
Aikaterini: I’m Aikaterini Kanta. I’m a PhD candidate with University College Dublin, and I’m really glad to be here today. I’m going to talk to you about my PhD research. So, about contextual based decryption.
So, the average number of passwords people need to remember increases every year. And in fact, a study showed that that number is upwards of 200, which means that we need to remember more and more passwords every day. And this is because we use them for everything: we use them for social media, when we go to the bank, when we log into something. And they can be of different types: they can be numerical, alphanumerical and patterns.
And lately we’ve seen that a multifactor authentication is also used. So, that consists of something you know (like a password), something you have (like a token or a bank card), something you are (like a fingerprint), or somewhere you are (like a GPS localization). But still the most common method of authentication remains the single password.
And this is something that adversaries have tried to exploit for many years, traditionally with brute force attacks, which if we have enough amount of time and enough resources, they’re guaranteed to work, although in practice, that’s a different story.
And with dictionary attacks, which is custom made dictionary lists with mangling rules. So, mangling rules are rules that imitate user tendencies: when we create passwords, for example, we sometimes substitute “i” for “1”, and things like that. And more recently we’ve seen machine learning and AI techniques being used, for example, generative adversarial networks.
So in 2013, the US National Institute of Standards and Technology recommended LUDS-8, which has been updated since then. But essentially this policy required lowercase, uppercase, digits, and special characters of at least eight digits long. So, in practice, if we had an Nvidia 3080, that can crack 54×109 passwords per second, it’ll take us about two days to fully explore the space for eight character passwords.
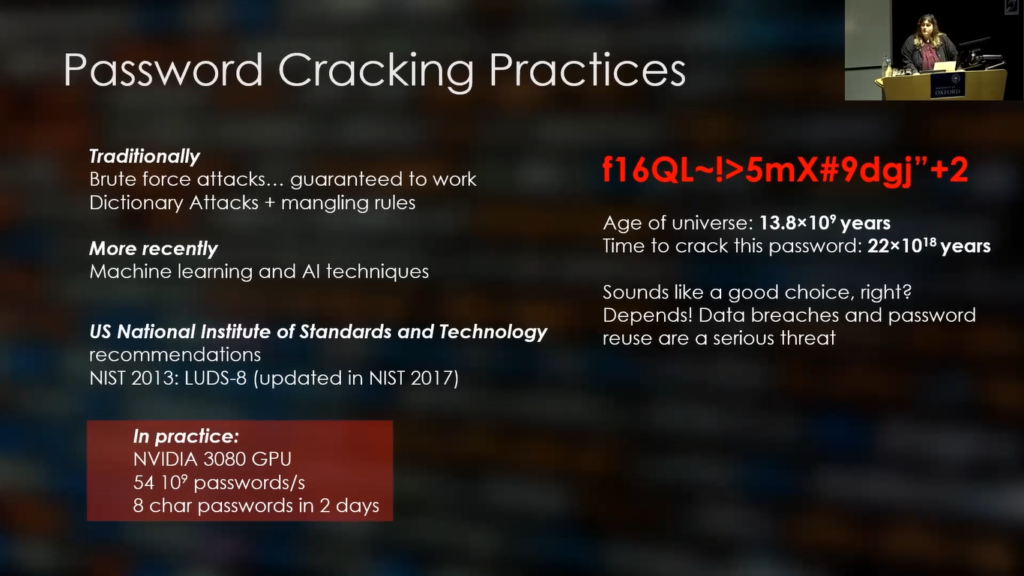
So we see that this policy, although it’s still in use by many websites, is really outdated. So what can we do? Can we use a password like the one you see on the screen with the red color? It looks really safe, and in fact the amount of time it would take us to crack it is a lot more than the age of the universe.
But again, it depends. If that password is something that we have used for more than one website, and one of those websites was found in a data breach then automatically that password is not safe anymore.
So I’m going to present a little bit of the analysis we performed on the “Have I Been Pwned?” dataset, which consists of 3.9 billion real world accounts. I have a link there as well for the full paper, if you want to read it. But here we can see the distribution of password length in this data set.
So “Have I Been Pwned” consists of leaks spanning, I think, the last decade, and we see that the prevalent length is eight digits, which is consistent with the LUDS-8 policy. We also see the top 25 passwords, and I think you would expect, at least like this, with a lot of number sequences, like “123456” is the most popular password. Keyboard walks like “qwerty”. Really easy words like “password”. And then adding “1” at the end of it is really popular.
One more thing we did for that paper was break the passwords down to fragments. So, essentially we had a password like “manchester.2019”. We broke that into three fragments. So, we have the letter fragment, which is “manchester”, the special which is the “.” and the year (so the number) which is “2019”. And here you can see the most popular fragments per category.
When we took that a step further, we classified those fragments according to their context. So, we used WordNet to do that. And these are the most popular fragment categories. So we see, we have “number”, which is the most popular one, and we have “common number”, which consists of number sequences and “popular numbers”, like the number for pi, for example.
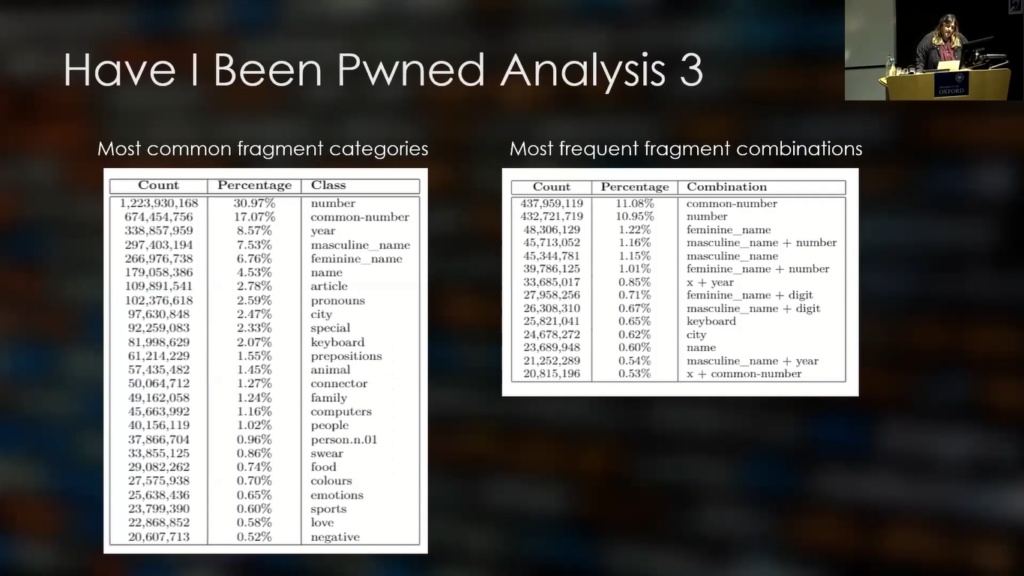
But we also have some categories like food, color, emotions, sports. So, a little bit of context starts to emerge when it comes to how people select passwords. And in terms of how they combine those fragments in their passwords, we see a lot of names followed by numbers. So, someone could use their name or a familiar name followed by maybe the year of birth.
So what does that mean to a digital investigator? So, if you’re in the course of an investigation and you are faced with a computer that you do not have access to, maybe a line of action would be to look at the digital life of the suspect.
So, that would consist of three things: the online presence, which is what they do in their social media, what they post about, do we see any specific interests? Or who do they interact with?
The local device information, which is all the information we can get from their other devices, but also maybe from the scene itself, because if you have access to their room, maybe there’s a lot more information there as well that would be valuable.
And finally, previous passwords, because if we know a previous password of a user, we have some insight into the way they select their passwords. So do they usually add a number at the end of the password? So, things like that are really important to know.
So, what we did in terms of how can we get that idea to work, was to use Wikipedia. And more specifically, we used DBPedia, which is a database version of Wikipedia.
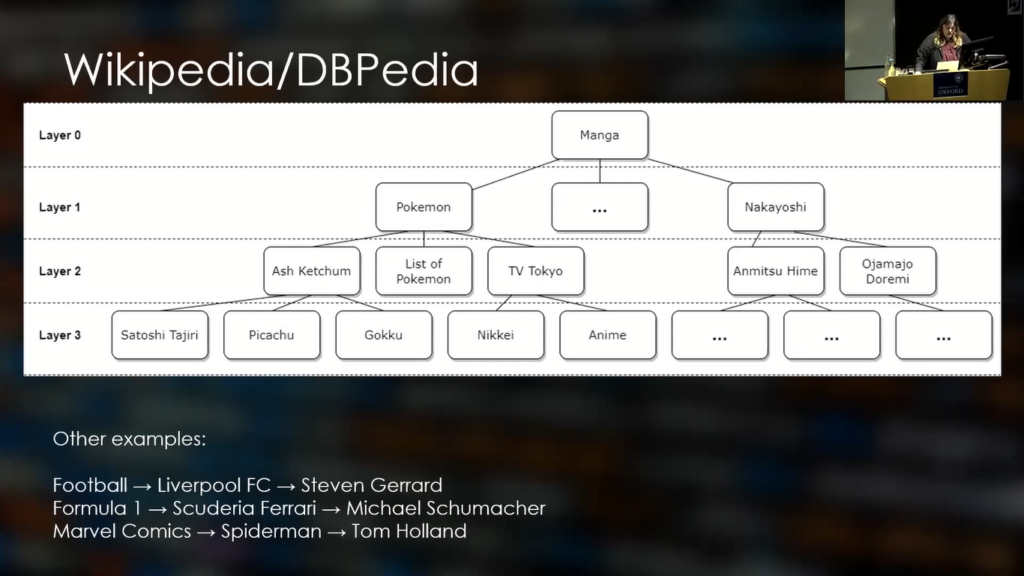
So here, what we are doing is we are saying that, for example, a user likes manga. So what we do is we start with the word “manga”, which is our seed word, and we create our own custom dictionary. So, by starting with manga, we go down to the first layer, so all the links that are linked to the Wikipedia page for manga, we gather all of that information and so on until how many links we want, how many layers we want.
So that way, for example, we can gather a few of their interests. So, if they’re interested in football, maybe they’re a fan of Liverpool, we get information like Steven Gerrard, like a different player, or something like that. So we can gather all of that information and put that in our custom dictionary list that is specific to that one person.
So what we did was design a framework, so we pipelined the process. And we start with a single Wikipedia, or DBPedia article. We perform this extraction of the links for how many layers we want. We create our own custom dictionary, and then we use a password cracker to see if we can crack the password.
So, because, in our case, it’s not easy to try a real case with one suspect, what we did was focused on the community approach. So, we got some data sets from leaks. So, we got axemusic, which is a music dataset, jeepforum, which is a forum for cars, minecraft, which is video games, and mangatraders, which is manga.
And we created another data set, which is called Comb4. And for evaluating, we used our own custom dictionary of two layers and of three layers with the starting seed word of “manga”. And as a baseline, we used RockYou, which is a very popular leaked list of passwords. And we evaluated all four of these dictionaries, and also mangatraders alone with our three evaluation dictionaries.
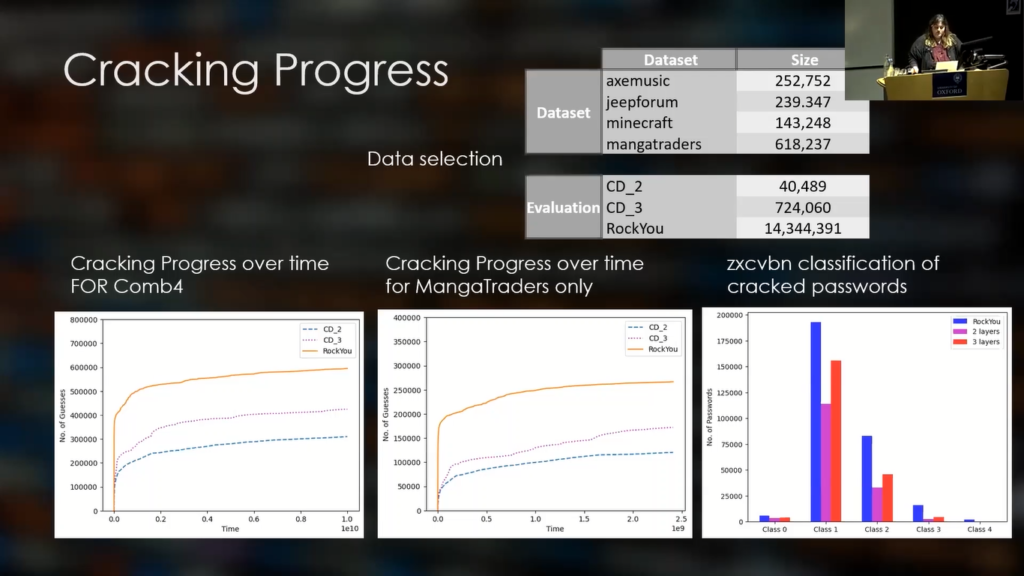
So, as you can see on the results on the first two graphs RockYou performs the best, which is something that we expected because as you can see from their size, RockYou is a lot larger than the other two. But we can see that layer three especially is performing very well.
And by taking that a step further, we classified the passwords according to strength. So we use the zxcvbn strength tool, which is the one used by Dropbox. And we classify them in five classes with Class 0 being the one that’s the least secure, and Class 4 being the most secure. And we can see here the results for all three dictionaries.
So, in case you’re wondering why would I go for a custom dictionary instead of using RockYou, since RockYou did perform the best?
So, in case you’re pressed for time, or you’re looking to crack a very strong password, it might be a good idea to first look into the custom dictionary, because as we can see on the last table, these are the passwords that were found only by the custom dictionaries and not by RockYou.
So, we can see that for the layer three dictionary, we had about 10% extra passwords found compared to what was found by RockYou. And for example, in Class 1, the number rose to 15%. So there is a lot of more contextually closed passwords that would not have been found by a generic list such as RockYou.
So, passwords can indeed reveal a lot about the users and vice versa. So, leveraging that information can help us create some targeted attacks if we want to crack the password of a specific individual.

There is…we should define what the “better” job means. So, if we are, as I said before, pressed for time, or if we want to crack up the password of someone who’s more technologically savvy, then maybe a generic dictionary list is not going to do the work, and we should look at the custom approach, or in some cases, a combination approach of both.
So, for us, our future work contains fine-tuning the pipeline for generating our targeted word lists. We want to look a little bit more into targeted communities and targeted classes of strength. So, focus more on passwords of Class 4, which are the hardest ones to crack, and to also look a little bit at options to customize our word list.
So, how long should they be? Should we do two layers or should we go maybe down to four layers? So, these are part of our future work as well. And finally we want to look a little bit more into how to evaluate them and use a compound metric because just the amount of passwords cracked from a leaked list is not really enough to say if one word list is better than the other.
Thank you very much. If you have any questions…
Session Chair: Thank you, Aikatertini. So, do you have any questions? We have questions. Yeah.
Audience Member 1: Thank you. Very nice presentation. I actually have two questions. First one: what tools did you use for the evaluation? Like the password cracker and so on?
Aikaterini: …find it here, I’ve used PRINCE, the PRINCE tool, but we’ve tried PCFG as well, John the Ripper and OMEN. So, we have results for all of these, but just for this presentation I used PRINCE.

Audience Member 1: Okay, cool. Thank you. And my second question: for this evaluation approach, did you just use the bare words from the dictionaries…that, let’s say, your context based approach, or did you apply any…some additional mangling rules and stuff like that?
Aikaterini: So, just the mangling rules that were by default added. So, nothing else. It is actually something that we want to look a little bit more into. Maybe see if there are some mangling rules that would actually perform better, but we haven’t done too much of that yet. No.
Audience Member 1: Thank you very much.
Session Chair: Okay, so we have another question.
Audience Member 2: Yep. So, really great presentation, really creative idea. So, I was just wondering, firstly, have you encountered the tool CEWL before (C-E-W-L) which…that does something not a million miles away, and also have you thought about automating this process and releasing it as a open source tool?
Aikaterini: So, I’ve not heard of this tool, but I would like to hear more about it maybe later. And yes, we want to automate it and release it. So, part of it is already automated, but we want to do it from start to finish. So, you input your sheet word and you get your dictionary list.
Audience Member 2: Great. Thank you.
Session Chair: Okay. So I think there is a question. Okay. So we have a question from online. Jen is asking, “did you manually compile the manga-related word list?”
Aikaterini: So, we coded it. Yes, we wrote the code ourselves to do it.
Session Chair: Okay. Any further questions? Yep. We have another one.
Audience Member 3: Thank you. I thought it was a really interesting approach to think about reduction of the space of passwords you need to check by looking at context. And I’m just thinking about this from kind of a theoretical perspective. Do you know, in terms of like bits of entropy reduction, how much faster it is in theory to crack a password set if you assume that you’ve got a list of every word that could possibly be used and no words that are not used?
Aikatertini: So, we didn’t look into entropy at all, which…so for strength and, like, for the evaluation, we only used the strength meter because I think…I’m not a hundred percent sure, but I think that entropy is not really the best tool to use for evaluating.
Audience Member 3: Okay. Thank you.
Audience Member 4: First off, thank you very much. That was really interesting. Secondly, have you tried running this against the new recommendations that have come out of NCSC with regard to, sort of, using three common words for creating a password? And I’ll reference xkcd’s common “battery-horse-staple” as the example, but NCSC has actually come out with that as a recommendation now. Have you tried running this against that and has it proved effective?
Aikatertini: So, we haven’t looked into that. The only thing I can tell you is that when we gather our links from DBPedia, there’s a lot of words that go together to make a link. So, in that case, we have looked a little bit into how to combine and maybe also when we have our dictionary list, use them solely, like each word as one password candidate, but also together. So, in that sense, we’ve looked a little bit at that combination, but we haven’t done any evaluation against dictionary list that consist of more than one words. We’ve only used data leaks to do evaluation.
Audience Member 4: Okay. Thank you.
Host: Okay. So, I think we can….because we are running a bit out of time. There is another question there, but maybe you can take it offline. Is it okay? So, thank you again Aikatertini.





