KS – an open source bash script for indexing data
ABSTRACT: This is a keywords searching tool working on the allocated, unallocated data and the slackspace, using an indexer software and a database storage .
Often during a computer forensics analysis we need to have all the keywords indexed into a database for making many searches on it in a fast way.
We could use strings and grep, for searching the keywords, but we cannot have a database and an engine, then we can’t search them inside many formats, like compressed files, including the ODT, DOCX, XLSX, etc..
So, I tried to solve this problem, first of all we need to extract, what I call “spaces”:
1) Allocated space;
2) Unallocated space;
3) Slackspace;
Then we can run the indexer against these three spaces and we can extract all the keywords inside them.
We must remember that we have two kind of unallocated spaces, the first is all the deleted files and the second is all the files those are not in the deleted set, but they are still on the memory device (hard disk, pendrive, etc.).
For extracting these file we need to use the data carving technique, that consists into the search for the file types by their “magic numbers” (headers and footers), this technique is filesystem-less, so we can gather all files, allocated and unallocated (including the delete files too), so we need to eliminate duplication generated by carving.
The slackspace can be extracted by the TSK (The SleuthKit ) tools and put into a big text file, we have to remember that slackspace is all the file fragments present into the unused cluster space.
Inception
We have to create a directory named, for instance, “diskspace”.
We can mount our disk image file (bitstream, EWF, etc) into a sub-directory of diskspace, e.g. /diskspace/disk and so we can have all the allocated space.
Now, we have to extract all the deleted files including their paths and put them into “/diskspace/deleted”.
We have to run the data carving and put all the results into “/diskspace/carved”, we can use the data carving only on the freespace of the disk and then we must delete the duplicates with the deleted files.
Finally we can extract all the slackspace, if we need it and put it into “/diskspace/slack”.
Now we got:
/diskspace
|_disk
|_deleted
|_carved
|_slack
We only need a “spider” for indexing all these spaces and to collect all the keywords into a database.
For this purpose there is a program in the open source world: RECOLL that indexes a content of a directory and allows various quests. (http://www.lesbonscomptes.com/recoll/)
After the indexing we have all to perform our researches.
All these operations are made by my bash script called KS.sh http://scripts4cf.sourceforge.net/tools.html
KS – This is a keywords searching tool. sudo bash ks.sh for running it. It mounts a DD image file; It extracts all deleted files; slackspace; It makes a data carving on the freespace only; It indexes all by RECOLL.
You need:
The Sleuthkit (last release)
Photorec
MD5Deep
RECOLL
It stores the index DB and the recoll.conf in the chosen output directory.
NEW file formats added and README.txt for the HowTo expand the search range.
Website:
http://scripts4cf.sourceforge.net/tools.html
This is the bash script code:
#!/bin/bash
#
# KS – by Nanni Bassetti – [email protected] – http://www.nannibassetti.com
# release: 2.2
#
# It mounts a DD image file or a block device, it extracts all deleted files,
# it makes a data carving on the unallocated space, the it runs recoll
# changing automatically the variables in recoll.conf.
#
# many thanks to Raul Capriotti, Jean-Francois Dockes, Cristophe Grenier,
# Raffaele Colaianni, Gianni Amato, John Lehr, Alessandro Farina
echo -e “KS 2.2 – by Nanni Bassetti – [email protected] – http://www.nannibassetti.com \n”
while :
do
echo -e “\nInsert the image file or the device (absolute path): “
read imm
[[ -f $imm || -b $imm ]] && break
done
while :
do
echo “Insert the output directory (absolute path):”
read outputdir
[[ “${outputdir:0:1}” = / ]] && {
[[ ! -d $outputdir ]] && mkdir $outputdir
break
}
done
(! mmls $imm 2>/dev/null 1>&2) && {
echo “0”
echo “The starting sector is ‘0’”
so=0
} || {
mmls $imm
echo -e “\nChoose the starting sector of the partition you need to index”
read so
}
HASHES_FILE=$outpudir/hashes.txt # File output hash
DIR_DELETED=$outputdir/deleted # Deleted File’s Folder
DIR_SLACK=$outputdir/slackspace # Slackspace’s Folder
DIR_FREESPACE=$outputdir/freespace # Carved File’s Folder
BASE_IMG=$(basename $imm) # Basename of the image or device
[[ ! -d $outputdir/$BASE_IMG ]] && mkdir $outputdir/$BASE_IMG
off=$(( $so * 512 ))
mount -t auto -o ro,loop,offset=$off,umask=222 $imm $outputdir/$BASE_IMG >/dev/null 2>&1 && {
echo “Image file mounted in ‘$outputdir/$BASE_IMG'”
}
# recovering the deleted files
echo “recovering the deleted files…”
[[ ! -d $DIR_DELETED ]] && mkdir $DIR_DELETED
tsk_recover -o $so $imm $DIR_DELETED
# extracting slack space, comment if you don’t need it
echo “extracting slack space…”
[[ ! -d $DIR_SLACK ]] && mkdir $DIR_SLACK
blkls -s -o $so $imm > $DIR_SLACK/slackspace.txt
# freespace and carving
[[ ! -d $DIR_FREESPACE ]] && mkdir $DIR_FREESPACE || {
rm -R $DIR_FREESPACE
mkdir $DIR_FREESPACE
}
# using photorec to carve inside the freespace
photorec /d $DIR_FREESPACE/ /cmd $imm fileopt,everything,enable,freespace,search
# taking off duplicates from carving directory
echo “taking off duplicates from carving directory…”
[[ $(ls $DIR_DELETED) ]] && md5deep -r $DIR_DELETED/* > $HASHES_FILE
[[ $(ls $DIR_FREESPACE) ]] && md5deep -r $DIR_FREESPACE/* >> $HASHES_FILE
awk ‘x[$1]++ { FS = ” ” ; print $2 }’ $HASHES_FILE | xargs rm -rf
[[ -f $HASHES_FILE ]] && rm $HASHES_FILE
# RECOLL configuration to have a single recoll.conf and xapiandb for each case examined.
echo “RECOLL is indexing…”
rcldir=$outputdir/recoll
recollconf=/$rcldir/recoll.conf
mkdir -p $rcldir/xapiandb
cat > $recollconf << EOF
topdirs = $outputdir
dbdir = $rcldir/xapiandb
processbeaglequeue = 1
skippedPaths = $rcldir $rcldir/xapiandb
indexallfilenames = 1
textfilemaxmbs = -1 # for indexing txt files greater than 10Mb thanks to Alessandro Farina
usesystemfilecommand = 1
indexstemminglanguages = italian english spanish
EOF
recollindex -c $rcldir -z >/dev/null 2>&1
case $(tty) in
/dev/tty*) echo -e “\nStart on terminal from graphic interface the following command:”
echo -e “recoll -c $rcldir\n”
exit 1
;;
*) recoll -c $rcldir >/dev/null 2>&1 &
exit 0
;;
esac
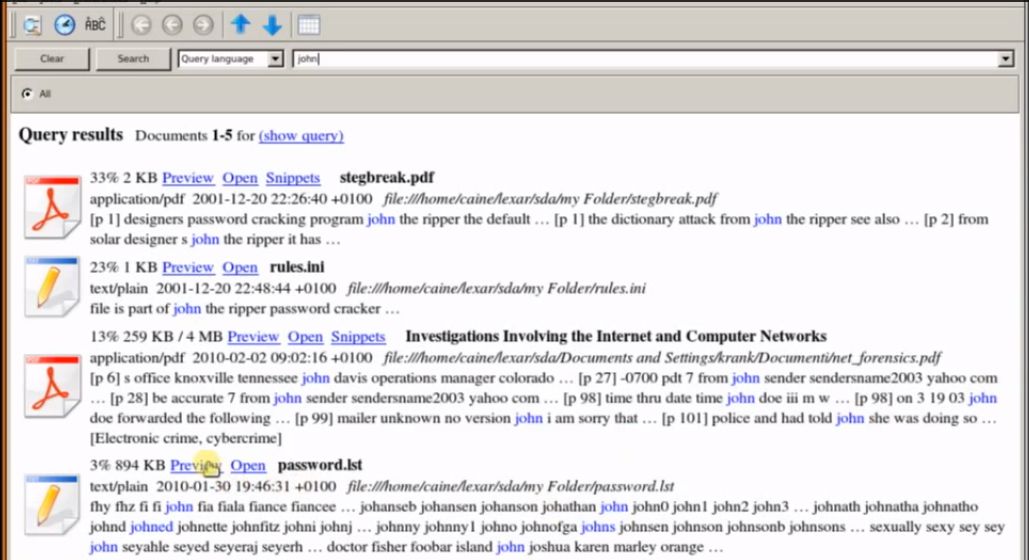
1- RECOLL in action.
The RECOLL allow the search for keywords also working in compressed files and email attachments in short, once indexed all the content you had to be able to search for keywords or phrases, just as you would with Google.
As all the open source projects I have to thank to the collaboration of some friends and developers.
Author
Nanni Bassetti, Digital Forensics Expert, C.A.IN.E. Linux forensic distro project manager, founder of CFI – Computer Forensics Italy, mailing list specialized in digital forensics topics, codeveloper of SFDumper and founder of the web site http://scripts4cf.sf.net.
Personal website: http://www.nannibassetti.com – e-mail: [email protected]






Thank you sir, it looked good!
in the release 2.2 I added this:
textfilemaxmbs = -1
after the line
indexallfilenames = 1 for indexing text files greater than 10Mb
Thanks to Alessandro Farina