Hello everyone. My name’s Wen Qiaokun. It’s my great honour to be here making this presentation about my research topic, and the name is ‘CNN based zero-day malware detection using small binary segments’.
Okay, let’s start. Firstly, why I want to do this, this is Symantec’s report published in February in 2019. We can see that the number of new malware variants is still very high. By the way, zero-day malware means a malware that’s new and has never exist before, and most office tech is on windows operating system. PE file is a type of file which can be executed on windows. So I chose PE files as my aim of detecting.
So this comes a problem, it is the most difficult part obviously in my research – data collecting. Because “zero-days” are the malwares that never exist, but the malwares we can get now are all existed. They are all not zero-days. A solution for data collecting is firstly, at March of 2019, I collected the data before March and I downloaded some antivirus tools and did not update them anymore. Which means I did snapshots for those antivirus tools at March. So to keep the ability level of detection in March.
And then in August, I collected the malwares between March and August and used my snapshots of antivirus tools to do the detection. If all of the antivirus tools cannot detect the files as malware successfully, it can be seen as a “zero-day”. So finally, I used data before March for training set and data between March and August as a testing set.
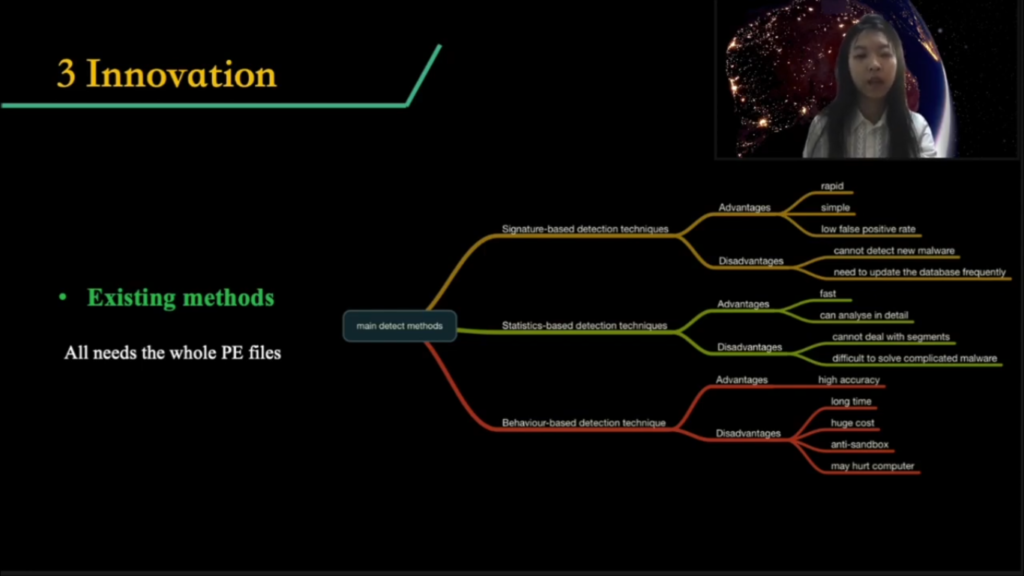
This page shows the existing method. The most traditional antivirus tool uses signature as the detection method. This technique is primarily based on the idea of pattern matching. The staff manually or automatically creates an unique label for each malware, which is called a “signature”.
The signatures often include a variety of different attributes, such as file hashes, common strings, or bytes. And then the staff create a malware signature database. When detecting antivirus tools, we’ll compare the signature of the unknown code with the content of the database. If it matches, the code will be judged as malicious code. Obviously the downside is this method cannot do anything in the face of viruses that have not appeared before.
Another method is behavior based. This method is just run the malware and just see it’s behavior, see what it have done to the computer. This method has a low false alarm, which is good, but it always costs a lot and needs a long time. In addition, a lot of malware holds an anti-detection architecture. When it finds it is running in a set walks or isolated environment, it kills itself so we cannot detect it.
So researchers come to static based method, which means we just observe the feature of the file without running it, without doing anything to it. Actually scientists did a lot on this. They propose to detect based on features from PE-headers, assembly code, or just binary itself. But all of those methods need the whole PE file. So we are thinking about, can we use just more segments to do the detection? This is this the other innovation, exact for the data collecting methods.
So why we want to use segments? There are several reasons. Firstly, it’s because of the various kinds of malware making technologies, some malwares host a self destruction program, which means after running it deleted itself. This means this malwares may only leave small segments on the disc. We cannot get the full of them.
Other scenario is some malware split itself into several parts and then call itself to run the whole malicious functions. The second reason is, different companies or institutes obtain malware samples by capturing package which goes through this systems and because of the limitation of package LAN, we usually get only a segment of the malware and we want to detect whether the data hosting one package is a malware. The third reason is higher efficiency, we can see that it’s really better to only use a small segment to get the final results, it saves times and energy.
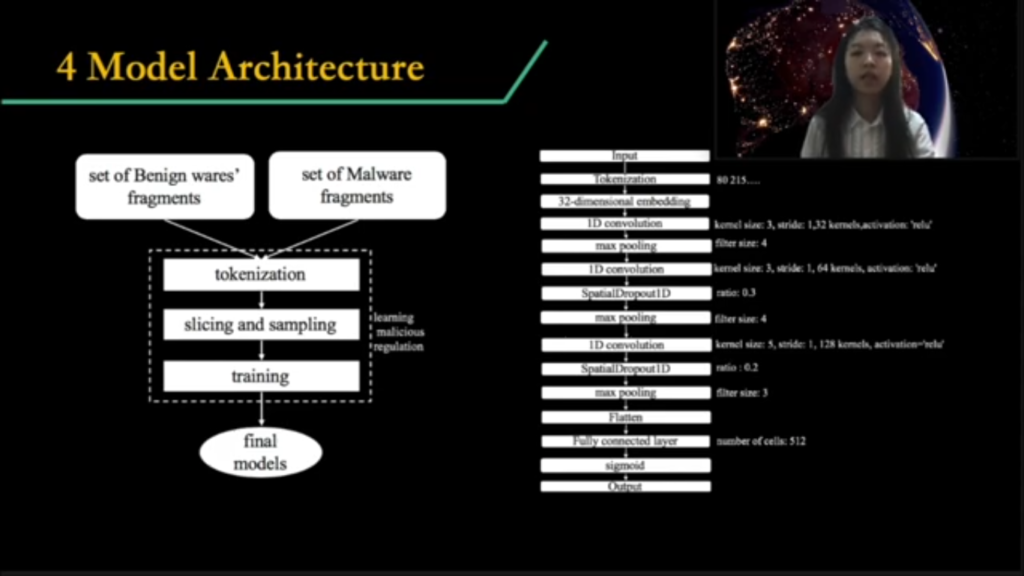
This is the architecture of my model. Basically, it’s based on experiments, which means through a lot of exact experiments and [comparison], I finally found the best one. And I try to explain why the model like this is the best.
This first question is why I’m using deep learning. As I said in the past, researchers always extract features like size of file, size of header, to do the detection. But human beings can never find all the features for malware that did not be discovered before.
At the same time, deep learning combine low level features to form more abstract, high level representation, attribute categories, or features to discover distributed feature representations of data. So, deep learning is a good method in zero-day detection.
And the reasons for choosing CNN is, compared with RNN , which is the most regular used method for time sequence data, obviously binary is a time sequence data but we found CNN is more suitable. Because the numerical distribution of the malicious code binary is relatively sparse, usually many bits means only one word. And also the translation invariance of CNN helps to solve the problem that distribution of each part of the PE file is random. Then finally, CNN is very quick.
For the parameters setting part, I use small convolution kernels in order to achieve more multiple nonlinear layers. And also, I used a 1D convolution filter to feed the time sequence situation. After all, binary is time sequence. And also, I used the “spatial dropout” method to reduce overfitting.
I mainly did two kinds of experiments. The first one is extract continuous segments with different LAN. The second one is extract un-continuous segments in order or not. This aims to simulate package capturing, because we may receive packages not in order. So I also do experiments on different parts of the segment to see how different extracted positions affect detection performance.
The following pages shows the results I got. This page are different extract methods and different lengths. These two tables are different models for different extract methods, and we can see CNN is the best.
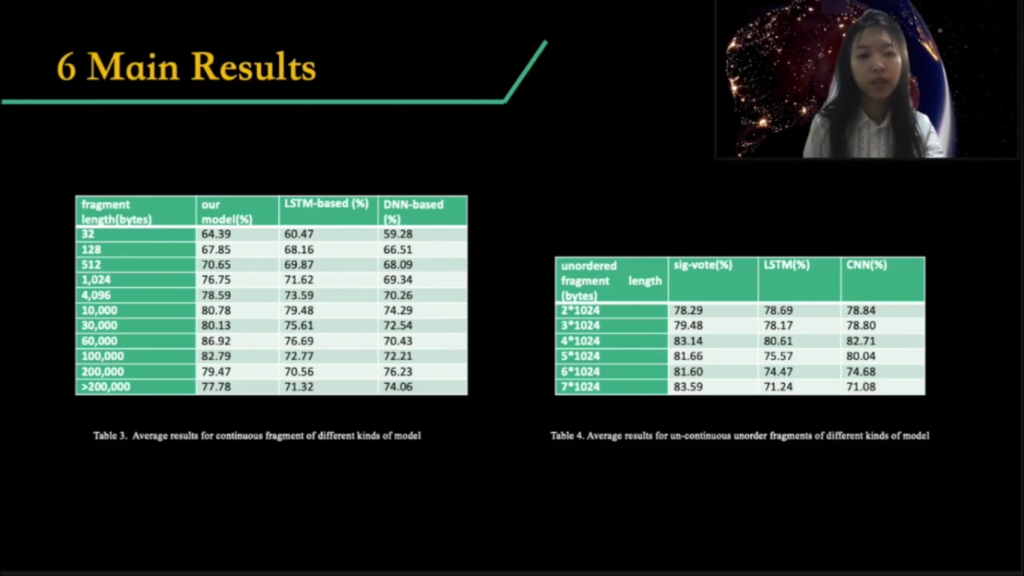
Those page shows the accuracy using different extract position. And this page shows the main results. We can get that nearly 87% accuracy for 68,000 bytes continuous zero-day malware fragments, and 95.27% accuracy for ordered un-continuous 6 KB bytes fragments.
83.6% accuracy for unordered un-continuous 7 KB bytes fragments. And for different parts of PE files, the front part of PE-header or “PE-header pod” performs better than others. The best accuracy is nearly 90%. So, when the whole file come in, we can only use the front part or PE-header part to do detection, to improve the efficiency.
In this paper, we have described a malware detection by using small fragments of them. CNN based method is used to effectively avoid the risk of extracting fractured features. We experimented with continuous and un-continuous, ordered and out of order malware fragments and came up with some conclusive experimental conclusions.
We believe that we have contributed to this malware detection field, including firstly, we proposed a method based on detection of small malicious code fragments and gave the usage scenarios of methods in digital forensic process.
This method can detect both malware fragments and entire malware. Secondly, through observation of the data, we explained the reasons why the CNN model is selected when directly using binary to do the detection. The reasons include captures of binary like sparsity of input, complexity of time and space, and the relationship between CNN’s translation invariance and structure of the PE file.
Thirdly, we experimented with continuous and non-continuous ordered and unordered malicious code fragments, comparing their final effects and playing the effects finally proved that it is reasonable to detect malwares using small fragments only. In the future, we will continually modify the model to improve the detection rate. We will also try to find out why deep learning can successfully detect malicious code using very short fragments and try to explore its interpretation in the next step.
Okay, so this is all of my presentation. Are there any questions?
So finally, thank you for listening.





