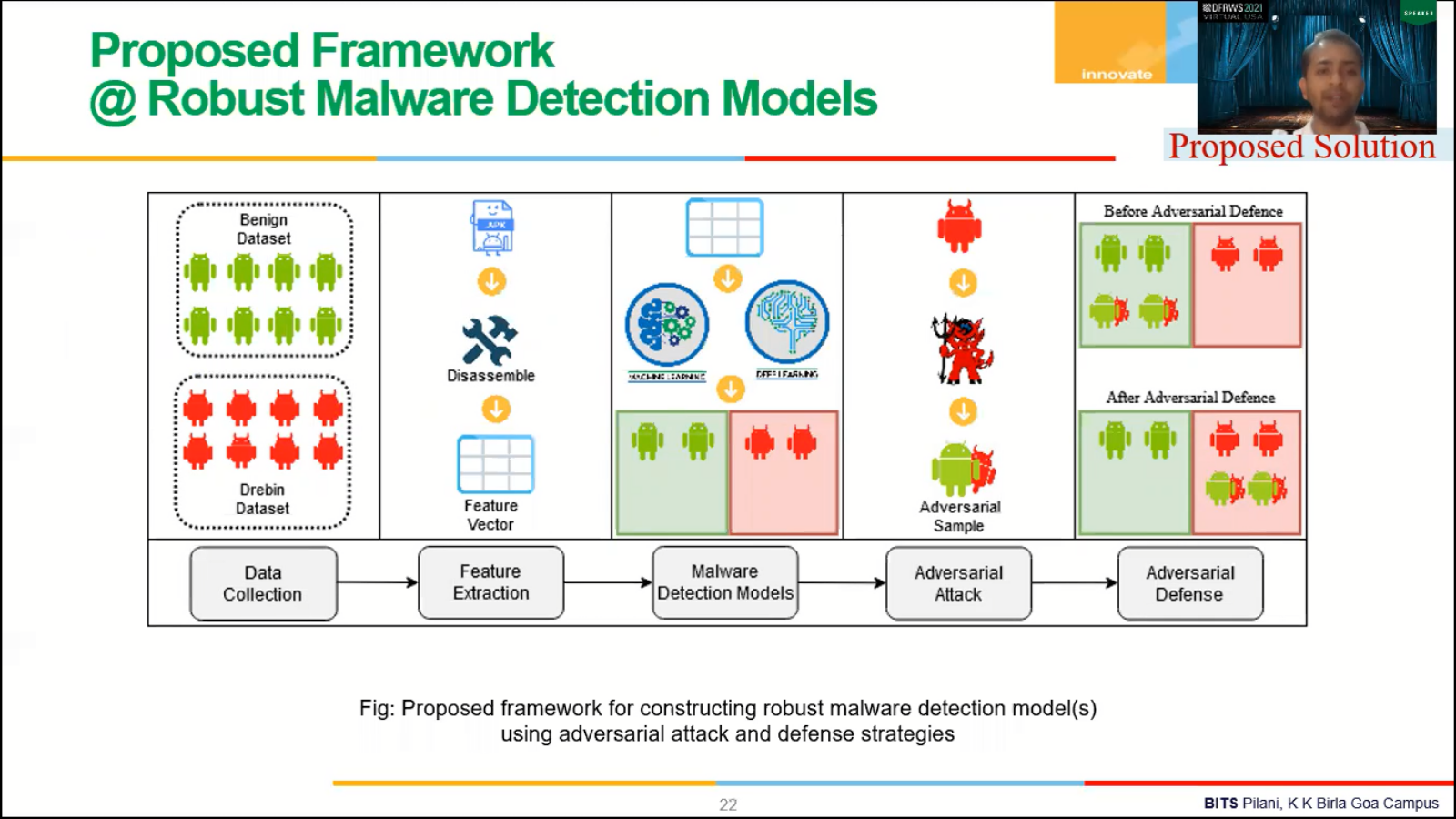
Now here we have proposed a framework to build a basic malware detection model using machine learning and deep learning. It is a five-step process. The first step is for a data collection where we try to collect the data, malicious and benign samples.
Once we have collected the data, then we will try to extract some features that will help us in separating malicious and benign files. Those features can be in case of Android can be permissions in dense CPA codes, right? And we can use what static or dynamic analysis or hybrid analysis to extract those features.
And once we have extracted those features, we can use EDA, which is exploratory data analysis, to understand the feature vector better. We can also use feature detection methods like variance threshold or BCA or deep learning like [inaudible], reduce the number of features and make more efficient models. Right?
Once we analysed the feature vector, then we are going to use various classification algorithm to build the classic malware detection model. Then we can use classification of what’s coming from basic classification algorithms, [inaudible], boosting base algorithms and part deep learning, basic deep learning algorithms, you can use any of those.
And then we can build a malware detection engine. Then be able to use test samples to evaluate the performance of the detection engine. And then once the performance has been evaluated, it’s going to be deployed on the customer.
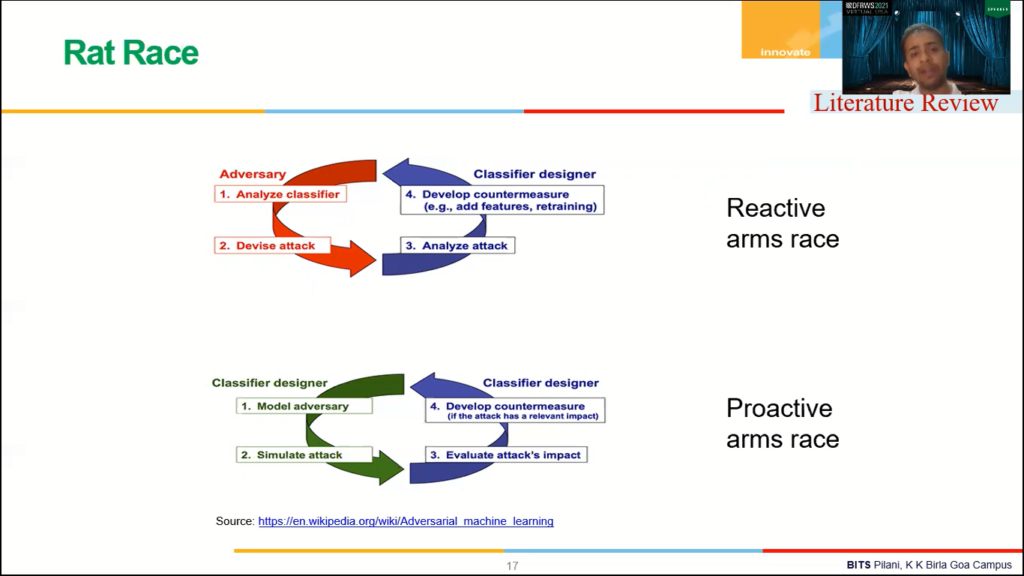
The problem here is, I mean, it is a rat race. That means that there are two players in this game. One is the antivirus type. The other one is called a malware designer. Now whenever a new system will come, the malware designer will try to do something to evade the detection process, which they have already done in signature and which they already done in heuristic based detection. Right? Second generation, first generation malware. Okay, if you use a malware detection model based on machine learning and deep learning the malware designer will do something to evade the detection process.
So it’s a rat race. The rat race can be of two forms. One is called reactive form. The other one is called proactive form. In reactive form, in reactive arms race, the bad guy will try to attack or make the attack that was the attack on the detection system. Once that attack has been done, then we are going to analyse that attack and try to come up with some countermeasures. This is called a reactive approach.
There can be a proactive approach where once we build a malware detection model, we will behave like a bad guy. We will behave like an adversary. We will behave like an antivirus malware designer and attack our own system. Once we attack our own system, then we can analyze the back up data and then we can come up with the countermeasures before the actual attack happens on this system. Right? So we can come up with the counter measures. So this is called proactive arms race, right? So here in this paper, we are actually getting to proactive arms race where we will behave like an adversary and attack our own system to find the vulnerabilities, and then propose a defense against those attacks.
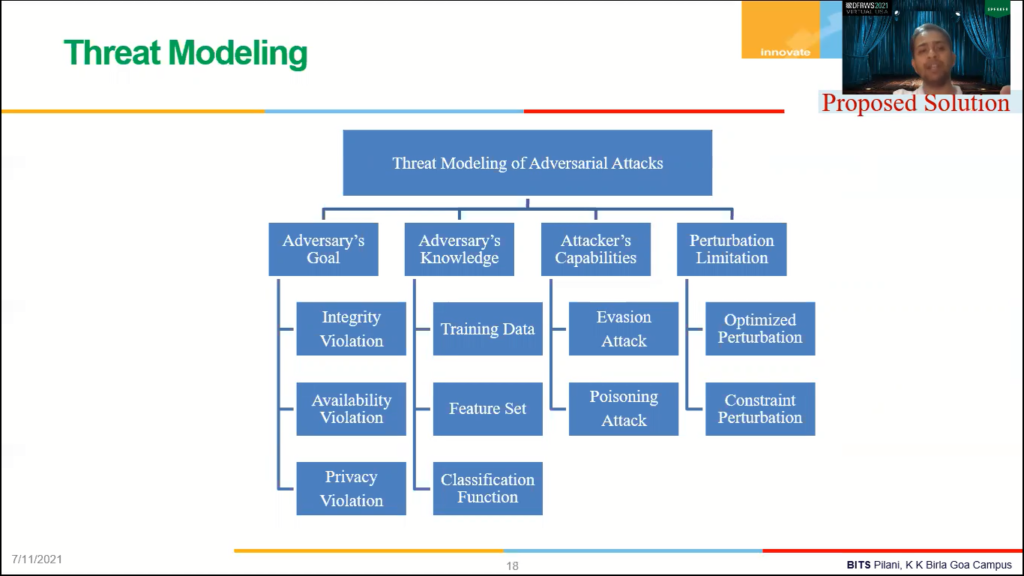
So the attack on these systems can be better understood with the help of threat modeling. Threat modeling can be defined based on adversaries’ goal, knowledge, capability, et cetera, et cetera. Adversary can attack based on integrity or availability or privacy, right? The attack can be based on the knowledge about training data, feature vector or [inaudible] The attack can be an evasion attack or poisoning attack, right?
So the research motivation of this paper is essentially according to Cohen it is impossible to develop one generic algorithm to detect all the possible malwares. And of course, signature and heuristic based detection and mechanisms are not good enough. So we are essentially looking into a rat race, right, where there are malware designers, they’re trying to come up with more and more malware, right? And they’re coming up with type of, trying to come up with this sophisticated malware. On the antivirus side, we are trying to prevent both old attacks and new attacks.
Right, so this is what we proposed a five step process to build adversarially robust malware detection process, right. For framework, right? So the first phase is essentially data collection. Then we are doing a feature extraction. Then we are building malware detection model. Then we are doing adversarial attack on the system then we are defending, right?
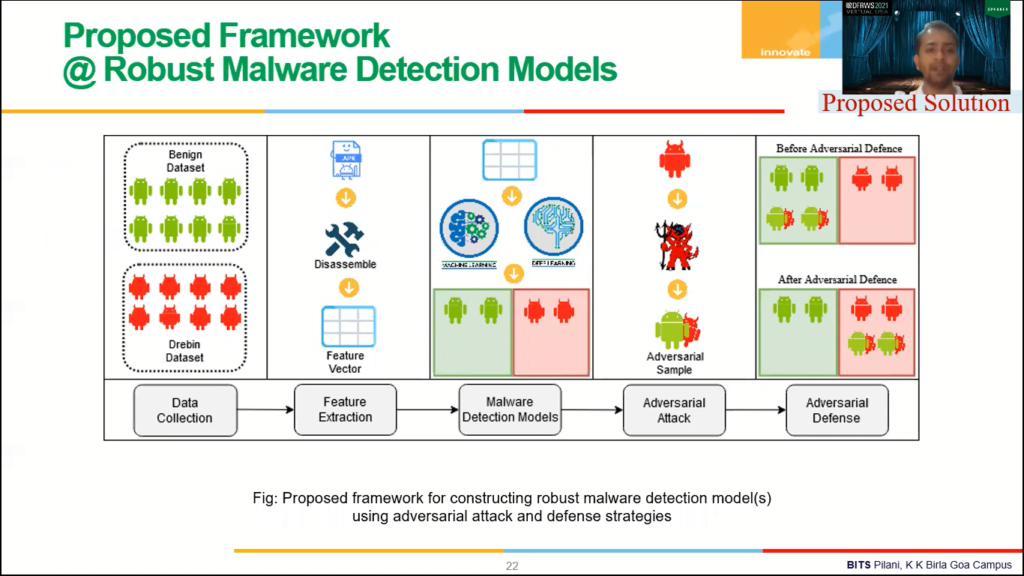
So here, the first two steps are essentially the same. So for, in data collection we collect benign and malicious samples, then in our paper, we have done feature extractions. We have done static analysis of Android application and extracted permission, Android permissions, and then write intent. And we have analysed both of them for a building a classification model, right? So once we have extracted features, right, that the feature extraction part is over, then we can use classification algorithm. So here we can use machine learning and deep learning models, algorithms to build a classification model.
So here red samples, which are malicious, are already in the red zone that is they’re classified correctly as malicious, and in green samples, which are benign, essentially are lying in the green zone, that means they’re currently classified as benign. Now, now we are, we will behave like an adversary and try to attack our own malware detection systems to find a vulnerability in them. Right?
So these malicious samples are modified in such a fashion using an agent so that they can evade the detection process. And this new sample is for adversarial sample, right. So these malicious samples are actually converted into adversarial samples and these adversarial samples are falsely misclassified as benign by their detection vector? Here, the fifth part of the graph on the right. And from the left-hand side, you can see benign samples are correctly classified as benign, malicious samples are collected, classified as malicious.
However, adversarial samples, which are malicious in nature, are falsely misclassified as benign by the malware detection engine. So this is before there were adversarial defense techniques. Our models are adversarily one driven. Right now, we want to propose a defense against it. Right. So, yeah, so, so that these adversarial samples are correctly classified as malicious by the detection. So we proposed this frame.
So again, I say we will behave like an adversary to attack our system. So we propose a GAAN based attack, where we are actually finding the gradient of the samples. And then we are actually attacking. So this is working to actually devise the adversarial sample, come from the malicious samples. So first we actually claimed the neural network ways that it does it. Then we will try to find gradients against all the features and based on the gradients, when we first saw the gradients, and then we will add the feature, having the highest gradient in the malicious sample, we convert that into adversarial sample.
So you can look into that available working for more detail. And if you want you can look into the paper, as well? So this, this GAAN attack is tested against different classification, where different classification algorithm coming from classical machine learning to bagging based algorithm to boosting based algorithm, to DNN based algorithms, right from decision tree to support vector machine, from random forest to ET, to bag SVC, from a gradient boosting to adaptive boosting, to eXtreme gradient boosting.
And we have four different DNNs with one layer, three layers, four layers, five layers, right? So we have analysed all the attacker bins?, all these malware detection model is built with all this elements, right? Of course, how do we measure the performance with the performance measure, like true positive, false positive, true negative and false negative, and we can derive accuracy of the percentage of the fooling rate based on that. So most of them you already know, but let’s talk about the fooling rate.
So the fooling rate actually talks about how many malicious samples we are actually able to convert into adversarial samples with the help of GAAN attack. Right? So how many benign samples are converted into adversarial sample using GAAN attack? That is essentially my fooling rate.
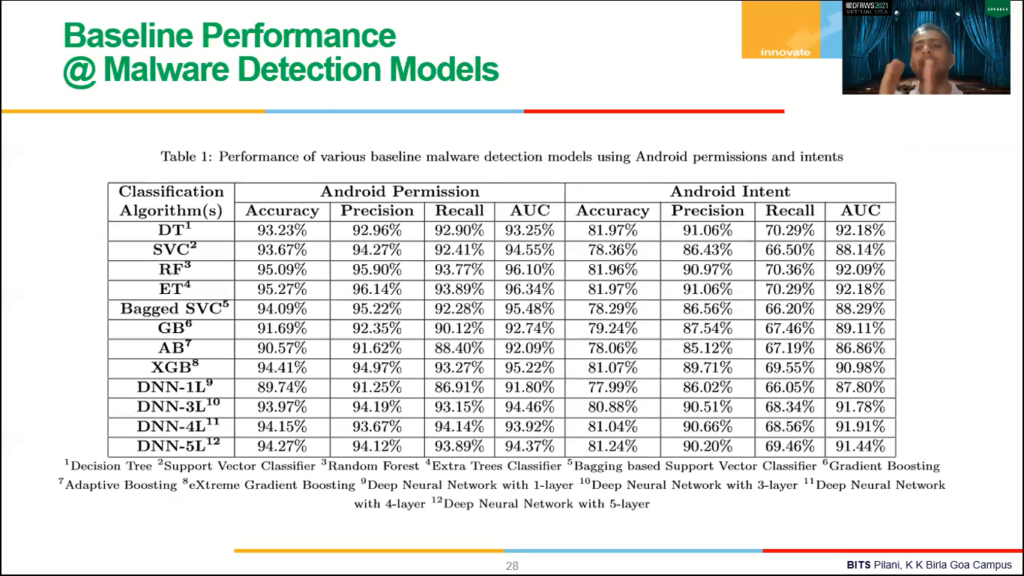
So let’s talk about the experimental results here. So, as I said, we have extracted two different features, Android permissions and Android index. We’ve used three different classification algorithms to build the malware detection models, so in all we have 12, 24 malware detection models. So like 12 for Android permissions and 12 for Android index.
So the first column is essentially talking about which classification algorithm is used to build attack malware detection system, right? So the second part is essentially the accuracy of the malware detection models using Android permissions. And the third column is essentially talking about accuracy of the model when the Android intent is used to build the classification system, to share the highest accuracy for that no permission is achieved by ET, extra trees, which is around 95%.
And the highest activity you see that is achieved by again ET which is around 96%. Android intents the highest accuracy achieved by random forest is around 81%, and AUC’s around 92%. Accuracy or within Android intents is less than the permission, but if you look into AUC, both of them are pretty balanced.
Once the malware integration models are built, then we are going to attack. We will behave like adversaries and attack our own system, right. Once we attack our own system with a GAAN attack, we will know that what is the performance with the help of something called fooling rate. So here you see the graph.
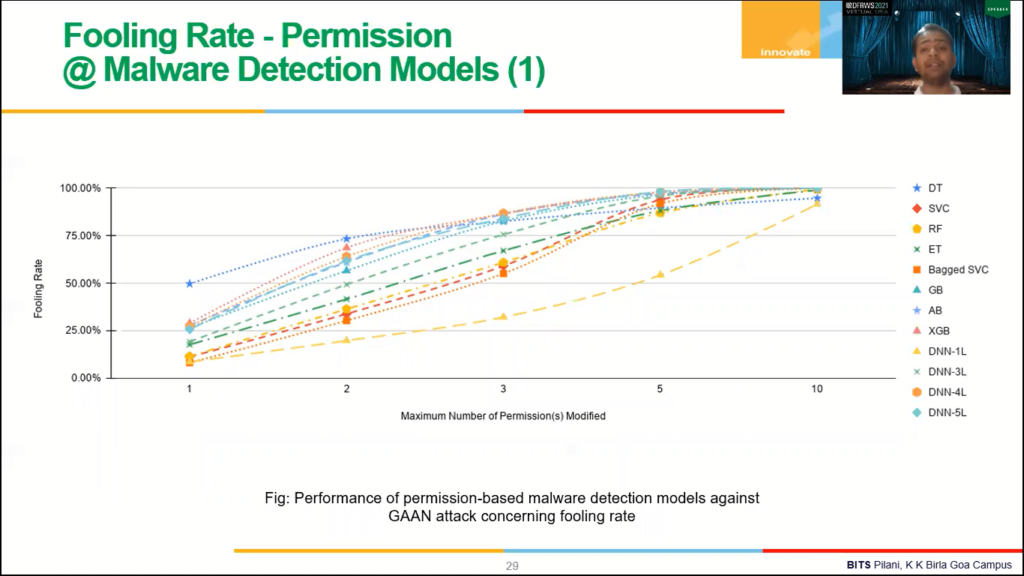
This is the fooling rate, when we use permission-based malware detection models, based on the GAAN attack, so the Y axis is essentially talking about the fooling rate and X axis is talking about how many modifications is done in each Android, each malicious sample. So if you do one modification, we are able to convert 25% of the malicious samples into adversarial samples that have been falsely misclassified as benign under [other] detection systems.
And if you do ten modification, you can convert all the malicious sample into adversarial sample, right, against any classification model built using 12 different classification Android intents? so we can you can fool any classification and right, this is what we want to prove, right? So that, that was so powerful.
Same experiment we do that with an Android index? and here also with one modification rate of around 25% and ten modifications, we were able to convert 95% of the samples and fool almost all the classification algorithms. And so this is the graph that shows up.
Right? We also try to find which permissions are, which intents are actually getting modified majority of the sample, times to convert into it adversarial samples. So we see here is the list of pending permissions that are getting modified maximum number of times, right? So we can see the limited number of permissions that are actually getting modified or getting added into that sample to convert into an adversarial sample. These graphs are essentially talking about which intent is getting modified the majority of their time.
So let’s talk about the defense. And once we have attacked the systems, let’s talk about the defense, right? So once we attack the system, right, the accuracy of the model which is around 95% with permissions, right, was reduced to around 50%, right, once we attack the system, right.
Now, we proposed three defenses, adversarial retraining, GAAN defense, and hybrid distribution. Now adversarial retraining retrains the model with the adversarial samples and correctly, but in GAAN defense we generated a sample using GAAN, and then hybrid distillation, used distillation coupled with adversarial retraining to, to make the difference.
So once we have built the first, we have built a basic classification model where we have achieved accuracy of around 95%. Then we attack our own system. Then when the accuracy was reduced to 50%, right here, you can see, which is the blue graph here. Then we actually use three types of defenses: adversarial retraining, GAAN, and hybrid distillation. And then we build the models, right? And then we re-attack the system. Once we re-attack the system, you can always see that the red, yellow, and green bar are always better than the, the first attack, right, which is the blue one, right? So we are saying that our models are adversarily superior once we actually applied their defense, right?
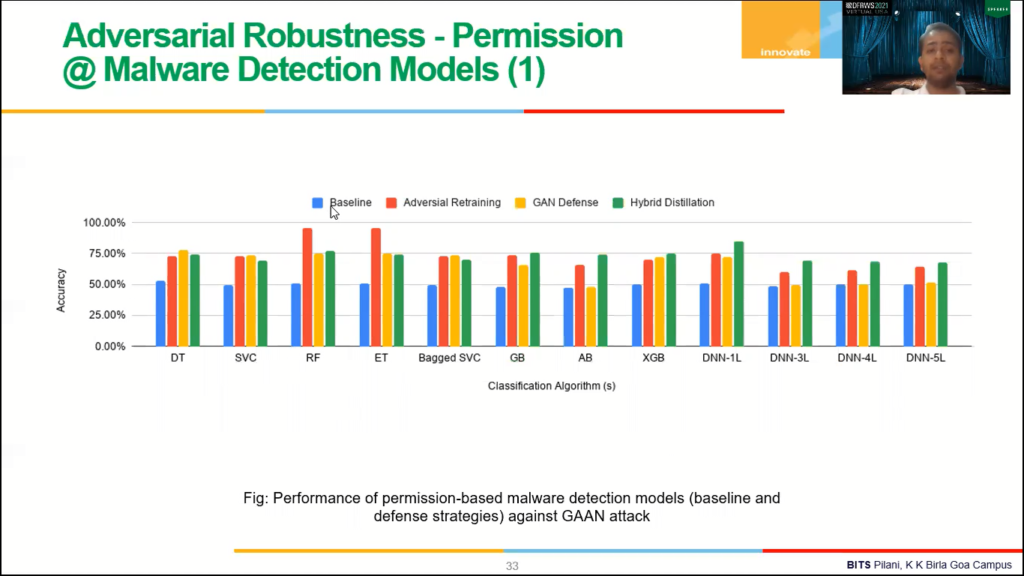
Again, we are getting some fooling rate, but we are adversarily superior. This happens, this gives me solver permissions ? and the same place we solved intents as well. Right? So after adversarial retraining or GAAN or hybrid distillation, the adversarial robustness of all these models, were improved, right, we saw this pattern across all the classification algorithms.
So finally to conclude that we have, what we have seen is a machine learning and deep learning can be used to build malware detection models, but these models might be vulnerable to adversarial attacks. So we behave, first behave like an adversary and propose a GAAN attack, which is an evasion attack with a gray box, right?
With a GAAN attack, we got a fooling rate up around 98% for permission with detection models, malware detection models, and for an average, around 90% with intent malware detection models. After applying the defense, we were able to improve diverse robustness, all other detection, models almost all the detection models.
So the future of work in this domain is around, we can look into the explainability of these attacks, right, and defenses. And the other part is about incremental learning of how we get implemented incremental learning in malware detection models, labelling is again an issue. So thank you all for listening to the presentation. If you have any queries, please drop me an email at @HemantRathore or [email protected]. Thank you all for listening. Take care. Bye.





