
Holly: Hi everyone. My name is Holly Hagene, welcome to today’s webcast. We’ll get started in just a minute. First, a few reminders: all the lines have been muted to reduce background noise. We also encourage you to submit questions or counterpoints at any time through the webinar control panel. We will do our best to work those in throughout the discussion. This webcast is being recorded and will be posted along with a copy of the slides to Exterro’s website. We’ll also be sending you a link to those materials later today over email.
Today we’re excited to present the third webinar in our Masters of Digital Forensics webinars series. This series is an educational program focused on best practices for optimizing the digital forensic investigation process. There are five complementary courses in the series, and in today’s course, we will be diving into the analysis phase, part one. If you attend all five webinars, you’ll receive your Masters in Digital Forensics certificate at the end of the series.
This Masters of Digital Forensic series is brought to you by Exterro. Exterro is the leading provider of e-discovery and data privacy software, specifically designed for in-house legal privacy, and ITP at global 2000 and AmLaw 200 organizations. Exterro also recently acquired Access Data, the makers of FTK. By combining forces with Access Data, Exterro can now provide company government agencies, the law enforcement, law firms and legal service providers with the only solution available to address all legal GRC and visual investigation needs in one integrated platform. For more information, visit exterro.com.
Now I’d like to introduce our speaker today. We are happy to have Allan Buxton back as our speaker. Allan is the director of forensics at Secure Data. He is a former law enforcement forensic analysts, has provided expert witness testimony in both state and federal courts, holds multiple forensic certifications and is a former international instructor and course developer. With that, I’ll turn things over to you, Allan.

Allan: Thanks, Holly. And good afternoon or morning, depending on where you’re at. That’s enough about me. So let’s talk about low hanging fruit, which we can talk about, say, triage versus analysis. And I don’t know that this is going to categorize easily or neatly into the either one of those. You could use it in both situations. For me, when I talk about low hanging fruit, I’m talking about the types of data or bits of information that tell me that this is an item worth focusing my attention on. Not necessarily am I going to seize it, because I may very well have already seized it, but is this worth devoting resources to crawling through the whole drive, or building a full-text index, or loading it down with keywords? Because all those types of searches take time. I think in terms of size of information out there, your standard hard disk you buy off the shelf now is at least a terabyte. Solid state disc started…I don’t know anyone who buys a 256 gig anymore in a machine, it’s 512 or up, and all those things take time to parse. So if you’re dealing with one evidence item, or multiple evidence items, the question becomes what is the best use of my time?
If you’re a government agency, I’ll be amazed if you tell me you have no backlog. If you’re working on the corporate side, we’re talking about spending the client’s money…even if that’s just your employers. So trying to find bits of information, say, “this is where we’re best off focusing” is a huge bonus in my book. You can tell pretty quickly usually whether or not something’s worth your time, if you know something about the case, and that is one thing I will caveat straight upfront: this sort of information is contextual. You have to know what you’re looking for, what is expected in terms of the scenario being investigated and known details already. So low-hanging fruit are going to change based on the type of case you’re working in. We will go through some examples.
I do consider this an analysis step, because I’m a big believer of “when in doubt preserve”: it’s better to have more evidence items than less evidence items and preservation is arguably the least expensive in terms of time and analysis comparison, right? Storage is cheap. If you have a dedicated imaging platform, then it’s a matter of stacking stuff up. Even if it’s mobile, figuring out which devices to extract, rather than screwing with extracting, checking, extracting, checking, it’s just easier to grab them all and then work through them. So, because you can always say, look, “I didn’t need those evidence items, I didn’t need to look through those, we felt like we made our case”, or “we found the information we needed at a later date”. So no one really argues if you find what you have efficiently. The question is always, “well, isn’t there some that may be exculpatory or would argue a different side of the case?” You can say “sure”, but contextually, my goal is to find XYZ. Someone else’s goal might be to find the exculpatory information. So, low-hanging fruit is not a complete analysis. It is strictly a way of prioritizing where and how you’re going to focus your analysis.

First thing first: is there data? If you’ve taking your phones, and it boots up to a new user screen, the odds are good it’s been reset, so probably no data to look at. Likewise with the hard disc, or a solid state disc. If I’m looking very quickly at a file system (and I am using X-Ways for this, because X-Ways parses the file system quickly without having to pre-process of boatload of stuff) they’ll tell me, are there deleted file system markers, right? Are the first clusters reassigned? In the first screen capture, you will see that…the “first cluster not available” means that that cluster is being used by another file. So the contents are probably overwritten, right? If we look at a couple of others, it says data unchanged, there are previously existing, and tells me there’s data there that may still correspond to those files. So maybe I’m not dealing with a wiping situation.
Now in the second screen cap on this, we’re looking at free space on the drive. All starting zeros is not a good sign, especially if it’s a solid state disc. We have a good guess garbage collection has taken place, or someone has taken a few steps to wipe the drive. So easiest step first, do I have data to look at? Not a hard one, by all means, a very fast one, depending on the tool you use. This is the kind of thing I would argue for using triage mode in something like FTK, as opposed to building the index right off the bat and doing all the parsing, because you’ll know real fast, if that’s even worth doing.
And then example-wise, we talk about the context. Pictures or video case types. And then if you’re in law enforcement, you know exactly what I’m talking about. If you’re not law enforcement, understand that there are cases where pictures or video or your most damning kind of evidence. So if you’re looking for a producer, even if it’s like a hidden camera case, look for a large file sizes for video, or B proprietary file types, right? If they’re working with a specific set of cameras, it’s easy enough to hit the support forum and see what types of camera formats are used. I listed a few here. If you’re using the RAW formats, which is your highest picture quality in most situations, Canon still uses a CR2 extension, Nikon uses in NEF, Sony uses an ARW.
What I will call your attention to in the screen capture though, is the directory content: directory names can also be indicative. If you, if you’re dealing with a GoPro, almost all your video is in a folder labeled 100, 101, 102 GoPro. Nikon D750, the camera models are generally dependent on the directory. Those kinds of things are global. That tells you that you’re dealing with someone who does have access to video or camera systems. And so maybe we have something to look at.
If we’re talking mobile, those of you who own an Android phone or have worked with a Pixel before, we’ll see that the camera app shows the PXL prefix, and then the day/time of the image capture. That’s good info to have, right? PXL_20210826 etc. And that not only gives me a day/timeframe for when the device was last in use, but tells me that I’m dealing with someone using a mobile camera. So, these are very fast things you can flip through in a file system display, or even in a recursive explorer. So they’re not bad to go looking for. I mean…straight up, even if you’re dealing with the hidden camera stuff people buy on Amazon, they almost always have a prefix appended as a directory structure. So pulling down a manual for the evidence item in front of you, can very well tell you where to go looking for those types of files.
The other thing I look for, that I have highlighted in the screen capture, is the overly generic file name. Like…old joke in the industry is that anyone who’s got a folder labeled “stuff” is hiding something in it, because the name is so boring, that no one feels compelled to go looking! So I threw that in there as just a reminder that an overly generic name, like…we know our defaults: documents, pictures, and video, desktop…all of those exist. So if someone’s gone ahead and conned the links to make a folder even more boring than those names, maybe it’s worth poking around in, just to see what you have.

If we’re dealing with a disseminator or recipient, you may very well find names consistent with the transfer. If you’re looking at the right, that is a screen capture of my first birdie putt of the summer. And if you’ve ever gone golfing with me, it may very well be my last birdie part of the summer. But the arrow there will show you that that file is named 20210820_193040, which is a date/time stamp. But it didn’t originate from my camera. My camera doesn’t create that file naming convention, it’s indicative of a transfer via data. So I go looking for pictures or video that have names consistent with – or prefixes consistent with – a transfer. You know, a lot of older phones still will use an MMS prefix for a file saved from an MMS text message. If you’re looking at Facebook Messenger, everything’s prefixed with FB_IMG. Others will just have an IMG_ for other types of camera or transfer apps. So very quickly…if you pull an SD card or you do already have a phone extraction to go through, and you’re like, “where’s the smoke, where’s the fire?” Start here! Transfers are usually compressed, so you won’t have the massive file sizes you might with a RAW image or a full-sized JPEG taken by a camera, or a 4K video taken by a GoPro or whatever. But you will definitely have a prefix or a file name indicative of that transfer..
And then again, directories are consistent with known tools, right? For transfers. (I think I’ve got a screen…I had a screencap coming up. It doesn’t look like it’s here at the moment.) But you know, if you’re dealing with any of the download links from peer-to-peer, they all have an app, they all have a folder, received files. Shareaza, any of those, will very much have some sort of directory structure. So if you’re dealing with even like One Drive or Dropbox cloud transfers, those directories jump right out at you. So they’re not hard to go looking for real quick with just a quick directory parse. Show me what’s there inside program files, show me what’s in my user directories: all that good stuff. And you will very much see that you are rolling along with, “do I have things that may have been transferred?”

Moving on: stalking and harassment. There is no good anonymized GPS location data. So you have a creative commons location screen cap for this. So stalking and harassment location data…sometimes what I’ll do is I’ll take their location data, map it all out, but then I’ll just tack on one waypoint for my victim, right? Address for home, address for work, and see where it falls inside all of their location data. Because if you’re stalking or harassing them, sooner or later there’s gotta be an overlap. Now, if your suspect works with them, that’s a little less incriminating than maybe we would hope for. But if they don’t work with them, or if it’s someone they no longer have a reason to associate with (maybe they’ve been fired, maybe there’s a restraining order in place) the date/time stamps, that location data could very well come into play. Now, most of the time, this is often mobile. So we do have to parse the mobile device to get this. So it could be a little faster than digging around for SMS, MMS or any kind of messaging apps. It may not be faster. But it is a quick way to see if you’re dealing with physical interaction. You may also get this kind of information from call detail records, if you’ve got the probable cause to build that up. So there’s an option there. I did highlight also browsing history because people tend to look up addresses, they tend to look up locations, especially if they’re stalking or scouting someplace out.
In terms of other things on mobile, right. Does their name even exist in the contact entries? Does it exist as an address, as a phone number, as an email address? None of this is rocket science, but it may very well save you from keyword searching and waiting for the returns on a full analysis of that device. So, it’s just tricky. You got to tailor it to what you’re dealing with. If they’re sending threats, or if they’re faking being the recipient of threats, sometimes the data here will tell you where that information is coming from. A little faster than possibly reading through all the messages to say, “look, do they have some interaction? Or does this match what’s been reported?”
So misbehaving employees would either call soon to be ex employees, or possibly ex employees already. The first thing we want to tell you is when in doubt, pull the browsing history. If they’re goofing off at work, they’re probably in a browser. If they’re in incognito mode, we got to go a little deeper, we’re talking full analysis. But what I want to draw your attention to in the screenshot is the search?q=. Pretty much every search engine artifact out there has a ?q= in it followed by the phrase they’re searching for.
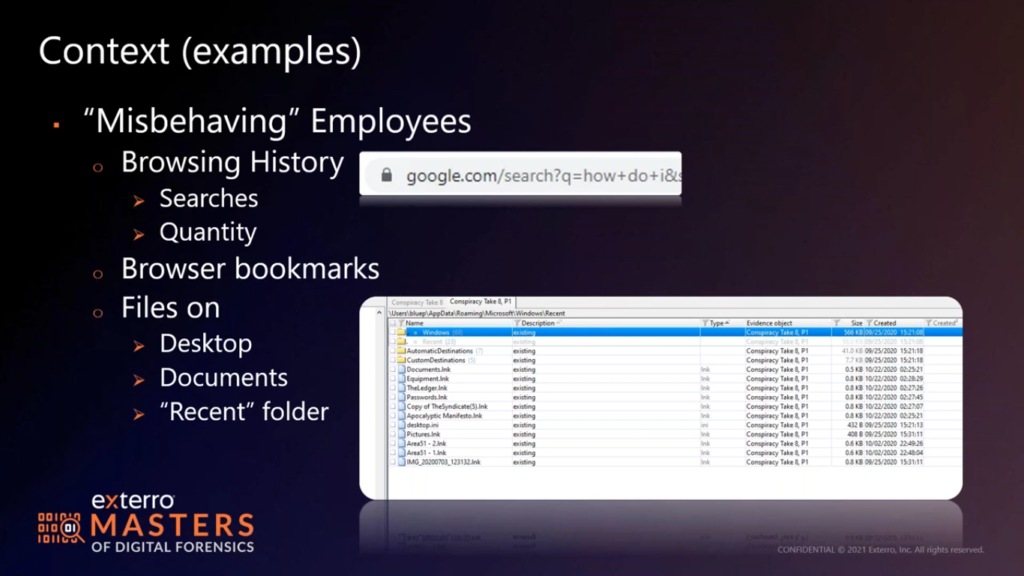
So if you just pull places.sqlite. (I honestly think SQLite is the one that won the browser wars, as far as history, right? I don’t think there’s a modern browser that isn’t using a SQLite database.) You don’t even have to pull the dates and times. Pull your table for places visited, and then just do a filter for ?q=, see what’s there for searches, and then start working backwards. If they’re looking “how do I delete my records?” “How do I copy stuff?” “How do I quit a job?” Or if they’re searching for new jobs, you’ll see a search engine for jobs in your area, jobs that match their experiences, or maybe they did not match the experience levels. You’ll see all of that real quick, just by checking what they’ve searched for. And by pulling the database and just checking it quickly, you don’t have to wait on all the parsing and returns.
Now you do have to be comfortable with the manual tool, right? But SQLite is not a complex beast as far as browsing and exploring. Things like DB browser or…there’s a million different SQLite browsing parsing tools out there. There’s a million scripts for pulling history. So, you can do that very quickly with just a couple of right click file copy out, and then load in tool to see what’s there. You don’t have to wait on a full parse. Quantity events, history entries will give you some idea as well. Are they deleting entries or they’re using incognito mode because there’s just not much there? In some of that’s going to come into their job functions. If you’ve got someone whose job is to work with a lot of web interaction, you’ll see…you should see more quantity, not less. What you’ll see though, are types of sites, names of domains that tie into what’s work appropriate. If that job runs their own series of web apps, you should see that URL over and over and over, right? So maybe we filter that one out and then work our way backwards as to what’s left. If you’re not seeing it over and over and over, how much work is actually getting done?
Likewise with bookmarks. Bookmarks can tell you what their interests are, what their interests should be and everything in between. I don’t know how many people link their personal browsing bookmarks to their work profile, or if they load a second profile on a work machine anymore. Seems like most people keep that on mobile now, but the work profile alone should give you some idea of what’s going on. If they’re spending all their time on their phone, how many records do you expect to see on their machine? Probably not as many as you would hope.
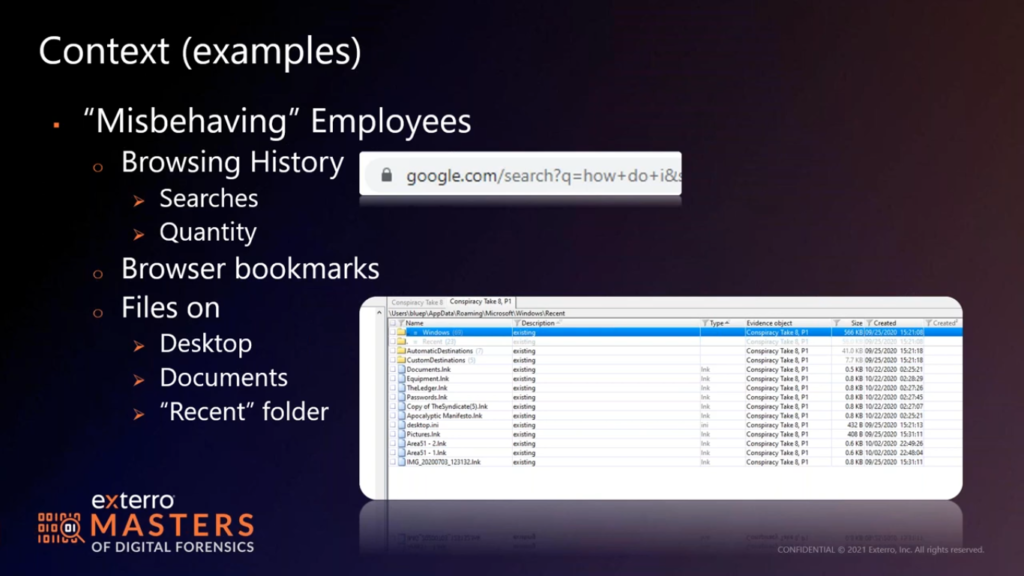
Same thing with the files on the desktop or documents. I like to ask, do they have a network share for storing files? Do they use a Google Drive in the cloud age? Do they use One Drive? Where should I expect to see their work product for an employee investigation? Counsel or the HR or their supervisor will tell you where they expect to see files, maybe it’s just back and forth and email and the local disk, they don’t have any redundancy policies in place. That happens.
And if that’s the case, that’s a goldmine for me, because that machine will tell me everything I need to know. If their data is elsewhere, I still check the recents. Where are they accessing those files? If I only have, like, in this screenshot, 10 or 12 link files, how many files are they really pushing through in any given day? I should see hundreds, if not allocated and certainly erased old file markers as they get updated and moved around. And this is just browsing through these folders is faster than parsing all my jump lists and back files. Certainly I’m going to do that to paint a picture, to really dig in deep as to what’s going on, but I’m not going to spend a lot of time doing that if it’s painfully obvious that this disc either has had those records purged and wiped, or was never configured to keep them to begin with.
How many people keep a clean desktop anymore? I get a little ridiculed because I…computer and recycle bin are the only thing on my desktop, unless I’m working on it in that moment, and then it gets moved into my storage hierarchy. So I get a little PTSD when I sit down in front of a machine that has a couple hundred icons spread across two or three screens. But that’s a person who’s generating and creating files and content. Likewise, in the documents folder, which is where you’ll find most of my stuff that hasn’t been backed up to a network share, you’ll see hundreds, if not thousands of files or files that have been erased as they’ve been updated and moved. You should see revision history as things go from draft one to draft five or six or final.

All of that, those directories will tell a very fast tale. Quantity alone will give you some idea, file name transitions will give you another. So again, in terms of browsing through folders, very quickly, can I work through my user accounts. It’s not hard. I can take a quick assessment. Is there stuff here? Is there not stuff here? More importantly, in terms of recents, where do these links point to? Something to think about there as well is that those link targets will either point to this machine, or a removable drive or a network drive. So if you’re worried about data exfiltration (which might be our next slide) checking those recent files, and then maybe digging into the jump list and whatnot are all options for checking targets.
I like to still pull the registry, see how many storage devices I have floating around. If we look at this one, we see a great many USB devices have been connected at some point in the past. So now it’s a question of what’s your USB device policy? Have you issued any? Would that be irregular use? Which of these might be IT functions or left over from data loads? All those questions come into play. The only thing we don’t see any more that people tend to overlook is that this one has a DVD drive in it, that’s capable of burning disks. How many people have had data dumped on a disk anymore? Everybody sneers if you hand them a blank DVD, but something to consider is maybe I need to go looking at other artifacts along that route.
I mentioned cloud uploads earlier. Clearly the browser URLs are of interest there if there’s no application loaded, but what we’re seeing more and more is, there’s always at least one application loaded. If you’re in the Windows world, it’s One Drive, if you’re in the Apple world, it’s iCloud. And the push is to use those services. A lot of corporate environment…the cloud sites enable a lot of collaboration, especially in the last year and a half. So when…it’s just faster and easier to roll out a cloud deployment of some sort than it is to build resources when no one’s allowed in the office, or there’s only two guys permitted to work on the infrastructure at any given time…then you got a VPN.
I mean, I don’t know, I would…if we were all in a room, I’d say, raise your hand If you didn’t roll out some sort of cloud cloud management or document sharing solution in the last year and a half. And I would be surprised if there weren’t quite a few hands raised. So we go looking, right? We’ve got to go looking in the applications folder to see what’s installed, check the app data folder, check the program data folder, check the program files folder in the Windows world. And and see what’s there, and more importantly, what may have used to have been there.. It’s not uncommon for people to remove an application thinking it covers all their bases, but I think we both know that…the LocalLow and the app data has a way of hanging around just in case the programs are reinstalled.
Sometimes program data does as well. Program files tends to go away, but occasionally program data is left behind in case the app is reinstalled as well. So we can find some artifacts very quickly. And the second screenshot here, you’ll see some of that app data stuff floating around, and here we have Dropbox, we know the app was at least installed at some point in time. We also have some peer to peer apps, right? eMule, Shareaza, there’s a Google folder, might very well just be a browser. Could also be Google drive. I would expect to see some One Drive settings. I don’t know if I would expect to see some One Drive data without digging deep into the Microsoft settings. But a quick run through here will give me an idea of what I may have seen in programs that wasn’t there now, or what would have been previously allocated.
So again, all I’m really talking about here is hitting the directory view. Maybe in the case of the registry, I’m pulling three files: system, software and SAM. Why am I pulling SAM? I’m not busting passwords, I don’t have time for it. What I am doing is seeing if the accounts listed in SAM match the accounts listed in my user’s hierarchy. There’s probably a service account that has never been logged into and that’s easily identified. But if I have, say, two local accounts on a box, and I have three or four accounts, I would expect those three or four…those other two accounts to be domain accounts of some sort, or why is there a disparity all of a sudden? Do I need to go looking for an older version of the registry files? Am I dealing with deleted accounts? With account data left behind? Am I dealing with cached accounts from a reuse? Generally, if you have your suspect on the machine, you have a good idea of what account is theirs. So is their account even present? And again, in the last year and a half more and more it’s local accounts because VPNs and domains don’t always play nice. Or it’s BYOD, since you’re working from home. So local accounts are still of interest to me in terms of pulling the SAM. Software hives tell me what programs are there also. So…and then maybe what some settings are. I can tell from software, if there was a One Drive account loaded and configured for use. Likewise with Dropbox or a few of the others. So, if there is an active cloud account, I’m very much in business, just digging around that way.

So something to think about here is sometimes all you have to do to assess something is have good access to the folder structure and the types of files…easily viewed types of files. In this case, three or four registry files or recent location, or their equivalents on Mac. Which would be normally hidden under the user’s home folder and then library. Safari uses a SQLite database too. USB devices are logged in their debug files. So, Mac is not…panic on the Mac side is not necessarily appropriate. What’s the bigger issue with Macs now, is if it’s been built in the last two, two and a half years deleted data’s not an option, right? T2 max, the M1 Mac, all of those automatically discard file-based keys as files are erased, so there’s no getting anything back from an allocated space. So all you have is what you see in front of you.
In which case what’s missing becomes a little more important. If I do not have a user’s home folder, or if I don’t even see an account that matches what I’m being told they should have been using, now we have a big concern. Do I focus resources on that device? Probably not. I know I’m not going to get any more than what’s there, and all I can do is quantify what’s there now. Now you can write 30 pages about what I should anticipate seeing or what should be there, if that were the case, but what should and what is comes in the tampering when you can prove a case, when you have a case to prove.
So I am probably moving on from a device, in the last two and a half years on a Mac that I cannot get deleted data back from. It’s abundantly clear to me that there is no data to review. It’s an unfortunate truth right now. We don’t have to start the Apple hates investigators talk because I don’t know that it’s appropriate. But the truth of the matter is that if you’re dealing with a Mac, even the luckiest can catch a real break by deleting their data. Someday, maybe we’ll like Macs again…maybe.
And then mobile: there’s always a lot of questions about mobile, which is kind of where I’m at until we get questions. I put a tiny old phone up here for one reason alone, and that’s that last bullet point. The temptation is always to look through the phone rather than waste the time with the extraction and parsing, because most tools are designed to extract everything and then parse everything. And if you’ve ever tried to run the extraction wizard with the 17 different options and the different security options and patches that might enable which one works, you can spend hours on one device. So the temptation is “let’s just look and see if this is worth doing”.

If you couldn’t tell from the golf shot, I don’t have hands sized for mobile. And these are the size phones I started with, and about the third time you inadvertently hit draft or create…going through text messages, or you take a picture of your hand as it covers half the camera, and you’re stuck writing a memo or adding two reports that the last picture on the camera extraction is yours because you inadvertently pressed the button, you’re kind of done with it. Now, smartphones don’t actually even have buttons, they just have a screen and somehow the screens have gotten larger, but the buttons still don’t fit my hands. So for me, even with a Stylus, I will avoid hand parsing a device because when I’m doing that, I’m creating records.
And any phone extraction where the phone remains functional, we’re creating a little bit of data. We’re either loading a client on the device, leaving the client on the device, or removing the client after the extraction. We’re changing settings, even temporarily, then we’re changing them back. We’re making a series of controlled changes. And for me, I want to keep that control at the minimum. I want to say “these are the changes I made to extract information, and then I want to get out of it.” I do not want to get in the spot where I’m like, “well, before I did all that, I went ahead and took a look to see if this is the first phone I should start with.” It just doesn’t work for me.
Tools are slowly evolving. There’s starting to be some options. There’s always been some options for limited extraction of either what’s supported or what’s desired, skipping pictures and video. If you’re strictly dealing with SMS, MMS…is occasionally an option. I tend not to because of MMS moves pictures and video, but do I need ringtones? No. I don’t think I’ve worked a case yet where a ringtone is incriminating. Although I’m sure someone’s got that story, and I will buy you a drink if we ever meet up, you have a chance to convince me it’s true! Do I need contacts? Almost always. Do I need every app on the device? Probably not. Like, there’s a lot of apps that just don’t tell a story.
So I may streamline an extraction based on what I know about the case. I may want to go back and re-extract that as things change. For me, it’s just easier to pull all that data. There’s not a lot of low hanging fruit to be had in a phone until you’ve done your extraction and run your parse. So I don’t do a lot of limited analysis on phones, unless that’s all the analysis I have in front of me. Just kind of the way things shake out.
So, we talk about infotainment systems, in vehicles: do you rip the dash apart and do the full extraction or do you push the buttons and see what’s there? Now that’s an 8 inch, 12 inch touch screen, so it’s a little easier to look at that information, so I might be a little more bold and dig through what’s cached as far as contacts or SMS. But if something’s read or unread (I guess I should say if something’s read) I don’t want to flag it as read, I’d rather extract the data in its unread status than try to explain that I moved that data to read prior to extraction. So I’m even very careful with infotainment devices. It’s just easier to say “this is the data I’ve found, these are the steps I took to preserve that data”, than it is to say, “I made a call to change some data, to find out if it was worth doing some data.” Now you may be in a different spot on that. That’s why all this is contextual and largely a judgment call. It’s not the end of the world, we can agree to disagree on some of that. It really comes down to how you articulate it later. For me, I tend to go back to preservation.
I think…let’s see, we got PCs, Mac…Mac prior to M1 T2: very useful. If you had the firewall keys or…I still see Macs that don’t have this encryption enabled so those are very informative. Everything we’ve talked about with PC translates for the most part over to the Mac side of life on that front, if you can get that far. So, buyer beware, I guess, on which version of Mac you have. I do tend to run every…yes, color codes, gunmetal Mac versus silver Mac versus brushed steel Mac versus plastic Mac. But I do tend to avoid assuming I know what model Mac that is from the color or from the shape of it. I will check every serial number and I will run every model number and look at which options are available before I start with those.
Having said that, let’s…any questions? I don’t feel like I flew through that, but it certainly ended a little quick. So if you have some questions, let’s run them.
Holly: Yeah, if you have something to ask, please post your question in the question box and we can go ahead and answer those. Have you had any instances where you’ve had to extract from smart refrigerators or anything like that? What kind of information do you get from that?
Allan: So interesting things, smart fridges, smart TVs: largely Android based or Linux based, custom kernel. So you get account names, you can get a lot of information about usage of viewing…if we talk about a smart fridge, we’re not quite at the stage of the game where it’ll tell me how many times the door has been opened and when the milk’s been removed. But that’s really where they’re trying to get to. Most of the time it’s what accounts loaded on the box? Which apps have been run. A lot of people like to stream music from their fridge…and more power to them. I guess I don’t quite see the benefit personally, but you can get patterns. If someone says they’re in the kitchen doing things then the fridge becomes in the play as confirming or debunking an alibi. Otherwise it’s not super useful.
The smart TV is great because it will tell you viewing patterns, it will tell you what apps have been launched, and it gives you a whole slew of accounts. So if you’re really struggling for email IDs or account names, or even handles for individuals, sometimes those places are better places to look because they tend to overlook them. I’ve worked a lot of cases where people have reset their laptops, reset their phone, and haven’t touched a single bit of their smart speakers or tablets. And you can get IDs off of all of that to start building that paper trail back. So, a lot of that stuff syncs to the clouds, so you’re dealing with a lot of court orders to get that information. But there’s some good info there. I liked the IoT stuff for building patterns of being home or not being home. And like even the video doorbells can give you an idea of what the traffic is around the house or outside the house.
Holly: Okay. This might be a similar question: how would you extract data from an Alexa or Google home systems like that?
Allan: All right. So when we’re dealing with the actual devices, it’s going to be chip subtraction, most likely. I haven’t seen a whole lot with ISB ports still intact, or they’ve been so small that you’re better off removing the chip. But it would be chip subtraction. I’ve done some smart speakers. I haven’t looked at a Google home controller, but I’ve looked at similar style home controllers, and they contain logs for what devices are talking, what modes have been engaged, what sensors have been tripped or what things have moved in and around on the smart home.
So, even a schedule, like a pattern, helps sometimes. If the lights are all set to go off at 11:30 at night, or if they have a very advanced house where they can control their locks, or tie them to the doorbell, you can build a pattern of activity from that sort of information. It’s a lot of manual decoding. Some of it’s SQLite databases, some of it is just raw text log entries. So timelining becomes a very manual process. But it’s very informative for telling you about the actions of the people around.
I haven’t dealt with a very, very heavily integrated smart home yet where they’re controlling the TV and the speakers and the lights and the locks and the doorbells. But largely because I don’t think we really hit full integration on that stage, unless you’re a real power user. But I love to build a pattern of activity. What’s a normal day? And the patterns in those smart home controllers tell you what they expect their day to be. This is when I get home. Or is it when my phone hits the driveway that the lights start warming up?
That sort of thing…a lot of smart home thermostats will bring the temperature of a house back up or back down, depending on the climate, within an hour of people usually coming home. All of that gives you a pattern. So if you’re dealing with a missing person, you know what they may have been…what they expect their day to be and what their day has been in the past, I should say, as a pattern goes. So what days are anomalies? What day did their phone ID, their Bluetooth ID, their wifi Mac address, not trigger the, “I am home” function. Those are the kinds of things those devices can tell you. Is that low hanging fruit? Probably not. You’re doing a deep dive to get that information. You got to put some resources into it, but it’s well worth doing if it fits the context of your case.
Holly: Any additional advice on Macs?
Allan: Man. Additional advice on Macs? I guess, for right now, the best advice is: make zero assumptions about what preservation tool or what analysis tool is going to work for you. Yes, Macs are really good about forcing updates out for the same OS version. But you’re in a world where there’s potentially three different platforms floating around, sometimes four, in terms of processor architecture, and what those features were enabled. And then also they have an amazing amount of controls for how to safeguard that. If you’ve got an M1 Mac, you have integrated storage, you have a full disk encryption, based on file on file. And if they’ve taken the time to set the recovery options to be locked to a password, there’s not a tool out there that’s going to let you do anything with that, much less log into the desktop and build a logical acquisition.
So for me, I always check the model number. I always check the serial number, and I do a deep dive as to which version of the Mac that is. And then I start slow. Can I boot the Mac to the recovery console? Will it load target disc mode? I.e. do I have a chance at making any form of preservation? Because even a preservation of an encrypted disc, I don’t have the code for. May be useful in the future.
And then it becomes, can I get a logical acquisition? You know, if it’s old enough and I have the firewall password of people are cooperating, can I build a decrypted version of the disc? Great. Can I log in and build a logical acquisition? Even if it’s a limited one. Am I limited to just my user account and what it has permission to do? Can I escalate that privilege to the whole drive by taking ownership? All of those are options that are incredibly controlled on a system where those exploits aren’t there, and the exploits that do exist don’t necessarily help you with getting raw access to information.
So Macs…proceed slowly with a Mac. Yes, the pressure’s on for results sometimes. But bear in mind that, even with full disk encryption (if it’s solid state) you still have all your maintenance functions running. So wear leveling, garbage collection, come into play as well. And while that may not affect the allocated information, it could affect things like your virtual swap file or your hibernation file, where data isn’t expected to reside and the controller is well aware of that, that that data is not necessarily going to be used more than once. So yeah, I would say go very slowly with most Macs, and especially in a situation where you do not have a good log on and password, or you have steps taken to protect the storage beyond the desktop login.
Holly: Okay. Do you have a worksheet for your workflows of the choices you make for your cases? For example, start with A, branch to B or C depending on what you find, etc.
Allan: I build a new one in my mind for every case. I have charted them out before, and it’s certainly something that is an option as far as flow, but I guess my response to that would be, when is a forensic analysis finished? There’s a lot of jaded answers to that, there’s a lot of philosophical answers to that. Is it finished when the client runs out of money? Is it finished when your boss tells you he has to have a report by 5pm the next day? And the simple answer is though it’s finished when you’ve exhausted all your questions. If we go back to: is there data on the device? The next question would be is any of that data pertinent or informative as to the scenario being investigated? That’s our contextual categorizing of that information.

Once I go through that (not just low hanging fruit, but a deep dive on analysis) the question becomes: is there other information on the disc or the device in front of me that would make me doubt my findings? I.e. are there wiping tools? Is there malware that may permit remote access or be suggestive of another user? Is there even date/time stamps that call into question the integrity of the data as I see it on the box, and can I reconcile that information?
So I’m doing my own mini cross-examination as the third phase of my exam. And then the fourth step then is: are there other avenues to examine? Are there court records or subpoenas that need to go out, or are there other devices to examine? And then once I’ve worked through all that, or if those are not options (if it’s strictly, yes, there are, but no they’re not available or no one’s going to do it or the timeframe doesn’t permit it) then my exam is done, right? Like I’m ready to quantify all of that information into a report.
But in terms of a flow chart, that tends to branch the changes with what you see in front of it. If we start with, say, like this screenshot here of a C drive that has some allocated files, some overwritten files, some files are not overwritten, then where do I go from there? I’m dealing with a Windows box. So maybe my next check is: what version of Windows? The reality of it is though my next check is probably: who are the user accounts and do any of them match my suspect? And if I don’t have that, then it branches again. And so your flow chart could be 300 boxes very quickly, and it’s just things you’re eliminating. So, do I have a flow chart? Kind of. Do I have it committed to paper? No. Could I work one up? I could, but I don’t know if you’d be satisfied with it the third time you used it, if that makes sense.
Holly: Can you speak to retrieving low hanging fruit from Linux system?
Allan: Low hanging fruit from Linux? Yeah. So Linux, you know…var/log tells you a lot about the behavior of the device. (I should have put some Linux slides in here. I apologize. Wasn’t thinking about it at the time, and that’s on me.) Var/log is usually my go-to for: is the device functioning normally? Or are there things not not appropriate in terms of hardware errors or even user fail authentication, because Apache logs are in var/log, buried deep in there. And what I will do, I will not use a forensics tool to do those, because all the forensics tools is going to give you is usually a text output (which I do not have a screen cap of anything along those lines).
What I will do, is take those logs and move them into a commercial log aggregator, something like Splunk, which is designed to ingest those logs and build a timeline and let me search it as individual entries. It’ll do the same thing with Windows event logs, but I start there. Obviously the user’s home folder, you know, also very informative. Bin, sbin for executables, USR, all of those, right? I’ll take a look at mount points. And depending on the flavor of Linux, it could be under mount, it could be under media. It’s largely the same locations for the same types of data, but you also have to remember that in Linux, most people will jump into the command prompt, and at best your log may have 30 or 40 entries. So if they’re desktop user, if they’re using the browser, using apps that are designed to work off of a GUI, you can start pulling that apart in the same way we’ve pulled apart Windows or Mac. Does that help?
Holly: Perfect. We have a few more questions. So what is your process on selecting tools for analysis? Do you have a standard set that you use?
Allan: So I’m a picky guy, right? Like most of the screenshots you see here are X-Ways because X-Ways works very quick. If I load a disc, it parses the partitions…as I load a partition it’ll parse the file system in that partition, if there is one, and then it stops. So unless it’s a corrupt partition or a corrupt file system, I’m usually looking at my data (be that a live disc on a write blocker, or a logical preview, or an image file) I’m usually looking at data within 10 minutes of starting the tool. I don’t have much metadata to configure for it. And then for me, the other thing I want to see is…I want raw access to information. I want to see the hex. If it’s good news or bad news, I want to see it because…even things like zip files that aren’t recoverable, or non-intact, if you’re looking at the first four or five clusters of that zip file, there’ll be a listing of files that used to be inside it still.
Even data that the tool knows isn’t necessarily useful, can be useful in the right situations. So I have a whole stack of tools, always evaluating new tools. In terms of criteria, I really want to know what the tool is designed to handle. What file systems, what disc structures, what media types is it designed to handle? I want to know what file systems are supported? Does it have built-in processing? And if so, what artifacts? If it’s a Windows specific tool, does it run Windows 10, Windows 7, Windows 8? Does it go back to Windows 98 and Windows XP? Because we still see some old data, or I might be dealing with a virtual machine…can I use one tool for?
More importantly, how does it handle errors? If it’s an imaging tool, do I want to list the bad sectors? Absolutely. Do I want to know how it pads those sectors? Yes. More and more recently, and I touched on this briefly in the imaging thing is: do I want to be able to control how it pads those sectors? And my answer is yes, because if you’re dealing with garbage collection, on a solid state disc, it’s either all zeros or all Fs, depending on the age of the chip. All zeros is kind of the default padding for most imaging tools. Can I change that to something where I know that that is padding from my tool and not zeros from something the user has done? Like a wiping tool, or the disc has done with garbage collection, wear leveling. So that’s kind of one of my newer criteria. I do want to know how it handles errors, if there’s a tool that can’t parse…if it crashes consistently, or if it defaults to a preview where it tries to parse it, as opposed to maybe hex view, I’m going to want to be able to change that setting. Because default hex view is the fastest way to look at data, and then I’ll figure out if it’s valid.
And then how long does it take to work with information? The full-text index has its place in this world, still. Email parsing has its place in the world. Every tool can be a good tool in the right situation. With mobile it’s: how up-to-date are the extraction engines? How good is the parsing? What parsing does it do? And what options does it have for me to work in the tool – A – to parse stuff it doesn’t do automatically – or B – move data outside of that tool so that I can work with it in something else, or manually decode it. I’m not big on vendor lock-in formats. So, if you’ve got a format that is like, “well, it’s proprietary only it works with our tool and tools that have licensed that format”, I’m probably gonna pass on that to something that works universally. I want to be able to move data between tools or into a place where I can work with it myself, if I need to.
That’s in a nutshell, that’s my flow chart for evaluating a tool: what does it do? What does it do better than some other tools? What does it do maybe not as good as their tools? Because you want to know your tools limitations also. It’s one thing to know what it does well, it’s another thing to know what it’s not doing well, so that when you encounter that, you know to go to another tool. I want a tool that tells me, “I don’t know what’s going on right now”.
The dialog box in X-Ways can be really annoying some days when you’re dealing with corrupt file system, because it pops up constantly. But that feedback tells me that I need to consider another tool or I need to make a change. Maybe it’s time to create a copy of the image, mount it and run a check disc, or something, and correct some of those file system errors so that other tools parse it well. And I’m working off a copy, so I can do that. Maybe I just want to document the errors. It kind of depends on where those errors are occurring. If they’re occurring in files I want to review, I will take those steps, but I need to know that it’s having a problem parsing that data.
So I like a tool that gives me feedback as to how it’s working also without having to go digging through a bunch of logs. FTK’sindexing engine will create a huge log of problems, and it’ll populate that dialog box, and that’s great because it tells me what file formats I should not expect to be able to review in that as it builds. So there’s two tools that I know what they do well, and I know what they don’t do well. I’m not looking for one size fits all, I’m looking for tools that solve problems. So if I know a problem is out there, I can go to another tool that will address that particular issue.
Holly: Alright. What is a good technique or tool to handle iPhone acquisition?
Allan: Man! So iTunes backup, right? It’s still a thing, until Apple says it’s done again. I do use the Cellebrite UFED extraction wizard. I’ve used Magnet’s AXIOM wizard, I’ve used iTunes. Whatever is available is available. So there are some other limited subsets…I’m not big on jailbreaking phones, if they’re not already jailbroken. If it comes to me jailbroken, that’s one thing. If I have to escalate something, I will explain to the client what the risks are involved or what changes are taking place and we can work through it. But I will take just about every iTunes backup engine out there. Even some data recovery one-offs that’ll create an iTunes-like backup. I’ll use them all if I’m looking for different types of data or I think I’m not getting good data with the tool I have. It’s not uncommon to use a couple tools, but again, Apple really controls what data you can get off those devices now. So it’s almost dealer’s choice until you have a problem or an error with the extraction you’re using.
Holly: How do you extract data from a Google Chromebook?
Allan: Oh, man, that is a tough one! There is a series of steps out there for pulling data off of a Chromebook. And I want to say that Magnet put out a plugin that lets you work with it. You have to be able to log into the Chromebook as a user. So it’s no different than basically performing a logical acquisition from an M1 Mac. There’s a series of steps out there. I’m pretty sure Magnet is the one who built it into a tool of their own as well. Accrediting the original author whose name escapes me at the moment as well. But Chromebooks are tricky. When I get Chromebooks, I usually do not get a login name and password. It’s either been abandoned by the user, or maybe an ex-employee, or they know very well that they’re required to turn it over, but “I forgot my password” is the name of the game. So Chromebooks are tricky and can be every bit as frustrating as Apple devices.
Holly: Okay. This might be related to something you said before. Could you obtain the information the system overheard since the systems are in passive listening mode? Assuming that’s regarding Alexa.
Allan: Sure. I actually just did this on a device. And honestly it’s better to do it from the Amazon plugin and a cloud host than it is from the device. Because the device is only going to have the last thing you recorded, maybe the last two things that recorded until it synced up. But if you were to go to an Amazon account and pull up the Alexa devices tied to it and then view the recordings, they have a category for things not meant for Alexa. And a lot of times it catches the commercials…the Alexa commercials, but you’d be surprised what it picks up just on its own. So those are the things the speaker picks up and sends on to Amazon. Amazon keeps them.
I will tell you the downside to their format at the moment is that you cannot download those actual files. You can erase them. You can clear them. You do have to log in as a user or serve them with court orders, but even from the user log in, you can’t download them. So you have to capture the audio as you play them. I use Audacity. Set the input to your direct sound output, play the device, and record that, play whatever that recording is and record it. And then you’re writing a memo about what that recording represents. I’ll screencap it or maybe videocap the process as I go if it’s something I’m doing for the first time with the crew. But you can get those recordings. If you’re looking for the very last thing picked up, then certainly you can do a chip subtraction on the device and parse for audio. But if you’re dealing with something that would have been synced up, it’s better to go to the Amazon accountant in question and get the recordings either via legal process, via cooperation with whoever was the registered owner of that device.
Holly: Have you had an opportunity to work with Zoom history that is stored in the user’s profile? Wondering if it is possible to decrypt the history file?
Allan: I have started in on it, but I haven’t spent a lot of time working on it yet. Most of my misbehaving employees don’t get as far as Zoom! What they’ve done on the conference call…it’s more about what they’re doing during working hours. So stay tuned, I guess, on the Zoom stuff. I’ve started playing with it, but I do not have a full solution on it yet. But I do say that log exists for a reason. Zoom knows how to parse it. So it’s just a matter of working backwards with a lot of testing and evaluation to figure out how that log can be interpreted.
Holly: Somebody was wondering what tool you use to produce the output displayed on the current slide?

Allan: So these are both X-Ways. This is your data view on the bottom right hand pane. This is the directory view. And again the whole point of this was speed and grabbing stuff quickly. So X-Ways is a great tool for that if you’re fluent with the tool. It’s like any other tool, if you’re not fluent with it, it can be a very frustrating time-waster. So what I use is a great starting point, but you need to take the time to learn your tools as well. I mentioned before X-Ways will parse just about anything out that doesn’t have errors in about 10 minutes flat to get to a file system. But you got to know what you’re looking at inside that.
So these are X-Ways. I don’t think there’s anything in here other than my computer and then some creative commons. The registry entries are from a tool that just parses registry files. So I told you about copying those out and moving them out into a place where I can use a registry viewer on it. This is actually a tool that the creator opted not to continue supporting past Windows 8, so it’s listed on a discontinued section of their website.
But having said that with Windows 10, all your key hive locations haven’t changed. So if I’m looking for basic data in the registry is still not a bad tool for digging into it. It’s not my only tool, it’s strictly a triage tool for looking at registry entries quickly. But I think that’s the only other screencap. (This one is also X-Ways, I think.) So most of the tools I’ve highlighted for you are things that work very quickly or efficiently in terms of finding stuff quickly. Sort of, full keyword search and text index or carving for files.
Holly: Alright. So we are at the end of our time, however, we have three more questions. If we can get through them, I would love to. If the hard drive has a full disk encryption and a RAM dump was not done, is there a way to access the data on a hard drive?
Allan: Sure. All you needed the keys. Fun fact with BitLocker: default OEM config from BitLocker for most you Dells and HP’s of the world started off as a clear key encryption, meaning the key is stored in the metadata for the device. We’re finally starting to recognize that and offer automatic decryption of them. I know Magnet’s one of them. You can also just mount the disk image in something like Arsenal Recon, where it presents as a physical device, and Windows will offer to unlock it for you.
So, again, work off a copy in that situation, so you’re not modifying your original. If you can identify the encryption algorithm, if it’s something commercial like Checkpoint or any of the McAfee and Norton stuff out there, if it’s something that a company has put in place, or they’ve gone…taken the steps to use appropriately secured BitLocker implementation, then they can provide you with a set of credentials or a decryption key, as long as they’ve been managing those keys.
I think this last year and a half has been a little bit of a learning curve on that front. A lot of companies rushed out to full disk encryption, employing the single device option, and then realizing that they had no control over those keys. So we’re starting to see more and more of the commercial management packages for full disk encryption, which is a huge boon for us because the company will cooperate 9 times out of 10 and help you with the decryption of that desk with credentials or the appropriate unlock via their server.
Holly: All right. Do you have any advice on evidence collection processes for a Chromebook in which the disc is not removable? For example, how do you grab an image and leave the smallest footprint possible?
Allan: So the smallest footprint possible is kind of what I talked about before. You have to log in as a user, use a logical acquisition tool to grab your files and then get out of there, turn it back off. The other option, you could do a chip subtraction, you could remove the storage and read it. And then note that it’s encrypted in a preservation copy and then put the chip back on the device.
Chip transplants are becoming more and more common. You have to be a very skilled examiner, you have to have the right tools to do it, in terms of extraction. But, you could do it that way. Unfortunately the logical extraction is still the only way I know of to get data off of Chromebook. So, you have one option and that is, “I logged in, I followed these steps, I pulled this data and then I turned the box off.”
Holly: All right. Final question. Have you worked with TFK and how does it compare to some of the commercial offerings, like at FTK and case X-Ways etc.
Allan: I’m not familiar with the TFK acronym. I’ve used a lot of the open source tools, the autopsy plugins and whatnot. Well, TFK is not one I’m familiar with, but now I’m going to have to go look it up!
Holly: Perfect. All right. I’m just going to the very last slide with all of our contact information. If you have any additional questions or comments, please feel free to reach out. Thank you, Allan, thank you everyone for attending and for all your great questions. Once again, this webcast was recorded and will be posted along with a copy of the slides to Exterro’s website. And we’ll be sending you a link to these materials later in the day over email. Along with that will be a link to the last two webinars in the series that you can register for. And that concludes our webinar today. Thank you so much and have a great day, everyone.





