
Well, good day. My name is Bradley Schatz, I’m from Evimetry. Today I’m here, it’s my distinct pleasure to be here at the Magnet Virtual Summit to talk about the Advanced Forensic Format Container version four. That’s an evidence container also known as AFF4.
So a little bit about me. My background prior to doing a PhD in Forensics was as a software engineer. Since around about 2009, I was primarily a full-time practitioner. And over time there’s more to becoming, these days, primarily a tool vendor which builds largely upon my backgrounds in the research side of things, as well as a software developer. Very actively involved on the scientific side, in the Journal of Digital Investigation and the DFRWS Conference where I’m on the board. And I’ve led a couple of the conferences, most recently the APAC and prior to that, the USA. Other things that I’ve contributed to the field would be, other than the AFF4, would be the Windows 7 Vista Support in Volatility back in 2010.
So today we’re going to be looking at AFF4 or looking at what’s wrong with traditional forensic imaging. Then we’re going to look at how AFF4 solves those problems. How you can take advantage of those in your workflow. And finally, we’re going to be looking at the next generation in imaging, which is AFF4-L, which is focusing on logical imaging.
So what is wrong with traditional forensic image containers? And by forensic image containers, I’m talking here about what we typically refer to as an EWF or E01. They’re compressed containers as well as Raw also as dd.
The first thing that’s wrong is, with EWF/E01s, they’re actually quite expensive in terms of CPU time. So what you end up getting is, if you have a disk that’s fast enough, you can actually end up being limited by the CPU.
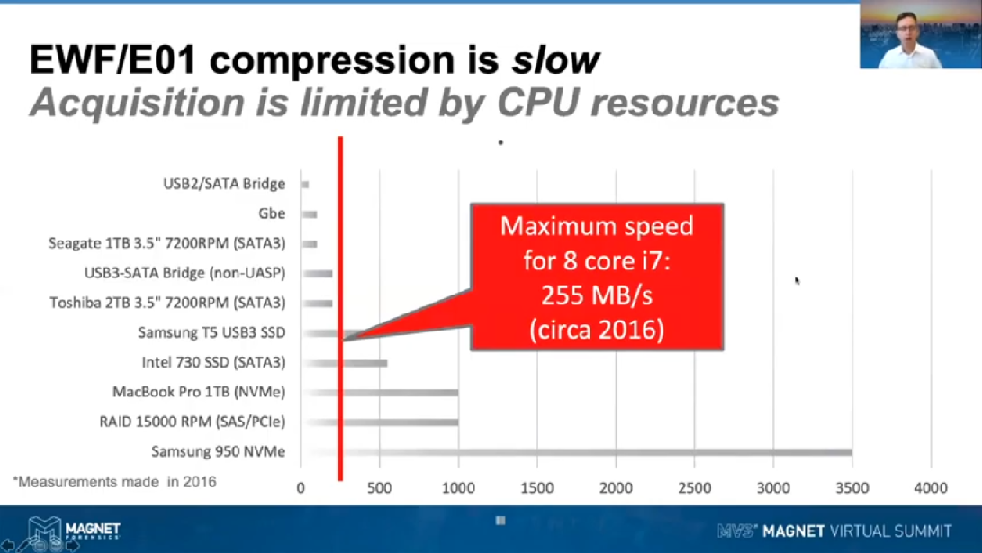
So, for example, when I was doing the research that lead to Evimetry and AFF4, as it’s currently implemented, we were finding that when we were starting to try and image things like SSDs, which were decent enough in terms of IO to go to about 500 MB/s, we couldn’t go any faster than half that at 255 MB/s. More generally in those kinds of timeframes we were only seeing right about 100 MB/s from some other tools that we were looking at.
These days the CPUs have increased in performance a little bit but really we are not seeing speeds going much higher than the 500 MB/s we’ve been seeing running about the place. Now, if you have a look in the background of this slide, you can see some of the speeds of the devices that you may be coming across in the field.
Some interesting points there, is that in many instances you won’t be getting the speeds approaching 500 MB/s from old-style devices. So, you know, maybe old spinning disks, they’re only going to maybe 200 MB/s. The really old spinning side disks, they’re only going to get about 100 MB/s as are some of the newer generation shingled magnetic recording ones. CPU isn’t really that much of a limitation for those, but where it really starts to hit is when you’re dealing with SSDs, RAIDs, and more importantly, NVME drives, which are going with thousands of megaseconds kind of a range.
Now moving on to Raw images, where they’re really slow and inefficient is when you’re dealing with sparse data. So what I’m talking about there is large multi-terabyte spinning disks that have significant amounts of empty space that generally just form all zeros. The key point here is that when you’re making a Raw image of a device, it’s got lots of sparse. You’re spending a lot of time reading zeros, passing those through a hashing algorithm, and then copying those zeros out [inaudible] take time and energy. For a disk that’s a terabyte in size that only goes about 100 MB/s, you can be spending around about two and a half hours just verifying that whereas with a better approach to enable this containment, we could be doing that in seconds or minutes depending upon the amount of sparse that you’ve got.
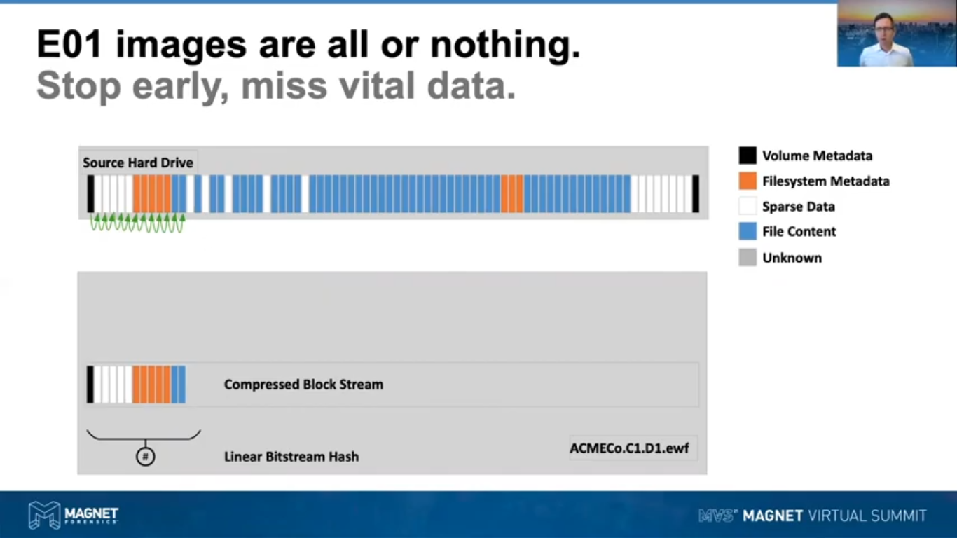
So your E01 images, they’re all or nothing. Our traditional view of forensic images is based on the linear bitstream copy. So the idea here being, and what I’m depicting on screen, in the upper half we can see a source hard drive and I’ve put a bunch of cells there, they’re representing clusters or sectors, or what have you. I’ve colour coded them so over on the left-hand side would be LBA 0 and on the right hand side would be the maximum LBA of the drive. But then the general theory of a traditional forensic image is that we started at LBA 0, we read it, we store it in the EWF file. And we can see that down in the lower part of this diagram here, that we’ve got that little LBA 0 which is colored in black, it’s installed first. That’d be the MBR on a regular old-style drive.
On to the next LBA, we read that, we can compress it and store it and so on and so on [inaudible] the drive. The problem that we’ve got here is that if we need to finish the image early, we’ve only got the data that we’ve read from the beginning of the drive. So for example, in this particular depiction, if you finished at the last sector there, the last blue one where we’ve got those little green arrows and maybe if we’re depicting here, that we’ve got an NTFS drive and the false metadata is stored right at the beginning of that drive, but maybe also somewhat later on in the [inaudible] we might have visited these particular blocks or sectors. So you’re going to have an incomplete file system and your forensic tools are gonna have a hard time, actually interpreting it.
So that’s our current view of the forensic image container. We only get as far through the drive as we can in that linear pass that we go over it. The research that has turned into the AFF4 has given us the ability to look at this in a little bit and in a way that will allow us to acquire the higher value stuff first, I’ll get into that in a little bit.
The other motivation that we had for coming up with a new forensic image container was when we first started doing this, which is back in about 2009, we were starting to deal with evidence sources that weren’t actually linear and complete. So while the hard drives were dealing with time, you started reading at LBA 0 and went to the end of the drive. The only holes that you might get, you know what I mean, discontinuities in the drive that you might find could’ve been due to read errors or the like.
What we were facing at the time, though, was the ideas of acquiring volatile memory, which when you dig into it, there’s many, many holes in the physical memory of a computer. And you can see here on the lower part of the screen, this is a BIOS memory map taken from a Linux machine that’s been booted up. The rows there that are marked as usable is a memory that we could acquire, but regularly the areas that are reserved we may not be able to acquire, and we may need to treat that as a whole.
So using a traditional E01 or a Raw, what do we do? There’s no real provision in those image formats to actually describe where those holes are. So what we’ve traditionally done is just zero through those holes and basically, possibly document those outside of the image format.
But we do have some more interesting discontinuity showing up more recently. A key case and point that’s affecting many forensicators at the moment is for APFS Fusion Volumes. They’re quite interesting in that the approach that Apple has taken for assembling a Fusion Logical Volume — and a Fusion Volume, for those who haven’t come across them, are a special type of volume where you have a fast disk and a slow disk and the MacOS manages to speed up and optimize some of your accesses by storing hot data on the fast disk but the bulk data on the slower disk. The way that Apple have chosen to do this with APFS is that they put one drive at basically, the virtual LBA 0, but the second disk they actually have a very high address range starting at the four exabyte mark. In between, it’s just a wasteland of sparse data, it’s all basically unknown. You could choose to represent that giant hole as being full of zeros but it doesn’t work out very well unless your tool is aware of it.

So for a case in point, we can take quite an efficient physical [inaudible] AFF4, using AFF4 represented on screen here, I’ve got an eight exabyte image being verified using Evimetry. And we’re verifying that at an [inaudible], which is a pretty reasonable linear bitstream rate to be achieving. The problem here though really comes down to just that ability of the MD5 and SHA1 hashing schemes to actually process eight exabytes worth of data. We don’t get the maximum speed, we can on a fast CPU, but there’s just so much data there, having to pass through eight exabytes is actually going to take 429 years. So it’s actually quite impractical to try and not represent that discontinuity. We need to take the discontinuity into account and not try and do hashing over that area where we don’t have any data.
So the key point here being that we can’t take a MacOS Fusion image that’s in an AFF4 format and convert it over to E01, it’s going to take too long. We can’t verify using a regular linear bitstream hash, which is what we’ve been using since the beginning of computer forensics because it’s just going to take too long.
Another issue that we have with E01s and Raws is that they’re not great for storing metadata. Raws specifically, they don’t have any real standing for storing metadata. We’ll regularly see another file being provided alongside or [inaudible] contain a wide degree of metadata that’s generally defined by the manufacturer of the tool, there’s no real standard way of representing the documenting that data though, it’s all very tool specific.
E01 went a little bit further than [inaudible] the ability to package up metadata inside the forensic image. We can see here in the bottom right of the screen, some of the metadata that’s formalized in E01, so you’ve got things like description, case number, the model of the media and that’s been documented largely by Joachim Metz, who has produced the lead EWF tool set. But largely we have a fixed set of its metadata, there is no easy way for [inaudible] metadata that we want and then share that with other tool vendors and extend on that over time.
So a lot of the reasons that I’ve just covered were either anticipated and motivating the AFF4 research. What I’m going to describe now is how AFF4 solves these. So before I do that, though, what I wanted to do is just recap again, on what a traditional forensic image actually is. So you’ll find here that the picture that I was using in the acquisition process earlier on in the seminar. Again at the top I’ve depicted the source hard drive, the suspect drive, and then down below, we’ve got our forensic image.
So a forensic image generally by definition is that we’ve got a one for one copy of all of the blocks of the source drive. And then importantly, we’ve got a linear bitstream hash that we’re using to verify the integrity of the data that we’ve copied.
So down below, we can see here our representation of an EWF [inaudible], which is the gray area. We’ve got the linear bitstream hash being stored within the image. And then we’ve also got the blocks that we’ve copied across. Now, the key advance that we had with an E01 is that it introduced the usage of compressed blocks. So it’s able to be efficient with the way it stores data. It doesn’t take as much space, especially when you’re dealing with blocks of zeros. But again, as I said before, the compression scheme that it uses actually is a little bit CPU expensive.
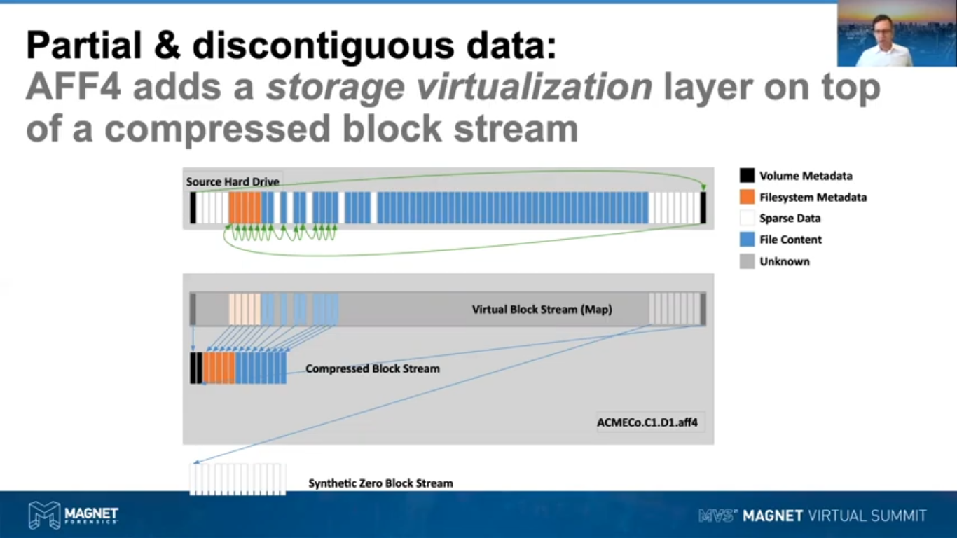
We don’t actually compress those and store them in the compress blockstream; what we do is we kind of synthesize those at runtime as blocks of all zeros. It’s kind of similar if you were coming from the Unix world to the /dev/zero device. But we can actually represent large areas of sparse blocks in the image in only a few bytes and having that representation of sparse areas and then similarly, we can represent areas that we don’t know about. So for example, if we’re dealing with the APFS fusion image that we were talking about before that has the four exabytes worth of empty space, we can represent that as unknown space. Similarly, we can represent [inaudible] areas. We can represent those using a specialist synthetic block stream.
Now, what AFF4 does is it takes the general model that we’ve got of an E01, i.e. the compressed block stream, but then it adds on top a virtualization layer, which we call the virtual block stream. Now, what that virtualization allows us to do is firstly, it allows us to represent discontinuities in the hard drive. So if you have a look at the virtual block stream below, which is mirroring the source hard drive up above, you can see some of the white blocks there that we’re using to represent sparse data or zeros.
Having this virtualization layer in place allows us to take our concept of a forensic image from being a linear block stream to being a nonlinear block stream. So what do I mean by that? Now, if you look in the path that we’re traversing by these green arrows up above here, what it allows us to do is to read the blocks of the source hard drive out of order. So for example, if we were to [inaudible] LBA 0 blocks, that’s the black one on the left, we could read that, compress it, store it down in the compressed blockstream, where you can see it there, and then store a reference to that in the virtual block stream map, so that we know where it actually belongs in the source hard drive.
But we could then choose to go to the very end of the hard drive and read the end of the hard drive, where there might be some other partition information being stored, for example a UEFI partition scheme could store some data there. So again, we can read that block, compress it, store it down in the compressed block stream. So you can see now that the blocks have been split out of order, and then we would store the Map, ensuring the virtual block stream, which shows us where that particular block belongs in the Virtual Address Space.
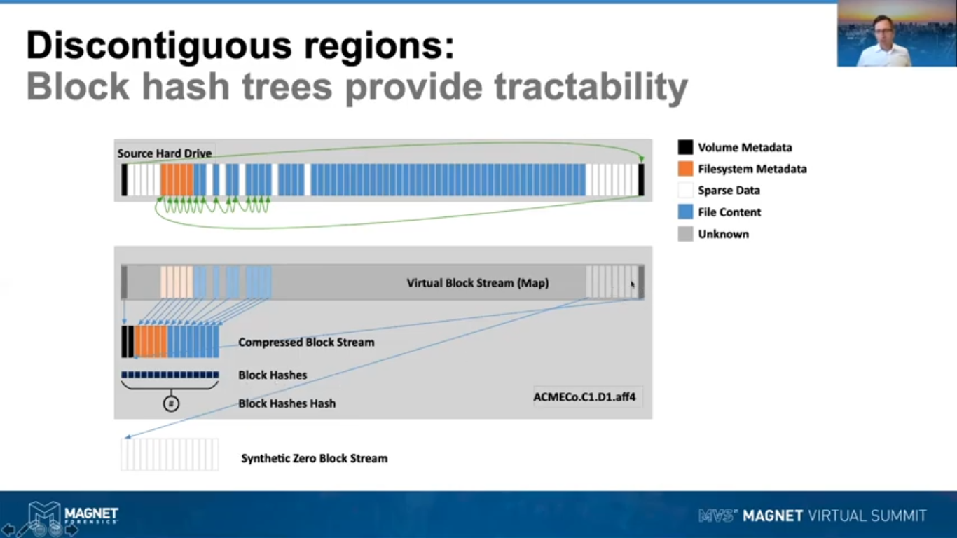
Once you start doing this kind of thing, then you know where the volumes are laid out on the drive. So you might then start actually acquiring the file system metadata of the drive. So you might fly back over the hard drive and go to the beginning of the partition, slurp up all the NFT entries, compress those, push them down into the compress block stream, store the map reference. And it’s by doing this, that we get to a point using AFF4 where we can do two things. We can store non-linear images, that’s images that we’ve built up by traversing the initial source drive out of order. But also we can represent those discontinuities or areas that we’ve chosen not to acquire as a partial image. So just by the addition of this virtual block stream, we now have the idea of the forensic image being both non-linear and partial.
As I introduced before though, having discontinuities does mean that hashing in the fusion drive sense takes too long or just in the regular sense, it gets very difficult to create a single linear bitstream hash when you are missing a lot of the data. So what we’ve done in the AFF4 standard is to dust off an old hashing scheme which is used in some of the old dd tools more specifically, which is [inaudible].
So rather than trying to generate a [inaudible], which we can’t do if we’re reading the drive in a nonlinear fashion, what we do is we use block hashing. So for every block that we read that we’ve got data, when we compress it, we also hash it. So we store our compressed block in the compressed block stream, and then we store a block hash of the block that we were using there. And over time we build up block hashes as well as the compressed block stream. This, and then at the end of the image, we take a hash out of all of those block hashes, which is used to preserve the integrity of those.
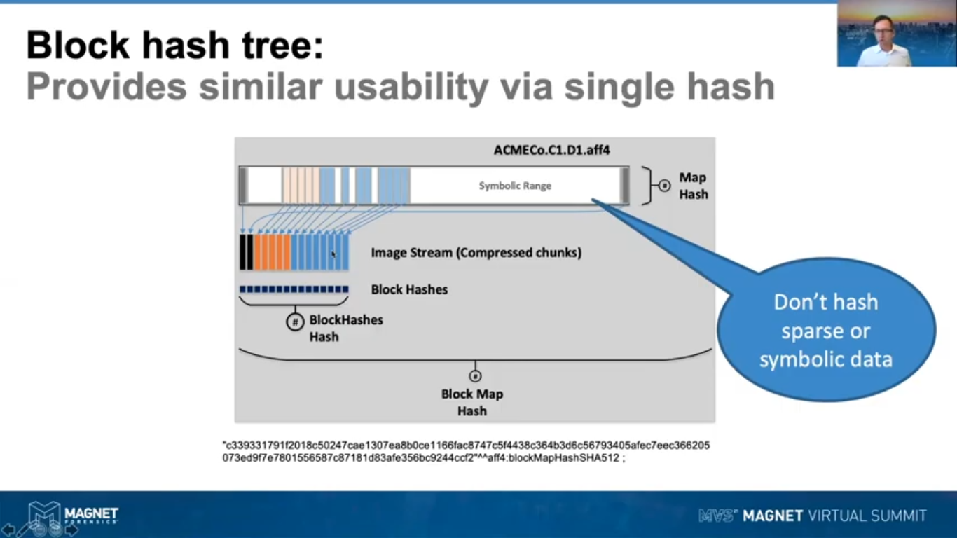
Now, what we’re missing in that, is we still don’t have a hash that’s protecting the information that we’ve got in the Map. So what we do there is we, rather than trying to hash those sparse readings, which can take too long, or it will be very complex and not reproducible, we just don’t hash symbolic regions, we only hash regions that are actually containing data and are stored in the compressed chunk strip. What we do is we take a Map, we take a hash of the Map, and then now that we’ve got the Map being protected by a hash and the block hash is being protected, we’ve got the integrity of [inaudible] the image being protected.
Finally, so we can actually still have the usability of our traditional hashing, we then take both of those hashes and we take the hash of those, and we call that a Block Map Hash. Now this type of hashing scheme is similar to a scheme called a Merkle tree, which is like a computer science approach to hashing, also referred to as hash trees. They have a very long history in computer science and are very widely used in systems like the blockchain, BitTorrent, et cetera. At the bottom of the screen here, you can see a Block Map Hash as it’s being stored in AFF4s metadata, you can see here basically that we’re using SHA512 for this level of our hashes. We don’t use SHA512 or 256 for the block hashes, what we do is generate multiples of those, using faster hash algorithms, like MD1 and SHA1.
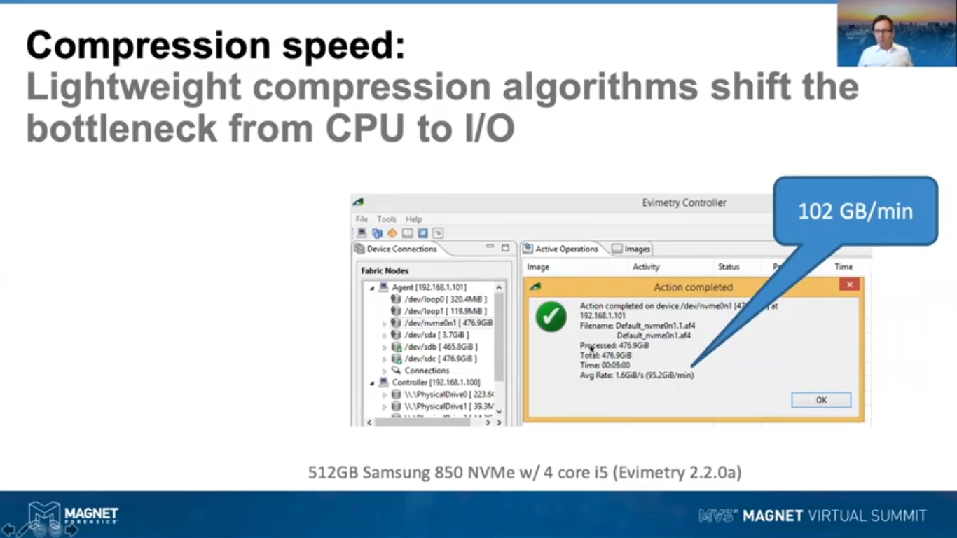
Moving on to the issue of speed. We, in our testing, found that the Deflate algorithm used by E01s is very CPU expensive as I mentioned before. It turns out there’s a number of options out there for varying CPU efficient compression schemes that are almost as good as Deflate, certainly good enough for what we’re using. So what we’ve done in the AFF4 is to enable people to use those improved compression schemes. There’s one which we implemented originally in AFF4 back in 2016, with the Evimetry version which is called Snappy, that’s used extensively and supported by Google. Then there’s another one called LZ4, which is coming more from the ZFS storage. And we support both of those, [inaudible] supports both of those and they both perform reasonably similarly. The key point here being that with enough CPU you can get to speeds in the hundreds of GB/m. Really it shifts that equation from being CPU limited to being I/O limited.
Finally, what we did to improve on the situation using AFF4 was we created a metadata storage, which enables the metadata to be arbitrary, that’s being stored in the image. To do this we adopted a Links Data Approach using the RDF language. You can see here on screen some of the metadata that’s used to describe a forensic image coming from in an AFF4 image. The key point here being, this is particularly an object within the AFF4 system, objects have their own identity, which are unique, which is this particular UID up here. They have Type, so this is all Type image stream, and then we have a number of properties that have values associated with them. So, for example in this particular compressed block string, we have chunks, which are about 32K in size. The compression method that we’re using is Snappy. And then we’ve got a linear bitstream [inaudible] with that, and this is the SHA1 linear bitstream hash encoded here.
So this encoding here is using an RDF Arbitrary Turtle. It is somewhat human readable, certainly computer readable and it’s supported by a whole raft of web standards, languages, libraries, which can be reused by implementers to work with, and is very compatible with our more recent efforts and even sharing, like CASE and the like.
So, it’s one thing to propose a new image format, but we’re in forensics, we want forensics to be a forensic science and to be accepted by the courts ultimately. So the AFF4 has a strong history of undergoing scientific peer review. On screen here you can see here some of the snapshots of the papers which the original one on the left there was written by Michael Cohen, Simson Garfinkel and I back in 2009. We’ve published — to some extent us, and to some extent me alone — a number of papers, all for over the last decade which had been peer reviewed and published openly so that implementers and forensic scientists can look at the scheme, critique it and refute it if they so think. To date we have no refutations or any adverse findings against the approach.

Finally, I’ll talk about how easy it is to adopt, how we’ve gone about developing the AFF4 as a standard. It is an open standard and we’ve gone to great efforts to create multiple open-source implementations. So back in 2016, 2017, we took the extended AFF4 research and came up with a canonical set of reference images, which are really the ground truth for implementers to adhere to in ensuring that their implementations are compliant with what we call the AFF4 Standard Specifications v.1.0. We provided an explanatory specification document, which explains to implementers how those ground truth forensic images work. We released a copy of Evimetry called the Evimetry Community Edition under a very liberal license, so that other tool implementers could actually generate and test and validate forensic image interoperability. And finally we’ve got a Python based reference implementation, which is able to both read and write AFF4 physical images, as well as logical images and I’ll get to [that], as well as your hash verification. And then we’ve got a C++, C and Java implementation which are read only implementations other than the C one, which is read/write, the main limitations there being that none of those implementations involve implementing hashing, which is something that needs to be implemented on top.

So over the last maybe five years I’ve spent a significant amount of time promoting the AFF4 format at a number of conferences and working with tool vendors to get AFF4 support [inaudible]. We launched Evimetry in 2016. At the time, it and the Rekall C implementation were the only implementers of AFF4. The next year, Evimetry, we contributed Patches, to Volatility and Rekall as well, the memory part of it, to be able to read AFF4. And since then, we’ve worked with this big list of forensic tool vendors to get AFF4 support into their tools. Initially, this was read only support, but in 2019, we saw Macquisition come along as the first tool to adopt producing AFF4 images. And more recently we’ve seen a number of other tool vendors come along, including Magnet, implementing AFF4 write support as well as read support. These days, really it’s a matter of who doesn’t support it rather than who does.

So where do all of these improvements actually [inaudible] the image format actually help you in your workflow? Now obviously if you’ve got a fast suspect device and enough CPU and high-end storage you can actually go as fast as the source we provide. If you’re dealing with an NVME laptop, generally where the bottleneck is going to be, is going to be in where you’re storing the image too. So the approach that we came up with, with scaling that bottleneck was actually to be able to store a forensic image to multiple destinations [inaudible] and get the aggregate I/O throughput of those.
Another approach which we’re seeing, is now the ten gigabit Ethernet is starting to become a thing, is that we can start getting, we can start using that and do it to get higher in storage. So maybe you can plug in ten gig Ethernet into a RAID array and you can get some really fast acquisitions going on there.
For slow sources, like spinning disks, Evimetry really is generally not going to speed up the acquisition, but where it will speed things up is at the verification time as long as you’re acquiring to a disk that’s high-performing. So, for example, if you’re acquiring from a spinning disk that only goes at 100 MB/s, but you’re acquiring to an SSD with pump starter at 400 MB/s, your verification is likely to go at least four times faster than you required it, likely much more, depending upon the amount of sparse that you’ve got.
So moving from acquisition to verification, I’ll just reiterate that point. Regardless how much shorter amount of time you can do the acquisition in, the verification does add up a lot of time in the field, on the copying round, images in the lab, et cetera. So it makes sense to, in your infrastructure, to have fast storage and CPU and faster networking so that you can at least take advantage of very fast verification. We’re seeing verifications regularly going to 100 GB/min, that’s at the low end, but again, that’s running off a RAID with a reasonable number of CPU calls.
Finally, where AFF4 can work quite effectively is for remote acquisitions. Up until this point, doing remote physical acquisitions has been quite a forward exercise. [inaudible] image you drop, if you get a dropout due to the latency or a network dropout, you get a situation where maybe we haven’t gotten the file system metadata. You haven’t been able to acquire the high value files first. By doing a non-linear partial acquisition you can, using AFF4, with the right tool and in-file system passes built on top of it, you can actually do images. We regularly do images of remote disks and call the file system metadata, the volume metadata, all of the high value forensic artifacts in under 10 minutes over a new DSL connection. So in the current environment where we’re doing a lot more remote acquisitions, doing partial non-linear acquisitions gives us that ability to prioritize acquiring the high valued stuff first. And then if we have the time and if we have the reliable networking to grow that image to the point that it’s much more complete or potentially fully complete.
So most of what I’ve just been talking about, well, all of what I’ve been talking about there, is actually focused very much on physical acquisition. What we’re finding today though to be the challenge and that we’re focusing very strongly on is logical acquisition. The motivator for that is really the shift that we’re having from two locked devices, as well as two cloud-based evidence sources. Obviously with locked devices or devices like mobile phones we can’t get access to a physical drive for things like [inaudible] since [inaudible] High Sierra introduced Session Integrity Protection or SIP. They locked out our ability to get full physical access to the first driving computer. The only access that we’ve got left at that point, if we’re talking about live forensics, is file based access. If we’re looking at Cloud APIs, we don’t have physical access, we just have access to streams of data that we’re accessing via some kind of wave API. How do we do forensic images of Cloud APIs? We adopt a logical imaging style approach.

Our logical image formats at the moment, no open standards. We’ve got ones like L01s, AD1s. We’re seeing people regularly using just regular archive formats like TGZ and Zip to store evidence in, what we really need is an open standard. We needed one, this is primarily to my view that we want more metadata being preserved in our logical images. We really want to carry over the types of metadata that we would typically get from our physical images and produce those in our logical images. A key point here being something like the file birth time that we get out of MacOS or Windows.
So how do we achieve this? Well, it’s actually not all that difficult. If we take AFF4 as a basis, really, we just need to add [inaudible]. So for example, what I’m representing here is, rather than a disk image, we are representing a file image. This looks similar to the fragment of RDF that I was showing you before. Basically what I’m seeing here is an image of a folder called Test Images. It’s got a folder underneath it called AFF4-L and I’m just showing a little bit of Unicode file coding going on there. But you can see here in the metadata that we’ve preserved, we’ve got the birth time, we’ve got the last access, the last written, we’re preserving the original file name as well, just in case we’ve had to change our unique identifier. We’ve also got the record changed, which would be equivalent to the NTFS attribute we were talking about. Yeah. And this is a very small file, it’s only 4 bytes in size.
Finally, what we want to do is we want to store a hash of the individual file rather than of the free disk, so we’re reusing the hashing pass of Evimetry here, so we can see we’re going to have the linear bitstream hash stored as an MD5 and as a SHA1.
Now what we’re doing is we can reuse our compressed block stream abstraction out of AFF4 for storing large files. So what we can do is we can create a Map segment, which we use, or we can use a Map abstraction from AFF4 for large files. That is a little bit expensive in terms of storage, so [inaudible] proposing to the AFF4-L spec, but for small files, we can actually store them just as a Zip segment. I haven’t mentioned this yet, but the AFF4 format is actually based at its roots using the Zip [inaudible]. So we can reuse some of that lower level plumbing to store some logical files where it makes sense.
Now what’s the current state of AFF4-L? We proposed a paper published back in 2019 and at the time we published the pyaff4-L Open Source Implementation, prototype implementation. There’s currently two implementers, that’s Evimetry and Magnet and we are now both actively working towards formal AFF4-L as an open standard. Some of the things that really weren’t considered in the original paper that are quite interesting when you actually get into the weeds of implementing it, issues like Firmlinks, for example. So on, if you’ve seen more recent versions of MacOS that have [inaudible] Firmlinks, which essentially mean that you’ll end up seeing, in the live file system tree, two copies of each file. So, naive implementations would end up acquiring multiple copies of many, many files. May need to be aware of that kind of chip location on a MacOS, for instance.
Further, the other interesting challenges, to what extent do we go? How far do we go in preserving metadata? I’ve talked about preserving the regular metadata that we would see in a NTFS image for example, or in a HFS+ or an APFS image. How much further we go? Because in some file systems or even some operating systems, there’s further metadata associated with each file. Say for example, your MacOS is stored in Spotlight. Implementers will really have the ability to choose how much they want to put in there, but really what we want to do is come up with a reasonable base set.
So what are our next steps? Evimetry and Magnet, we’re both working together to lead the initial standard. One of the things we really need to settle on are what the core metadata vocabulary will include and which supported features will form a core part of it. That really comes down to whether or not both Maps and Zip file segments are supported. We then need to, like we did with the physical image spec, develop some canonical images and develop an Explanatory Specification document. After that, we’ll be in a very good position for third party tool vendors to consume and produce AFF4-L images and open up some new interoperability options in that space.
And that brings me to the end of my talk. Thank you for your time.





