In this video from DFRWS-EU 2022, Pedro Fernandez-Alvarez describes research focused on the Telegram Desktop client, in particular the client process contents in a Windows system’s RAM.
Session Chair: We are now in the topic of memory forensics, and we have a virtual speaker: it’s Pedro Fernandez-Alvarez. He and his colleague, Ricardo Rodriguez, made a paper, and it’s about extraction and analysis of retrievable memory artifacts from Windows Telegram Desktop applications.
Pedro: Hello, everybody. I am Pedro Fernandez-Alvarez, and I work at the University of Zaragoza in Spain, and I’m going to present a work that Ricardo Rodriguez and I have done titled “Extraction and analysis of memory artifacts from Windows Telegram Desktop application”.
Instant messaging applications allow us to communicate quickly and easily. And today a large part of society makes use of these kind of applications in order to have conversations. Unfortunately, sometimes these applications are misused by cyber criminals for malicious purposes, like harassment or extortion.
The forensic analysis of instant messaging applications can provide essential clues to solve or clarify a possible crime, because they store data such as messages or contacts that can be relevant to an investigation. When these applications store their data on an encrypted database and the communications with the servers are also encrypted, then disc and network forensics are limited.
But however, the application needs to decrypt the data at some point to be able to work with it, and the location of that decrypted data will be the RAM, making memory forensics very important when the database and the communications are encrypted.
Due to the popularity of smartphones, most of the research related to instant messaging applications is oriented to mobile platforms. However, less attention has been paid to desktop applications. Telegram is one of the five most popular instant messaging applications globally.
And in particular, in this work, we have focused on the Telegram official client for computers called Telegram Desktop. The goal of this work is to study the contents present in the RAM of the Telegram Desktop process in order to identify digital artifacts that can be relevant to a forensic investigation.
With regards to the scope, we have focused on the version 2.7.1 of Telegram Desktop for Windows 10. And we have chosen Windows 10 because it is most popular operating system for desktop devices nowadays. One thing to mention here is that the Telegram Desktop database is encrypted and the communications with the Telegram servers are also encrypted.
With regards to the research in the memory forensics field that is focused on instant messaging applications, we have seen research targeting different devices, like smartphones or computers, different operating systems, like Windows or Android, different instant messaging applications, such as ones that support Telegram, and different application versions like the mobile or the desktop version.
All the references to these articles can be found in the associated paper that goes with this presentation. In all this works (normally, although not always) the researchers are able to retrieve data about conversations from the memory with various degrees of success. After analyzing all this works, we haven’t found research targeting Telegram Desktop for Windows.
Regarding the background, on Windows, each process has its own private address space, which is divided into blocks of the same size called pages. Operating systems that have support for virtual memory need to somehow maintain a relationship between the virtual and the physical memory.
And on Windows, the virtual memory manager is responsible for that. Also the virtual memory manager is responsible for saving pages from RAM to disc when there is not enough space in RAM to store all the pages for other processes.
Later, when a process requests a page that is on disc, that page will be loaded back into memory, and that is called memory paging. When an image file corresponding to a certain application is run, Windows creates a virtual address space for the new process and maps the image file into memory.
Also, memory for the stack and the heap is allocated, and additionally the application will depend on certain system libraries, called DLLs, which will be mapped into the process address space.
With regards to Telegram, it is a multi-platform instant messaging service with client server architecture. In order to use Telegram it is necessary to have a user account, which is associated with a mobile phone number. Once you have an account, you can set a user name so that people can find you by your user name instead of by your phone number.
In Telegram, in addition to text conversations, voice and video calls can also be made. Telegram applications can be locked with a password, so that the user must enter that password if they want to access the application.
In this work, we have built an analysis environment for instant messaging applications based on a three phase analysis methodology commonly used in digital forensics.
The first phase in this methodology is the extraction phase, where we obtain the data that we want to analyze.
The second phase is the analysis phase, where we analyze the data that we extracted in the extraction phase in order to identify relevant digital artifacts.
And the third phase, the reporting phase: in this phase, a report is generated with the artifacts that were found in the analysis phase.
In this slide we show a high level diagram of the analysis environment, which is composed of two command line tools, facilitating their integration into coded analysis patterns. The first tool…well, both tools are open source, and have been released under the GPL version 3 license.
The first one of these tools called Windows Memory Extractor takes care of the extraction phase and it obtains the contents of a process that is running on a Windows system.
The second tool, Instant Messaging Artifact Finder, or IM Artifact Finder, takes care of the analysis and the reporting phases. And it analyzes a process dump from an instant messaging application previously taken with Windows Memory Extractor, and then it generates a report containing the information about the artifacts that were found.
Windows Memory Extract is a C++ tool that doesn’t need to be installed in order to be used. As a result, a forensic analyst can have this tool on their USB drive and run it from there, minimizing in this way the contamination introduced in the system under analysis.
In order to dump several memory regions from a given process, a process ID must be specified to this tool, as shown at the bottom of this slide. A memory region is just a set of contiguous pages and each memory region has a certain protection like “read only” or “read-write”.
By default the tool only extracts the memory regions that do not have execution permissions. However, the tool accepts an optional argument to specify the protections that the memory regions that we want to extract must have.
Additionally, it also accepts an optional argument to specify the name of a model, for example, the name of a DLL, if we only want to extract the regions corresponding to a particular DLL.
On the right side of this slide, we can see an output generated with this tool, which is a directory that contains several files with the DMP extension. Each DMP file corresponds with a memory region and their nomenclature is as follows: first the virtual memory address where the memory region starts is indicated, followed by an underscore that acts as a separator, and followed by the size of the memory region.
With this nomenclature giving a virtual address, we can know the file to which it corresponds and the exact location inside that file.
As a result, we can access an element which is stored at a particular virtual address, which allows us to navigate through a process tab from an object A to an object B, because if the virtual address of the object A is stored inside the object A and we can somehow locate object A, we are going to be able to, to locate object B.
Well, now I’m going to play a very short video just to show how Windows Memory Extractor works. In this video we are obtaining the read only memory regions from the user 32.dll that is loaded in the process, whose ID is 7964.
After running the tool in the directory generated, besides the temporary files, we have a TXT file, at least all the files that were generated alongside their hashes.
Well, back to the slides. IM Artifact Finder is a Python tool, and that has been designed as a frame so that it can support different instant messaging applications, different operating systems and different devices. IM Artifact Finder depends on interfaces, so that…and because of that, it is easy to add support for a new instant messaging application.
To do that, a set of interfaces must be implemented as well as the classes that represent the artifacts in the application in support. This tool requires two arguments, the first one is a directory generated with the Windows Memory Extract tool, and the second one is the name of an instant messaging application to which the closest dump corresponds.
With regards to the reports, actually JSON is the only reporting format that we support, but we have designed IM Artifact Finder to make it easy to add support for new reporting formats, like for example, CSV.
In order to extend IM Artifact Finder to support the Telegram Desktop application for Windows, we have analyzed its source code, since the Telegram Desktop source code is available.
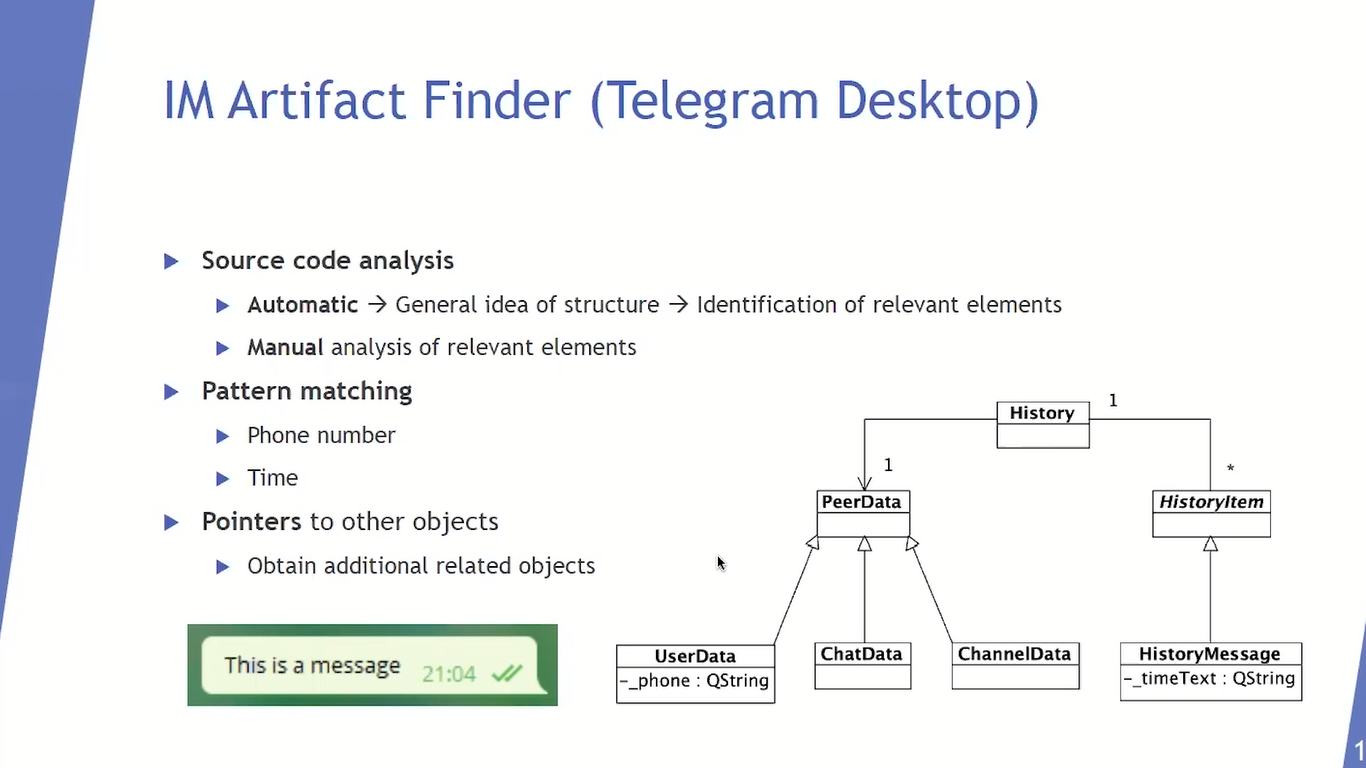
We first performed an automatic source code analysis, and we obtained the entire Telegram Desktop class diagram, which gave us a general idea of the structure of this application.
After obtaining this diagram, we identified inside it the relevant elements from a forensics perspective, and later we manually analyzed those elements.
On the right side of the slide we can see an extract, a very tiny extract, of the Telegram Desktop class diagram, which is relevant. The peer data class represents a conversation, the user data class represents both a Telegram user and an individual or one to one conversation, the chat data class models a group, and the channel data class models a chat.
The history message class represents a message and the history class relates each message with its corresponding conversation. In order to find objects inside a memory dump, or a process dump, we look for patterns using regular expressions.
The user data class has their phone attribute, so in order to find user data objects inside a process dump we look for phone number patterns.
On the Telegram Desktop graphical user interface, it shows the time each message was sent as shown at the bottom left of this slide. This information is stored in the time text attribute of the history message class. So, in order to find history message objects inside a memory dump, we look for time patterns.
Once we find user data objects and history message objects inside a process dump, we look inside them for pointers to other objects. And as we can navigate through RAM we can obtain additional related objects.
And since we have analyzed Telegram Desktop source code, we know which pointers we have to follow in order to find relevant information, like descendant of each message and the conversation to which message belongs.
We performed several experiments in order to evaluate our analysis environment. And we have been able to retrieve the owners of the accounts used in Telegram Desktop where up to three accounts can be used simultaneously. For each account owner, we can get their ID, their full name, their phone number and their username, if they have a username.
In this slide and in the next one, we show several extracts of the JSON reports generated by the IM Artifact Finder tool. From top to bottom, the first image in this slide shows the data that we can retrieve for a particular user. We can retrieve users who share their phone number with the account and some users who don’t share it.
And for these users that don’t share their phone number, we cannot get their phone number from memory. For each user, we can (in addition to their ID, their full name, their phone number, if they share it and their user name, if they have one), we can distinguish if they’re a contact, if they’re blocked or if they are a bot. And we have also been able to retrieve deleted contacts.
With regards to the conversations, we are able to reconstruct the conversations that the user accessed. However, we haven’t been able to retrieve the edited or the deleted messages, but we can retrieve the rest of them. The second image shown in this slide represents an individual conversation with a user, Pedro Fernandez, and in this case, no messages are displayed. In addition, for each user and each conversation that we have retrieved, we can know the account to which they belong.
On the right side of this slide we can see a message retrieved. For each of them, we can get their text, the date when they were sent, and the sender. In this case, the attachments field appears as empty because this is not a multimedia message. In the case of multimedia messages, for the transmitted files, we can get their name and their type.
For the shared contacts, we can retrieve their name and their phone number. And on the bottom left, we can see a geographic location retrieved: for this kind messages, we can get their latitude and their longitude. And if additional information was attached to the location (like the name of the place or its address) we can also get that information.
In all our experiments, we have observed that when the application is locked, we can get the same information as we can get when the application is not locked. Additionally, we have been able to retrieve data after logging out and after deleting conversations. Although these two particular processes are not completely relied.
One important thing to mention here is that if a forensic analyst has access to assist Windows computer, that has the Telegram Desktop application running, and the application is locked, or the user has deliberately delete some contacts or some conversations, or has logged out, then the forensic analyst will be able to use this analysis environment in order to retrieve digital artifacts that cannot be accessed through the graphical user interface.
As conclusions of our work, we would like to highlight the importance of memory forensics when the data that is on this…the communications are both encrypted. With this technique, we have been able to retrieve digital artifacts related to the Telegram Desktop application, which can be relevant for a forensic investigation.
As future work, we would like to support other Telegram Desktop questions and analyze the Telegram Desktop application in other operating systems, and keep extending the framework to support more instant messaging applications.
Thank you very much for your attention. If you have any questions, I would be glad to answer them. And if you want to know more details about this research, you can check out the associated paper that goes with this presentation. Thank you very much.
Session Chair: Thank you very much. Thank you very much for this great talk. Are there any questions? Yes, I can see some, I will just start.
Audience Member 1: Hello. One question I do have is: do you know what artifacts would be potentially exposed with the CLI, the command line version of Telegram?
Pedro: To be honest, I don’t…this is the first time I hear about CLI version of Telegram. We have only worked with a graphical user interface. And to be honest, I wouldn’t know what to say to that question. I don’t know if the graphical user interface is just a presentation, like to…something else in the background that the CLI interacts with.
In this case we would have to research about that, but the structure would be the same on principle, but I wouldn’t know for sure what to say about that. I would have to check that.
Session Chair: Okay, thank you. Next question. Yes.
Audience Member 2: You said that you can retrieve messages and conversations, and I wanted to ask if you have a limit of the amount of messages you can retrieve. Is it possible to retrieve the whole conversation of, I don’t know, 1000 messages, or is there limit to it?
Pedro: Yeah. We can retrieve the messages that are loaded by the users. We can also retrieve the messages in conversations that the user accessed, either to read them or to send some messages in those conversations.
If the user didn’t access the conversation, then those messages are not loaded in the RAM. And for the amount of messages that we can retrieve for a particular application, if the user has scrolled to see messages like from a month ago, or from two months ago, we can retrieve those messages.
But if the user didn’t scroll to see those messages, then those messages are not loaded into RAM, and we cannot get them from memory.
Audience Member 2: Thank you.
Audience Member 3: Hi. I have a question. You said that you can’t see deleted and edited messages. So, does this apply to the whole message that is edited, like the original one and the update, or only the updated version?
Pedro: No. If there is a message that a user edited, then that message…we cannot get neither the original one nor the edited version.
Audience Member 3: So an edited message is like a deleted message in this sense?
Pedro: Yeah.
Audience Member 3: Okay. Thank you.
Pedro: Yeah, we cannot see it. We cannot see it. Yeah.
Audience Member 4: Okay. Great. Yeah. First of all, thank you very much. I also have a question. Hello. My question would be: you mentioned the artifact finding, which actually is one of the most important parts in memory forensics, and you said that you were looking for some patterns. What is your experience when looking at messenger memory? Did you see any kind of obfuscation regarding these kinds of artifacts we want to have? And if so, how do you deal with them?
Pedro: In our case, we haven’t seen any obfuscation. The messages, for example, the text is stored as pure string, they are stored in UDF 16, each character is a UDF 16…is in that format, and there is no obfuscation. If you search for that pattern, you are going to find something in memory.
You have to understand how each character is stored in memory, and for that, we analyzed the source code, and we saw that the format was UDF 16 in this particular case. And you put that in a regular expression and you can find the text. But we haven’t seen any obfuscation with regards to mobile phones or names of Telegram users or text messages. If you know how to look for them, then they are there. You are gonna be able to find them.
Audience Member 5: Thank you for the presentation. I wondered if you also looked at information that would give access to the original underlying database, for example, the pin code or password a user used, and perhaps the key to the database, if there’s one?
Pedro: We have looked…we checked that the database was encrypted, but we haven’t looked into the database, we just checked that we couldn’t create the database because it was encrypted. And that was it.
You know, the database can only be read by (as we understand) by the Telegram Desktop application, and that data is decrypted and loaded into memory, and that is where we can retrieve that data in a encrypted way. But we haven’t looked at what is inside the database or how to decrypt it or anything similar. We just focused on the data that is on the RAM.
Session Chair: Okay. Thank you very much. There is another question in the chat.
Session Chair: Yes. “Have you explored doing this with the virtualized disc image? It is more likely that law enforcement will not directly access the machine, but they may have a disc image which could be virtualized.”
Pedro: In this work we depend on acquiring memory. If you don’t have a memory dump, then this is useless because we are not focused on secondary memory. Our tool, Windows Memory Extractor works with live systems, with Windows live systems.
So, it would have to be used in Assist Computer that is on…you would have to execute that tool in order to acquire the memory that you want to acquire. But yeah, from…we haven’t, like, worked with images taken from Assist Computer, just with live computers that…Assist Computers that are on.
Session Chair: Okay. Thank you very much. I think there is time for one last question if there is another one…? No, perfect. Then we will continue to the second paper. Yes. Another applause.
Pedro: Thank you.





