
Hello everyone. My name is Steven O’Shaughnessy, and I’m a lecturer from the Technological University in Dublin. And on behalf of my colleague, Frank Breitinger from the University of Lausanne and myself, I am presenting our paper entitled malware family classification via efficient Huffman features.
So to give you an idea of what this paper is about, efficient Huffman features (or eHF) is essentially an algorithm based on compression. The idea was to produce a machine learning ready feature set without the need for any kind of manually intensive preprocessing feature extraction, or feature generation steps.
So to give you some background issues that I suppose motivated this study: malware is constantly on the rise. It’s hardly breaking news, but what is interesting is that the new malware that we’re seeing is generally kind of staying stable, whereas the variants of these original strains are constantly rising at an almost exponential rate.
The classification of these variants is important in order to group them into their correct taxonomic class based on similar traits and behaviors. The problem with that is malware is essentially a binary file. So these traits and behaviors that we can extract are not readily available.
So we normally need to use some sort of preprocessing stage or preanalysis stage to extract features. Generally these feature extraction approaches are quite labor intensive, they can be invasive (so for example, using reverse engineering or disassembly), and some may not scale well to large datasets.
Initially then, they require knowledge of the malware’s internal binary structure, because we need to know the internal binary structure in order to know where that interesting information is.

On top of that then, feature selection, which is the…once we’ve gathered or extracted the features, we also need to be able to select the correct features for classification because if we select incorrect features, then the classifier will learn incorrect traits that will throw off its predictive capabilities.
The problem is by and large malware analysts are not data scientists, and so the choosing or the selection of the correct feature sets can be quite challenging. So the motivation for this was to produce almost an automated solution whereby we didn’t have to have any feature extraction or feature selection processes before we actually got the data into a state that we could use it for machine learning classification.
So I first looked into compression. So if you think in the likes of 7-zip or WinZip or BZip, you’d be correct. So in terms of what a compression algorithm does, well essentially it encodes data with reduced representation of fewer bits, usually for reduced storage or for reduced bandwidth, if it’s to be transmitted on firmware.
For our purposes, we can think of compression as representing our data or our files with less data, so essentially a subset of the original data. The advantage of compression, as well is that it can be applied to data in any format. So this has the potential to be used in a wide variety of domains. So it’s not just limited to malware classification.
In terms of what’s been done before for compression, mainly the works are concentrating on distance metrics. So the main one being normalized compression distance or NCD. This has been shown to be used in a wide variety of domains, like text classification, genomics, virology, even music classification.
So it was found to be an effective metric. The LZJD and SHWel algorithms were based on the Lempel-Ziv compression algorithm and also were shown to be effective, particularly in the malware classification space.

In terms of compression as a feature space, there has been work done to show that the dictionaries produced by some of the algorithms, such as the Lempel-Ziv variants, can be engineered as feature vectors, and that was the case with the likes of LZJD and SHWel.
The authors did use min-hashing and feature hashing in order to convert or engineer those substrings into features that could be used for classification. We’ve seen the LZ algorithm being used for text classification problems as well.
Some of the limitations with these approaches though in particular, NCD is computationally inefficient. So to calculate the similarity between two inputs sequences, we need to calculate three compression processes. So we need to compress not only the input strings or input sequences A and B, but also the concatenation of A and B as well.
So essentially you’ve three compression operations per similarity metric measurement. And so this becomes infeasible for large datasets.
The LZ variants have been shown to produce very large feature spaces. So for example, the LZ variant LZ77 produces an exponential feature space. So as our data inputs grow, so the number of our files that we’re processing grows, so too does the feature space to represent those.
And again, the likes of the LZJD and SHWell algorithms, the authors have had to use feature dimension reduction in order to make this kind of feasible as a feature space. I kind of highlight the LZJD and SHWell algorithms because although they are essentially a distance like metric, they do produce a feature set based on the LZ algorithm that is essentially a feature vector, and in some ways then are similar to the eHF algorithm that we produced.
So based on the findings there, I wanted to find an algorithm that was efficient and produced a small feature space. So I settled on Huffman coding essentially just because of the way the algorithm works. So it’s based on the frequencies of occurrences of the input symbols, which are essentially characters within the input sequences.
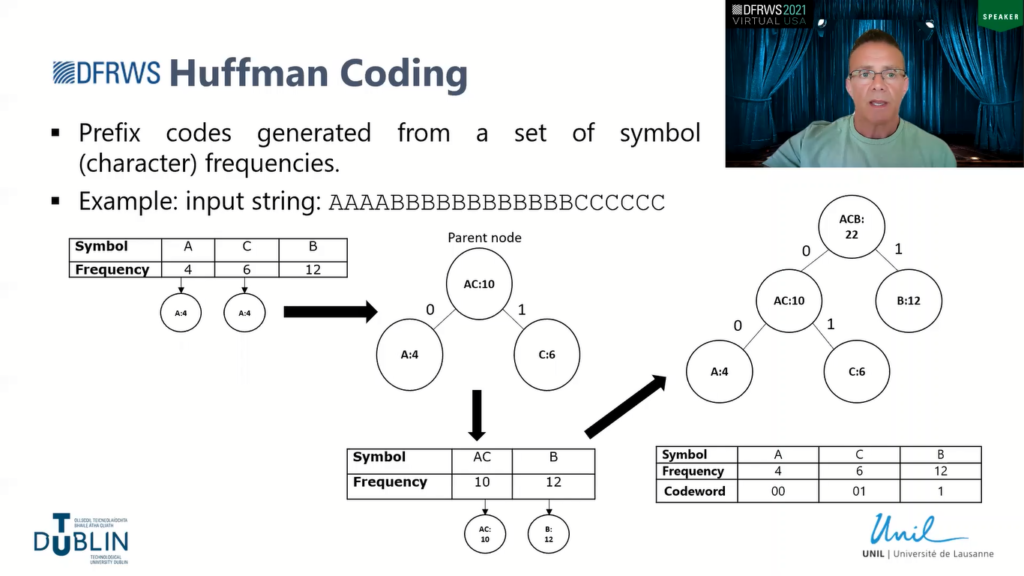
So the input sequence in our case is a malware binary. So if you think of it, we’re representing the extended ASCII set. So the maximum amount of characters or symbols within our alphabet is 256. So that equates to essentially the maximum feature, so our feature dimension and size of our vector is going to be 256, which is markedly smaller than the looks of the LZ algorithms.
So just to give an idea of how Huffman works: essentially what it does is it generates a binary tree based on the frequencies of occurrence of the characters such that the tree produced the lower nodes on the tree, or the end nodes on the tree, will be the input symbols with the lowest frequency, so the lowest frequency of occurrence, whereas at the top of the tree, the symbols with the highest frequencies will tend to be.
So to give an example of how it actually works: we have a simple string there of 22 symbols, 22 characters, A, B, and C. So we first of all start off by calculating the frequencies of each, so we’ve got 4 As, 6 Cs and 12 Bs. The iteration of the algorithm works by removing the first two lowest frequencies from the set and adding it to a sub-tree (or creating sub-tree), the parent node being the summation of the weights of (or the frequencies of) the two child nodes.
So for instance, in our example A is 4 and C is 6, so the parent node is going to be 10 and that’s added back then into the set and then that process is repeated until we get the full binary tree, and we essentially only have one node left in our set.
The actual Huffman codeword (which is essentially the representation for the symbol, or the character) is obtained by following the edges from the route down to where the node is on the tree. And I should have said that as the tree is constructed, the convention is that we add a 0 to the left-hand child and a 1 to the right-hand child, and these are used then as the binary codeword as we construct it.
So if you look at our example: A, the Huffman codeword is obtained by following the route node down to A, so that’s 00, C is 01 and B is 1. So instead of representing, for example, each symbol in terms of eight bits (which would be 22×8, which would be 176 bits) we can now represent A with 2 bits, C with 2 bits and B with 1 bit, which works out forward to 6×2 + 12×1 which is 32 bits. So that’s essentially how the Huffman coding algorithm works.
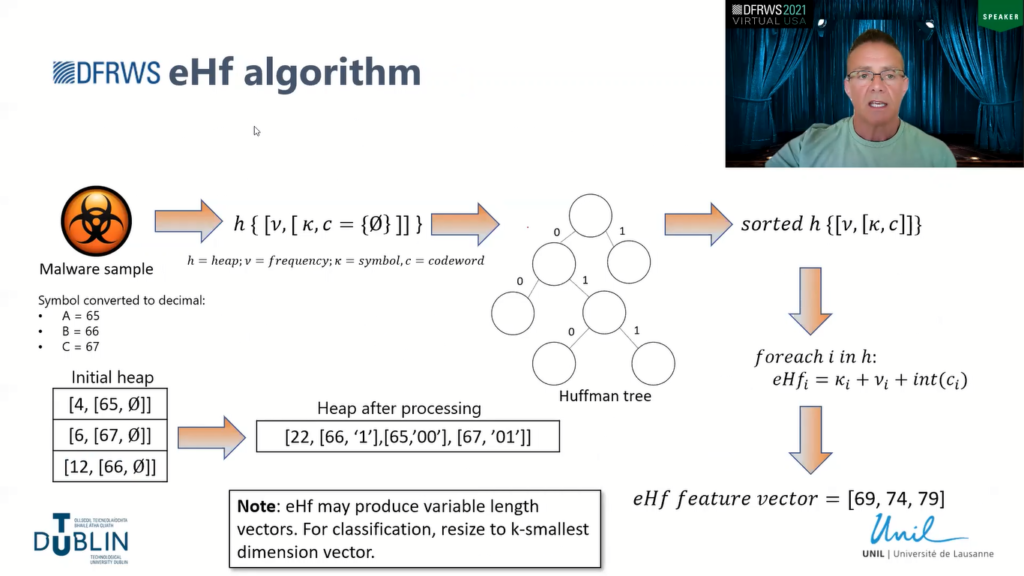
The eHF algorithm is a kind of…I suppose an extension of that. So it calculates the codewords in the same way as before, but what it does at the end then is it combines the symbol (which is converted to its decimal equivalent), the integer value of the binary codeword and then also the frequency itself.
Initially, I just used the Huffman codeword as the feature for classification, but I’ve found that the models that were produced didn’t generalise well, so they weren’t robust against unseen samples.
And so I kinda went back to the drawing board and I said, if you look at what we’re producing here, the symbol itself can be represented as a number (which is important obviously because we’re dealing with, individual unique symbols), its frequency, (so if a malware sample is almost the same…two variants are almost the same, then they will share the same symbols, they will share more or less the same frequency of symbols as well, and the codewords will be quite similar as well).
So I combined those three values into a composite feature and used that then to represent each symbol. So essentially the output from the eHF algorithm is a vector. So the dimensions of the vector depends on the input of the characters or the symbols within the data. So, like I said, the maximum size or the maximum dimension is 256.
I suppose, just to note that, because we’re dealing with variants of binary files, there may be some alphabetic symbols missing or not present in certain files. And so the eHF algorithm may produce variable length vectors.
So for classification, we need to have a uniform sized vector (so the dimensions need to be the same for classification). And so to kind of get around this, I resized all of the vectors to the k-smallest dimension vector.
So for example the smallest dimension vector in the dataset that I used for the experiments was 229. So I reduced all of the other vectors in the set to 229 dimensions. So the way that the Huffman algorithm works, it sort of based on codewords, so the least frequent codewords, or the least frequent symbols, will be towards the end of the set.
So any features that I’ve trimmed off will tend to be the lesser frequent symbols within the input sequence. So will have less of an impact on the actual overall classification of the malware.

So the data that we used was primarily the Win32 portable executable files, so P files, which are essentially the most common type of format that we can find malware in. These were extracted from several repositories on the VirusTotal academic share from around 2018, up to 2021.
I used an open source tool called AV Class Labeller, which enabled me to cluster the malware together based on family class. And it uses the output from the VirusTotal AV scanners to label the malwares according to their family. Initially I used a training set of around 8,000 samples from 12 families.
The reason why I’ve extended that then for further testing is because we just decided that we needed to test how well the models generalized under different and more families, so I extended up to around 14,500 from 23 families for the latter stages of the testing.
In terms of the classification, once we had the data into the feature sets, the data and the labels were split in a 90:10. So 90 being the training and testing, and 10% then was held back then for evaluation, for evaluating the models on unseen data.
I primarily chose k-nearest neighbor as the algorithm, because it’s a distance based metric and some of the experiments that I was conducting were based on NCD, so I wanted to be able to interchange the distance metrics easy enough, which I could do with k-nearest neighbor in order to evaluate against the NCD algorithm.
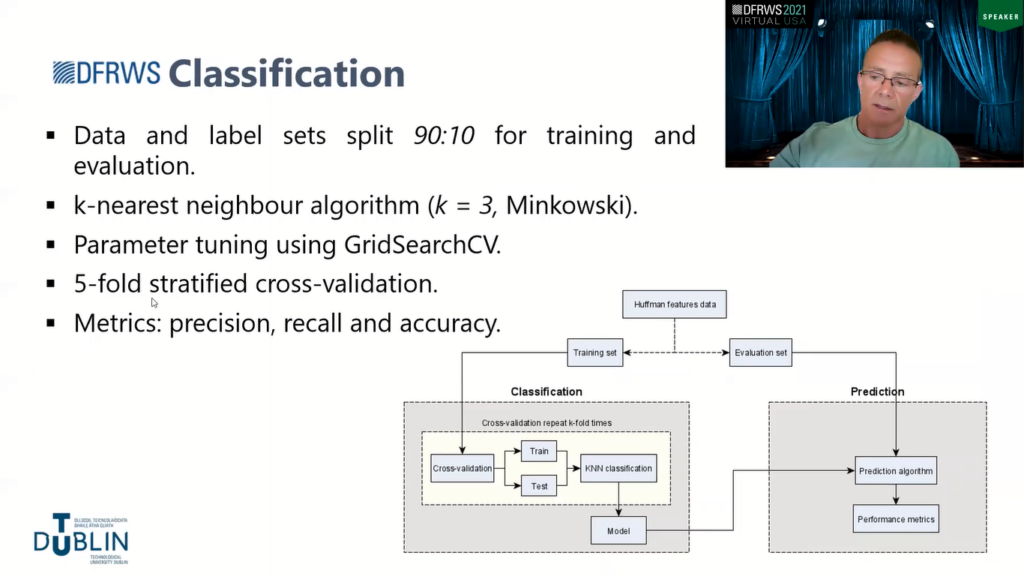
So I used parameter tuning to find the best or optimal parameters for the KNN classifier, and I also used 5-fold cross-validation in order to reduce overfeeding and classification errors. The metrics used are precision, recall and accuracy, just because accuracy alone, I don’t think (which was found in most cases in previous works) doesn’t give a good overall picture, so precision and recall will obviously give a better indicator of how the models performed.
So the results on the initial training set were good. 11 out of 12 families were predicted with a TPR rate of 97% or above. One family in particular performed markedly poorer, which was the Scar family. I did some further digging on that and did the two classes that it was misclassified as being Autoit and Vilsel.
When I checked out, I ran them through VirusTotal API, and it was found that in many cases there was mislabeling, or Scar would be mislabeled as Autoit for instance, in some cases. So that could be the reason for that mislabeling.
Once the models were created, the 10% devaluation set turned pretty good results as well in around 97% for the three classification metrics that were used. I wanted to run a comparison with NCD, even though NCD is primarily a distance metric, I wanted to show that eHF could be used in conjunction with a standard distance metric in order to produce an efficient way of similarity comparisons.
And so the table there shows the runtime for the comparisons for each data point or each feature, essentially, in the feature set. So you can see that the Minkowski eHF algorithm ran at roughly around one millisecond per comparison, as opposed to 1.2 seconds of NCD, which is pretty much three orders of magnitude slower.
Likewise, the Minkowski eHF algorithm outperformed NCD by roughly around 20% as well. So that just proved that eHF, along with some standards distance metric, is a viable method for similarity measurements for malware.

I compared and evaluated eHF against LZJD simply because again…I suppose the LD sets that were produced from both algorithms were essentially feature sets that could be used for classification, and I wanted to show a similar kind of method and again, evaluate how well eHF will compare to those.
So in terms of feature generation times eHF had an average of around 50 milliseconds, as opposed to 120 LZJD, and LZDJ-SHWel algorithm was around 500 milliseconds, which is obviously 10 times slower than eHF. In terms of training time, again, the eHF was roughly around three times faster than the LZJD-SHWel algorithm, and roughly probably around seven times faster than the LZJD.
A lot of that is obviously down to the feature dimension size as well, because the feature dimension size for both LZJD variants is 1024, as opposed to eHF, which had a feature dimension size of 229.
The second parse then with LZJD was for classification performance. So this was on the larger VirusTotal dataset of the 15,500 samples. So the SHWel algorithm performed slightly better than eHF with around 0.1-0.4% over the three metrics: precision, recall and accuracy.
But in terms of the validation on the 10% dataset eHF outperformed both LZJD variants quite considerably. Now, just to put in a note there that I didn’t do any kind of parameter tuning or dimension reduction or anything like that in terms of the LZJD.
So if we did spend a bit more time on that, the results might have been different, in terms of performance for the LZJD. But again, this was used to evaluate the eHF as a viable method, I suppose, of classification for malware.

The last set of tests I did was on code reordering. So I used the import tables extracted from the VirusTotal dataset. They were trained on the classifier as before, and then I used a tool to basically reordered the code and as such, reorder the import tables. The import tables were extracted from the sub-sample then, and then were run against the KNN model, which produced an accuracy of roughly around a 100%, very, very high recall, precision and accuracy.
The reason why I conducted this experiment and this set of tests was just to show that the way eHF works, and the way Huffman works, is because it works on the frequency of occurrence of symbols, the order in which the data is input doesn’t matter.
So if two files are the same, if they’re reordered in any way, then the sets produced from the eHF algorithm should be the same, because the alphabetic symbols will be the same, the frequencies will be the same and so on. And so, this test was essentially to show that.
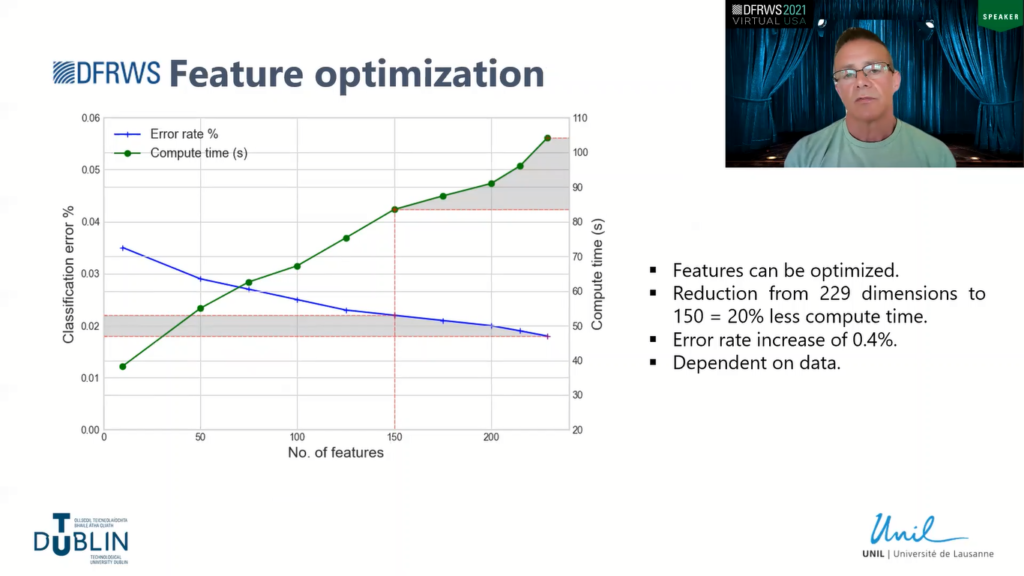
In terms of feature optimization, I played around with the number of features, just to see its effect on classification error. So the example I have here, I reduced the dimensions of the VT set down from 229 to 150, which is approximately from 105 to around 85, which is approximately 20% of less compute time, which you can see on the right-hand side.
And then if you look at the corresponding error rate, it increased only by 0.4. So the significance of this is if we want to run this at scale, and we have a large scale dataset, then we may want to optimize the algorithm by lowering the features. And if we can afford a slight trade-off of an increase of classification error, then we can greatly optimize the algorithm at scale.
Again, this is dependent on the data, so I don’t have any information on other datasets, but for this particular dataset, roughly dropping the features down to 150 only had an increase of 0.4.
So just to give a summary of the contributions of this paper, we’ve produced an algorithm called eHF, which is based on compression, which negates the need for any kind of invasive preprocessing and gives a set of features that are ready for machine learning. It’s quite fast, it’s built on Python, it can be improved. But at the moment it’s built on a heap structure, which is quite fast. And so is scaled into large data sets. It’s free and open source.
In the paper, I do provide a link to the repository. It has the potential to apply to other domains because it’s based on compression, we can compress pretty much any file.
So it has the potential there to be used in other domains, not just malware classification. Any outputs then are in such a way, in such a format, essentially that they are ready to be plugged into machine learning algorithms. They’re essentially a feature set that represent the malware binaries and that we could just pass to any machine learning algorithm then.
Some of the limitations: eHF is, I suppose, in its infancy. We only developed it in January. And as such we developed tests, and subsequently wrote the tests around the paper because when I spoke to Frank about this in January, we decided that we wanted to put it into this conference, and obviously we had a short deadline.
And so we designed the experiments to fit into the paper and in this short space time that we had. So there obviously are limitations there that we can address. We limited the malware experiments to executables and import table dumps, but like I said, we could probably implement this in any type of data type or a data format.
I only use the KNN classifier. Again, I used it out of convenience because it’s a distance based classifier, and I could easily interchange the distance metrics to have a comparison or evaluation against the NCD algorithm.

And then obviously, there is lots of other obfuscation methods such as packing and encryption that weren’t tested. Again, this is down to time, and obviously that’s something that we could explore further.
So in terms of future work, to test that scale, at the moment I’ve unsuccessfully tried to download Sorel dataset (it’s 8TB!). I’ve managed to download 2.5TB before…the connection seemed to just crap out, I don’t know why.
So hopefully over the summer, I’ll get to download the whole data set and work on that. We’d like to improve the processing speeds obviously because we’re looking at large scale processing, we need to have something faster. So we could use maybe a different language or use maybe C bindings in Python to do that.
It could be applied to other forensics scenarios. So one that comes to mind would be, say, file fragment identification. And again, because we’re dealing with compression, that is a possibility. And then obviously the further obfuscation test and the test on the likes of packing or encryption and see if eHF can pick up any of those obfuscated samples that are in the dataset.
Okay, so that concludes my talk. I just want to thank the organizers for the digital forensic research workshop for allowing us to present today. And I’ll answer any questions that you may have now. Thank you.





