by Stephen Stewart, CTO, Nuix
Preface: This NOT about politics. This is all about the data discussed in Volume 1 of The Mueller Report.
I will admit, I am a total geek. When the government released the Mueller Report, I downloaded the PDF and, within a few minutes, ran it through Nuix.
For anyone who works with unstructured data for a living, the document would fall into the category of “Gross Data.” The PDF was a container for 447 JPGs with zero searchable text. Nuix made short work of this, and I was able to quickly OCR the images. Thanks to the auto-detect for rotation I was able to very quickly get good clean text.
From there, I extracted named entities (people and company names, email addresses, etc…) and pulled out a list of shingles (basically a quick way to look for repeating phrases).
Named Entities
The Mueller Report contains a wealth of named entities. Here are just a few examples:
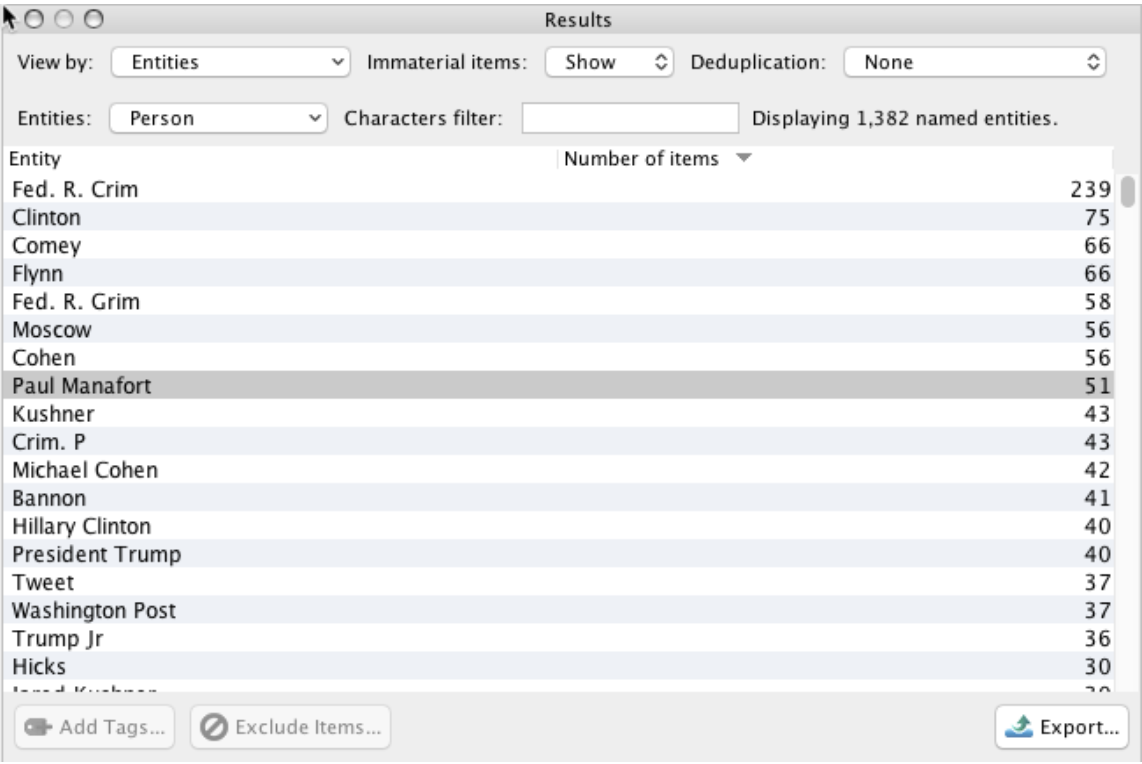
People
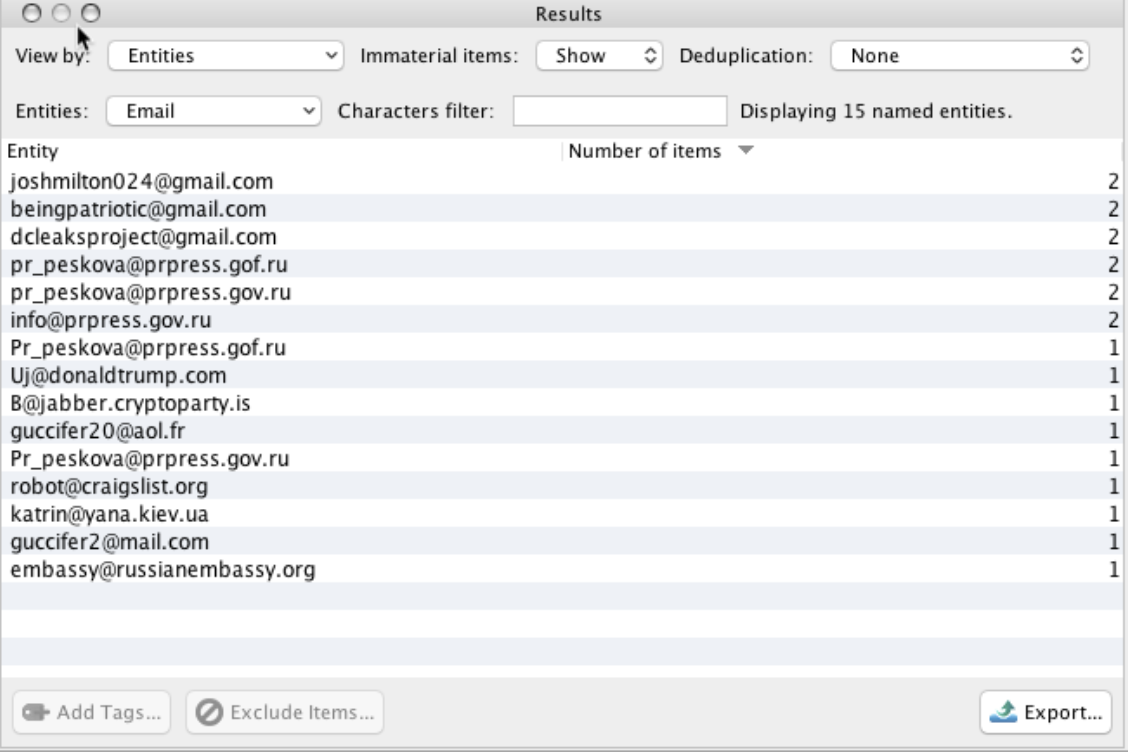
Email Addresses
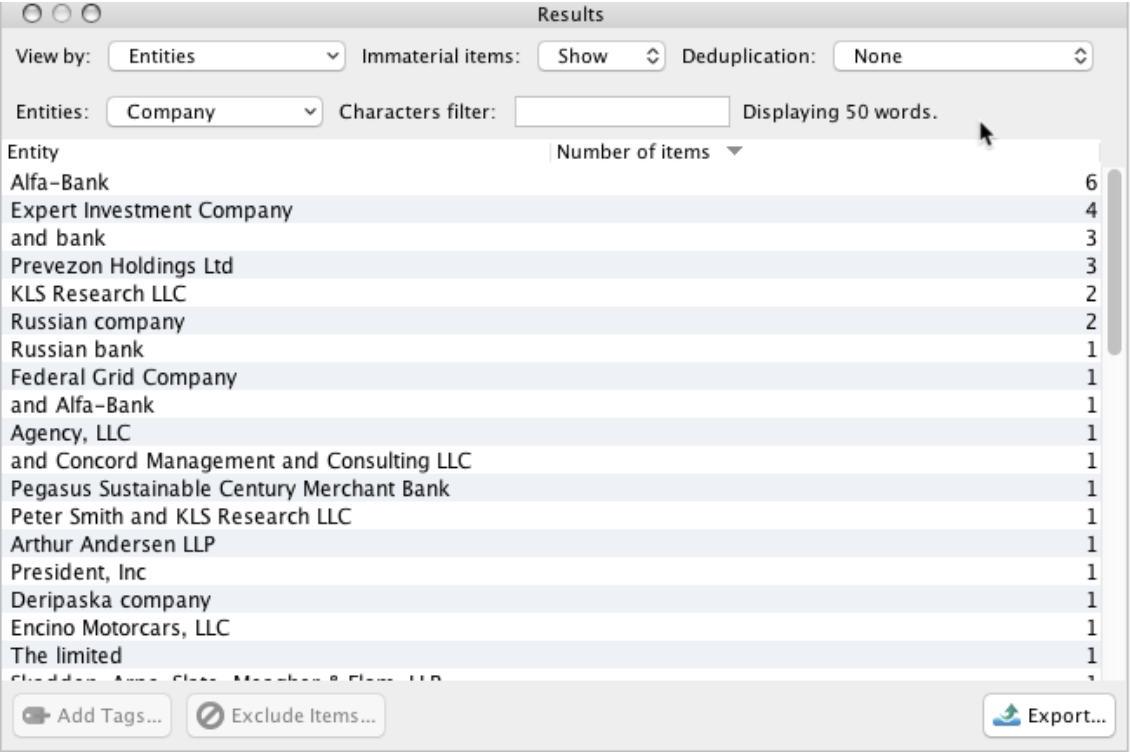
Company Names
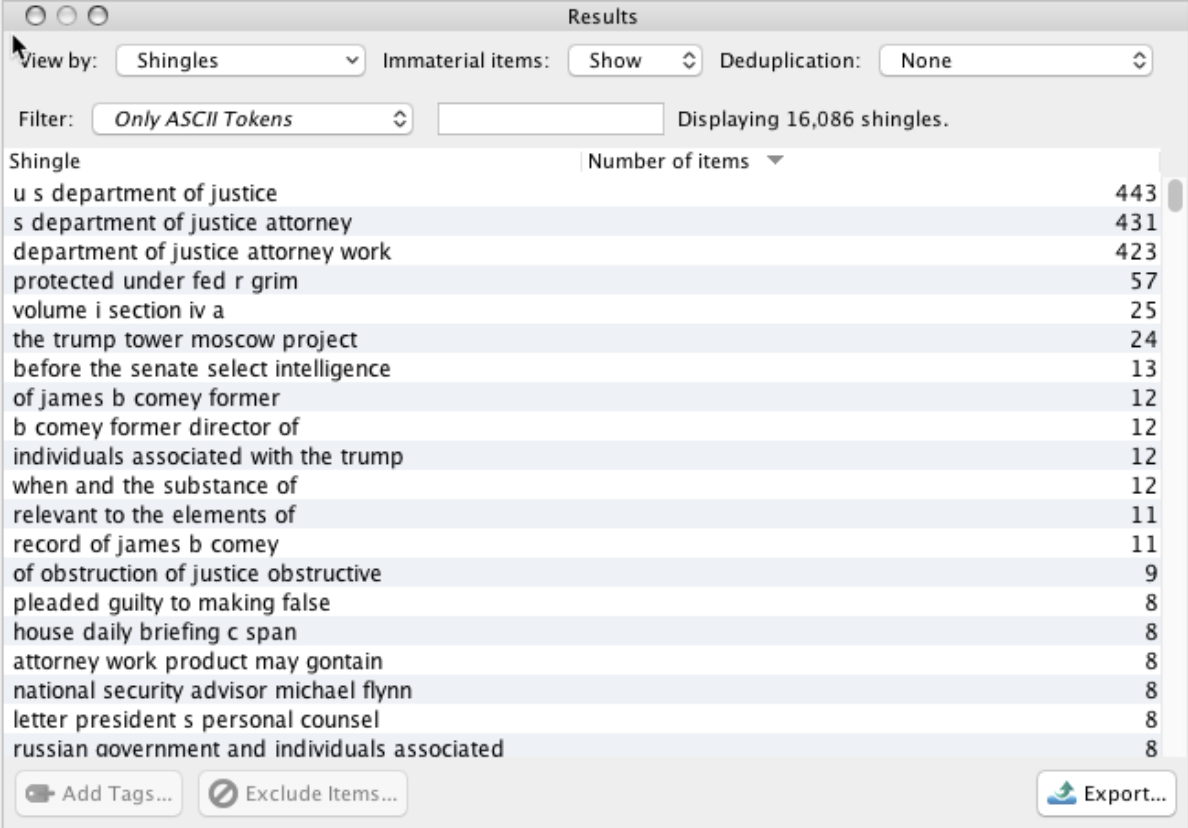
Shingles

Note: “Number of Items” refers to the number of pages that contained the entity or shingle.
Thanks to how fast I had all of this detail, I was able almost immediately to start to get a sense of the document’s content and quickly understand what the data landscape looked like.
Next Step: Analysis
So, what’s next? I decided to do a little open source analysis and compare the report to things like the publicly available data released by the ICIJ as part of the Panama Papers and the United States Treasury Specially Designated Nationals And Blocked Persons List (SDN).
This was also super easy, since I had already converted the Panama Papers and SDN to a huge search and tag (more on that in another blog post!) I should note: Many of the search tokens are over-broad, but it’s still a really interesting exercise…
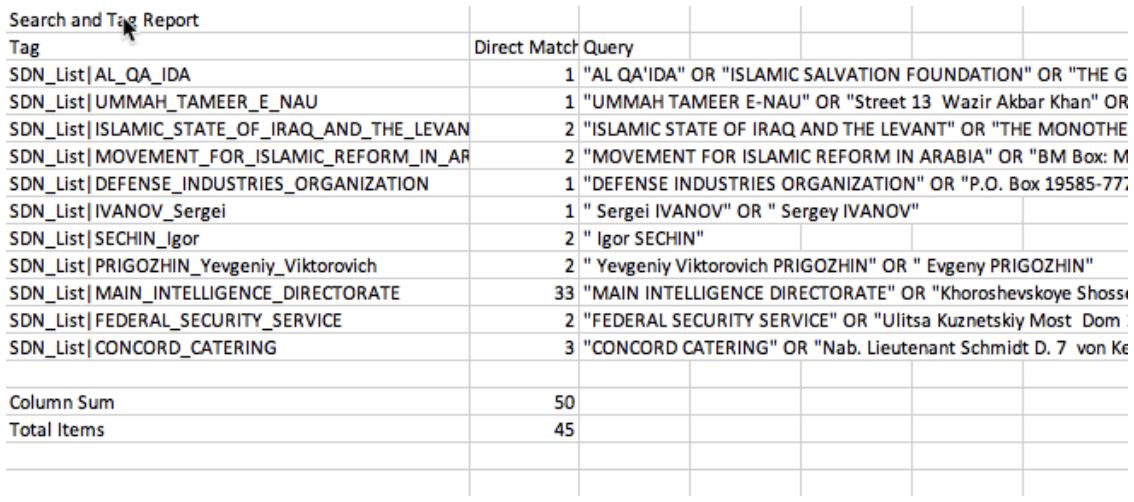
As a reminder, all of this was extracted from just the final report – not the actual source data!
The actual source data that was part of the investigation read:
“During its investigation the Office issued more than 2,800 subpoenas under the auspices of a grand jury sitting in the District of Columbia; executed nearly 500 search-and-seizure warrants; obtained more than 230 orders for communications records under 18 U.S.C. § 2703(d); obtained almost 50 orders authorizing use of pen registers; made 13 requests to foreign governments pursuant to Mutual Legal Assistance Treaties; and interviewed approximately 500 witnesses, including almost 80 before a grand jury.”
Within just this short example of the source data, we have a lot to consider, including:
- 2800 subpoenas: With 87 references to Facebook and the detailed documentation as to the activity of certain profiles, can you assume that the Office was sifting through Facebook, Twitter, and Instagram data?
- 500 search and seizure warrants: That is bound to generate at least a couple hundred hard drives and mobile devices.
- 230 2703(d) and 50 “pen registers”: Interesting in that it laser focused on who is talking to whom and the frequency of their communications.
- 500 witnesses: That is a whole lot of testimony that needs to be checked against all that digital evidence.
Modern Investigations Are Complex
Regardless of your political persuasions, Volume 1 of the the Mueller Report offers an amazing look into the complexities of modern investigations and really highlights the importance of being able to handle diverse collections of data about, and created by, humans and then being able to understand the people, objects, locations and events (POLE).
Nuix’s software fits right into the middle of this landscape—helping organizations handle gross data, running hundreds of thousands of searches looking for hidden links, and visualizing relationships across the POLE framework. I’m continually surprised at how powerful and extensible it truly is.
In my next few articles, I’ll dive further into some of the topics I touched on here:
- What it feels like to targeted by a Nation State
- Human-generated data is at the heart of most investigations (even in 2019)
- Using open source intelligence lists to augment investigations





