Tara: Hey everyone, Tara Melton here, and I’m going to be showing you a new and exciting feature introduced in AXIOM 4.8. Now you can extract text from certain files using optical character recognition, or OCR, technology.
AXIOM will extract text from picture artifacts and PDF documents, including scanned documents and pictures within those PDF files.
So I’m here in AXIOM Process, I have my case details, I have some evidence loaded in; and you can see that you have the option here to process your case with OCR upfront. And you can select to run it against PDF files, or pictures, or both.
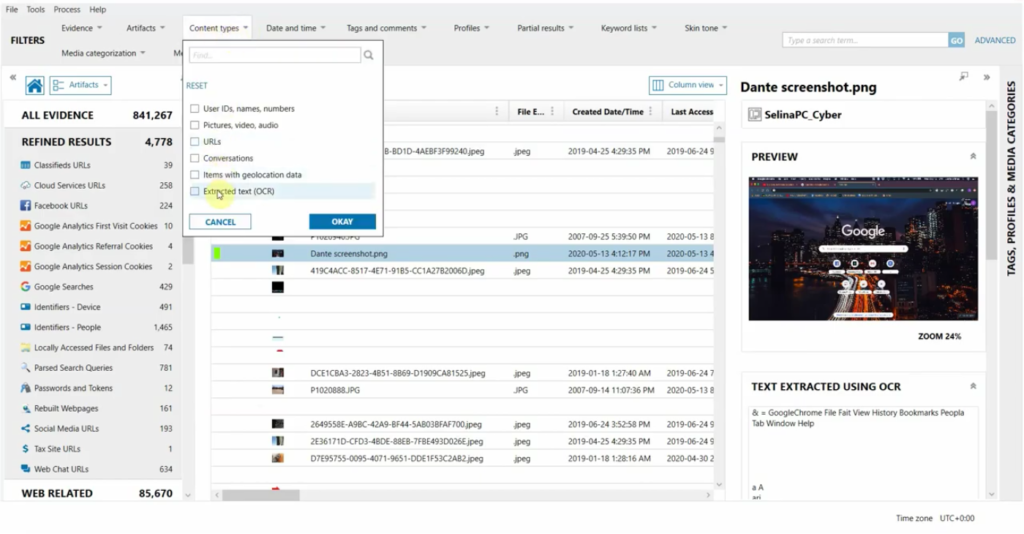
So I already have a case processed, so I’ll switch over to Examine, and we can filter to those files that have output to OCR quickly by using this content filter here at the top. And when I do, you can see that’s going to go ahead and narrow that down pretty significantly so I can actually just look at the files that only have that OCR output.
Now to show you what that OCR output looks like, you’ll see over on the right-hand side there’s an additional details card that will show the text that was extracted via OCR. And this will really help when you’re doing global searches, so that the text extracted when you’re doing OCR can also be searched.
So I’m going to go ahead and just type something in there. And there you can see that the keyword that I just searched for is highlighted in that extracted text.
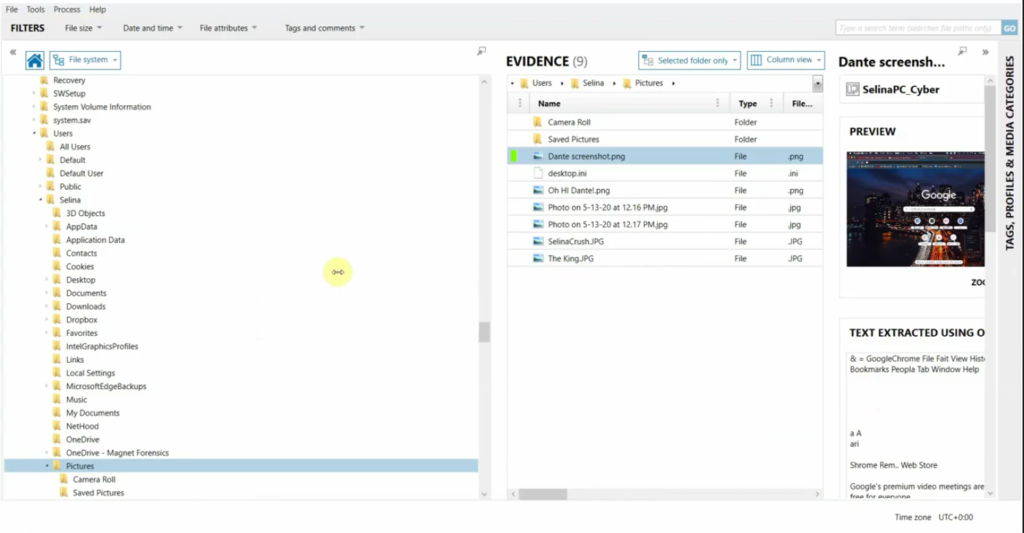
And then also note that this additional extracted OCR data can be found not only in the artifacts view, but also in the file system view. So as I switch over here, you’ll see that details card with the extracted text, and then it can also be found in the timeline and connections view as well.
I’m going to switch back over to the artifacts view. Now, if you don’t want to run OCR initially, in the beginning of processing your case, you’re also able to run it in Examine as well. You just go up to the process menu at the top and select ‘Extract text from OCR.’ And you’re able to again run it against your PDF files or the pictures in your case, or both, and you can also choose in this view to run it against all items in your case, or only the items in your current view.
So we hope you find this feature useful in conducting your examinations. Please let us know what you think, we’d love to hear your feedback. Thanks for watching, everyone.





