
During the Kenosha Shooting trial (“STATE OF WISCONSIN – VS – Kyle H. Rittenhouse”), there has been a lot of discussion about the applicability of image interpolation and images enhancement to video evidence. Martino Jerian, Amped Software‘s CEO, has clarified many important concepts related to forensic video analysis in this “Enhanced Reflections” article on the Amped Blog. We are publishing here some of the parts that are more important for the wider digital forensics community.
YOU DON’T KNOW WHAT YOU DON’T KNOW
The beauty and damnation of image and video forensics is the fact that it’s something that at a visual and intuitive level seems very understandable to the average viewer but actually underlies pretty complex mathematical concepts. While it seems easy, the risk of getting something wrong is high, especially if you are not aware of the limitations of technology and the shortcuts done by our human brain during interpretation. This, in fact, has been the focus of Amped Software’s Video Evidence Pitfalls blog series earlier this year.
Forensic video analysis is usually defined as “the scientific examination, comparison and/or evaluation of video in legal matters”. When we talk about forensic science, “science” should be the foundation, and “forensics” should build over it, not the other way around. When the opposite happens, there’s a risk of science being bent to the needs of a legal proceeding and the interest of one of the parties involved.
This is what has happened in the context of the Rittenhouse trial, where the process of image interpolation (especially the bicubic algorithm) has been put under the radar. While it’s right to evaluate the impact of various algorithms for evidentiary use, often the implication can be misunderstood by a non-technical audience, and sometimes even by a technical audience not specialized in video forensics.
IMAGE INTERPOLATION IS EVERYWHERE
Since image interpolation has been questioned, let’s dive into it. What is interpolation in a nutshell? Digital images have a given size in pixels. Whenever you need to display an image on a medium that has a different resolution in pixels (either lower or higher), you need to estimate the values of the pixels in positions that were not present in the original image. Additionally, you need interpolation for every kind of geometric transformation applied to an image, for example, when you are resizing it to zoom.
Bicubic is a standard algorithm that is implemented virtually everywhere, and it’s one of the most used ones. It’s not an AI-based algorithm that can add or remove objects, but it’s only a mathematical combination of nearby pixels.
Interpolation is everywhere and mostly out of our control. Where can we find it, for example?
- Taking a picture or video with any digital camera (during the demosaicing and image acquisition process).
- During video recording, every time digital stabilization is used.
- Playing a video in Windows Media Player, VLC, or any other software (interpolation is part of the decoding process, for example, as a consequence of chroma subsampling).
- Playing a video from the internet in your browser, either as a thumbnail or in full screen.
- Often during the rendering of the image on a TV, a computer monitor, a projector, or any other screen.
WE NEED INTERPOLATION TO SHOW THINGS AS THEY ARE
Videos captured from CCTV and other devices are often saved with the wrong aspect ratio or are affected by lens distortion. To show the actual proportions and shapes of an object, we need to correct them. Whatever process you use to adjust them, this involves interpolation. There is absolutely no way around that. Should we stick to curved walls and confuse SUVs with limousines because of this?
What if we stick to nearest-neighbor interpolation? Essentially, it means replicating the pixels and creating big square blocks. Is this more reliable than bicubic?
Remember that when we have a limited number of pixels in the part of interest within a photo, it is because of a process called sampling, which essentially drops information from the real world.
Sampling is almost always followed by a compression phase (and a lot of other processing) that essentially removes even more data and creates artifacts as a side effect. During post-processing, even without interpolating at all, or sticking to the nearest neighbor algorithm, there is no guarantee that what we see in the picture at the pixel level is an accurate representation of the scene.
We always recommend comparing the results obtained with different interpolation algorithms and with the original image. If we have to analyze something made by a very limited number of pixels, especially in a single frame, there may not be enough information to distinguish details whether there is interpolation or not.
Furthermore, the human eyes (and brain) do a lot of tricks that are out of our control. An experienced analyst knows how to limit these effects in order to state what a video does or doesn’t show.
PROPER IMAGE ENHANCEMENT GIVES YOU A MORE ACCURATE REPRESENTATION
Because of the limitations above, an image or video is an imperfect representation of the scene captured. With forensic image and video enhancement and restoration techniques, when done properly, we can provide a more faithful representation of the scene by reducing some defects introduced during the image generation process and amplifying details of interest.
Overly cautious analysts (or those who don’t have the adequate tools, experience, and preparation) may tell you not to enhance the image at all because they are afraid of getting questioned about it. The safest thing to do for them is just to play the video, if possible, and refrain from every possible attack. However, I think that the duty of a forensic video analyst is to do all that’s possible to help the trier of fact get the truth. Image science does not take a “side” in a case.
ENHANCEMENT WORKS, WHEN THERE IS SOMETHING TO ENHANCE
We can attenuate the defects of an image and amplify the information of interest, but we can only show better what’s already there. We can’t, and we must not attempt to, add new information to the image (as can potentially happen with AI techniques). A typical example is a white license plate made of 3 pixels; we’ll never be able to get anything from there, and whatever you could “believe” to read would be completely unreliable. The success of enhancement depends on the following factors:
- The technical characteristics of the image or video
- The purpose of the analysis (understanding the dynamics of an event is generally easier than identifying a person, for example)
- The technical preparation of the analyst
- The tools available for the analyst
To get some objective data, at the Amped User Day 2021, we asked our users how often they were having different levels of success with enhancement. The pie chart below summarizes the findings.
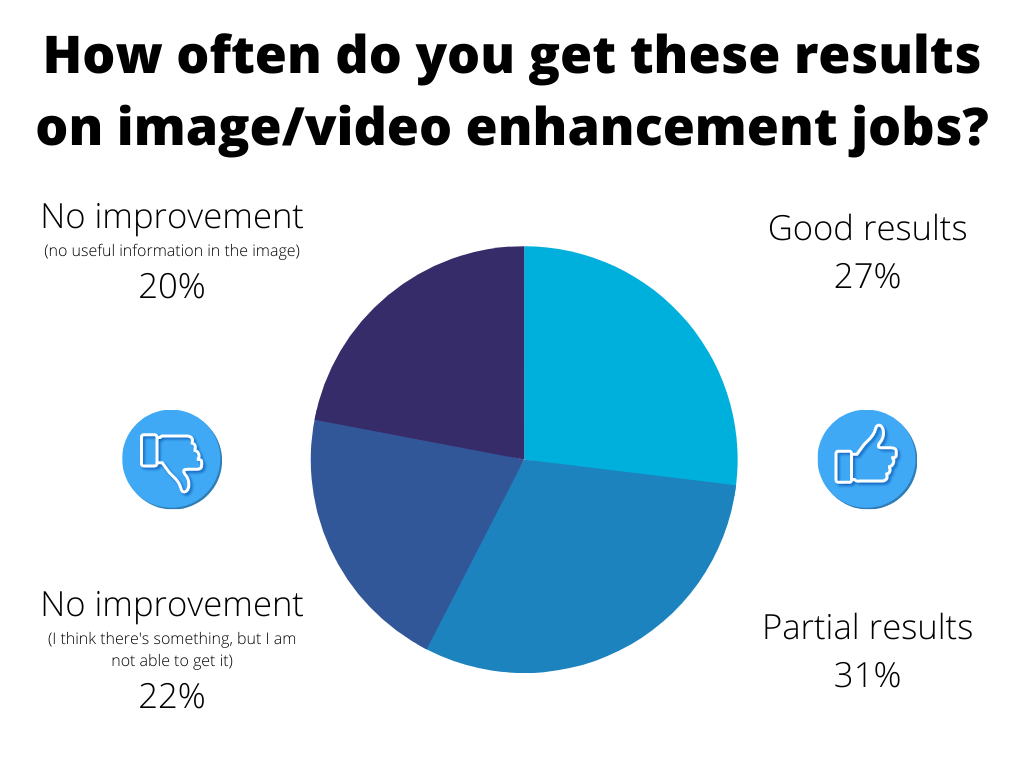
As it can be seen, according to our users, in almost 6 cases out of 10, the enhancement provides some form of benefit. When there’s no improvement, it could be either because of the lack of actual information in the image or because they weren’t able to get it. Often this situation can be improved with training or seeking the help of someone with more experience.
THE FOUR PRINCIPLES OF FORENSIC IMAGE AND VIDEO PROCESSING
There are just a few basic concepts to keep in mind, to properly process images and videos in a forensic context, around which we design our tools and teach our training.
- Have access to the original piece of evidence with a proper chain of custody and integrity verification (for example, with its hash code).
- Process and analyze the evidence with procedures that are reliable (as much as possible free from bias and errors) and accepted by the scientific community.
- Produce an output image or video.
- Produce a report that allows repeatability (by the same analyst) and reproducibility (by other analysts).
The same analyst, or an independent one with the appropriate preparation and tools, should be able to independently obtain an equivalent output image (3) from the input image (1), following the process (2) described in the report (4). All the procedures done and reported should be individually correct and applied in the right order.
It’s clear that you should arrive at the stand with all the evidence ready just to be played. There shouldn’t be the need to process or make calculations “on the fly”, and those that are asked to be done could be subject to acceptance or rejection. Even still, all your work should respect the same guidelines of reliability, repeatability, and reproducibility. Essentially it means accurately recording all the steps.
WE MUST SERVE JUSTICE, THROUGH SCIENCE
Anything can happen in a trial. Things can go down a bad path, and the prosecution or defense can be unprepared, or simply not play their cards well. Regardless of the circumstances, an expert witness must help the trier of fact with objective and reliable techniques based on science, not on opinions and tricks.
In addition to the remaining objective, one way experts can assist the courts is by helping to educate. The forensic video analyst can and should be able to assist with understanding what is happening within a given media, how a player can affect perception of that information, issues that may arise, and how to explain potential objections. In the US, the Scientific Working Group on Digital Evidence (SWGDE) recently published a paper designed to help bridge the gap between the attorney and the examiner.
Finally, the forensic video analyst must properly enhance images and videos to give a more accurate representation of the scene, compensating, when possible, for the imperfections introduced by the image generation process.
Image enhancement is a fundamental part of video forensics: this is the premise under which we created Amped FIVE, and this is why it has become widely accepted as the standard tool for forensic image and video analysis, being used in courts in 100 countries worldwide.





