The inaugural E-Crimes Symposium: Cutting Edge Topics in Digital Forensics — offered on February 28th by the Henry C. Lee Institute of Forensic Science at the University of New Haven — brought together experts in a range of digital forensics disciplines.
The symposium began with Cellebrite’s Ronen Engler and Shahaf Rozanski on challenges and opportunities with mobile forensics; then turned to the Defense Advanced Research Projects Agency (DARPA)’s Dr. Matt Turek on deepfake image detection, followed by Metaspike’s Armin Gungor on email forensics.
The final presentation of the day was a panel discussion moderated by Forensic Focus’ Christa Miller. Amber Schroader of Paraben and Rick Clark of CloudNine touched on four different concerns around the estimated 100MB of data generated by a single person per minute:
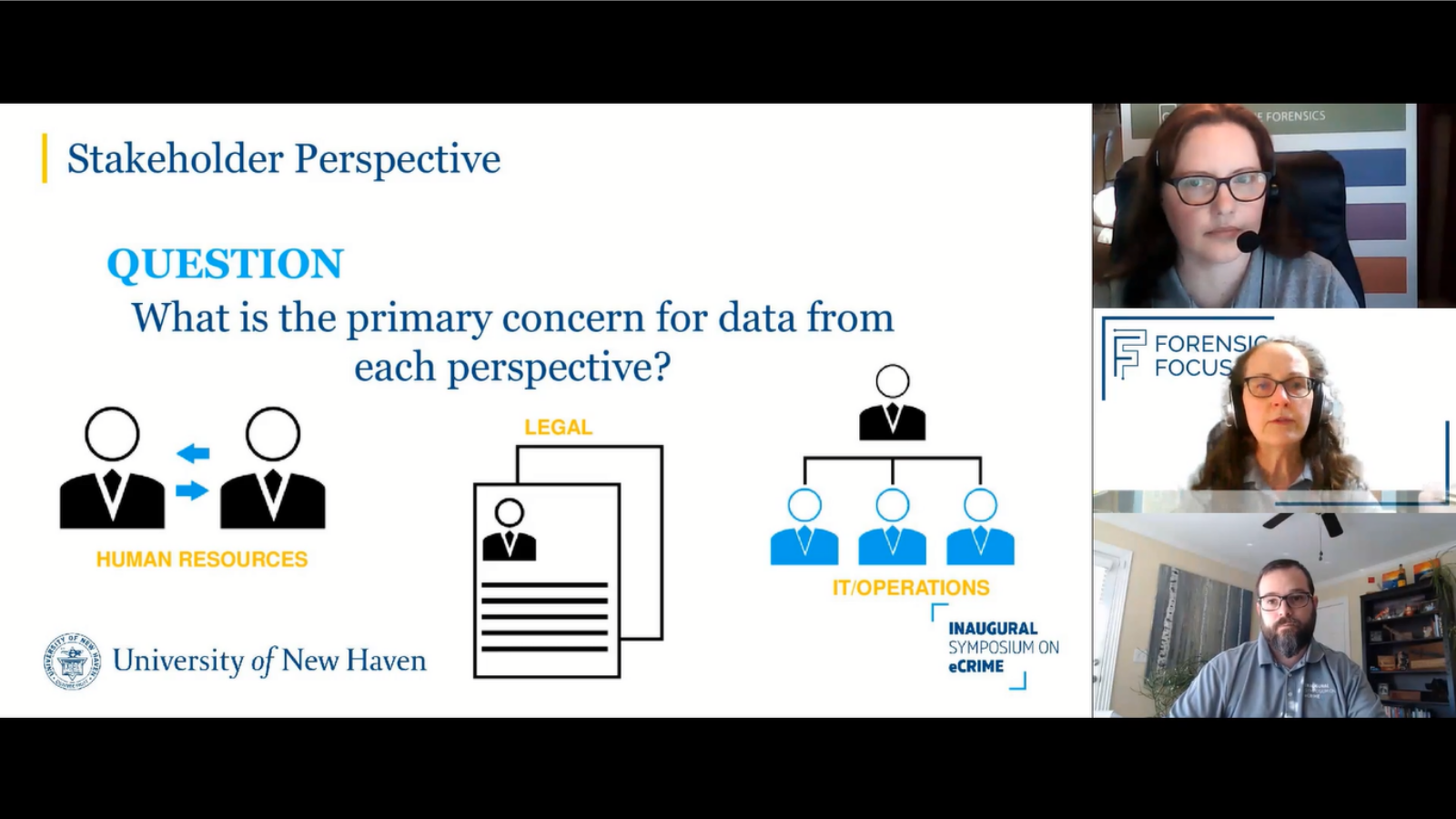
- Stakeholder perspectives, with particular focus on human resources, legal and the information technology teams in an organization.
- Criminal activity in the context of corporate or internal investigations.
- Employee information privacy.
- The human element of all of this data: who’s generating it, how it’s interpreted.
Christa Miller: All right, welcome back, everybody. This is going to be our panel presentation. I’m again Christa Miller, I’m with Forensic Focus. I’ve been in communications and media, as I said, for about 20 years now, maybe a little bit longer than that even. And in the interest of time, I will let Amber and Rick introduce themselves.
Amber Schroader: Hi, I’m Amber Schroader. I’m the CEO and founder at Paraben Corporation. I’ve been in digital forensics for the past 30 years. I’m definitely in the technology side of it and looking at different data sources from computer smartphones, IOT, and the Cloud.
Rick Clark: And I’m Rick Clark with Cloudnine; Senior Director. We were recently acquired by Cloudnine, I was with ESI Analyst as a co-founder. So I’ve been dealing with modern data, we really should call it today’s data because it is everything that we’re doing on our devices and laptops. And so I’ve been working on the analysis side of all of this type of data.
Christa: So we’re focusing on the amount of data that you can get for multiple data sources. By now, some estimates say that just one person generates about a hundred megabytes of data per minute. We don’t think about how much data we’re actually generating. You know, we’re compartmentalizing our data between the emails that we’re writing or the documents that we’re working on, or the video that we’re taking of our child.

But, you know, aggregating all of those things together, it’s not the data that we know we’re creating, it’s also the data that’s being created about what we’re doing. I think that was a point that Ronen got into this morning regarding, it doesn’t matter, the device doesn’t necessarily have to have been involved in the crime. You know, the person’s not necessarily recording a video of what they’re doing or the device wasn’t used to yield the intellectual property. But it’s also about the geolocation tags on what we’re doing, or the email headers, or any one of a number of things that provide context for what was going on at the time that a crime happened or any kind of incident.
So in our panel today, we are going to be touching on four different concerns about all of this data. We’ll be talking about the stakeholder perspectives, with particular focus on human resources, legal and the information technology teams in an organization.
We’ll be talking about criminal activity versus the privacy of information. Some people do use their work devices for bad things; whether that’s viewing child sexual abuse material, or whether it’s embezzling funds. At the same time though, there are privacy concerns, right? There are people that are using work devices to conduct, say doctor searches or things like that and we need to keep that in mind.
And then finally, there’s the human element of all of this data. Not just who’s generating it, but also the interpretation of it. Especially when we talk about artificial intelligence and machine learning, we still do need those humans to interpret that data. So we’ll be touching on each of these today. So I’m going to start with a question for Amber and Rick: when we talk about stakeholders, what is the primary concern for data from each of these perspectives?
Amber: Do we want to start with human resources?
Christa: Sure.
Amber: So I think it’s actually, from my perspective is, a lot of it is about risk; no matter what it is, the data is going to create some risk to the organization. And I think multiple of these perspectives have that. And the side of the risk is, is the activity going to lead to our next poisoned word: criminal versus not. But it’s what’s the risk to a financial and also what’s the risk to the other data in the organization, cause our data links so much? So I think that’s one of the areas that as we go through, that’s probably one of the biggest concerns I see.
Christa: There’s a reputational risk in there too, isn’t there?
Amber: Yeah, absolutely.
Rick: Yep, and in legal where I spend probably 90% of my time, you know, really their big concerns are, you know, proportionality, right? So with all of this data that you’ll see here shortly, where do we really start? What’s going to be most relevant? And so a lot of it’s just costs associated around that as well as validation of that data. So, you know, I think Armand was talking earlier about, you know, authentication of that. So, you know, they want to make sure that everything they can authenticate, nothing’s going to get spoiled and they have a nice process around that. Now I will say, in legal, we see a lot of this data being treated as documents. I’ll talk more about that later. And so when it comes to modern data, we’re really looking at different approaches to this and actually treating data as data versus documents first.
Amber: I think that brings up a lot about the diversity of data, as well, because so much of our data sources are not limited to a computer or a phone or Cloud or IOT, they’re all intermixed and they’re sharing so much. I think it’s almost like a big old pile of spaghetti and you’re trying to pull out that one single noodle without touching all the other noodles in the process. And it’s almost an impossibility that I think each one of these areas within an organization feel that strain with it.
Rick: Yeah. And partially with IT, you know, there are two policies, right? Corporate-owned devices, or bring your own device, or I’ve heard many people say, “Bring your own disaster”, right? So there are, you know, challenges with all of the different apps that we saw earlier of just, you know, what’s on our devices? What’s actually relevant? What can they actually pull from it? So IT’s got their hands full with, you know, typically corporate-owned, you know, devices and getting data off of there, preserving that data. But when it comes to BYB policies, there are a lot of challenges there, still.
Amber: Yeah. I think it also has that problem where almost they have like a schizophrenic identity where they’re expected to be able to respond to a situation. But in fact, that’s not really within their purview. Their purview is to protect the IT infrastructure and maintain it, not necessarily be able to do the response, the collection and all of that side of it.
Christa: So there are really policy and logistical challenges that abound for each of these stakeholders.
Amber: Absolutely. Yeah.
Rick: Yeah.

Christa: I want to delve a little bit in particular into criminal concerns. So I mean, we’ve talked sort of broadly about risk management and so on, but I feel like criminal activity whether it’s fraud or embezzlement or or anything else, you know, threats, harassment that might get the police involved or add a whole different layer of complexity onto what those stakeholders are thinking about. What do you both think about that?
Amber: Oh, I completely agree. I think, and let me caveat; not a lawyer, definitely discuss with a lawyer when it comes to anything criminal. I’d like to put that out there, but I think the biggest problem we have on the criminal side of it is I don’t think a lot of corporations know where the hard line might exist with their data. At what point does it become criminal or they need to bring in law enforcement so that they can pursue it another way?
But the flip side of it is, at what point do they respond to law enforcement with their data, as well? Like when they get a request. Nothing is worse than having your company have some type of investigation where you’re already in a panic mode going, “What is happening?”
I almost joke that like 50% of your time consulting in digital forensics is actually just doing therapy because they’re like, “I don’t know what’s happening. Everything’s going to fail. It’s all just going to fall apart.” And it’s like, “No, calm down. You’ll be fine. Let’s just look at the data and see what you have.” But that really is 50% of every phone call I’ve ever done for consulting is just making the person feel better about being in the investigation in the first place.
And it’s interesting to see how few end up criminal. When it comes to a lot of the corporate cases I’m like, “You really don’t have anything criminal happening, but you have a civil concern.” but it just doesn’t move into that criminal area. But so much TV I think has made people think a lot more things are criminal than what are actually criminal. That’s just my, you know, two cents on it.
Christa: Interesting.
Rick: Yeah. I would agree with all that. A lot of my time is spent in civil, but because of the nature of ESI analysts and what we have here, you know, and being able to look at all of these data types together, we’re getting a lot more into these types of cases.
But primary concerns for them would really be, sometimes we hear just access to all of that data, right? Like, it might be, they have all of it, but it’s analysis paralysis. They’re staring at all of this data, but how do they actually do analysis on it? I get that a lot.
Amber: Yeah, when someone asks for a production and is like, “Hi, we want everything from your server for the last two years.” And you’re like, “Are you kidding? You’ve got to be kidding, because that can’t be legitimately what you want to see.” And they’re like, “Well, what would we want to see?” I’m like, “Not that much, ’cause you’re going to drown in it.” It’s, you know, drinking the ocean all at once.

Rick: Yeah. And so what we’ll do today is we’ll talk about a case that I see often and that’s an [intellectual property] IP theft or non-compete type matter. And the reason why we pick this one specifically is these types of investigations can actually expand out more than just traditional, what we see in e-discovery as email and documents. That these types of cases can look at computer forensic artifacts, they can look at device data, even geolocation might come into play here.
So we mock this up, we’ll show that here shortly when I get to my part of the presentation. But really what we’re seeing is that cases are expanding out certainly in the e-discovery world from just documents and needing to really look at all different types of data, always maintaining, you know, within the realms of proportionality.
And so we’ll talk about that as we go along, but that’s usually the biggest argument is, well, you know, we have all of this data, we can’t look at it all. And so it’s really prioritizing what is available and what they can, you know, review or request.
Amber: And as the three of us discussed, one of our things was our quality of our data associated with it. So that’s part of what we’re going to go to, as well.
Christa: Again, that balance between content and relevance and proportionality. So on that note, since we are talking about intellectual property thefts, which I feel like is one of those things, Amber, that you were talking about could seem criminal, but maybe isn’t, is who really owns the data?
You know, we talk about privacy of employee data. I know when I was employed full-time, I’m a contractor now, but when I was employed, I had to sign a clause that said that whatever I created on company time on company property was the company’s property and not mine. And it seems like the sort of thing that maybe some companies don’t put that in their employment contracts, they maybe thinking of it as a given or assuming that it’s a given.
And then there’s also the other challenge of, you know, what happens if you’re an employee on the road and you’re checking your, you know, personal Google Docs on a company laptop when, you know, after hours or something like that. So I feel like there are some gray areas there in terms of employee privacy, as well as data ownership.

Amber: I think there’s also that side of it. And this is an interesting part that I’ve seen. We’re all in a similar generation, I will put it out as a similar generation, but every generation also sees a data privacy line at very different levels. I know I’m a Gen Xer. You guys, I think are Gen Xers, as well.
I see much harder lines in my privacy than what I saw in some of my staff that are millennials or Gen Zers that have a very fluid perspective on what their privacy is because they’re going to be the BYODers, they’re going to be the ones that are like “Here, you know, oh, I’m on my company machine. It really doesn’t matter. I’m just going to go check my social media.” And now it’s got a cookie in there and all of that, it’s like, well, technically as soon as it hit my company machine, that data belongs to me. You chose to do that and that active choice drew that hard line of privacy.
And I say that from my own documents, I have the same thing in my company documents where people consent, this is what’s going to happen. And it’s the same. So we have BYOD. My BYOD policy is if you want to use your own personal phone for company business, then you have to consent to searches. That’s part of their agreement. If your cell phone number is on the business card, you consent to searches. I don’t own your data, but you consent to have it searched. And it’s cause it’s gray.
Rick: Absolutely. And you know, I might answer this best with a case study we saw where it was a C-suite executive who deleted everything off their device. And it was a pretty big case and the judge was pretty upset about it. And opposing counsel said, “Look, the data’s not in the email. It has definitely had to be done via text messages.”
Well, that person then had to identify over a hundred people that person talked to such and such a thing about. Well, that happened to be family members, that happened to be relatives, happened to be all sorts of people, but it was very important to know any and all conversations around this particular thing.
So they collected all hundred devices, but only put in the conversations that that person had with that person. So there was a lot of calling ahead of time, but we put all of those into ESI analysts, deduplicating anything that might have had duplicates and restoring those threads as if it came from that person’s device.
Now, it was interesting because there was a lot of back and forth early on about, well, they don’t want to give up their phones, right? Of course they don’t. And but it was interesting to see that that play out and that the privacy measures that were put in place with those devices and the care around it.
Amber: So I think that’s one of the hardest things is when people think of, you know, this is my phone here, it’s your most personal electronic device you have. You sleep with it, you carry it with you all the time. You probably spend more time with it than you do your significant other.
And so people, when they look at the data that comes with these particular devices, they’re very protective of it because it’s part of them in a lot of ways. I’m like the least active smartphone user in the fact that I don’t put a ton of data on mine, but it’s because this is what I do professionally.
On average, most people have almost half a million text messages just on their phone alone, that you’re having to go through and weed. And it is hard to determine what is private. What if I talk to my spouse about what happened at work and that’s part of the investigation? And that starts turning it and making it weave into that big pile of spaghetti so…
Christa: Well I think that brings us to our next phase of our panel discussion. Amber, I think this is on you.
Amber: Yeah. So we were taking the perspective of how do you get that best practices associated with data? And this part hasn’t actually changed in the 30 years I’ve been in the field. It’s always been the same where we always look at an acquisition stage, an analysis stage, where we follow that rule of tools that we’re going to follow here and then do that final review.
The thing that happens in the whole process is that there’s obviously a long process in adjudication of any case, is that you occasionally will go back and re-follow these same steps again as you get towards the end of the case, so keep that in mind. I was focusing on some of the acquisition of our data sources that we decided to discuss as a group, which was our smartphone, our computer and the cloud-related data.
When it comes to smartphone acquisitions. I know it’s been about earlier in the symposium. One of the big things that you have to decide is how many different methodologies you’re going to use and what’s your bare minimum?
Because whether you are doing it within your own lab or you’re hiring a lab, you have to have that best practices that says every time I know I’m going to have a logical examination done, I’m going to have this expectation of the data.
Because every tool is going to produce different types of data. It’s not the same as a computer where once I get a DD image done, I’m going to get the same data production out of every tool I use.
The actual acquisition stage of this is going to change your production. If I do an Android and I read off a chip and I do a chip dump, I’m going to get a physical image and it’s going to have a very different format to it than if I’m going to do a logical image doing an ADB backup. All of those have to be considerations in that acquisition stage.
For Apple, Apple is very traditional. They don’t allow a whole lot of coloring outside the lines. It’s always the same. So you’re going to have a little more static of what you’re producing each time. But in that, it means that you have to make sure that you don’t miss a step. So for example, all iOS, you need to do an encrypted backup to get the best possible data otherwise you miss big chunks of it.
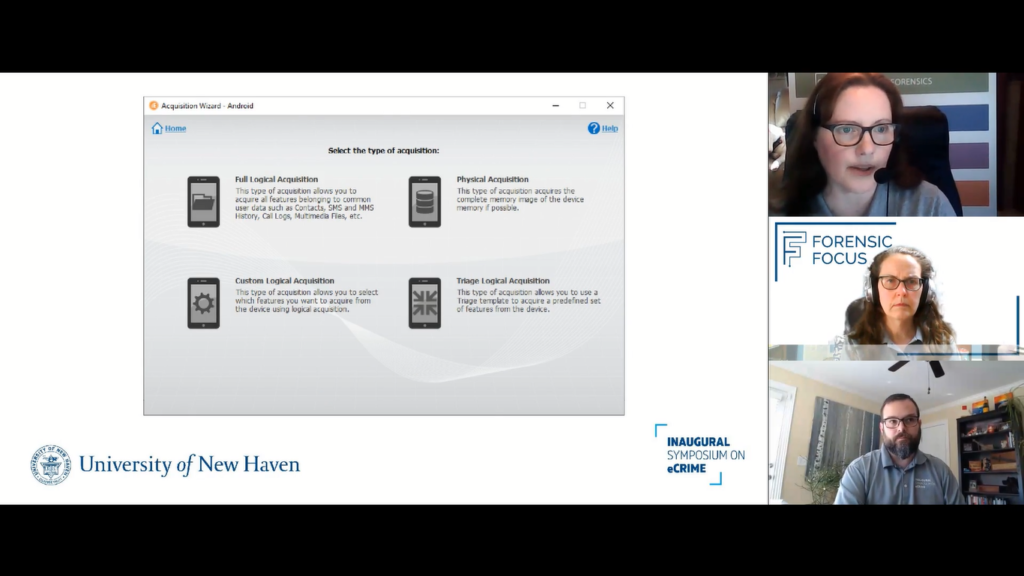
And within that process is where those acquisition selections happen. This is where we go into our terminology of our full logical, physical acquisition, or realistically now with the large production of data, since we’re talking intellectual property, you might not have purview to all of the data in the device.
And that’s where you have to adjust to make sure you’re only collecting data that occurred from X date to Y date, or only from SMS. You’re not entitled to calls.
That is starting to change and become more and more applicable as you start doing these investigations, because on a typical phone, so I held up my phone, my phone will take a full 24 hours to acquire, just based on the overall volume of the data and the fact that it has a terabyte worth of storage. You’re pushing that through a teeny tiny like straw and that no matter how fast you feel type C is, it’s not that fast. And that transfer rate is gonna cost you in that acquisition stage of the process.
Once you go through and actually do it, you’re looking at access controls, where it’s anything from, do you have access to the file system, which is where a lot of your data is now residing, or do you not? And these are questions you have to ask in your process for doing that collection side of it when it comes to phones.
Again, on the Apple side, a lot of times you’re working with my backup records. Believe it or not, most of the people can do your own backups and you can parse them yourself because the methodology can’t change. Apple is extremely restricted on its choices.
What I’m going to show you on the collection side for the computer or the acquisition side is I’m going to switch over to a screen share really quick, going to get a little bit of that infinity going, but you should be able to see my collection here.
So I’ve already imaged my drive. So I have a 001 image and it’s segmented out. As I add that in and I decide I’m going to process it, like most things in the world it’s a Windows device. So I’m going to choose at this point, I’m kind of walking into data not knowing what I’m looking for. That’s the hard part, I think, about all types of investigations or collections is you really don’t know what the entire story is. It’s like you’re given a puzzle and you don’t have the actual box to tell you what the image is. So you have to kind of start just putting those pieces together.
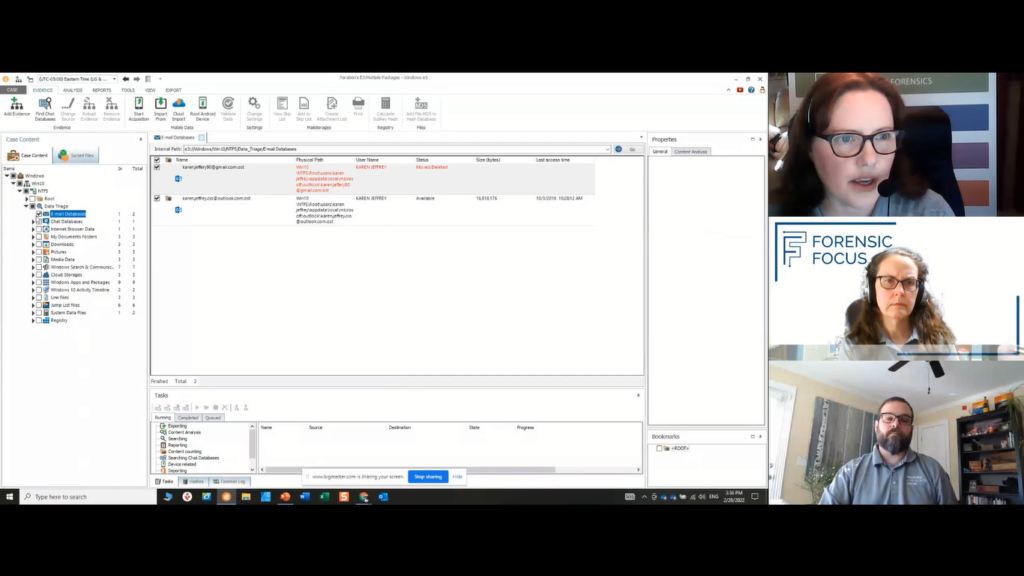
I’m going to skip processing a lot of my file system in that aspect because I need to see some idea of what I’m looking at here. This is when in my philosophy, data triage really becomes a big help for you because this is going to give you some idea of what you’re looking at before you start diving in saying, “I know I’ve lost intellectual property out through some means within this investigation, but I don’t know what was involved that I need to start looking for my artifacts.”
So obviously we look for things like email, but I immediately can tell my email, I have two and one was moved or deleted, but I know I have an OST file I need to look at. Maybe I want to pop into things like the registry and I want to see what was attached to it. If I’m losing data out of my registry, maybe it’s about the different devices that have been attached to this system.
So I want to look for those artifacts that are kind of helping me put together what those pictures are before I just jump in and decide, “I’m going to process this entire file system.” Because the other side of it, depending if your criminal or your civil is how much expense is your client going to put into this?
They might not want you to spend all the time to process everything in a multi-terabyte system. They might want you to say, “Hey, I see you told me they have email and they have some cloud storage and it looks like they’re connected to OneDrive.
So let’s focus on those and let’s focus on some of the devices that they were having connected into the system, and perhaps look at some of the mobile side of it.” And as you adjust in, hang on, that was kind of funky. You can go through and say, “What is going to be my next step in the process?”
Christa: So as you’re talking through all this, are there special legal considerations for each of the different data sources?

Amber: The biggest thing is on that criminal versus the private side. And I think the biggest data source problem we have right now, it’s not about your phone and where you’re going to draw your lines or your computer and where you’re driving those lines, but it was that mention of cloud.
And the reason is as we’ve all been through a pandemic, every one of us has connected to the cloud. We’re in a virtual symposium, obviously we’re connecting through the cloud, as well. It’s really that side of consent that starts happening when we start touching that extra data source.
And that extra data source at this point in the world is that cloud data source. And the legal system didn’t get a chance to catch up to that migration. And that’s been a big problem. So people like, on private consulting, we offer a consent document. I don’t know what happens in a lot of the civil litigation.
Rick: Yeah. What I really see here is more of the proportionality argument on them arguing away this data. I remember back in the mid-2000s they were shaking hands over file cabinets and ignoring emails. In this instance, you know, right now people are trying to make the arguments and to consider these different types of sources as part of the discovery altogether.
So I know that’s maybe a little bit different than what you were saying there, Amber, but from what I see all the time is helping them structure the way they’re going to ask for this data, right? So the protocols, the ESI protocols and case strategies.
And what we do also find is that this also, data sort of begets data, right? You might start on text messages and realize, or emails and realize the Slack data is really important because that’s where everyone’s communicating. So what I’m seeing is the legal considerations are making the right arguments and asking for the data and making it possible economically to do the same things as well.
Amber: I think there’s been a lot more restrictions with the costs associated with an investigation. Sorry, I didn’t mean to interrupt you.
Christa: No, I actually was going to raise a point that Armin had talked a little bit about before, which was preserving data in its native format. I think once you start talking about all those different data sources, that, how do you do that?
I think with email it’s easy, right? Because everybody’s used to kind of the formats that, or everybody has a kind of an understanding of what the native email format is, but maybe not so much with Slack or Zoom or many of those.
Rick: No. And that brings up the point on that our industry, e-discovery industry treats data like documents. They will create 500,000 single text message documents to do brute force review, or they might expand into making them into 24-hour, 48-hour threads, but then they have to redact all around those relevant messages.
And so, you know, that’s been the biggest challenge from a document-centric industry for us saying, “Hey, leverage the metadata, leverage the data as it is, create documents later.” Right? And that comes to, really speaks to workflow versus anything else there.
Amber: Yeah. It’s important to know those diverse data sources. I do agree that e-discovery is all very document-oriented. And when you start putting those pieces together to recreate that puzzle, you’re not just looking at an individual like, “Oh, this SMS is, is where it is. And that’s it.” The data leads you, it’s part of that human element we’ve talked about.
Christa: One question that I have personally actually is as the two of you were talking and going back, Amber, to a point that you raised earlier around the gray areas is sandboxing. I think some companies are using mobile device management to sandbox corporate data away from personal data. And I’m not sure if that can help in the kinds of situations that we’re talking about here, or if it creates other hassles.
Amber: It creates other hassles when it comes to the collection, since we were talking acquisition-side, if you have any type of MDM in use, it does create a hassle for that collection side. What we found is that you might get initial perspective, but almost every time it’s like almost nine times out to 10, they have to go back and do a larger purview that represents the larger scale of the device because people don’t keep their conversations about whatever it is about.
So if I’m doing intellectual property theft, I’m not going to keep it on just what the corporation is monitoring or allowing me to have in the sandbox. I’m going to pull it into WhatsApp, I’m gonna pull it into Signal, because if I’m doing something nefarious, I’m pushing it outside the fence either way.
Rick: Yeah. In fact, one quick case study was a very important case. But this individual on their device looked like they just talked about, you know, butterflies and daisies, right? Everything was just so clean and nice. It wasn’t until they went and collected their Twitter direct messages that blew the whole case wide open. And this was a very impactful issue there.
Amber: That leads perfectly to my next case example for us for intellectual property, too.
Christa: Well, go for it.

Amber: Okay. So this is part of the reason that we’re a panel discussion about different data sources is because it always is two perspectives. I don’t think I’ve ever done a case where I’m the only person that has looked at the data and it’s just all 100% me and my brain, that would actually be very scary. I always want to have someone else’s perspective and I always want to have another tool give me perspective, as well.
Although you might be seeing a tool that I have at Paraben that I’m using, having another tool give perspective. So that’s what we’re going to show you is what those two perspectives are really about because that principle of always having more than one source to review it has been around since I started in this space. And that was a long time ago, that was 30 years ago. And they always still, even though it was DOS, they still used more than one tool.
So keeping that in mind, as we look at our analysis perspective, it’s, as we were just talking that human element, you didn’t know until you were in the private Twitter messages, it’s all about where they are actually communicating is where your collection has to be focused on.
And a lot of times it happens in that initial triage, but then once you go into it, I’m going to share my screen again, so we have kind of that awkward transition there, is I’ve pulled up a Google Pixel, and this Google Pixel, I have root level access, because my file system is open to me, which is fantastic. That’s what you always want. It’s a great day in digital forensics when you get root.
But one of the things you want to look at is all of your installed applications. It’s one of those first steps and I always say that when I’m doing any type of investigation, is that I want to see how the person was using their data.
And the best way to know how someone is using a mobile device is really look at the apps that they installed. Were they going through and what were their browsers? What were they connected to with social media? What were they using potentially for messaging? Did they use something that was also IOT-driven in that process?
All of that is something that I want to look at. So being able to see all of the apps together I think is really critical for people. So I know I can get geolocation data from my FitBit. I know I can probably get it maybe from their Instagram posts they’re doing.

And then if there’s something in your list of apps that you’re looking at and you’re like, “I have no idea what VK is.” You know, that’s when you go and look in the app store and look up, what is this app? What should I be looking at? And all of a sudden I’m like, “Oh wait, this is a Russian app. Are they talking to someone in Russia?”
These are things you want to make sure that you’re investigating and understanding about your potential suspect. And just know when I use the word suspect, I call everyone a suspect. My kids are suspects, my husband’s a suspect, my dog’s a suspect. Everyone’s suspected of doing something.
So in my case example for IP is, we had looked through and we looked at the traditional, “Okay, hey, what are they doing?” So if I’m over in their SMS, and this is fake data, so I don’t want you to think I’m going to share live case data. I’ve got nothing. Like, they didn’t have any text messages that they were doing. I’ve got nothing in the recovery associated with it. I’m like, “Okay, they’re not making phone calls because no one uses their phone to call people.”
That’s crazy. I can go and I can look in their call history and I’ve got six phone calls, but their phone is very full of data, that’s when I go to that app source. And in my intellectual property case I actually did an investigation where I had two people and an organization was losing data outside of their organization. They were losing proprietary information about a large project that they were working on.
And I was like, “Okay, this doesn’t make sense. Let’s look at the people involved in the project. They consented to their phones being searched. We searched through all their different phones” and I’m like, “Something is still not adding up because no one’s got any data that really represents that.”
And I said, “Let’s look at the apps.” And I looked at all the apps that were geolocation-based and I realized that what they were doing is they were using Tinder. And I know many of you are probably thinking one; you’re probably really grateful you’re married and you don’t have to date online, cause that’s always fantastic, and I’m very grateful I don’t have to date online anymore, because that would be rough.
But I have all these people that the person has connected to. It’s 100% geolocation-based. They had another app that was associated and this just happens to be Russian. So they were connecting with people that were geolocation-based and they were sharing the details out. And in this case they happened to be sharing them outside of the country.
And that’s where all of the intellectual property was happening is, as they were going through and doing their communications, it’s where can they meet up all of this information? I know it’s delivered. I know it’s viewed. I know Nikita is getting the information and I know it’s then being able to transfer it out.
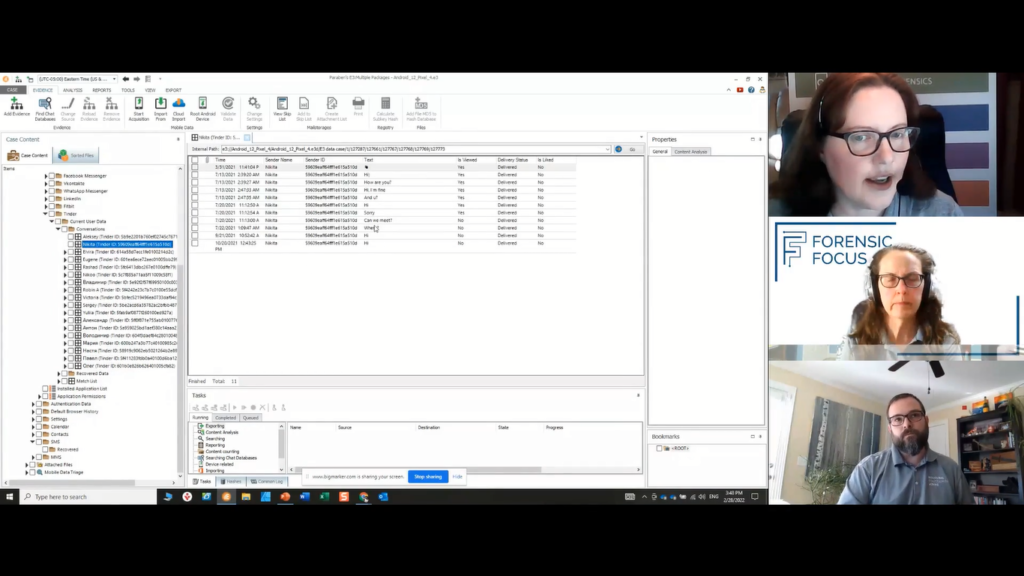
And most of the time this would not be covered by your MDM. So your mobile device management system is not going to be looking in Tinder, but at the same time, what are the policies within an organization that are watching for this type of information to happen?
Because this person was connecting with someone that was just simply outside of the building, because it still allowed them to like one another and it allowed them to swipe up, which means they super-liked one another, which started the conversation threads that allowed them to keep dumping data into those conversation threads. I was not picking on Tinder there, just so everyone knows.
But that’s part of that human element side of it is because that’s understanding the people who are involved in how that data might have transferred from point A to point B. And it might not have been that same side of it.
And then it’s really about me as a person sitting behind that chair, my tool can do so much: it could show me the Tinder data, it could show me what was involved, but I was the one who had to put that link together. And just as a side thing that it’s just so important that you can never replace the, way that our brains are thinking and the way perspective happens.
Rick: Oh, let me go back one. All right. So, my perspective, I have always in my career been post collection. So, you know, we know a lot of our clients, forensics have a suite of tools they use to collect all of this data. For me, that doesn’t matter. All of this data that I see is typically collected and those processes wrapped around it, right?
So what do we see when we get that data? It’s going to be more like the databases, especially nowadays, right? So JSON from Slack or Facebook, or you might get reports out from collection. All of it really is structured databases and that makes it easy for us, certainly not easy for the documents type world, but to do proper link analysis, you do need to leverage all of that metadata together.
So I’ll show you that here shortly, but really when we start to look at a case like this IP theft case we’ve been talking about, it’s, what is most important, right? And I might even ask the audience here, as I go through my awkward transition to my demo, what are some data sources that you might think would be relevant to an IP theft department employee? What would you want as part of your investigation there?

So what I’m going to do is I’m going to segue over to a demonstration of ESI Analyst and how we pull all of these data points together. And I’d like to just see what your thoughts are on any of those data types.
All right. Should be able to see my screen. Okay. So can you all see my screen okay? Yep. Okay. So when we look at all of these modern data types, right, or today’s data, we have five categories that we put this in, and that is first and foremost, communications. Communications to us is anything where two of our people are having a conversation.
So this could be a group category that could be Slack or channel-based communications that we typically see in corporate environments. It could be third-party chat applications like you might find on your devices like WhatsApp, WeChat, Twitter direct messages, I was referencing earlier Facebook Messenger, certainly email.
You want to see that all together. Text messages, calls, voicemails, all of the attachments and media people are sending back and forth, that all helps build relevancy around those conversations and those cases. Creating documents out of each individual message isn’t very helpful or creating documents out of threads may or may not be helpful for proper link analysis.
But the second category, and this is really a free beyond devices that we find, and that is geolocation. Every time you fire up Google maps, if geo services is turned on, that will save to a table with all of those geo points, including whenever you take a picture. So that EXIF data that sits behind that picture, that all can get pulled in and you can start to find relevancy there. as well.
Now, as Amber was talking about all of those artifacts, right? So, forensic artifacts like plugging in a thumb drive, saving to that thumb drive, websites visited, logging in, logging out. All of those activities could be helpful.
Now, what we advise on is because there are literally hundreds of them, identify the ones that are most important potentially to your case. And that goes to the proportionality argument where look, you’re not going to load the whole image of the laptop or something. You really just want those artifacts of interest to go here.
Now, the next one is financial transactions. This could be debits, credits of any kind. The last category before I get into the case study here is social media. So that would be all of the posts and basically cat pictures and dog pictures and arguments and all the stuff that Facebook and, you know, social media is nowadays.
But really it’s those public-facing discussions versus as I mentioned earlier, the direct messages. We must certainly put those into a communications category here because they’re having one-on-one conversations or group conversations in those messaging apps.
Now this case study I have here is a particular individual, this is mocked up, but a case type that we see often: Jesse Bradshaw being a departed employee. So first we want to see Jesse left, is Jesse talking to competitors? Did Jesse take something?
First and foremost, we identify very quickly that Jordan here, we may know as a VP of Sales for a competing company, we might dive right into those 35 text messages to help to see what the conversations are like, build some context there. But we’ll get there because we also loaded in computer artifacts that we were curious if they showed up.
Did Jesse, like for instance, take something from the company? So, files being copied. So we’ll look at those five artifacts first and we can see right away near the top that Jesse copied something benign from the F drive. But the next one over is Jesse grabbing the Acme Anvils client list from the sales drive, this all happening on 02/04/2020.
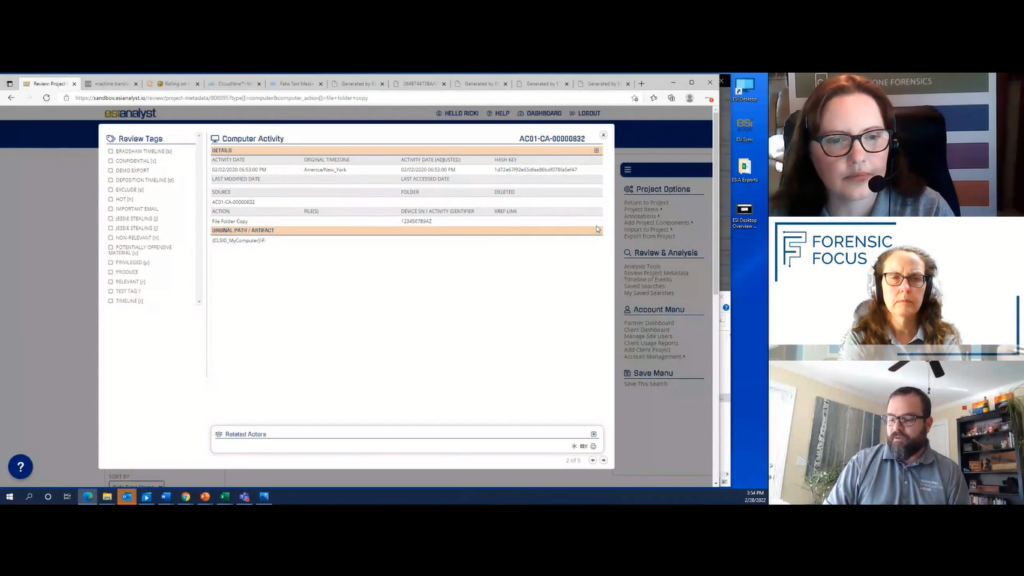
The next one being the 2018 business plan. So we know Jesse is taking some things from the company or saving some of these things. So let’s look at everything Jesse did across all data types in that particular date range. So we’ll go here, put in 02/04/2020, go out to the 7th, and really what’s important here is we want to just look at Jesse’s data because if we look it in Samantha or Sarah’s data as well, we want to limit it to just Jesse’s activities and conversations on this day or in this date range.
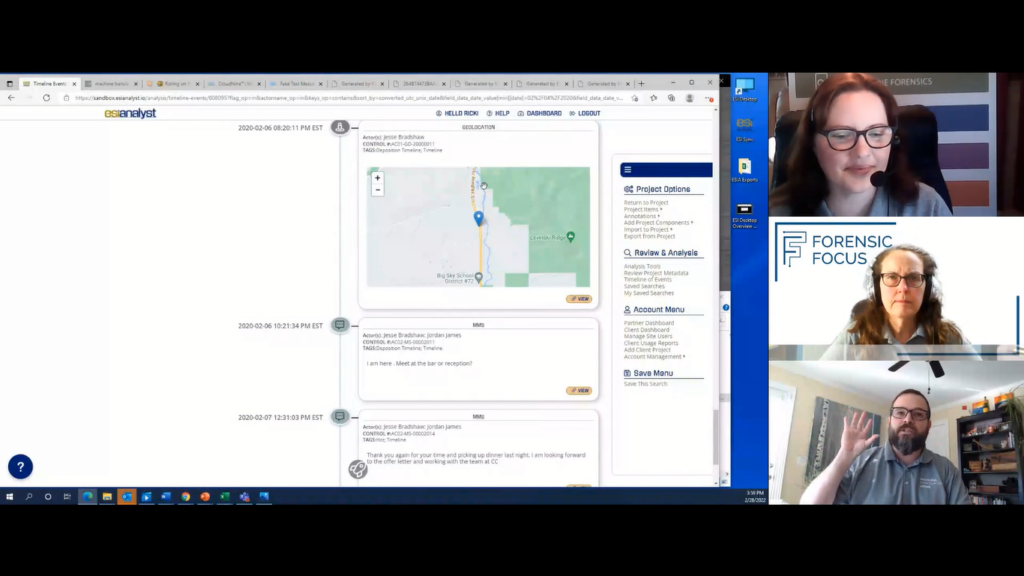
Now, using the key here, we can see a cluster of computer activity; some text messages, geolocation, so where was Jesse? And again, this is really where we start to tell that story, because the date itself is really doing that. So first for context, where was Jesse? Was he in the office? Home office? Nope, looks like he was out in Big Sky, Montana.
So that’s interesting, not the smoking gun or anything, but certainly helps build some context there. The next thing we see, we’ll go to the cluster of computer activity of these artifacts, and we see Jesse plugs in a thumb drive, goes to Google Drive, logging in, logging in grabs an IP address, so we’ll go look up there in that ping near Bozeman.
I see the two items that Jesse took, so the Acme Anvils client list, the business plan. Now Jesse’s done doing that. So he logs out, pops out the thumb drive and sends a text message to that person, Jordan, that we saw earlier.
So here, because this is data not documents, you can tag items individually. You also have access to a master conversation group ID. This will take you to the very first to very last text message between these two. And for best context, you can see their conversation.
Now, we have translation built in here, but I will hide that so you can read the conversation. So they’re talking about meeting at Buck’s T4 Lodge, say, yep, bring me those client sheets. that’s why I had to download those things, right? So we can now tag these items individually. So, but we really are starting to get a good feel for what’s going on here.
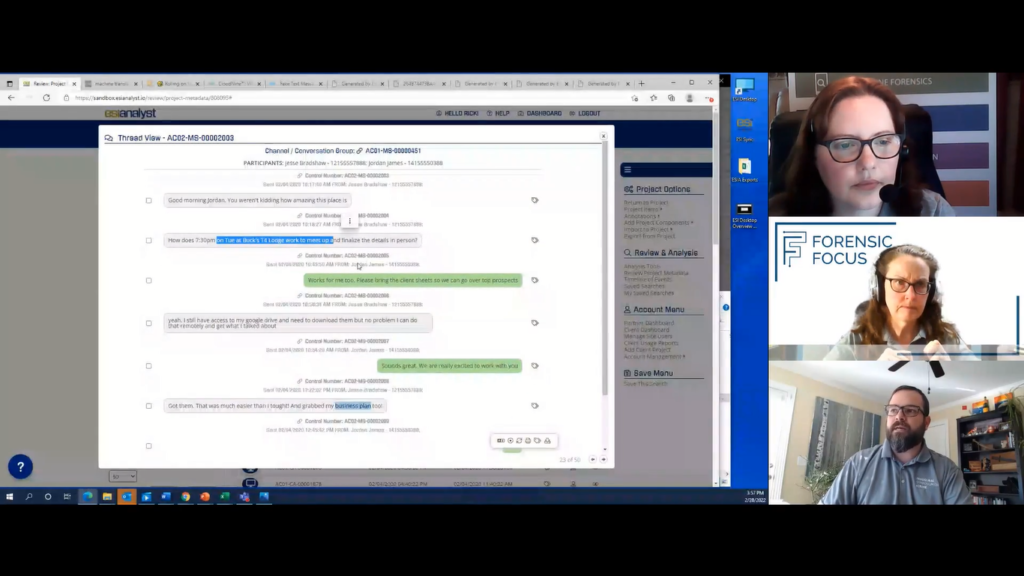
So we might say, okay, we know where Jesse was and what Jesse did. Let’s just now limit it to conversations. Now, one quick aside, another big aspect of link analysis is to make sure that you’re tying all of Jesse’s data points to Jesse; Jesse’s WhatsApp account, Slack identifier, Facebook Messenger, identifier, phone number, email, all of that.
So when I just toggle Jesse, I can see just those conversations here. And as part of the process, we pull in all of the pictures and videos as well. So Jesse’s trip to Montana does not disappoint with pictures and videos of mountains and buses and Buffalo. Videos you can certainly play online.
But the whole point that I want to show here is that context is built in the accumulation of all of this data. We could have loaded in Jesse’s Facebook account, we could have loaded in tweets, we could have loaded in anything to help build context around this. In some instances you don’t need to if you get some of that data off to, when you first start.
And the last thing I’ll show here is all of this data would be remiss if we could not create nice, pretty timelines of all of this. So all of those items that we tagged specifically to timeline is now represented in a timeline where, you know, they’re talking to Jordan about how great this place is, meeting at Buck’s T4 lodge.
So let’s just say Jesse’s in the deposition. Now he might say, “Yeah, well, you know, it was a VP of Sales trying to, you know, recruit me and I never met up with him.” We might just scroll through and highlight the activities we saw earlier about Jesse copying files and all of that and we might even just skip to the bottom here where he says to Jordan, “I’m here at the bar reception.” and then we can zoom right into where they were sitting in that restaurant.
Now, I’m not an attorney, I just play one on Zoom sometimes, but I would imagine this is where Jesse puts his head down, starts crying, the cops come in. No, I’m kidding. I’m getting out of hand, but get the idea here. So, but the whole point of all of this is, this data exists and we’re only showing a small portion of the data that could have been collected for Jesse, you know, to show here as well. All right. Let’s get back to our regular scheduled programming.
Okay. So, we had a question here and actually, if there are any questions, feel free to chat. You know, we’d like to dive into more, you know, kind of conversations there, but you know, sometimes we have the question of, well, and we can see this in our world because all of the other platforms out there are document review platforms. They’re always going to have different results than what we’re having, what you might see here.
So the question is, what do you do when two tools give you different results? So Amber, I’ll kick it back over to you for that.
Amber: I think it’s a positive day, cause in a lot of ways you kind of want them to show you something different. And I started a poll here too for our data sources for everyone, because I want the two perspectives. I think I’m going to see the same data as well, but I wang to see it brought in different ways or your tool’s going to parse the data different than what my tool is, but it’s all going to lead me to the end source. So I think it’s a real positive. What do you think? Do you think it’s a positive or negative?
Rick: Well, I think it’s, because of where we are in the process, it’s always a long conversation with the case team, you know? So we have one case and it’s interesting, they have everything, and also Relativity, which is document review platform and everything in ESI Analyst and they’re running searches and things and they’re getting different results and it’s because they created all those documents first and they’re just, everything’s getting treated just enough differently to get some different results. So it’s a challenge, but it’s one that can be explained. But to your point, Amber, it’s actually great. You might see different things, get different results and actually have, you know, see other contexts there.
Amber: I think some people don’t realize even with email, so that’s like the most traditional data source that everyone’s been used to doing forever and ever. But we have in the forensics side where we do our hash verification and you’ll get different hash verification, but you have to ask your tools, you know, are you hashing it with the complete header, the body and the attachment as one or as two parts or as three? There are so many different combinations that you can do.
And then some tools won’t hash with the entire header, and so you’ll get a variance there too. So understanding what your tools do and people are going to hate this, cause I’m going to say read that manual cause it’s fantastic. And I’m sure that you all know what that means. It’s, RTFM, it’s a fantastic manual, but it’s going to tell you how your tool is actually producing the data.
And I think that’s a really important aspect if you do end up with two different results. So how did my tool produce it versus how did your tool produce it? Was that variance why I’m seeing different results?
Christa: We do have a question here from Ashley who is asking: if an automatic tool gives you a different result than the manual tool, for example, a database browser in a mobile extraction, which one would you choose?

Amber: I would use both. I know that sounds silly. So for example, I’m going to go back to my app example. So, when I process a device and I look at an app and all of the data it produces, I will let my automated tool do the processing, show me what it looks like parsed within that tool.
But the difference is, my tool probably releases once a quarter. It doesn’t release every few weeks. Apps release every few weeks, they update often and you’re going to get a data gap that exists.
And because of that, you’ve got to go to the raw data source and that’s where the ability to go through and review SQLite, JSON and P-list files, which is what almost all of the data is existing within smartphones, that was our most popular data source in the poll, that’s where I’m going to go through a manually look and say, “Okay, look now all of a sudden there’s a new chat functionality that wasn’t there before, a new hidden messages section that didn’t exist.”
All those are going to be new databases that I can manually see. My data’s still been collected properly, but I have to do that parsing engine. That’s that value of that person in the chair. And I always actually go to the app store first before I start, just to see what version of the app they’re using, what data gap can exist.
Christa: All right. Well, I guess we can move to our final review of all the material that we’ve covered, which has been a lot today. Unless anybody has any other questions, feel free to put them in the chat or in the Q&A. Do we want to go over what were the poll results here? Almost everybody, 78% of all of our viewers see smartphone data most commonly, very small proportions in comparison with computer and cloud. That’s interesting.
Rick: Yeah. We’re seeing such a fast growing trend with device data. I mean, and it makes sense. I mean, this is the thing, as Amber was saying, we carry it, we do everything on it now. Some of the data like Slack, for instance, that doesn’t save on your phone that saves somewhere else, but we use it.
But to Amber’s point, you might know that they have that app, so those types of things may be collected. But really again, we’re finding that the devices themselves have just so much data, so much information. And they’re usually a good place to start an investigation.
Amber: Yeah. We peeked at a terabyte device a couple of years ago and I think it’s definitely become our primary data source. I think the second I’m surprised that it’s computer, because I look at a phone and I think probably 40%, maybe even half and half at this point is all represented in the cloud. A lot of apps are not storing their data locally.
And so I know I’m, if I’ve got a smartphone, I’m going to do a cloud collection, too. It’s almost inevitable. It’s like cupcakes and frosting. You’ve got to have the two together.
Christa: Yeah. I think what’s surprising to me actually about watching these poll results, which is now it’s 80% smartphone and only 12% computer and just 8% cloud. I would’ve maybe expected to see more on the cloud arena, which is maybe an indicator that that’s not maybe an area that people are comfortable with right now or have the tools for, potentially.
Rick: Yeah, I think it’s scope. I think it’s expanding out to collect those apps. We find a lot of hesitancy in case teams to go after that data. They want, you know, we’re getting them to go after devices versus just email and documents for, you know, so it’s a next logical step, but yeah, it’s really good a poll there.
Christa: We do have another chat question from Jennifer this time: do you ever see cases where identity fraud exists? More importantly, an ability to detect if a device has been stolen and misused where this illicit activity exists?
Amber: I’ve seen that, not through cloning, I know that was a big trend that everyone’s like, “My device has been cloned.” It’s actually very hard to do that type of attack. You physically have to have the device. But I’ve seen it where different identities associated with different media outlets have been used to commit fraud in another media outlet.
In our discussions prior to this panel, one of the things is one of my sock puppets that I use to create case examples and exist on the internet as a different person than myself, her information was taken by multiple people within the process of her existing, which I thought was really interesting cause I’m like, I wouldn’t have that happen, but as maybe a more typical user on the internet, that would be very realistic to have that happen. I don’t change the same security settings if I’m doing a lab example because I don’t think everyone on the planet looks at smartphones with the same paranoia that I do. I could be wrong, but…
Rick: Yeah, I haven’t come across that, actually. I’m thinking of like rattling through all the case studies. And that is an interesting one. I would imagine, you know, there would be ways to whether it was through cell tower data, through other things, just to see where that device was at a given time. But no, I haven’t come across that.
Amber: I think your point about geolocation data is really critical because it’s not one that I think everyone pays attention to and there’s so much of it. You brought up so many of the bread crumbs that are left behind with it.
Rick: Yeah.
Christa: It goes back…sorry, Rick.
Rick: Go ahead.
Christa:No, I was going to say, I think it goes back to that pattern of life data: what’s normal for this user, what’s not normal for this user, and having a really solid understanding of that.
Rick: Yeah, that’s perfect. Exactly right. And, you know, we’ve seen anything from health data, so FitBits, and I didn’t show you the cool map views and stuff, but it’s amazing the representation of just where this person plodded around in the city or went in the shopping spree and what stores that person went into. That was just, it’s generally stored in those types of devices.
So if you have a health device or health apps turned on, you might be grabbing that on a very consistent basis. And then for criminal, we’ve seen other stuff: grabbing the cell tower’s geolocation data. And we see that represented, but it’s, yeah, there’s probably enough data out there somewhere to track down what actually went on there.
Amber: We’ve had health data where it even comes in in a civil case where a divorce that actually showed infidelity because their heart rate went up at two o’clock every day cause they were having a visit. And it showed all in that and became part of, you would think that’s a privacy concern cause it’s your health data, but it became part of the scope of the case because it was an infidelity matter.
Christa: I think, speaking of pattern of life data, Jennifer’s also asking if it’s possible to trick an investigator by false social site data on the part of a professional con man?
Amber: Sure, absolutely. I don’t feel that most of the data that you generate has a lot of authentication back to the person. I don’t know if it makes any sense.
Christa: I feel like you’d have to get really, really granular with that pattern of life data to be able to differentiate the two and most people probably don’t have the time or the money to do that, so…
Amber: I think the hardest part about all digital data is proving that it was the person generating it. No matter computer phone cloud, whatever, it’s just that it was the person.
Christa: Putting the person behind the keyboard.
Rick:Yep. Great questions.
Christa: Yeah, For sure. All right. Yeah, I think that wraps it unless anybody has any, we’ve got about five more minutes, four more minutes here. If anybody has any other questions for any of us?
Amber: I think that that was a good statement. That’s why they get away with it. It is hard. This is not the easiest field. It’s nice, though. It’s binary: it’s either there or it’s not, which is a benefit, but it still is, there is that reasonable doubt of proving that person behind the screen.
Rick: You know, and it’s interesting about that as well and how they get away with it. Sometimes all of that data could be collected, exists, sitting on an investigator’s table, but never opened, right? Because we’ve seen that when they try to, it’s PDFs, HTML, it’s just a big pile of data and they just end up saying, forget it.
And I think it was a prosecutor or it was somebody that they said, you know, that my biggest thing that keeps me up at night is not the fact that I don’t have the data, it’s the fact that I don’t know what to do with it.
Amber: That’s a very good point.
Rick: And so we coach a lot of teams to ask for the UFDR, ask for the containers of data, not the PDF reports, the HTML reports, you know, all of those, because then all of that has to get extracted out to do something with, unless you’re just going to go flipping through millions of PDFs. And so that’s a big challenge we see. And so that’s why we took that focus on data and structured data versus a documents approach.
Amber: I imagine if we all took the data that we generated, just in a day plus, looking at our computers and things like that, we would fill the University of New Haven with pieces of paper that would represent all, of that quickly and easily. And no one would ever want to go and sort through it all cause it’s overwhelming.
Christa: All right. I guess that wraps it. Eva says thank you. Thank you all for listening.
Amber: Thank you.
Rick: Thanks, everyone.
Rob Fried: Thank you very much, everyone and a great panel. I appreciate everybody’s time and the efforts that were put in for it. So we have our next session, which is going to be a Q&A, a general Q&A for all speakers that can join as well as closing today’s event. So if you can join, we’ll reconvene in about 15 minutes to wrap up today’s event.





