Justin Tolman: Episode five, and we’re already doing a sequel. We’re taking another look at optimizing our processing in FTK Feature Focus.
Welcome back. This is episode five of Feature Focus. I’m Justin Tolman. I’m the Director of Training over North America for AccessData, which is an Exterro company. It’s a new name, but the same great software.
And today we’re taking a deeper look at optimizing our processing options. That was not originally scheduled today, but a topic came up through the support portal. And I think there’s more that we can talk about — some concrete examples and some ways that we can talk about — reducing the amount of time, and getting to that evidence quicker. Let’s get into it.
All right. So from our support chat, this issue was brought up through there, and a discussion evolved. So what the user says is: I uploaded several outlook PST files on Friday, and the status still says ‘processing.’

They uploaded multiple PST files. So each PST file is 10 gigabytes in size, for a total of 100 gigabytes of data. Would this size cause it to hang? So first off, FTK isn’t hanging in this case, it is still processing. There’s a large amount of data and it’s going to take a lot of time to chunk through it. And so let’s talk a little bit about that.
So the first question you’re probably asking is, wait, isn’t this FTK Feature Focus? And the question is yes, but the same concepts can apply. And so I think this will apply to FTK in the way that we process our evidence. And so specifically, what we’re going to look at is email today.
So first off, what is our objective again? Our objective is to determine if there’s any evidence, if we need to go through. So in this case, a recommendation may be — and remember, this is just a general recommendation — your policies, procedures, laws, yada yada, yada will of course apply.
So our recommendation may be to load the PST related to the primary individual of the investigation, if there is such. If they are all to one individual, then maybe start with the PST that is most recent or closest to the time of the event that you’re investigating. This would be advised if you’re going to run a lot of processing options on them, okay? Because 10 gigabytes alone, and I know we’ve got more, but 10 gigabytes is a lot of email. So if we do a math on the 100 gigabytes of data — and email sizes vary and are kind of all over the place — but if we picked a round number of say, 200 kilobytes per email, that’s going to round out to about 500,000 emails that we could have in there, give or take a couple thousand, right? Depending on attachments and all that. So, that is a lot of text data that you’re going to be processing that it’s got to go through. So we want to try to optimize that if we can.
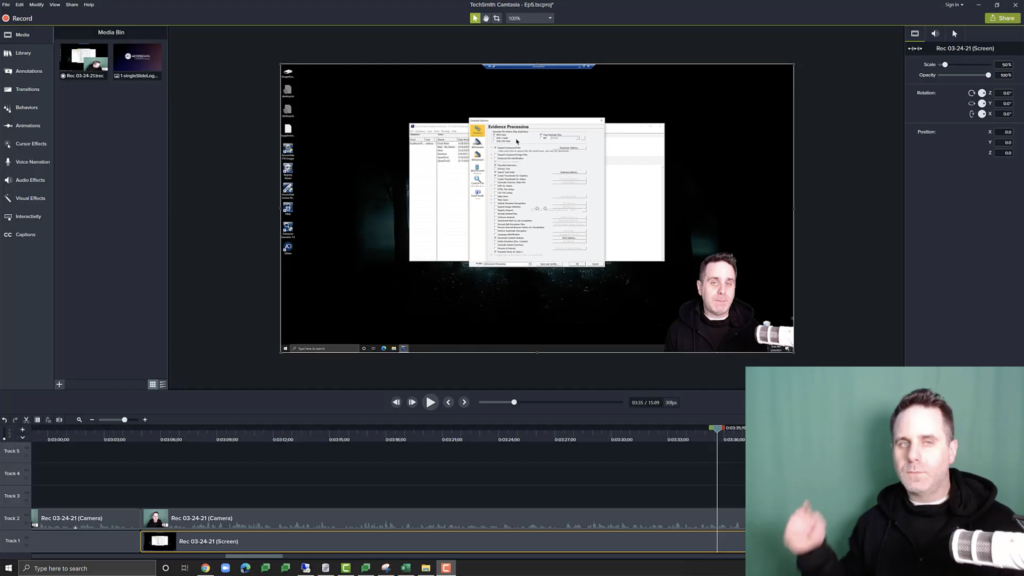
Let’s address this question head on first from the e-discovery processing profile within FTK. That processing profile is shown here on this screen, and we can see what we would get if we loaded in 100 gigabytes of data, and we just chose the default, the ediscovery default, and pushed it through. So first off we have the MD5 hash and flag duplicate files. And this is a common work flow when working with emails, as you want to reduce those duplicate emails and files, et cetera.
Now remember, MD5 hashing, you’re going to be hashing all the files. So if we go with our 100 gigabytes, approximately 500,000 emails, that’s a lot. And there are a lot of small files. So it’s starting and stopping that process quite a bit.
Hold up. So, one thing I noticed when I was editing here is, in the ediscovery software default options, there’s actually a small change, in that the known file filter is also enabled for deduplicating actual files. So that’s also another thing where it’s got to process and run the KFF engine as well. That’s going to increase time if you’re on the ediscovery side, if you were to enable that here, it would do the same thing, but by default on the FTK side, it’s not enabled.
Alright, back to… and then we’re going to flag duplicate files. So on top of that, we’re comparing that hash.
We also have various expansion options selected here in the expand compound files, PSTs, archives, various office documents and PDFs, those types of things. Things that you may need, things that are commonly attachments, those types of things. So that’s fine. We’re going to flag bad extensions. Okay.
We’re going to do the search text index. The search text index is incredibly useful, so I’m not saying you turn that off, but remember you have all text data in email, it’s primarily text data. So it’s going to take some time to chug through that. It’s going to generate a large database.
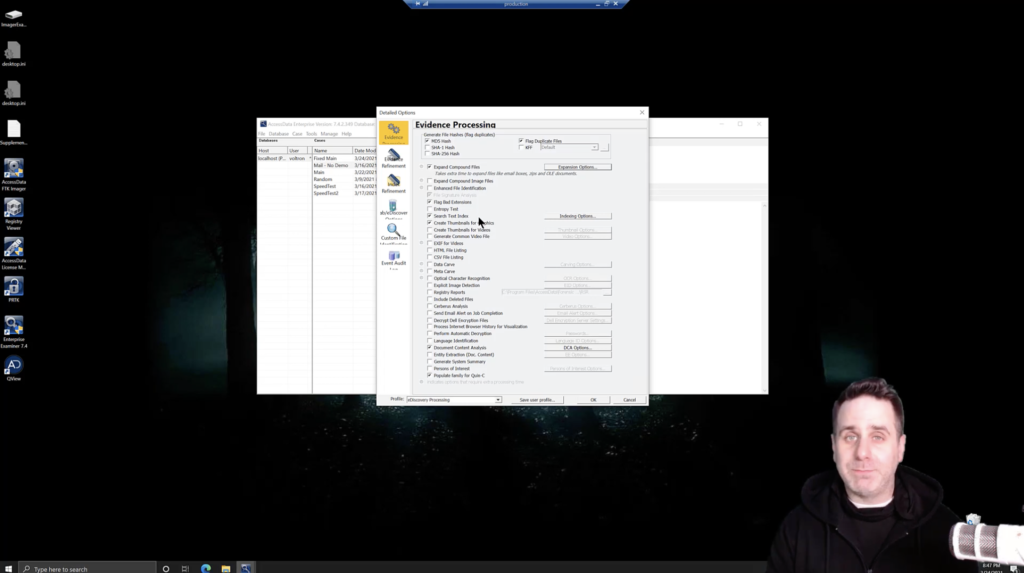
Create thumbnails for graphics. Now this one is one that maybe you could tweak, but again, you’re doing this by default. So if you just click default, you’re going to get those thumbnails on any attachments or any other things that may be in that image that you’re going to get. Now, in this case, it’s just PSTs. So they’ll all be attachments. Okay.
And then we don’t really have much else, other than document content analysis. If there was a lot of emails discussing, say, something like purchasing, it’s going to try to group those up into a little category that we could see in the overview tab. Really helpful, but it’s going to add some time to your processing. And remember, you’re dealing with 500,000 emails. And so every time it has a group, it has to look at all 500,000.
Also with ediscovery processing profile in FTK, you’re going to be de duplicating. Okay? And an oversimplification of the deduplication process is that it takes various fields. So you can see those fields here: to, from, CC, subjects, submit time, et cetera. And it’s going to hash those, create a checksum for those. And then it’s going to compare all of those fields across the dataset to determine, Hey, this email is already in there. I don’t need to bring it in again. Now, that’s great when you’re in the analysis phase and that’s what you’re doing now, you’re processing heavy upfront. You’re spending that time now so that you don’t have to look at it later. And it’s quick, once you get in the analysis phase, but it is time. And remember you’re dealing with a dataset of approximately a half a million emails. Yeah. That’s why it’s going to take a long time, because you’re doing a lot of things.
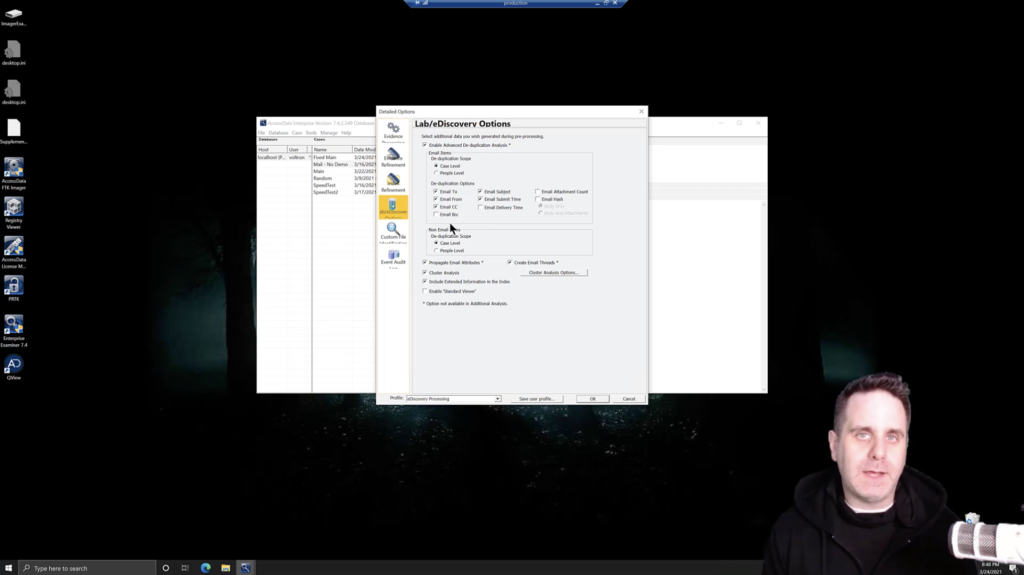
Now, other things that could impact the time on, say, an email case is a frequent a workflow for ediscovery is to use optical character recognition for things like tiffs and PDFs. Now, this is great because it’ll make all those easily searchable, even though they’re graphics, for the text that’s within them. But if you do that as a pre-processing option, you will scan all attachments and OCR every relevant file. Now you can reduce the types of files that are OCRed by selecting specific file types, but still, you’re not targeting just the topics that you want, or just the people that you want, or the subject, or that sort of thing. You’re still going to get everything. So if in those PSTs, only 10% of the emails are things you even care about, you’re still OCRing 100% of the attachments. So be aware that that’s going to add time that you didn’t need to spend.
So another reason you may need to, or want to, bring each item in individually is if you’re not in total control of the infrastructure on which your evidence is processed. In this case, the user reported to us that their IT department needed to bring the server down for maintenance or some issue. And his case was still processing. What do we do here? This way, you are processing for less time per chunk, and if you needed to wait in between chunks or tell them to wait, at least just another day or a couple more hours for the 10 gigabyte PST to process, that’s going to be a lot better for you as well.
The nice thing about FTK is that you can add evidence at any point through the analysis and do additional analysis as well. We talked about that in the last episode where remember, we want to determine if we have any evidence. Is there anything to support the hypothesis of our case? Is there evidence? Is there not? Et cetera. Okay. And so we want to get in as quickly as possible.
And so we can go up to evidence and then add, remove, and continue to add a PST as we go through, checking them as we go, this will reduce your upfront processing time and allow you to target things for additional processing. Okay. So if we need to come back in and OCR some documents, we know, okay, I only need to say here, Danielle Jason’s. I only need to OCR the attachments associated with her emails and I can check those, target them, so I’m OCRing, maybe, 200 emails instead of 500,000. Okay?
So don’t be afraid to do a little light processing on the front end and then do additional processing later, because you’re going to work those emails. It’ll be the end of the day. You can fire off an OCR job. It’ll be done by the time you come back in the morning. And you work your OCR, you haven’t lost any time on the computer, and you come back, load the next 10 gig, and go.
Now, if you don’t have anybody else using the machine, and like most of us, we have plenty to do plenty of other cases work. Maybe you’re going to go work other things. Then you can just let it run. And that’s fine. But in the case of, like, this user here, where they had pressures from outside their department with the IT, and it was just a lot of data and they may have over selected on processing options, at least upfront, then you can cut that down by optimizing your processing options in the pre-processing and do additional analysis later.
Thanks for watching. And if you want to take a deeper dive into the software, learn a bit more how to use it and optimize it and get the most out of your cases, of course you can sign up for training at training.accessdata.com. Is it worth it? Are you worth it? Thanks for watching. We’ll see you next week. Bye.





