Gaëtan Michelet: So good morning, everyone. Today I will present the project we are working on with Frank Breitinger and Graham Horsman. This project is “Towards a working definition and classification for automation in the context of digital forensic”. And I just want to thank Felix Freiling for his feedback and different discussions we could have with him.
So first, quickly, who I am, I’m Gaëtan Michelet, I’m a new PhD student at the School of Criminal Justice at the University of Lausanne and I’m doing my PhD under the supervision of Frank Breitinger. About my interests, I have a strong interest in automation and artificial intelligence, and of course, in the context of digital forensics.
How the idea came along: first, I started the PhD and I started with a literature review and we were looking for a definition for the automation in the specific context of digital forensics, but we came to a result, usually the authors are just giving some global definitions that are not specific to the digital forensic context, or they are giving some key elements from the automation.
For example, okay, automation is used to reduce human involvement or to get some benefits, for example, by boosting the efficiency. And this is why we came to that project.
So towards the definition. We took a look at the definition in digital forensics, as I just explained we didn’t find anything convenient for us because that was too generic or just some key elements. In general, we took a look at dictionaries or some knowledge bases like Wikipedia, for example, and we found some interesting definitions, but that was really global.
And in auto demand, like for example, business process automation, and we discovered that they had some definition for automation that were very, let’s say, formed by the context. For example, you could find some element of business in the definition of business process automation.

And from all those definitions, we could find some key elements that we highlighted. The first one is that when you are using automation, the idea is to get less or no human intervention in the process. And then when you’re automating a process, the idea is really to get a benefit from it. You want to accomplish a goal.
Generally this is boosting the efficiency, the reliability of the process, sometimes the rentability, and sometimes this is just to free human resources. In our context, that would be for example, to let the human do some more investigative tasks, instead of just doing some repetitive and boring tasks.
So we came to that definition of software or hardware that reduces or removes the need for human engagement when completing a task to be more efficient, more reliable, or to reduce human labor.
This has several implications. This is a working definition, so we know it’s not perfect yet, and it’ll need some refinements. This is why we are presenting that definition here to get some feedback and some ideas.
Then you can see when we are enumerating the goals for the automation, we are using the R because we don’t think that all those goals need to be achieved in order to enter the definition. If we, for example, have a tool that’s faster than a human and maybe a little less reliable, this can enter the definition, and if you have a tool that takes more time than a human, but that’s way more reliable, it also enters the definition.
And lastly, an important consideration is that with that definition, if we accept it, every tool must be considered automation. For example, a simple tool that’s transforming bit data into hexadecimal data, that would be automation. A machine-learning-based tool, that would be automation too.

So we need a way to be able to compare them, and the solution that we explored is the need for a classification scheme.
We took a look at the classification schemes that were available for the automation in digital forensics. We did not find anything convenient in other domains.
In the other domains, like for example flight traffic control, we found some really interesting classification schemes, but the problem was that it was not transposable to digital forensics because this is a really specific domain with an investigative process and that was just not possible.
We think having that classification scheme could bring several benefits. First, we could get some information about, for example, the risk and the capabilities of the tool by just taking a look at its level of automation.
For example, if you say, okay, it’s sort of full automation, we cannot do that. It’ll do a lot of things for us, but we have the risk of misinterpreting or misjudging some of the output.
And then if all the tools have a level of automation, we can compare them and select the one that we want to use in a specific context. And finally, if we do that, if we just see all the levels of automation of maybe lots of tools, we would be able to identify some gaps that are in the automation of digital forensics.

We are proposing two models. The first model is just a linear model. This is really easy and convenient to use. This is easy to represent because that’s just for example, a number. Okay, that tool is level one or level four of automation.
But we would like some granularity, we think. So here is what it would look like. On the left you have no automation, on the right you have full automation. Here the rubric that is presented is descriptive of automation. So no autonomy. This is just a basic tool doing some basic stuff. For example, transforming data or parsing some EXIF from a JPEG. This is the example that we’re giving.
Then you have the next level, which is assistance. It’s helping the investigator by, for example, highlighting or filtering some data. For example, text searching in a disc image. Autonomous assistance is basically the same as assistance, but instead of the practitioner having to launch the process, it’s done autonomously.
For example, imagine you have Autopsy, you upload your data and directly it’ll select a list of keywords that are usually searched for, and that will launch the searching process. Then you have partial task automation, which is the next level. And here, the tool is doing an investigative task.
We took the example of a report writing tool. That tool would be, for example, based on previously written reports, and it will learn from previous reports and write the first draft, and then it will give the first draft to the investigator, who will have to review it, adjust it, modify it if needed.
And the final level is full task automation. So here, all the tasks, the investigative task is done by the tool and you only have the output. The example here is blacklisting.
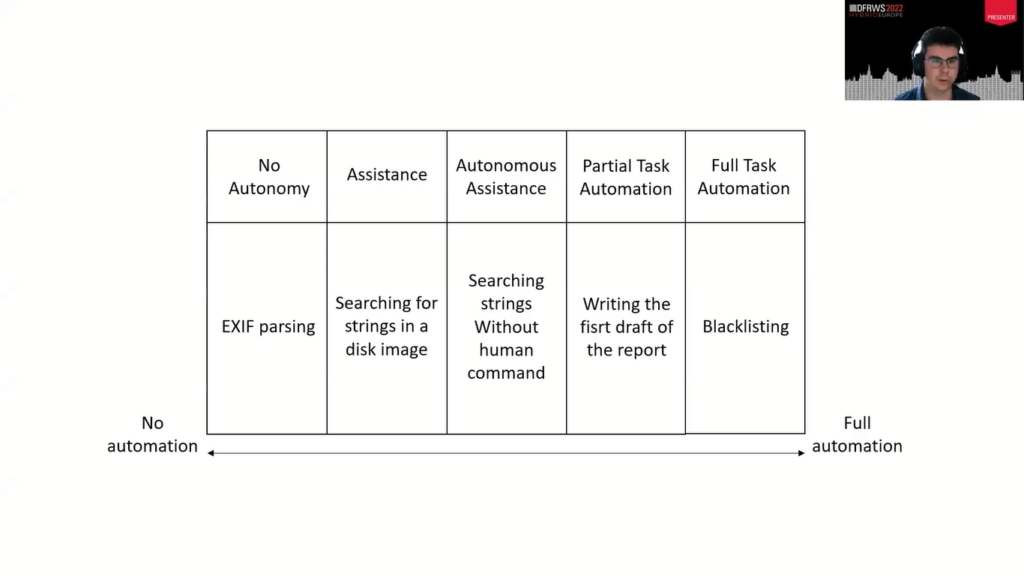
And with that model we have a problem. We see that blacklisting would have a higher level of automation than an advanced tool that’s using case-based learning or machine learning. And this is not what we want to have because technologically the report writing tool is more advanced.
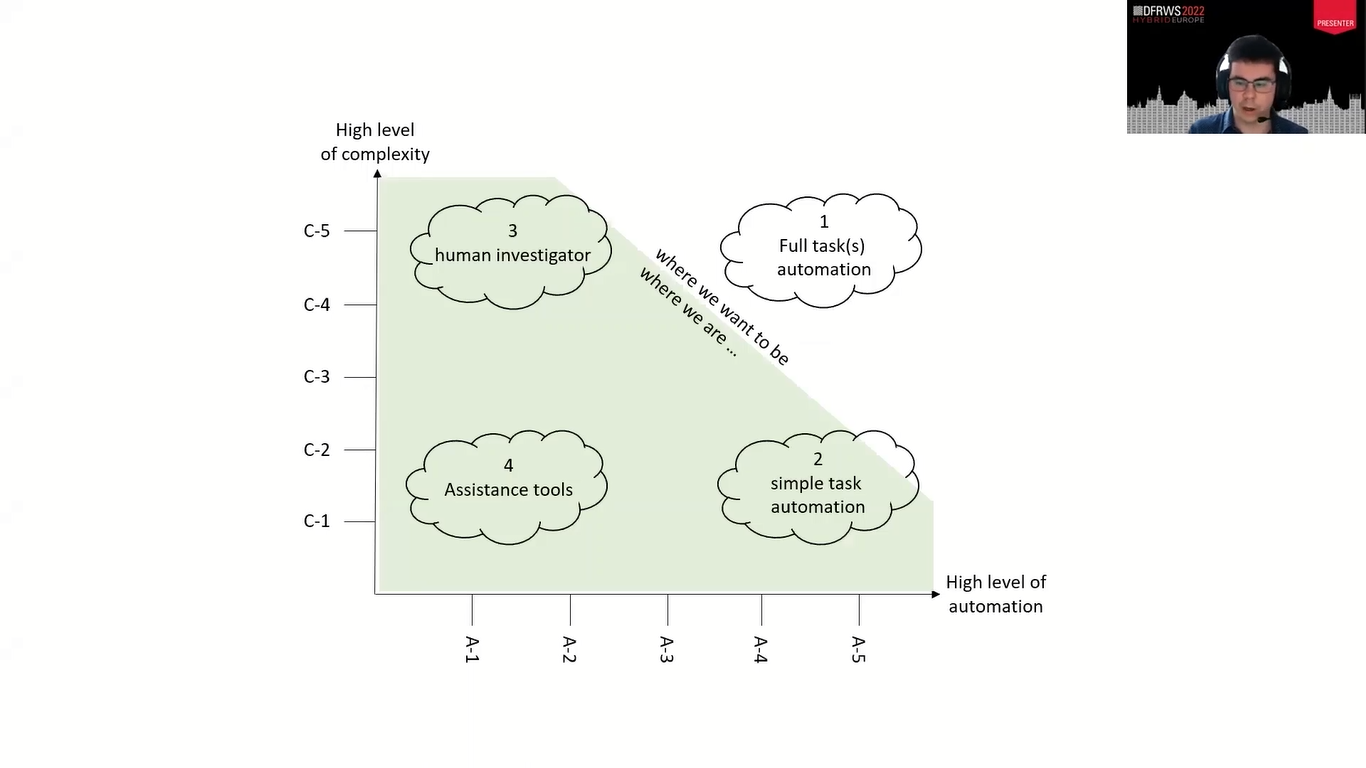
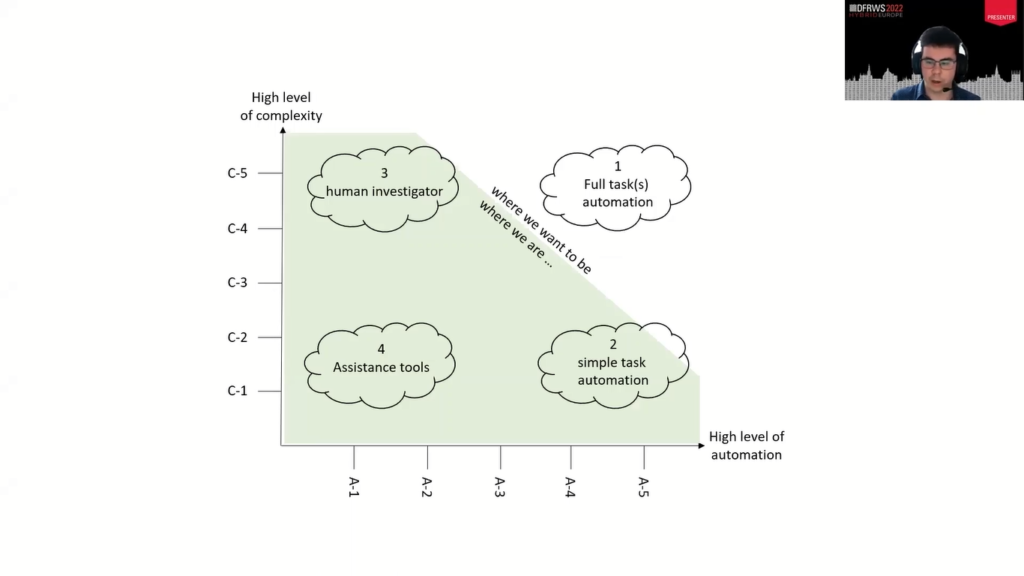
And so we are proposing a second model, which is a matrix model with two dimensions. So instead of having only one rubric, we could have two rubrics. We think that’s still easy to use and to understand, easy to represent, this is just a plan. And we will have a nice granularity if we imagine having two rubrics with five levels, we would have 25 classes instead of just five classes. And this is the model we are favoring.
Here is an example. So under the X axis, you just have the level of automation that we described before with the linear model. And on the other axis, this is the complexity of the tool. You can see that on that graph, we identified four regions.
When you have a high level of automation, low level of complexity, this is simple task automation like blacklisting, for example. If you have a low level of automation and a low level of complexity, this is just an assistance tool like the EXIF parcel, for example.
High complexity and a low level of automation basically does the practitioner, the human investigator. And what we would like to have is a high level of automation, a high level of complexity. And here we would get full task automation. And this is what we think we want in the future.
Of course, this is the rubrics we are presenting. We could choose other rubrics. For example, decision making of the tool, the number of investigation faces that the tool is automating, the complexity of the tool, and the description of the technique. These are the four elements that we’re proposing. This is not exhaustive.
And we already presented the description of the technique of the level of automation. And the number of investigation phases, that would be quite simple. For example; level zero, you have less than one phase automated; level one, one phase automated; level two, two phases automated, et cetera.
For the decision making, we could imagine those five levels. So the tool is making absolutely no decisions; the tool is making an objective decision, which is a decision based on a comparison, for example, blacklisting; the tool is comparing the hash in the database with the hash in the file and it’s making a decision about that.
You have subjective decisions, which is this decision based on a specific input that you’re giving to the tool. For example, that would be case-based resigning. Then you have learning to make a subjective decision. Here we would find machine learning and deep learning.
And full automation. We don’t know already what it would be, but that would be maybe something that’s learning on its own and taking the input data on its own, for example.
On the complexity rubrics, there is no clear level of automation that we have, but we could find interesting elements that will be taken into account when designing the levels. We think that the more complex a tool is, the higher are the risks.

So if you imagine, for example, an advanced AI tool, you don’t always understand how it is working and you can misinterpret the output or misjudge the data. The higher is the impact on the impact on the investigation. We think that basic tools are giving more advanced than a complex tool.
And finally the harder it is to verify the mechanism. You should have to go into the source code and take a look and understand. If your tool is more complex, that will be more difficult.
We have some future work ideas. So first, the refinement of the definition and the selection of the rubrics for the classification model. And this is also why we are presenting it to you. You maybe have some ideas or some feedback that you could give to us.
And we also want to create a common glossary of the terms that are related to automation. We could see in the literature, for example, process automation, task automation, the automation of the forensic process, that’s not always used in the same way, and we would like to have a common glossary to use it in a more precise way.
So in that presentation, we just presented to you a working definition and a classification model for the automation in the context of digital forensics. We would favor a matrix model with two dimensions. We were thinking maybe of a third dimension, but that would be really hard to use and really hard to represent. So we think that two dimensions is a good trade off between, let’s say, user friendliness and granularity, but we still need to decide which levels are the most suited.
And we really need the discussion with the community and to refine that definition. So thank you for your attention and if you have questions or comments, go ahead.

Session Chair: Okay. So do you have any questions?
Audience Member 1: Thank you. Well, thanks for this very interesting effort you are working on. I like it a lot. I have a question: did you also look into similar automation discussions in the traditional forensic fields? For example, related to pattern matching or stuff like that. I know there are some publications recently that presented a similar model, actually.
Gaëtan: I don’t think we took a look at that, so we will do it absolutely. Thank you.
Session Chair: Okay. Other questions? I don’t see anything from the chat or audience. I do have a question: So when you were checking the definitions of automation for digital forensics and in other domains, which were the main differences you found?
Gaëtan: For example, in the business process automation, that was really business-oriented even if the definition you found, yeah, that’s the kind of difference that you had. And otherwise in general, they’re just giving, okay, that’s less human involvement for example, or a computer doing the work instead of the human. Yeah, these are not big differences, but you can see the domain it’s coming from when you take a look at the definition.
Session Chair: Okay. Thank you. So, any further questions?
Audience Member 2: When it comes to full-task automation, clearly one of the big problems is ensuring chain of custody, making sure that whatever conclusions are drawn from the automated analysis are valid. So how do you go about ensuring in general that systems are coming to correct conclusions without essentially fully manually verifying the system?
Gaëtan: I think work has been done about how to design a tool in order to give some elements of evaluation for the user and about, for example, what the tool must give to the user in order to be able to know his performance and the risk associated, too.
And this is something that we would strongly recommend to follow. But yeah, before that needed a manual control, and then after when you have the tool and you know the performances, you know the risks associated, you will just run the tool automatically.
Session Chair: Okay. Thank you. So thank you to Gaëtan for this presentation and good luck. We are looking forward to seeing this publication. Thank you.





