by W.Chirath De Alwis, School of Computing, Asia Pacific Institute of Information Technology, Colombo, Sri Lanka
Abstract
Cyber security threats on sensitive resources have increased recently and it has increased the need for digital forensic analysis tools. Digital evidence can be extracted not only from hard drives but also from other memory resources of a computing device. Analyzing volatile memory is becoming popular due to increases in memory capacity. This research presents the importance of volatile memory analysis and identifies the limitations of conventional forensic methods. It also identifies the browser based information that is stored in the volatile memory and how this evidence can be retrieved for investigational purposes.
I. INTRODUCTION
At present, digital forensics is more focused on extracting evidence from non-volatile memory resources [1]. But volatile memory contains some crucial evidence that cannot be found in any other memory sources. Current findings identify that malware writers are keen to reduce their footprint on the victim’s hard disk, Instead they use the victim’s volatile memory to carry out their tasks [2]. The SQL Slammer worm is a great example of malware which exists only in volatile memory [3].
Browser based information gets stored in both volatile and nonvolatile memory. When users utilize private browsing mode, the computer does not store information about the user’s activities on the hard disk.
Information related to visited pages, forms, search bar history, passwords, download history, cookies, cached web content and offline web content are not stored in non-volatile storage media if private browsing has been enabled [4]. This has enabled malicious intruders to evade trace of their activities by disabling the logs maintained by the operating systems. Since volatile memory also stores these data, in order to investigate such cases volatile memory analysis becomes vital.
Even though acquiring memory image is not a complex task for forensic investigators, analyzing and extracting data out of the raw memory image is becoming a complicated task for them. Unless an application encrypts the data stored in memory, mostly data are stored by applications in plain text format. These application data have their own universal storage format. RAM will store the data temporally in its registers until allocated memory gets overwritten.

During this period, if the image of the memory can be acquired, these application data can be retrieved. But the limitation is that since RAM is volatile memory it has a high possibility of being overwritten by some other data in a very short period of time. After numerous studies, an approach of extracting evidence stored by browser in volatile memory has been developed.
“Keyword search”, also known as a “string search” has been used by forensic investigators to identify evidence based on known keywords [5].
In order to aid the investigators in this process, suggested methodology also has incorporated with other methodologies which will extract necessary information.
File carving is another methodology which is valuable in volatile memory analysis and it enables the investigator to extract files from the raw memory image. File carving techniques usually deal with the raw data stored in the memory and it doesn’t require considering the file system architecture during the process. Most of the forensic analysis tools do not contain features which will enable the forensic investigator to perform file carving on volatile memory.
Apart from these analysis techniques, analyzing memorymapped files is also used to extract data from volatile memory. Typically, many different types of data structures are used to describe file object.
These structures can be found by looking at process data structures and finding mapped files with that process [2].
Object table is one of the structures in the VAD tree and it can list private objects that are in use by a process [2]. These can be files, registry keys, and events. Therefore these memorymapped files contain many valuable data that may useful in investigating computer crimes and those data can be extracted from analyzing different data structures.
II. RELATED WORK
There are several volatile memory analysis tools which have been developed in the recent past. Volatility, Redline, Memoryze, FATKit, WMFT, VAD tools, EnCase, Rekall, Internet Evidence Finder (IEF) and FTK are the most popular volatile memory analysis tools.
Since most of the available tools are more focused on processes and threads, extracting web browsing artifacts has become limited. The capability of extracting email and social media artifacts has been limited in existing tools.
Even though Volatility has plugins for usernames and passwords, search forms [10], dump files [11], Facebook and Twitter artifacts [12], Volatility does not support the extraction of other social networking artifacts.
When comparing the existing tools it is evident that extracting web URLs is a common feature on both commercial and open source tools but only limited number of tools supports the string search and file carving functionalities.
Even though Internet Evidence Finder (IEF) supports multiple social networking artifacts the extraction of Facebook artifacts is limited in this tool. Extraction of Google search, YouTube titles, file carving and string search are also not available in this IEF tool.
III. TARGETED EVIDENCE RETRIEVAL
In order to simplify recovery of appropriate evidence, a classification was devised with five distinct categories: social networking, video streaming (YouTube), web history, email communication and VoIP (Skype). String search and file carving methodologies are also integrated as part of the proposed tool.
A. Social Networking
Social networking includes evidences that are related to most commonly used social networking sites such as Facebook, LinkedIn, Twitter and Google search. Table (I) illustrates the evidence that can be retrieved which are related to the above mentioned social networking sites.
TABLE I. DETAILED LIST OF SOCIAL NETWORKING ARTIFACTS
| Social Network | Artifacts |
|---|---|
| Login credentials, Security code, Messages, Observed images, Observed profiles, Provided Comments, Friends information, Notifications, incorporated third party apps, Hash tags, Status updates, Location status, Groups and Life events |
|
| Login credentials, Security code | |
| Login credentials | |
| Google search titles |
B. Video Streaming (YouTube)
Video streaming evidence will provide titles of videos that user have searched on YouTube.
C. Web History
Web history information will include Domain names, visited URLs, Visited PDF links, downloaded or opened JPEG images.
D. Email Communications
Email communications information will include evidence related to Gmail, Yahoo and Hotmail service providers. The table below shows the detailed list of evidence that can be retrieved.
TABLE II. DETAILED LIST OF EMAIL COMMUNICATION ARTIFACTS
| Artifacts | |
|---|---|
| Gmail | Login credentials, Contacts, Emails, Security code |
| Hotmail | Login credentials, Emails |
| Yahoo mail | Login credentials, Emails |
E. VoIP (Skype)
Information related to the most commonly used VoIP application, Skype, also can be retrieved. This information will contain the usernames used in the system to access the service provided.
IV. FRAMEWORK DESIGN
The framework includes two different components which can be used to extract evidence from volatile memory.
A. Extracting artifiacts based on Pattern Matching
The process of extracting artifacts based on pattern matching has three main phases.
In the initial stage, the investigator has to identify the unique pattern used by the applications to store data in the device. Various patterns are used by different browsers and operating systems.
In order to identify the exact pattern of data storage, multiple tests must be conducted. An example of a pattern identification is shown below.
Eg: Facebook stores their security code under “&approvals_code=”.

Whenever a user enters the six digit Facebook security code, it writes to the volatile memory under “&approvals_code=” string. Therefore “&approvals_code=” can be identified as the pattern that stores the Facebook security code.
In the second stage, evidence which have been identified using provided pattern has to be recovered from the volatile memory image. The regular expression in JAVA programming language is a great method to extract these data from the memory image. To extract the evidence by using regular expression, it requires a text file with the ASCII content of the memory image.
Eg:
The regular expression used to extract Facebook security
code:
\\&approvals\\_code\\=\\w{6}
Finally, it is required to filter the regular expression output to display the relevant content.
Eg:
Regular expression result before filter:
&approvals_code=123456
Regular expression result after filter:
Facebook Security code is: 123456
B. File Carving based on Header-Footer
File headers and footers; refer to specific patterns of values that are unique to the type of files [6]. These header and footer values can be used to identify the file within the memory image.
The content of the file is stored in between these header and footer values. The aim of this method is to identify the memory location where the file is stored at. Then the footer value is used to identify the memory size and the address location where the file is stored.
Eg:
Header value of a JPG file: FF D8 FF E0
Footer value of a JPG file: FF D9


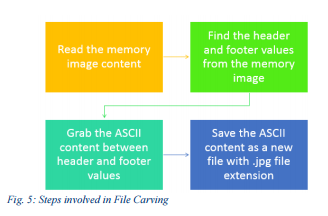
Since images using JPG compression was the targeted artifact, the methodology of carving .jpg files is elaborated below.
Once the memory image is acquired then the header and footer values of the file should be identified. After successful identification of the header and footer values or the corresponding offset values then the next step is to extract the ASCII content in between these header and footer values. The final step is to save the content as a new file with the extension of “.jpg”.
The same methodology can be used to carve any file format by converting the header-footer values and saving the new file with the relevant file extension. This method allows the investigator to carve multiple files with a minimum time. Since memory image may contain multiple files, it is possible to find the same header and footer value in multiple locations on the memory image.
The file is not overwritten; fragmented, compressed or encrypted are the assumptions that should be made when carving files from volatile memory image [7].
V. DATA ANALYSIS AND RESULTS
WinHex and HxD have been used as the primary tools to analyze the results. WinHex and HxD are hexadecimal editors capable of viewing the volatile memory image content. Testing is done on both Mozilla Firefox and Google Chrome browsers. The results of each and every function of the implementation were then tested manually with the use of above mentioned hexadecimal editors.
The accuracy of the identified patterns was tested comparing both expected and actual outputs. The same test was performed multiple times against multiple memory images. This was performed manually using the above mentioned hexadecimal editors.
After numerous tests, it is evident that the implementation of the methodology of the data extraction based on pattern matching which used to extract artifacts described under “Section III” has an accuracy of 90%. Implementation of the “Web History” was not 100% accurate and it had some false positives.
Apart from “Web History”, this pattern based data extraction method was able to retrieve expected outputs for each and every artifact described under “Section III”.
Proper test cases for each and every pattern were identified and the implemented function was designed to test the outputs. To verify the accuracy of this method and results, these tests were conducted multiple times and the results were compared.
Implementation of the string search was performed well but it requires some modifications. Implemented string search was able to find the searched strings with an accuracy of 90%.
Even though the implementation of the file carving was not completed, the method described under “Section IV” was tested manually using the above mentioned hex editors. The accuracy of the file carving methodology was 100%. Accuracy was identified by manually carving files from the memory image. This method has an accuracy of 100% because it was able to carve viewable .jpg files from the memory image.
After numerous tests on both .raw and .dmp memory image formats, it was evident that this developed application supports both .raw and .dmp memory image formats.
Integrity of the evidence is one of the most important components in digital forensics investigations. To ensure the integrity of the memory file after the analysis, hash values (SHA-1 and MD5) were taken on the memory image before and after the analysis. Comparing these hash values evident that the original hash value of the memory image was not changed after the analysis. It can conclude that this application does not affect the hash value when it is being analyzed.
VI. CONCLUSION
The analysis of digital evidence is facing several key challenges. Memory forensic techniques have the potential to overcome these issues [1]. But, most of the research carried out focuses on processes and threads.
But, apart from these data, memory holds various other data which has forensic value when investigating crimes.
Since malware writers began reducing their footprint in victims’ hard drives, it is difficult to trace activities performed by these malware from analyzing hard drives. Therefore an improvement on traditional forensic methodologies has become essential when investigating crimes.
Features such as “Private browsing” do not save browsing information when enabled. So users can take the benefit of such features to reduce their footprint. Therefore investigating such crimes are difficult with traditional disk forensics methodologies. Even though these features do not store browsing information on the client’s hard disk, this information can be found in the volatile memory. So there is a possibility of extracting these artifacts from the volatile memory.
Unless an application encrypts its data, data used by the applications are in plaintext format. During an application process, these data are temporary stored in the RAM. Since most of the plaintext data available in the volatile memory belongs to applications, these available plaintext data may contain valuable information. After numerous tests, an approach of extracting artifacts based on available plaintext data in the volatile memory has been developed. This approach was able to address a different area, which other available software solutions couldn’t address. With this approach, it was able to extract forensic artifacts based on five main categories such as social networking, email communication, web history, VoIP and video streaming.
After the identification of some common problems in the available software based memory analysis tools, an integrated solution has been implemented as a proof-of concept of the extracting artifacts based on pattern matching method.
Apart from these data, the application has an integrated string search methodology where the user can search for any known string against the memory image. “File Carving” is a technique that is used to carve files from a memory file.
Even though this header-footer based file carving is an existing methodology, the advantage of this method was limited to non-volatile memory. Most of the available tools do not support file carving from volatile memory.
After numerous tests it was evident that this header-footer based file carving methodology can possibly be used against the volatile memory to carve files. As a result of that, this file carving methodology was also integrated in this application. This integrated file carving methodology was designed to carve JPG files from the memory image.
This developed application is capable of extracting 36 types of data from the volatile memory which is a comprehensive development in the field of memory forensics. It is an accurate solution that can address many different problems in the field of memory forensics.
After numerous tests it was evident that this developed application is capable of extracting artifacts even when the user enables the “private browsing” feature on his/her browser. As in the “section V” this application was able to extract artifacts from both .raw and .dmp memory image formats that allow investigators to use multiple memory image formats. This developed application does not affect the original hash value of the memory image after the analysis. It ensures the integrity of the memory image.
As with every other volatile memory forensics tool, the volatility of the data in the RAM is a challenge in this developed application. If data stored in the RAM were not overwritten, it is possible to extract these addressed data from the memory image.
VII. FUTURE ENHANCEMENT
In the future, this application can be enhanced to more advanced application by integrating other existing methods with more efficiency and accuracy.
Since file carving focuses more on the JPG file type, this application can be enhanced to extract other file types as well. Command line details [8] and encryption keys [9] are some other possible data that can be extracted from volatile memory. Extracting such data can also be integrated into this application.
Since the extraction of data from Twitter, LinkedIn and Skype is limited in this application, it is also possible to improve the extraction of data related to these social media.
Since memory acquisition is out of the scope of this project, memory acquisition can also integrate into this application. From a forensic perspective, it is also important to have perfect research methods when selecting the acquisition tool, because running an application in a computer can overwrite the data available in the volatile memory.
REFERENCES
[1] Simon, M. Slay, J. (2009). Enhancement of Forensic Computing Investigations through Memory Forensic Techniques. [Online]. P 995. Available from: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5066600 [Accessed 04/06/2014]. [2] Amari, K. (2009). Techniques and Tools for Recovering and Analyzing Data from Volatile Memory. [Online]. P 10-25. Available from: https://www.sans.org/reading-room/whitepapers/forensics/techniquestools-recovering-analyzing-data-volatile-memory-33049 [Accessed 01/06/2014]. [3] Moore, D. et al (2003). Inside the Slammer Worm. [Online]. P 33. Available from: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1219056 [Accessed 4/07/2014]. [4] Mozilla. 2014. Private Browsing – Browse the web without saving information about the sites you visit. [ONLINE] Available at: https://support.mozilla.org/en-US/kb/private-browsing-browse-webwithout-saving-info?redirectlocale=enUS&as=u&redirectslug=Private+Browsing&utm_source=inproduct#what-does-private-browsing-not-save [Accessed 06/10/2014]. [5] Amari, K. (2009). Techniques and Tools for Recovering and Analyzing Data from Volatile Memory. [Online]. P 10-25. Available from: https://www.sans.org/reading-room/whitepapers/forensics/techniquestools-recovering-analyzing-data-volatile-memory-33049 [Accessed 01/06/2014]. [6] Shaw, R. 2013. File Carving. [ONLINE] Available at: http://resources.infosecinstitute.com/file-carving/ [Accessed: 11/9/2014]. [7] Merola. A. (2008). Data Carving Consepts. [Online]. Available from: http://www.sans.org/reading-room/whitepapers/forensics/data-carvingconcepts-32969 [Accessed: 11/09/2014]. [8] Stevens, R,M. Casey, E. (2010). Extracting Windows command line details from physical memory. [Online]. P 1. Available from: http://www.sciencedirect.com/science/article/pii/S1742287610000356 [Accessed 01/06/2014]. [9] Hargreaves, C. Chivers, H. (2008). Recovery of Encryption Keys from Memory Using a Linear Scan. [Online]. P 1369. Available from: http://ieeexplore.ieee.org/xpl/articleDetails.jsp?tp=&arnumber=4529504&queryText%3Dwindows+memory+analysis [Accessed 4/07/2014]. [10] Ligh , M.H.(2014) Announcing the 2014 Volatility Plugin Contest Results! [Online] October 29th 2014. Available from: http://volatilitylabs.blogspot.com/2014/10/announcing-2014-volatility-plugin.html [Accessed: 11/12/2014]. [11] Volatility Foundation. 2014. Command Reference. [ONLINE] Available at: https://github.com/volatilityfoundation/volatility/wiki/Command%20Reference#dumpfiles [Accessed 11/12/2014]. [12] Volatility Foundation.(2013) Results are in for the 1st Annual Volatility Framework Plugin Contest! Available from: http://volatilitylabs.blogspot.com/2013/08/results-are-in-for-1st-annual.html [Accessed: 11/12/2014].About the Author
 I am Chirath De Alwis. An information security professional with more than two years’ experience in Information Security domain. I am armed with C|EH, C|HFI and Qualys Certified Security Specialist certifications. Currently involved in vulnerability management, incident handling and digital forensics activities in Sri Lankan cyberspace. You can contact me on [email protected].
I am Chirath De Alwis. An information security professional with more than two years’ experience in Information Security domain. I am armed with C|EH, C|HFI and Qualys Certified Security Specialist certifications. Currently involved in vulnerability management, incident handling and digital forensics activities in Sri Lankan cyberspace. You can contact me on [email protected].





