
Chris Hargreaves: Hello, my name is Chris Hargreaves. I’m here to talk to you about TraceGen which is a piece of work that we did last year on simulating user actions in order to create realistic digital forensic disk images.
So there’s a long quote here that I won’t read out just for the purpose of time, but basically it’s talking about the need for realistic data sets and the difficulty involved in creating them. There’s lots of reasons why we need test data and digital forensics: from education and training; for exercises and assessment; through to tool testing and validation; proficiency testing; showing that, kind of, staff are competent; malware analysis; and just generally in R&D, particularly, kind of, automated analysis, you’re going to want disk images that, kind of, are big, complicated and realistic, and those are very, very hard to produce.

There are a variety of data sets that exist. Digital Corpora are probably one of the most famous variety of disk images, mobile phone dumps, et cetera. NIST has some data. They also talk about the different types of data sets, as well: smaller ones for tool testing; but then the larger data sets that would be needed for, kind of, full investigative scenarios. There’s smaller data sets that now focus on, kind of, specific file types: SQLite in this case, which is very sensible given its ubiquity.
A good, sort of, central resource is this paper from 2017 from DFRWS USA. A review of 715 publications, about half of them had data sets, some were real, some were synthesized. But what’s interesting is only 3.8% of those that created new data sets were released. So all this work is going on, but the data sets aren’t actually being released.
So, looking at these two types of data sets, real and synthesized, if we think about the real data, there’s obviously massive problems with this. I mean, ethics are subjective, but you know, we’re talking about real data belonging to a real person here. Maybe they were convicted of a crime, maybe it’s fine to use their data, maybe it isn’t, this is the ethical discussion to have, but I think it is worth remembering that the data that comes from someone that’s convicted of a crime may have data associated with the victims. So these are innocent third party people whose data is embedded in that data set. And I think we have to remember that when we have those ethical discussions.
Some of those ethical discussions may have now transformed into legal discussions, actually. How personal data in the sorts of data sets that are affected by GDPR is probably a conversation that needs to be had, and personal data aside, there’s also copyright issues in terms of whether it’s, you know, actual multimedia content on disk images or actually the binaries that make up the OS software that’s on the disk images. But ethical and legal issues aside, there’s a more fundamental problem with real data sets in that we don’t actually have a known ground truth.

So, they’re obviously useful, but they are inherently limited. Nobody has stood over the person whilst they were using their system, doing their various actions and generating these artifacts. So they are limited in the sense of what we can do with them in terms of we are always going to be inferring what happened from the artifacts that are on the disk.
So there are some problems with real data. Let’s talk about synthetic data sets. I mean it’s a sensible idea to consider just injecting data into a disk image, it’s certainly something that’s been done. And for situations where it’s very content-based investigation, they’re just looking for files of interest that’s going to work, but injecting data for very complex event reconstruction scenarios, where you need to patch all of the registry keys and event logs is going to be almost impossible to do.
So that leads you on to manual creation of these disk images by doing the actual things. And therefore that’s a huge manual effort, even just to do the incriminating actions. And even if you do that, you’re going to end up with a lack of, kind of, background noise, and that’s going to mean that every action and every file that’s there is relevant. So you need to not just simulate the incriminating acts, but then a whole bunch of sort of, background stuff, as well, like random Google searches and browsing and news and making all the files that people make just in normal life.

So this is a massive challenge. So where does this lead us? This leads us to the point where real data is potentially problematic. Synthetic data is really hard to fake at a very detailed level and creating it manually is really time-consuming. So that leads us to the point where the solution seems to be, let’s not try and fake the data, let’s try and fake the user. And this is where we get to in terms of trying to simulate user actions, user interaction with a machine and allow the operating system and other software just to behave normally and generate the artifacts in the way that they normally do for a normal user. The only thing that we’re faking is the user input to the machine.
So, I mean, this is not a new idea, in a sense. More than 10 years ago we had Forensig2 doing a very similar thing. It was a Linux-based guess, a lot of command line only stuff. So it is a bit easier to automate things at the command line, but it isn’t going to give you the same richness as, not necessarily cause of the graphical interface, but there are more OS components that are capable of generating interesting data like Windows Desktop Search, and, you know, maintaining lists of recent files. All of these features that you implement in an OS require data to be stored to implement them, and those bits of data that are stored are the artifacts that we use to reconstruct user behavior.
So we also have Yannikos et al. from 2014, mostly file system-based artifacts. And we have Scanlon et al. from 2017, as well. This is the data injection approach I’ve been talking about, which is perfectly valid for a lot of scenarios, but I think it will hit limits at some point in terms of what’s feasible to realistically fake with manual artifact injection.

So that brings us on to TraceGen. So what are we trying to do? Automated approach to generating disk images for research, teaching or validation of digital forensic tools or techniques done by programmatically automating the actions of a user. And it needs to use the GUI of an operating system because many of these artifacts are OS level traces produced automatically in the background.
So, let’s talk about interacting with a virtual machine. There’s kind of two different things to simulate here. If you imagine it was a real system, a real user, they have a physical machine in front of them and there’s things that they can do to that: they can turn it on, they can pull the plug on it, they can connect or disconnect the network, unplug USB devices, et cetera. So, those external actions need to be recreated. And then you need to actually then simulate the user interaction with the actual software system, the interaction with the guest OS, creating files, internet browsing, et cetera.

So, in terms of that implementation of machine control that I described, well, actually this is where you kind of pull in the API of whatever virtualization infrastructure you’re using. So in our case, a virtual box. This is well-documented. And actually there’s quite a lot you can do here so that you can use vboxmanage essentially to tell a particular virtual machine to boot up, you can adjust the bias time, you can shut down the machine in a kind of uncontrolled way This is kind of what you’re going to be using: the API of whatever virtualization infrastructure for doing this sort of thing.
In terms of simulating the actual user actions, there’s kind of two options here: internal and external, essentially. The difference is whether you accept the fact that you’re going to run software internally on the virtual machine. So you can use vboxmanage to launch a program inside the VM by providing a username and password on the program to run, in this case, Notepad. But if you can run Notepad, then you could also run, let’s say a Python interpreter. And if you can run Python interpreter, you can run whatever script you want.

So you can use the entire library of, kind of, packages that you can get for Python: pywinauto, all sorts to control, manipulate Windows GUI. The problem is of course that Python and whatever requirements for the packages that you’re using need to be installed. So they are going to be obvious in the resulting disk image. The scripts themselves need to be accessible to the virtual machine. So this is not going to be completely realistic because you don’t normally have these when a user interacts with a machine, but the advantage is you can pretty much do anything you want.
The alternative is to go for full external control. So this means keyboard, mouse and a screen, essentially. So, it’s relatively easy to inject keystrokes from outside the VM, into the VM. We’re also now able to capture screenshots of it. The thing that we’re lacking at the moment is mouse control. It’s a consequence of the virtualization infrastructure that we happen to be using. The combination of screenshots and mass control is where it gets really interesting. And it’s basically going to be the future of this, essentially, where you can use image processing to identify GUI components on screen, and then mouse control to click them.
Part of the inspiration for this is, if you ever come across Sikuli, you end up with a sort of graphical language for GUI manipulation where you can take screenshots of bits of a screen and describe that they need to be clicked and so on. So this is kind of the future, but we’re not really there yet.

We’ve also learned there’s different modes that it’s useful to be able to run these simulations in. So, the live simulation mode is where everything is real time. You script, essentially, I want this to happen at three o’clock on Thursday 4th, or whatever, and that is when that action is carried out. So, a scenario that runs for several months will take several months. Of course that’s machine time, not human time, so it’s not terrible. But it’s going to give you very realistic data. Everything’s going to be consistent, stuff downloaded from the internet, it’s going to have the right times, any interacting with external systems, all the timestamps and everything’s going to be correct, so this is kind of gold standard stuff.
We also found a use in terms of running compressed time simulations. This is where you basically say we want this to happen at this time, and actually you can set the BIOS of the virtual machine to be a certain time, run some action, move the clock, and so on. So it does have the advantage of that it allows several months of activity, say, to be created in a few hours, but there will be inconsistent data if you dig deep enough in it, you know, timestamps, data can come from external sources are going to not align. So good students or automated stuff might cause problems, but it’s another option.
So, this is a screenshot from the paper that shows you, kind of, how we express these. This is a little bit old now, we’ve moved on a little bit from this. But essentially you can see you have a bunch of functions and parameters and so on. Just to have a look at some of the newer stuff, this shows just a very simple booting of the machine and logging in. So you have a virtual box control thing saying, “Boot the virtual machine, sending a key: enter, sending the text password and enter”. That’s gonna boot the machine and log in, essentially.
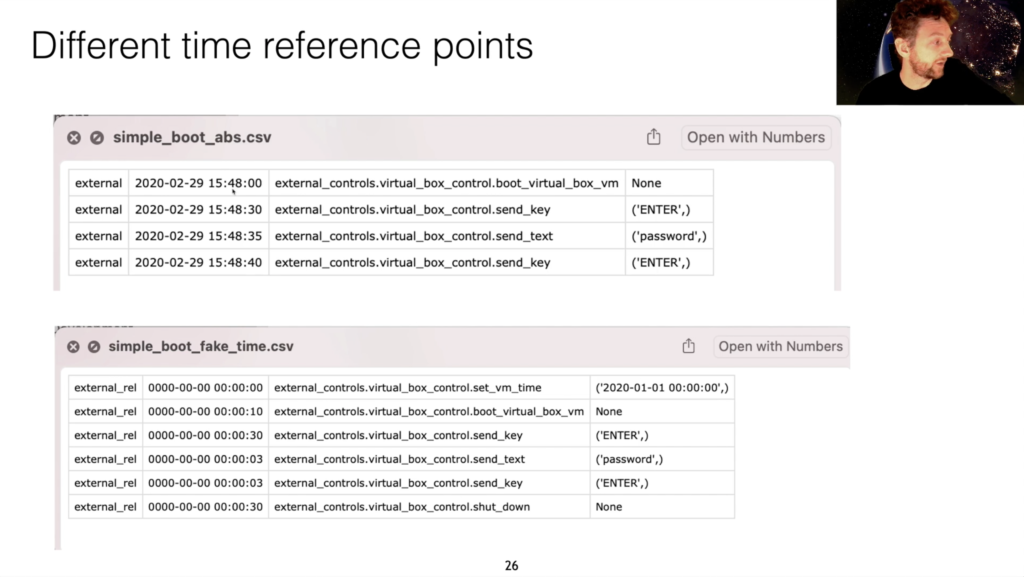
This one shows two different methods of dealing with time. So this is the absolute time. So this is the actual real-world time when these things are going to happen. This is actually setting the clock of the virtual machine to be a certain time. And these then provide offsets from the previous action. So 10 seconds later it will be booted, 30 seconds later: enter, three seconds later: password, and so on. So it’s kind of absolute versus relative time.
This one shows, you know, the way that when you’re limited to the keyboard, you can launch programs and do searches. The the reason I include this here is actually to show you that you have this, sort of, relatively small thing here that you can put in, something called a duck_search.csv, but actually, in terms of component actions or larger stories, you can actually do some actions here, but then you can basically import external files just to make this story a lot easier. So this is saying, “Set the time to be nine o’clock on the 7th, boot, do a search, shut down, set it to be nine o’clock on the 9th, boot, do a search, shut down.” So this is the beauty of merging or integrating, sort of, sub actions into a more extensive script.
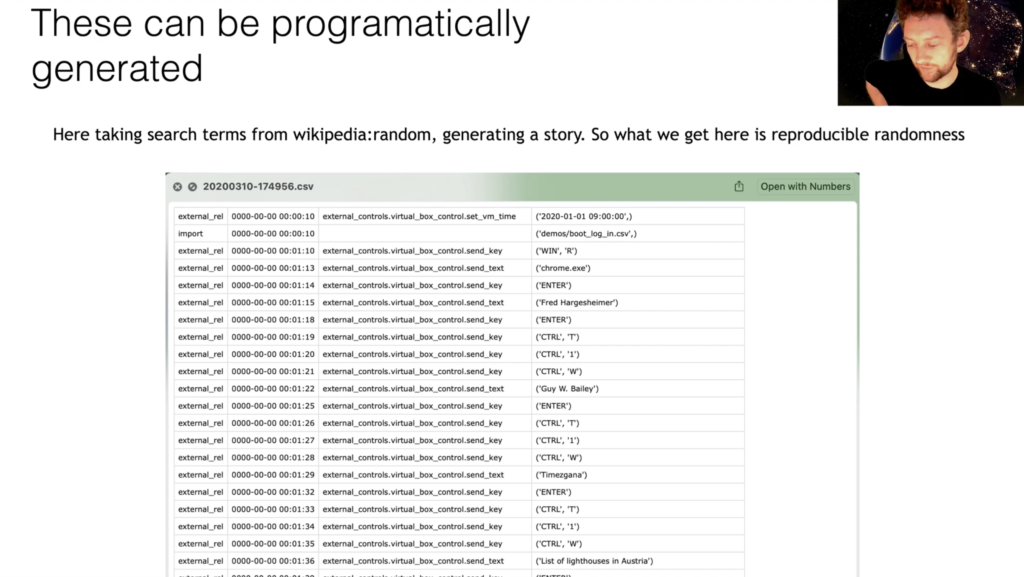
I don’t really have time to go into this, it’s a little bit of future work in terms of something we took from Forensig2 in terms of reproducible randomness. So, this was actually generated by code looking at Wikipedia Random, getting a topic, doing a search for it and generating the story for that.
I need to do very briefly because I’m running out of time, talk to you about the forensic traces of this automation. So this was all done by typical artifact research: disk images, procmon captures before and after. The reason we started focusing on the external control is when you start considering internal scripts, you can actually see the consequences of using this vboxmanage guest control to run, let’s say, Python. Not only will you get event logs from the vbox service as a login, but you’ll also, because you are logging in as the user of the virtual machine test user in this case, you will update the last login times in the F value in the SAM Registry hive. So again, for very detailed scenarios, this is going to cause problems.
You can also see the consequences of doing relatively simplistic file copying. So, running a script that uses shutil to copy files, this isn’t using the user interface. So, it’s not going to have shellbags, RecentDocs, all of the OS-level stuff that’s useful for user behavior we can structure. It is obviously going to have consistent file system artifacts, but it’s lacking the OS stuff.
The results from the browser experiments were quite interesting. Whilst we did install a browser plugin to allow the tab key to be used to navigate through the results, aside from the presence of that browser extension in Chrome, actually the results between the automated version and a user manually searching for something, clicking one of the results, going back, clicking a different result, going back, this actually was recreated very well using just the keyboard. So it shows if you just try and do things with just the keyboard and the mouse, you can pretty well align the resulting artifacts between the automated process and a real user.

So, evaluation of, kind of, what we’ve done. There’s some criteria here, Woods et al. adapted by Scanlon, things that we want in realistic data sets. Answer keys, well, the fact that we’re running to a story we can kind of have this. Both of these two, I mean, it’s kind of the point. We are reducing the human overhead of creating this realistic wear and tear and the difficulty of creating sufficient, non-incriminating data. Sharing and redistribution is interesting. It doesn’t necessarily help with this problem. I mean, the disk images can obviously be generated and distributed, but where there’s copyright issues or whatever, well, actually the stories themselves could be distributed allowing individual organizations to replay those stories and essentially create their own disk images. They’re not going to be exactly the same, but they would have the same behavior on them. So that’s an interesting compromise, if you like.
Future work, the story generator, I mentioned, so introducing random components, but having them preserved in the story. We really need to have a look at this language of the actions, you know, do we need loops? How do we express delays in relative time? Some of that’s done, but, but it’s not finished. Really what we need though, full external control of this VM. And as I’ve mentioned earlier, this is really a combination of a keyboard, mouse control and then taking screenshots and some decent image processing to identify GUI components. There will be sensitivities to OS interface changes, but I’m kind of just going to have to deal with that. And then once we get to that point, we can start building up a library of components and compound actions and indeed a library of the full stories or scenarios.

So, summary of this: real data sets have got potential problems; synthetic data sets, if you want to make complicated ones, are going to be really difficult to fake; and if you want to just manually do the actions, it’s just going to be horrifically time-consuming. We’re not the only people doing this or have gone down this approach. So simulating the user seems to be actually a valid approach to this. Internal scripts won’t generate the same artifacts and keyboard-only control is going to be limited. So that gets you to the point where you need mouse control with GUI-based automation. And the final thing we need to do, really, is standardize the language for these actions that make up stories, and that might be a useful way forward. And so if you want to get involved with this, please do get in contact. We can, kind of, align what we’re all doing.
Thank you very much for your time. If there’s any questions, if there is time, we’ll try and answer them. Thank you.





