by Harold Burt-Gerrans
Duplicative Documents
At the end of Part 2, I put forth an argument that de-duplication should always be done globally to bring the data set down to just unique documents. And now that you’re convinced (or should have been) that Global De-Duplication is the only way to go, I’m going to completely blow your mind by reversing my opinion and say:
“There should be no de-duplication at all, every document collected should be represented in the document review platform.”
Or at least, that’s what the end users should see…. Not everything is as it appears. Trust in magic.
My observation from most review platforms that I have seen is that they are typically structured from what I call a “Scanning Mentality,” where each document family consists of a lead document and its attachments. Some platforms have progressed to understanding multi-level Grandparent-Parent-Child relationships while others only truly understand a single level lead and attachment structure, but all require an actual document (and potentially extracted/OCR text and page images) for each Document Identifier (“DocID”). A quick scan of the cases we have hosted in Ringtail and Relativity showed that typically the number of unique MD5 hashes is only 70%-85% of the number of the documents in the review platform. Because we don’t extract embedded graphics from emails, these are not all logos. Since we almost exclusively de-duplicate globally, typically, 15%-30% of the documents in the review sets are children that are exact copies of children to other parents. I would be surprised if our statistics are not representative of the industry as a whole.
Some of the problems with having all these additional copies are:
- difficulty in maintaining consistency across coding, image generation and annotations/redactions for all copies, although this can be partially mitigated by automatic replication processes
- additional review fees due to increased hosting volumes (sorry boss) and review times
- potential statistical skewing of text analytics results affecting Content Analytics, Technology Assisted Review, Predictive Coding, Active Learning (and/or any other analytical tool used in automated review processes).
The full correction requires functionality to be developed by the review platform vendors and adjusting their database structures to always reference a single copy of a document. The coding and annotations/redactions done by the review team will have to be tracked by the platform against the underlying document. Architecturally, the change is from a single database table or view to a multi-table structure linking DocIDs and DocID Level coding to a Document and Document Level coding, perhaps by MD5 or SHA1.
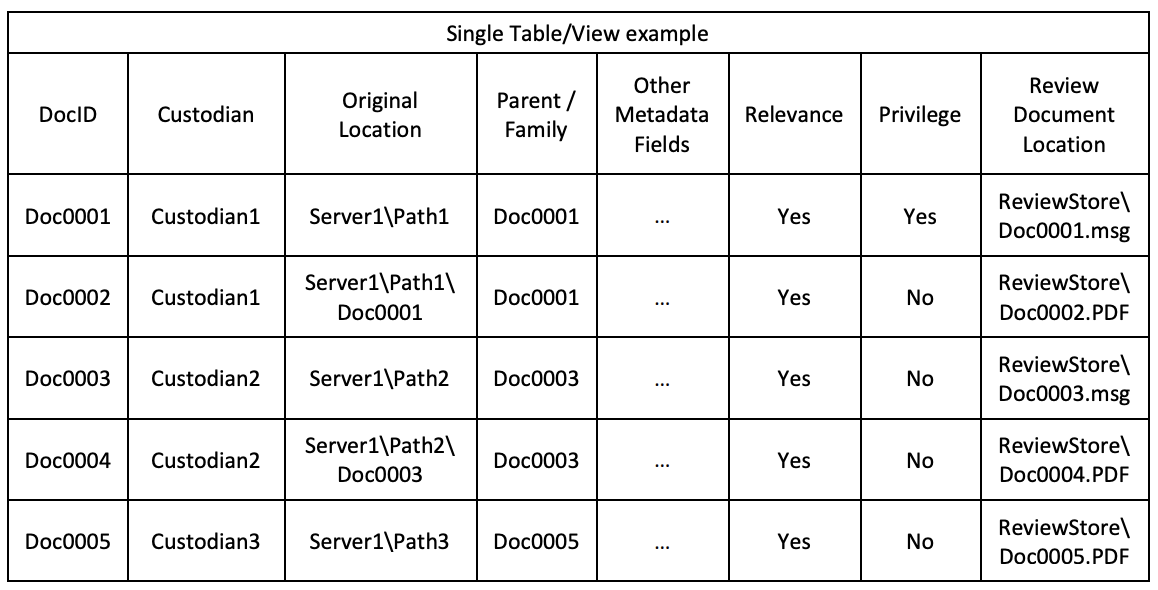
Today, when the same child is attached to two different parents, we track all the metadata (coding being “user assigned” metadata) for each of two copies of the child (one for each family). For efficiency, the review platforms should track, for each child, metadata that is specific to that occurrence of the child, and they should track, for a single copy representing both children, metadata that is specific to the document. For flexibility, the review team should have the choice of which level (DocID or Document) each coding field is to be associated with. The examples below illustrate the database tables for three document families under the current tracking of today and the multi-table tracking I propose:
Sample Current Data Structure:

Sample Multi-Table View:

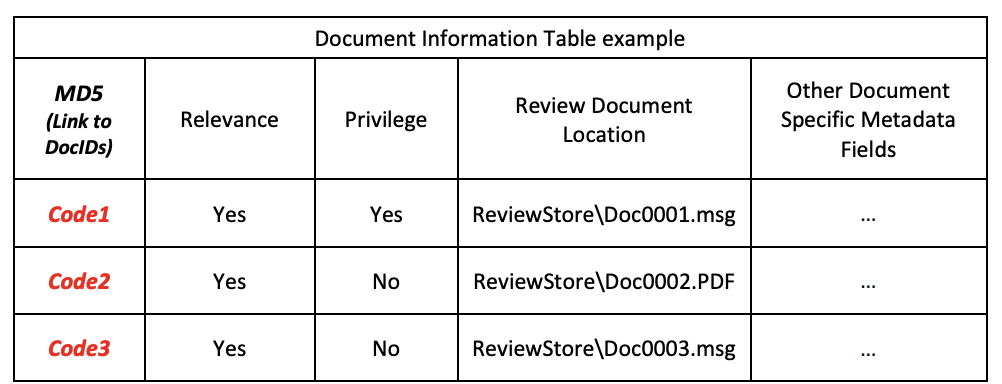
With the above proposed data structures, all review coding, imaging, Text Extraction/OCR, Machine Language Translations and annotations/redactions (and any other document level action) can all be applied against the records in the Document Information table. There will never be inconsistencies between Doc0002, Doc0004 and Doc0005. Today’s platforms often implement work-arounds to solve parts of these issues by automating the copying of coding between duplicates. Unfortunately, this does not usually work for annotations (where there is no control to ensure that the images for each duplicative document are identical – variations in image file type and resolution make it difficult to programmatically replicate annotations) and usually not for rolling ingestions (where new documents are added and some/all are duplicates of existing, coded documents).
Another advantage of this architecture is that it can be applied to all documents, not just child documents, and it can quickly identify stand-alone documents which may be coded inconsistently with duplicates within families. Suppose in the above example, Doc0001 and Doc0003 were both coded privileged. In that scenario, it would be quick to find that Code2 documents are always linked to privileged parents, so the stand-alone version (Doc0005) should be investigated to determine if it should be produced. Since the use of this document content has always been in conjunction with privileged families, perhaps Doc0005 could be considered as “Privileged Gained” (Remember from Part 2 – “A document can, on its own merit, be considered privileged or not, and that due to various family relations, privilege can be lost or gained“). A better approach may be to not produce any stand-alone documents if they are duplicates of family member documents – Those family members are either all not produced due to being withheld as part of privileged families, or at least one copy is already being produced as a member of a nonprivileged family.
Finally, implementation of an architecture such as described will still allow for document reviews to be run exactly as they are today, with the current de-duplication processes and coding processes, by associating all the coding fields to the DocID level. This will gain consistency for redactions and annotations while not disrupting current workflows. Over time, reviews can migrate to Document Level coding where suddenly documents will appear to have been coded because they are duplicates of others. This should be an easy transition as it is similar to what happens today when coding replication processes are used.
Start The Revolution
Document review has progressed from reading boxes of paper to online review using advanced analytics. It’s time that the review platforms stop mimicking the mindset of “1 document = 1 or more physical pages” and move towards “1 document = 1 unique set of information” and that piece of information may exist in multiple locations. Even though the approach I’ve suggested above is limited to matching exact duplicates, the reality is that the same approach should be expanded even further to encompass textural duplicates such that Doc0002 above could be an MS-Word document and Doc0004 could be the PDF version of Doc0002. Unfortunately, near-duplicate technologies at this time are not structured to safely enable that level of de-duplication since typically only the 100% near-duplicates identified tend to be in relation to the pivot document of each near-duplicate group/set. Over time, I’m sure that technology will advance to identify the 100% near-duplicates that exist between documents that are not 100% near-duplicates of the pivots (i.e. two documents both show as 90% near-duplicates of the pivot, but they may also be 100% near duplicates of each other and that relationship typically remains unidentified today).
Hopefully, I’m not a lone voice in the wind and others will rally behind my suggestions to shift the emphasis to reviewing “information” instead of “documents”. Everybody yell loudly like me and maybe it will happen.
Hopefully you’ve enjoyed (and not been confused by) Part 3. If you’re not overly technically savvy, it might seem confusing, but I hope most techies think “This seems like database normalization, should have started this in Summation and Concordance in the 90’s”. If you post questions, I’ll try to respond in a timely manner unless they’re addressed in Part 4. Part 4 will build further on the restructuring I’ve presented here and discuss things like restructured coding controls and recursive de-duplication. eDiscovery Utopia, here we come….
Read part four here.
About The Author
Harold Burt-Gerrans is Director, eDiscovery and Computer Forensics for Epiq Canada. He has over 15 years’ experience in the industry, mostly with H&A eDiscovery (acquired by Epiq, April 1, 2019).





