by Harold Burt-Gerrans
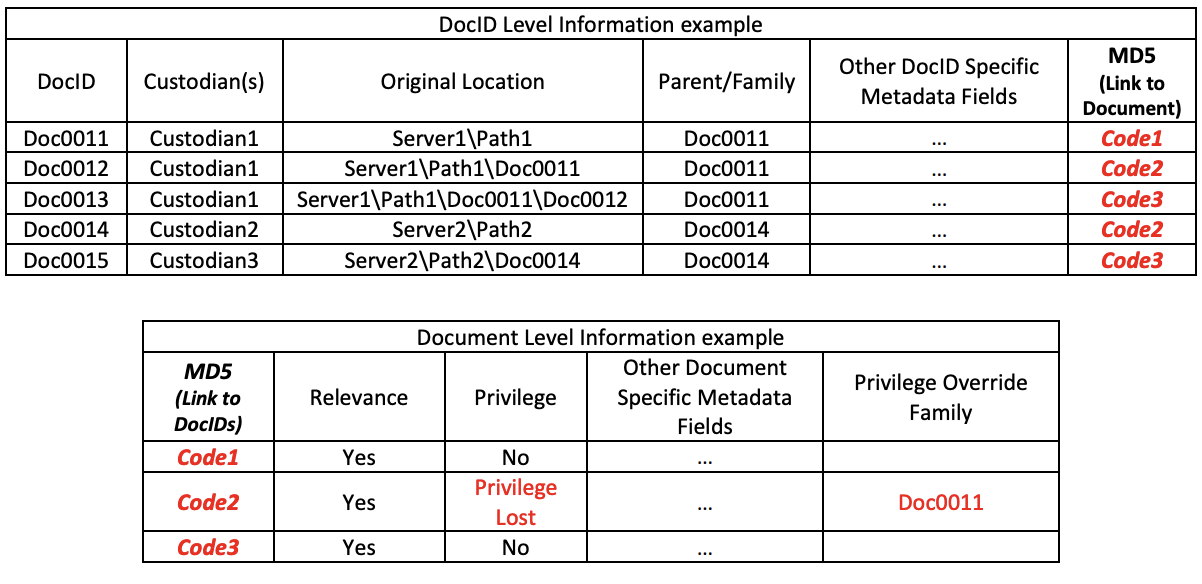
In Part 3, I introduced the concept of consolidating duplicates by tracking Metadata at a DocID level and coding and/or document actions at a Document Level. For ease, I’m duplicating part of the example charts here as I will refer back to them to illustrate some of the following discussion.
Sample Current Data Structure:
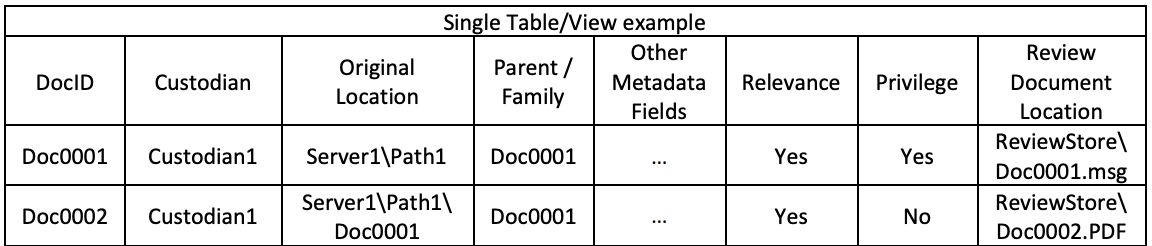
Sample Multi-Table View:
Family Level Coding
Perhaps you noticed in the above example that Doc0001 is privileged and the attachment Doc0002 is coded as not privileged. Within quality review platforms, this is the proper way to code the documents. At production time, let the family level coding control the production of the specific documents. This type of functionality can be accomplished today.
By coding this way, it becomes obvious as to which documents caused the coding decisions for Relevance/Responsiveness and/or Privilege. It also prevents the incorrect propagation of coding to other document families when coding replication is enabled (e.g. marking a non-privileged (on its own merit) attachment as privileged because the parent is privileged potentially causes a duplicate copy of that attachment to become marked as privileged due to coding replication).
By using the concept of family level coding to control productions, the idea of a non-privileged document gaining privilege does not need to be tracked, it simply follows the disposition of the privileged document within the family Remember from Part 2:
“A document can, on its own merit, be considered privileged or not, and due to various family relations, privilege can be lost or gained.”
Conversely, the concept of “Privilege Lost” should be tracked. Functionally, “Privileged Lost” = “Not Privileged,” but I suggest that the privilege coding currently used be expanded to include a “Privileged Lost” setting for the benefit of the review teams and Quality Control reviewers. This should be done (today) when coding replication between duplicates is in use, and is even more necessary if a review platform introduces a document storage structure similar to the one I previously proposed (example above).
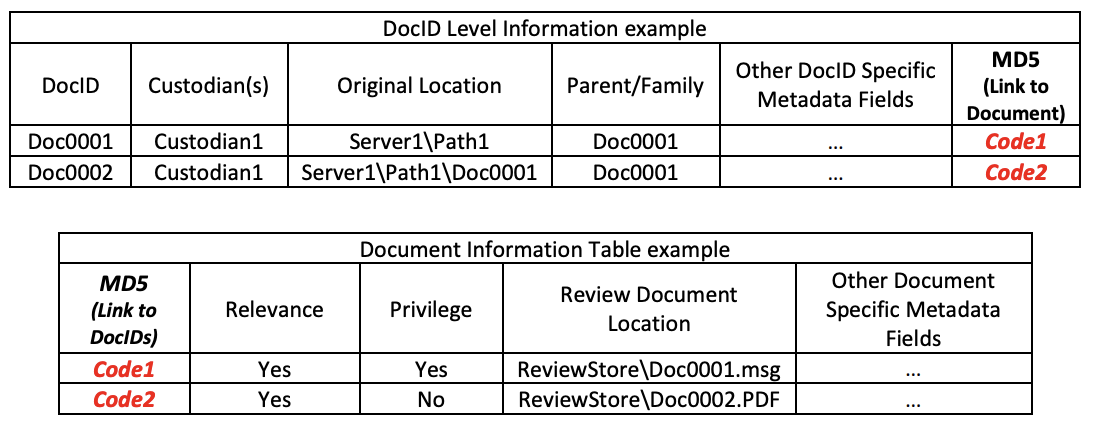
Consider a document, perhaps an email from a client to a lawyer, which would be considered privileged on its own merit. The first reviewer that looks at that email will likely code it as privileged. Subsequently, a second reviewer might find that same email was attached to another 3rd party email, which would cause the privilege to be lost. Updating the coding to “Not Privileged” will likely cause work at the QC level since they will need to investigate why the obviously “privileged-on-its-own-merit” document is not coded as such. However, if the QC reviewers find documents coded as “Privilege Lost”, they would immediately know that the coding is due to overriding non-privileged family members or other related documents. To help the QC reviewer, it would also be beneficial to have a coding field which contains the DocID(s) of that overriding Document or Family. This is especially important (today) if replication is used, as the overriding family member may not be a member of the family of this copy of the document, as shown below.
Sample Current Data Structure:

Sample Multi-Table View:

I know what you’re thinking… Doc0011’s family would be produced, so Doc0014’s family doesn’t really matter. And you’re right. But that’s a simple example to demonstrate the “Privilege Lost” concept. Now let’s examine another example with a bit more complexity.
Assume that Doc0021 would be an email that is privileged, and contains a non-privileged attachment Doc0022. Normally, these two documents would be withheld as a privileged family. But, Doc0023 is a non-privileged email that is the end of an email thread and includes the body of Doc0021 through a forwarding or reply. Doc0021 loses privilege as soon as Doc0023 is found, and consequently, should be produced along with Doc0022. The coding should be as follows.
Sample Current Data Structure:

Sample Multi-Table View:
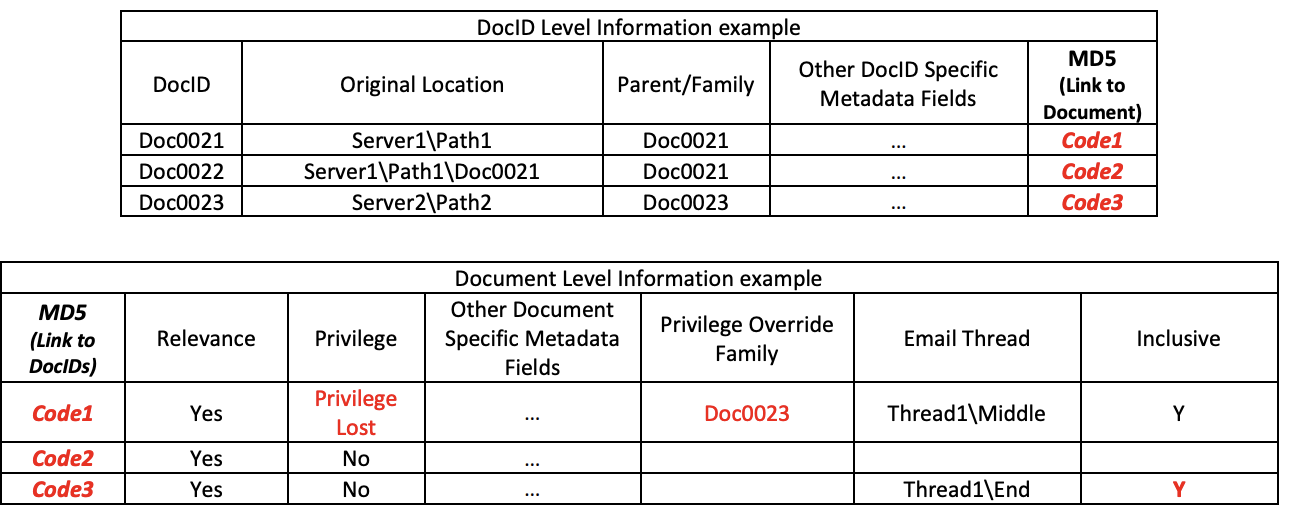
As shown in the above, privileged emails that are part of a thread ending with an inclusive, non-privileged message should be checked for loss of privilege. Consider that Doc0012 above is part of Doc0011’s email thread, but as an email itself, remember that it may also be part of a completely different thread.
As the complexity of a web of threads increases, and then consider the effect of identifying textual near duplicate emails where virtually identical information may be relayed in completely unrelated messages, it becomes apparent that coding based solely on simple relationships is not necessarily reflective of the truth, and better data structures are required to track the influences of documents on each other. Thus ends Part 4. Nothing discussed so far is too radical I hope. Part 5 will likely be the closing of my set of posts (unless something requiring another large rant comes along) where I’ll add another new concept or two, including Recursive De-Duplication (which I thought would be in this part, but it made this posting too long so I pushed it to Part 5). Part 5 should tie everything together to present my vision of eDiscovery Utopia (eUtopia ?).
Read part five here.
About The Author
Harold Burt-Gerrans is Director, eDiscovery and Computer Forensics for Epiq Canada. He has over 15 years’ experience in the industry, mostly with H&A eDiscovery (acquired by Epiq, April 1, 2019).





