by Harold Burt-Gerrans
Welcome to Part 6, the last in this series. In case you’re joining late, the previous parts are available as follows:
- Standards
- Standards and De-Duplication Levels
- New Approach to Managing Duplicative Documents
- Family Level Coding
- Recursive De-Duplication and Time Zones
With salutations to Monty Python: “And now for something completely different…”
Languages
Several years ago, we hosted what I believe was the first true single-language review of multi-lingual documents. At that time, Google search could only find one eDiscovery or processing software vendor that included bulk/mass machine language translation as a feature, and that was just being released in their most recent processing engine. As they were making it available to their clients, we had already hosted a complete case.
In our case, all the documents were primary language identified and machine translated to English. All the indexing and analytics were done using both the original text and English text. The whole review team was English. This approach worked well in this specific matter and it saved the client from having to build review teams for specific languages – especially helpful since many email threads would have needed to be split among review teams as the languages often varied between forwards and replies.
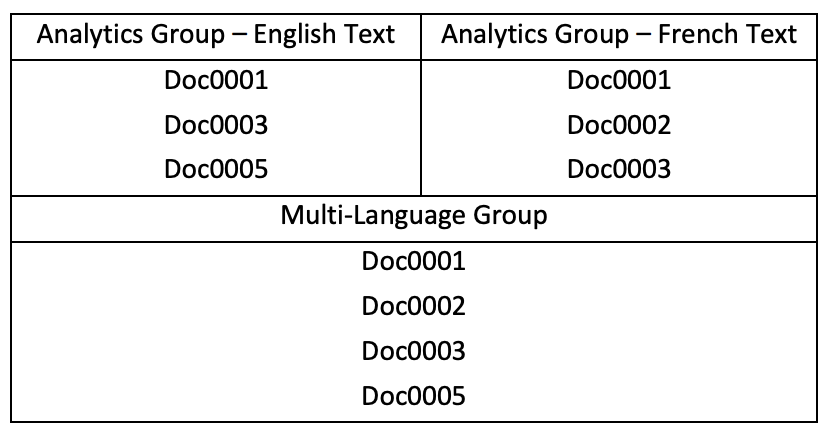
One of the problems, albeit small, that we encountered was that the review platform did not handle multiple document texts well. In fact, I don’t personally think Ringtail or Relativity are particularly good at it as of yet. In particular, in the use of analytics, there was no control that unified conceptual groupings across languages – we would see groups based on one language and slightly different groupings based on other languages.
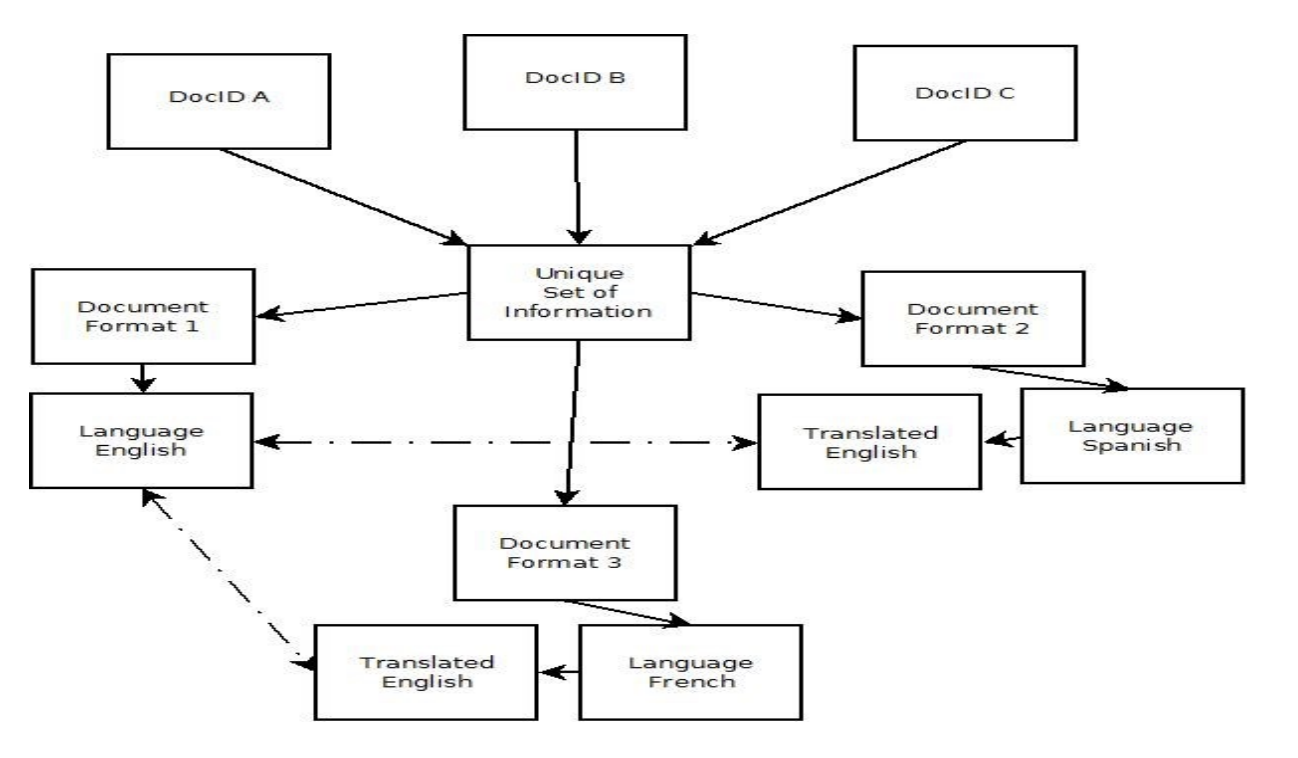
The document level data structure I suggested earlier (see Part 3) needs to have a defined substructure for the text of original and translated languages. Analytics could then build its document groups by linking documents together based on conceptual similarities among/across the individual languages. This will be particularly helpful if some documents have not been translated, allowing them to be grouped with documents that have (although, in a perfect world, all documents will have been machine translated to at least one language).
As technology improves and allows for de-duplicating between a document and a translated version of that document, my suggested multi-table document structure will need to expand to link together the documents that are both translated versions of each other as well as those that are transformed versions (i.e. MyDocument.docx vs. MyDocument.pdf) of each other.
The first step towards this ability is to allow documents to have multiple text support fields, each field having a control identifier to go along with it (i.e. Extracted Text-English, Extracted Text-French, OCR Text, Translated-French, Translated-English, etc) and then Analytics needs to group documents within the control identifier groups, and then join groups where the groups overlap.
Conclusion
The sum of the above, and the previous parts of the series, makes up most of my vision of eDiscovery Utopia or eUtopia (I won’t hold copyright on the term). The industry has not progressed far enough towards the idea of “one document = one unique set of information,” but we are getting closer to “one document = one unique set of information in one file type and one linguistic set”, which is essentially the function of current analytics tools, although they already handle multiple file types.
Over time, however, we will be able to process a collection of data and reduce it to a set of “Information Families” (copyright pending 😉 ) where each member is truly a single unique set of information even though it may exist within the data collection as multiple files in multiple formats, multiple families and multiple languages.
Let the analytics and reviewers determine which pieces of information are important to the matter and then let the machines identify what to produce based on those determinations. Diagrammatically, the review should be examining unique sets of information where each set may represent multiple documents:

Read part seven here.
About The Author
Harold Burt-Gerrans is Director, eDiscovery and Computer Forensics for Epiq Canada. He has over 15 years’ experience in the industry, mostly with H&A eDiscovery (acquired by Epiq, April 1, 2019).





