Justin Tolman: If you or someone you love selects all the options in processing with FTK, so they won’t miss anything, then this episode’s for you!
Episode four of FTK Feature Focus, we’ll come back to FTK Feature Focus episode four. I’m Justin Tolman. I’m the Director of Training at AccessData, which is an Exterro company. It’s a new name, but the same great software. And today what we’re going to be talking about is the processing options related to FTK. And specifically, what we’re going to talk about is how to optimize the selections that you make in processing, so you get everything that you need, but don’t spend extra time waiting. This gets you into your case faster, which means you can get through your cases quicker and more efficiently.
Shown on the screen is a very generalized workflow for what the analysis stage within a forensic investigation might be. Of course, within these different [indecipherable] here are going to be nuances and policies and procedures and various things that you’re going to go for. But of course, we’re going to start with this basic outline.
So the first thing that we would do, coming out of preservation into the analysis phase of our investigation, is we need to determine if there’s any evidence, and this is where we’re going to focus. Okay? Because this is the first step of our investigation, where we need to determine what we need to do. So what we want to be able to do is to process our case in the most efficient way possible so that we can answer this question as quickly as possible. Okay? So is there any evidence? Okay.
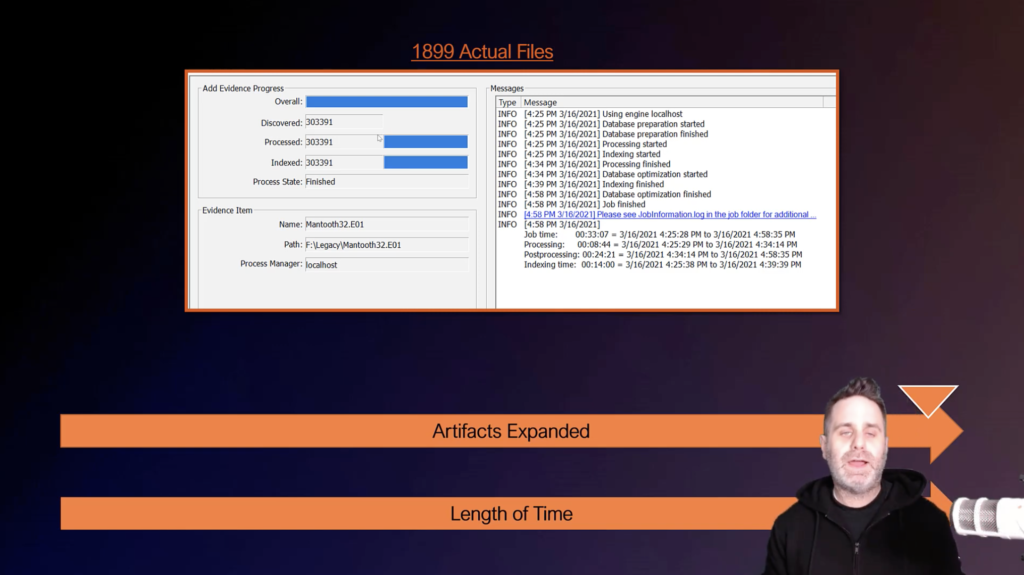
To illustrate this point, I have a small image. If you’ve taken AccessData training before, or have been around in the forensic community, it’s the Mantooth image. It’s been around for forever, but it’s perfect for these little examples. It has 1,899 actual files within the image file itself. So if I were to jump in and I were to check all the processing options in FTK and run it against these 1,899 files, it’s going to take just over 30 minutes. Okay?
And you can see that we’ve generated, from these 1,899 files, we’ve generated 303,000 files. Not all of those are going to be relevant to your investigation. Let’s say that all we care about is graphics and video files. Okay? It’s a case where we’re looking for those types of evidence items. You don’t need to check everything. Not everything is going to be, at least right off the bat, important to that type of investigation.
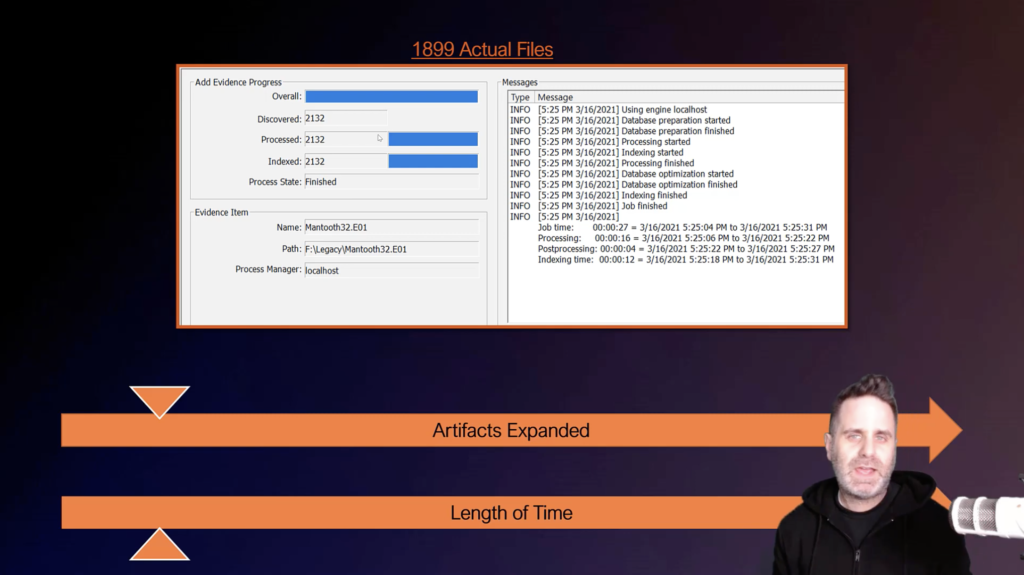
So to illustrate this point, if I were to only choose processing options that are related to graphic files, so I want to generate thumbnails for my graphics. I want to process the EXIF data associated with those. I want to create my index library so I can do some searching. And we’ll talk more about that here in a little bit. And then for videos, I want to process video thumbnails. Okay? So that I don’t have to actually scrub through them. I can just take a look at them and see chunks through the video.
Well, by reducing it down to just those handful of processing options, I can cut down the amount of files generated. Notice that we’re just over 2,000 now. Okay? Again, small image. And it only took us about 30 seconds to process. Now, obviously this is a very small image. The Mantooth image is tiny, but you can see how the time difference between targeting what you need, just what you need, and processing everything and generating files that you probably don’t even care to look at, especially right off the bat, when you’re determining, do I have any evidence? So we have this kind of scale where the more things you select and process, the higher up you going to go in the amount of time spent, and that’s a delay before you can get into your case.
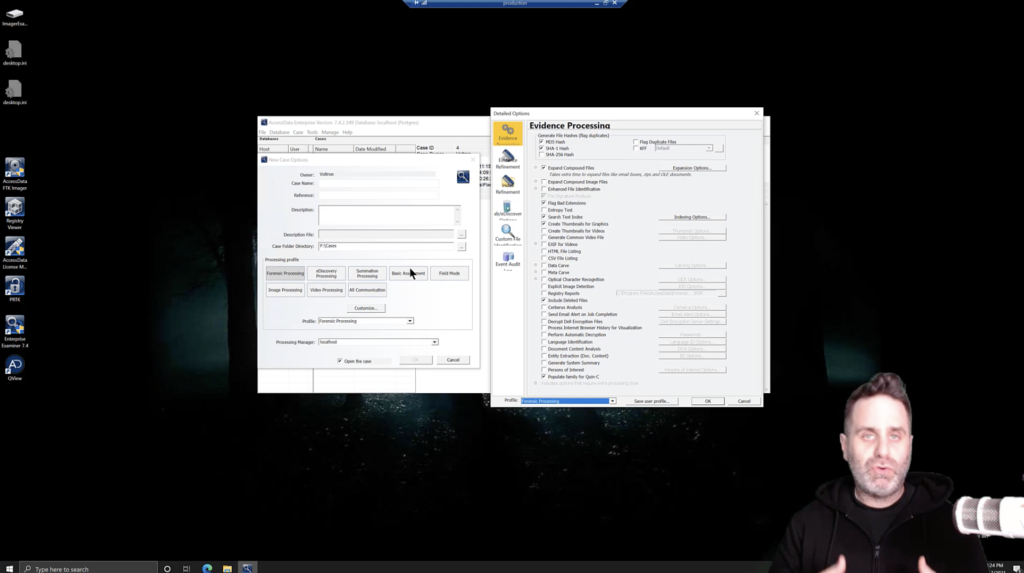
Alright, so we’ve covered kind of the general idea. We’re looking for evidence time versus the number of artifacts parsed. Okay, great. Let’s take a look at FTK and how we can manage our processing options. So first on the left here is the new case options window, or the create case window. And within the processing profiles here, you have our quick buttons, our easy buttons, the processing profile selection.
The one I’ll mention that can be used at any time without modification is field mode. Field mode turns all the processing options off and allows you to get in very quickly. Now you don’t have any help other than just the general structure of the disc. It’s not going to really process much there, but you can at least do a quick look at what you have.
The other processing options are just selections made from the evidence processing window, also displayed here, based on what AccessData thinks is a good roundabout thing for those disciplines. Remember, they’re trying to configure things to do the most good for the most people. It may not be exactly what you need, so we can customize it. What type of evidence are you looking for initially to determine, yeah, whether you have evidence, if it’s graphic files, if it’s documents.
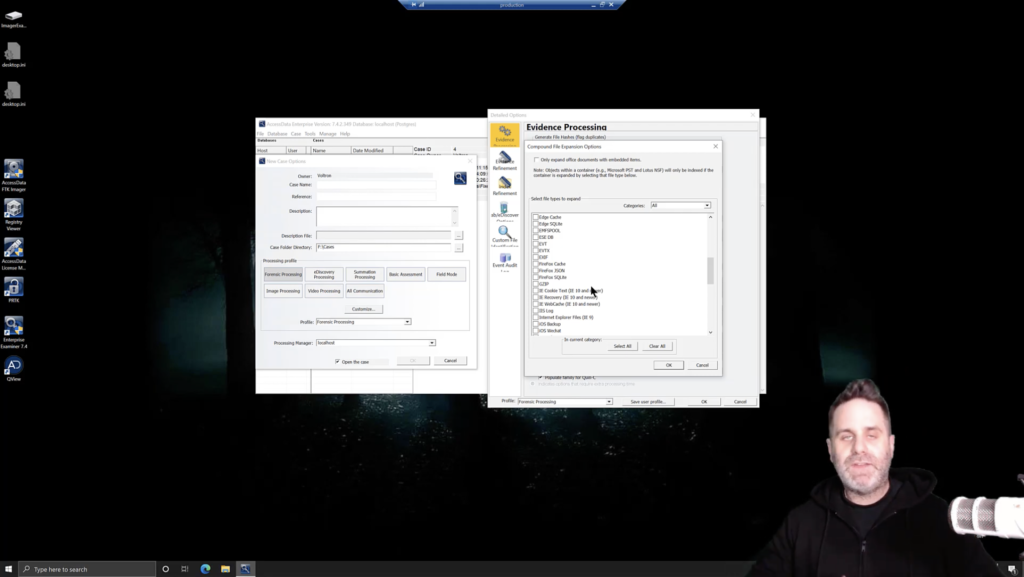
So if it’s documents, then we can come into our expand compound file options. We can clear all the ones we don’t care about. And we can come down into Microsoft Office or, you know, PC documents, maybe the documents will be related to emails. So we’ll grab MSG and PST as well.
And we can target just where it is and only process those things. Okay? If we were looking at graphic files right off the bat, again, we could choose our [indecipherable]. If we’re looking for documents, we don’t necessarily need event logs expanded out yet, or SQLite databases, or things like that. First, we want to be able to look at the Microsoft Office documents, determine if the keywords are there that we want, if the documents are there that we want, et cetera.
Once we’ve determined that we have evidence, moving to the next step: how did that evidence get there? Now we can take a look at, okay, let’s take a look at the event logs and the jump lists and the [inaudible] and all that sort of information and build up the foundation that supports those files.
One thing that can save you a lot of time when you’re going through your processing is turning off hashing. And I know that sounds a little weird, because in forensics, we’re very hash happy. We’d love to hash all the things. Now, if you’re going to use known file filter, or you want to flag duplicate files, then absolutely turn on the appropriate hashes and run that, if your investigation is going to make use of them then perfect. But if you’re not using known file filter and you’re not going to flag duplicate files, then why are we going to run MD5 and SHA-1 hashes? We can turn that off and save that and run only the hash algorithms on the items that we’re going to send out for our report. At that point, it makes sense to hash just those few files.
So what we want to do is, like that, analyze what is our objective here? Are we using known file filter, duplicate files? No. Then we can probably turn off our MD5 and SHA-1 until we’re ready for reporting. Are we looking at graphic files primarily in our example, kind of before, where we’re talking about document files? If I’m looking at documents, PDFs, Word, spreadsheet, QuickBooks, whatever else is out there, right? Do I need to generate thumbnails for my graphics right off the bat? Probably not. FTK will generate graphics as you look at them automatically.
Anyways, once you get into the case, let’s not spend that time upfront generating thumbnails for something that you’re probably not going to look at yet. The last one I want to talk about here specifically in choosing processing options and getting them optimized for your case is the index search function. So doing the search text index will take time to process, especially if you have a larger image or a larger set of evidence that you’re putting in.
However, it can be super useful in searching for all types of files. So it can be well worth the time, specifically with Microsoft documents and graphics, FTK 7.4 has added a lot of new column sets to those two file types. If you’re going to be digging through Microsoft documents, all the Office documents or graphics, we’ve added those columns. And now you can use filtering rather than the index search to narrow in on, say, the author, the last saved by, the save time, and the EXIF data, the make, model, GPS coordinates, all that sort of stuff is now displayed in columns, which means you can use the filter. So if that’s the information you’re looking for, you can cut further time off of your processing by using those filters.
I’m making this video because one of the things that I hear about FTK a lot is that it’s too slow. It takes too long to get into your case, but then when I’m running trainings and I’m talking with people at various places, I find that they’re choosing a lot of processing options that they either won’t use don’t need, or in some cases are literally selecting them all. And this generates a lot of extra time. And yes at that point, FTK will take longer to do.
However, if you take your time and create processing profiles for the type of evidence that you’re looking for, this is simply not the case. FTK will be able to process that data accurately and quickly, showing you only what you need to know at the beginning of your investigation to determine whether or not you have any evidence and how to proceed from there.
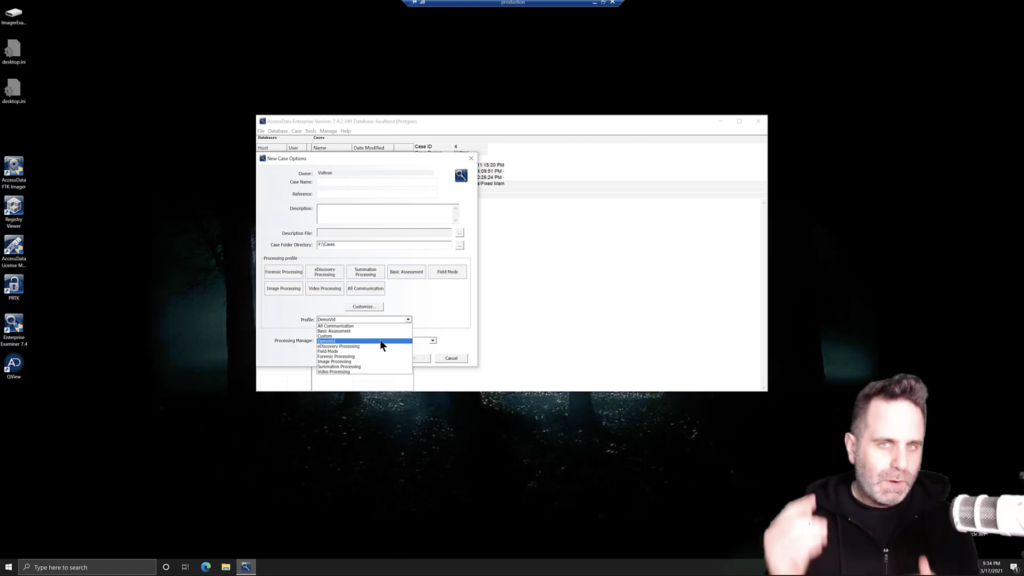
Lastly, you don’t have to reconfigure these every time. If you don’t need to, if you have consistent case types or evidence types that are you’re working, simply save the processing profile, and then just select that one every time. If I were to create this with hashing turned off and whatever else is here, I can save that user profile, giving it a name, we’ll call it DemoVid, okay? And hit save. Now it’ll automatically select it here this time, because we just created it and assumes that because we’ve modified it. That’s the one that we want to do. But the next time through, DemoVid will be a selection. We can select it and move on, just that quick.
So be smart about the processing options that you choose, because the one thing we don’t have in forensics is time. You’ve got a backlog. You’ve got plenty to do. Don’t waste time processing artifacts that you’re not going to look at this, going to clutter your interface and create more stuff for you to dig through.
Thanks for watching.





