Keith Lockhart: Hi, Keith Lockhart here, Director of Training for Oxygen Forensics. Here’s a short video on Version 13 and the new Optical Character Recognition built in.
Okay. Let’s have a look. So I’m just going to go to our options gear here, where I can get to my kind of global settings for Detective. I’ll check our advanced analytics section, where we have facial categorization, image categorization, and optical character recognition.
So what do we have from an option perspective? Well, we can turn off or back on. What would be the significance of that, you would say? And if you remember me from my previous DFIR career at AccessData, just in case, you know, in FTK, we literally had a tick box in the preprocessing section that if you turned on OCR, it said something close to the effect of you are about to add 50% processing time to this job: prepare, or something like that. I mean, OCR is a task, to be sure. Lucky for us, Detective is a 64-bit environment that will use the hardware you have available. So when we’re running an OCR job, it’s always fun to check the task manager, make sure things [are] at a hundred percent. I mean, tapping that thing out because it takes work to get this done. So off or on, depending on your needs.

Now, think about this. What about this workflow? So you pull a bunch of pictures in that look like documents… dun dun dun. If I scroll down in image categorization, wow, maybe they’re identified as documents, so you can actively filter and seek those out, and then come back and just OCR those. Check mark them, however you want to segregate them; do it when you have time. And certainly not against everything, maybe just the things that look like documents right out of the gate.
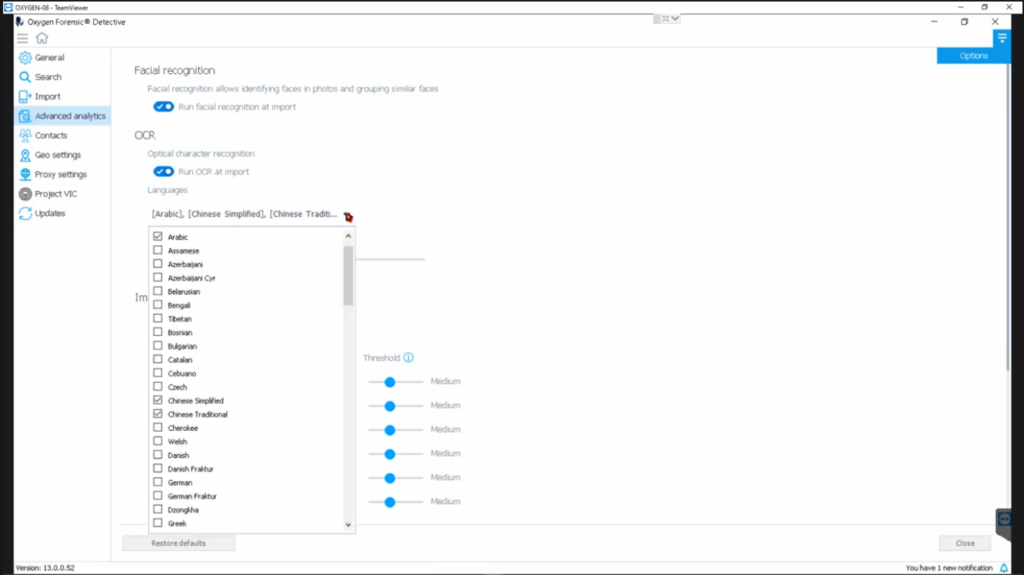
So this is the gears that need to start turning, especially on a page like this, where you have all of these interesting technologies available to you. Other option: languages that come with OCR, holy smokes. There’s a huge list, which kind of begs the question, which is also a requirement, you need to do this, where do I get the languages? Well, let’s go out here. I’ll just hit the updates module there. And I’m going to go out to my customer portal, which you should do too. Because when you get out there on top of the Detective download is the OCR language pack. Pull that down and install it. And that is how you get to this list. Okay. Look, I wouldn’t set them all at once. I mean, to be sure. And you can set them at each import job based on that import options menu. But you know, be selective, be smart about the time you’re spending.
And then what size picture do you want to go after: minimum and maximum pixel sizes?
Okay, let’s see how it works. I’m going to go to the import screen. And in this particular case, I just have a folder full of stuff on the desktop. I’ve already selected it. OCR data, I’ll select that folder. And here, like I was saying, you could go to the analytics section and change your job parameters for this import. I’m good. I’ll import and off it goes.
Now when it does this, I’m just going to go ahead and look, because I’m fanatic about more power, more power! And you know what? I’m at 37%… oh, I’m at a hundred percent… 50. I’m… you know, this probably isn’t a job big enough to have enough forethought to go: we’re going to tap out for a while. But I’m at 96, 80, 78. And I’m using all the cores available to me right now. This is a good thing. I mean, that’s what you want to see, is the hardware really putting itself toward that job. So I’ll get that out of the way. It’ll take just a second.
[inaudible]
Okay. So now I’m going to open this. And it’s sitting here, and unassigned extractions. Terrific. I’ve got six files: four is key evidence, and one of the timeline. So let’s first look at the six files.
Okay. They all happen to be… file section. I think they’re all images as well, all six of them. And we can tell just from the thumbnails, they all look like documents of text. So true. But let me also go back to the all files. And I happen to have four that are already tagged – shocking – as documents, because that was the conversation we were just having from a workflow perspective. Matter of fact, if I go back and look at the extraction info, I have four items of key evidence. I didn’t do anything. I haven’t even looked at it yet. However, if I just check right here, there are four things that are tagged already as documents, like we just had that conversation about that workflow. So terrific.
I’m going to jump down here to the OCR new analytic section and I’ll click there. And here’s how the OCR analytic pane looks. I’m just going to give myself some more real estate here. Now you gotta understand we’re using the Tesseract engine. There are several out there. Your mileage may vary. You know, it might… in this particular instance, I’ve got language.jpg, and I got nothing down there as indicated by, you know, there’s nothing, there’s no text to be seen here. However, this one, which is highlighted or lit up in green: if I click this one, I’ve got all kinds of text down here. So, watch this, as I click on this line, it tells you right where it’s getting those words. And this is quite the example, a lot of hodgepodge there, but it’s gathering stuff from there.

‘Fluency,’ I can see that word there; ‘lifestyles.’ is in there, and I don’t know, ‘real life English’ right there, kind of a blurb on that. And ‘real people.’ And I also selected the Arabic dictionary as one of the dictionaries I was using the go through this stuff, so… and Chinese. So it’s actually thinking, it can find something similar to a character like that based on the different fonts here. Love it.
Don’t know what that… is start it, help, but this is just an interesting example. This is almost like a capture with all the different fonts and different sizes and different colors, but you can see what we’re getting out of that as a searchable, now, item. All right, let me check this one: newspaper. I mean, this will probably be almost verbatim and I can scroll down and read nearly the entire document based on almost a word-for-word extraction of the newspaper clipping.
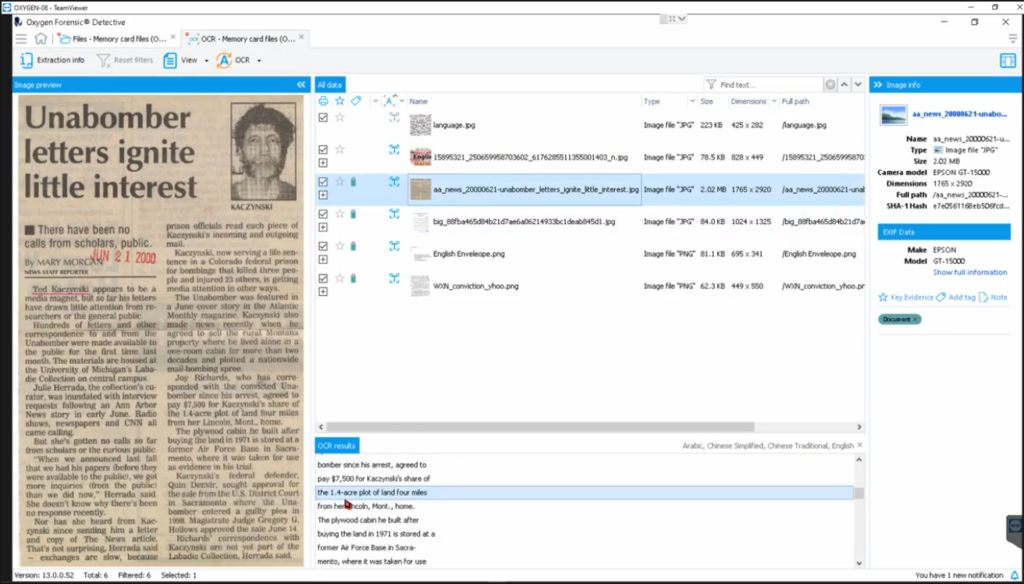
This one is an Arabic document. Now I don’t speak or read Arabic. However, I’m just going to do… from a demonstrative purpose. I’ll grab this cell, and I’m going to right click and copy it to the clipboard. I’m going to just jump back to the search functionality. And I’m going to paste that in here as a text word, or a text string. Matter of fact, I’ll get rid of ‘2015’, just so we have that. I’ll search through file content and go. Shouldn’t take too long. And look at that. There’s the source file of that hit, and the hit, and it’s crazy. Crazy. Really cool. How about I, how would I change that? They’re really cool. Not crazy, but really cool. I’m going to just jump back there and back to our OCR.
English, there is an envelope picture, you know, a lot of block lettering, so you can kind of see what you’re going to get from that. And, Oh, Chinese, there we go. Chinese. So let me go over here to a little bigger data set, or a couple more items of… your mileage may vary… and look at Alison’s data set. If I just go check her OCR, that’s not Alison… if I check Allison’s OCR. A couple of my favorites, like this one right here. I mean, this is certainly a capture thing: crazy fonts, colors, patterns, and it’s extracting words out of there. I love it. I don’t care about you; Friday, I’m in love; Wednesday, Thursdays…. That’s a really interestingly cool example. Oh ,right above that one is the British Airways. Well, almost British Airways: close. I mean, clear out there on the airplane in that picture. That’s really cool. I don’t know where the SU is. Oh, something also up on the airplane.
You know, again, your mileage may vary. CBS news: got news. A user picture got google.ru from the search bar. Let’s see. What’s this one? It looks like some kind of flyer, with all kinds of texts. And again, if I just give us some real estate so we can kind of compare: summer school, learn musical, experienced tutors in preparation for an early evening show at the… I mean, word for word, that’s great stuff. And that’s all searchable.
Your options look like this: recognize text on an image; and what that boils down to is, you can filter. And here’s an example. Let’s do both here. They’re both in there. If I sort, look, these are things that didn’t have text. Let me try to force them through there. That’s a Q, let’s try that one. I’m going to pick that one.
My other option is: do it; do just that one. Recognize text. Let me hit it… and still nothing. Fair enough. However, this is a quick way for you to figure out where you need to go. Let me just turn off the ones that don’t have it; only show the ones that did, and start going through like that. Database filtering. So, recognize text on nothing analyzed; recognized text on just checked items; database functionality there, right? And OCR settings, where we could go back and change these settings to run it again.
Okay. There’s your quick introduction to OCR in version 13, download today. It’s got a lot of awesome, cool new functionality in it. See you soon in class, have a great one.





